Yolov5自学笔记之二--在游戏中实时推理并应用(实例:哈利波特手游跳舞小游戏中自动按圈圈)
上一篇帖子我已经自学了Yolov5的基本流程,并运用yolov5进行图片、视频、摄像头、网络视频流等多种方式的推理,这些结合到实际工作中就可以有很广泛的应用了。但是还有一类情况,就是在电脑中的某个程序中,需要进行实时推理,比如游戏场景中的推理,这篇帖子我们就来解决一下这个问题。
现在比如我有这么一个需求,在手游哈利波特中有个跳舞的小游戏,其实就是按照一定的节奏来点击那个圆圈圈,我现在希望能够写个程序,自动实现这个功能。
游戏效果大概是这样:
yolov5检测哈利波特跳舞圆圈
1.基本思路
基本思路就是用yolov5对圆圈进行实时目标检测,并依据结果控制鼠标去点击圆圈。
具体来说就是,先用模拟器把手游画面放到桌面,然后抓取这个画面,对画面逐帧进行目标检测,获取圆圈的位置,然后用程序控制鼠标,去点击这个圆圈中心点。
需要用到的工具有以下几个:
1.1从手机画面到电脑桌面
首先考虑,把手游画面搬到电脑桌面,这个有很多手游模拟器都可以做到,我这里选择scrcpy,这是个很好用的在电脑上模拟手机画面的小程序。scrcpy通过adb调试的方式来将手机屏幕投到电脑上,并可以通过电脑控制您的Android设备。它可以通过USB连接,也可以通过Wifi连接(类似于隔空投屏),而且不需要任何root权限,不需要在手机里安装任何程序。scrcpy同时适用于GNU / Linux,Windows和macOS。
关于scrcpy的使用,可以参考下面的帖子:
scrcpy——Android投屏神器(使用教程)_星辰大海-CSDN博客_scrcpy
我自己的百度网盘资源:
链接:https://pan.baidu.com/s/1uavgsCxjDrdmYfpxWyV3Jw
提取码:drmm
--来自百度网盘超级会员V3的分享
1.2目标识别部分
用win32gui抓取电脑上指定区域(手机画面)的画面,然后用CV2对图像处理后送入yolov5进行识别推理,并返回结果。可以同时用另一个窗口显示识别结果(加上识别框的画面)。
如何采集图像数据并训练,可以参考我上一篇文章 Yolov5自学笔记之一--从入门到入狱,功能强大不要乱用(实现yolov5的基本功能使用流程及训练自己的数据集)_奢华贝叶斯的博客-CSDN博客
用yolov5训练识别那个圆圈,我本来想识别那个外圈的,后来发现还是识别内圈效果好,所以采集内圈的图片,并进行训练。
识别效果如下:
yolov5识别跳舞圆圈
1.3控制鼠标点击
点击部分,Python有很多控制鼠标的办法,我这里采用的是pyautogui这个库,操作起来比较简单,只要用到其中两个函数 moveTo() 和 click()就行。
2、具体代码实现:
2.1手机设置为开发者模式,手机连接电脑,进入scrcpy目录,直接启动scrcpy.exe,把手机画面放到电脑屏幕左上角
2.2写一个抓取屏幕的函数grabscreen
import cv2
import numpy as np
import win32gui
import win32ui
import win32con
import win32api
def grab_screen(region=None):
hwin = win32gui.GetDesktopWindow()
if region:
left, top, x2, y2 = region
width = x2 - left + 1
height = y2 - top + 1
else:
width = win32api.GetSystemMetrics(win32con.SM_CXVIRTUALSCREEN)
height = win32api.GetSystemMetrics(win32con.SM_CYVIRTUALSCREEN)
left = win32api.GetSystemMetrics(win32con.SM_XVIRTUALSCREEN)
top = win32api.GetSystemMetrics(win32con.SM_YVIRTUALSCREEN)
hwindc = win32gui.GetWindowDC(hwin)
srcdc = win32ui.CreateDCFromHandle(hwindc)
memdc = srcdc.CreateCompatibleDC()
bmp = win32ui.CreateBitmap()
bmp.CreateCompatibleBitmap(srcdc, width, height)
memdc.SelectObject(bmp)
memdc.BitBlt((0, 0), (width, height), srcdc, (left, top), win32con.SRCCOPY)
signedIntsArray = bmp.GetBitmapBits(True)
img = np.fromstring(signedIntsArray, dtype='uint8')
img.shape = (height, width, 4)
srcdc.DeleteDC()
memdc.DeleteDC()
win32gui.ReleaseDC(hwin, hwindc)
win32gui.DeleteObject(bmp.GetHandle())
return cv2.cvtColor(img, cv2.COLOR_BGRA2RGB)
这个函数的功能是抓取电脑屏幕左上角 width 宽 height 高 的一块长方形区域图像并返回该图像的RGB格式图片。
2.3写一个dancing主程序,实现抓取图像、实时推理识别、返回位置并控制鼠标点击等功能
import time
import cv2
import numpy as np
import torch
from models.experimental import attempt_load
from utils.datasets import letterbox
from utils.general import check_img_size, non_max_suppression,scale_coords, xyxy2xywh,set_logging,check_requirements,save_one_box
from utils.plots import colors,Annotator #plot_one_box
from utils.torch_utils import select_device #time_synchronized
from grabscreen import grab_screen
from PIL import Image
import pyautogui
pyautogui.FAILSAFE = False
@torch.no_grad()
def detect(
#--------------------这里更改配置--------------------
#---------------------------------------------------
weights='weights/best20220126.pt', #训练好的模型路径
imgsz=640, #训练模型设置的尺寸
cap = 0, #摄像头
conf_thres=0.25, #置信度
iou_thres=0.45, #NMS IOU 阈值
max_det=1000, #最大侦测的目标数
device='', #设备
crop=True, #显示预测框
classes=None, #种类
agnostic_nms=False, #class-agnostic NMS
augment=False, #是否扩充推理
half=False, #使用FP16半精度推理
hide_labels=False, #是否隐藏标签
hide_conf=False, #是否隐藏置信度
line_thickness=3 #预测框的线宽
):
# #--------------------这里更改配置--------------------
#-----------------------------------------------------
#-----初始化-----
set_logging()
#设置设备
device = select_device(device)
#CUDA仅支持半精度
half &= device.type != 'cpu'
#-----加载模型-----
#加载FP32模型
model = attempt_load(weights, map_location=device)
#模型步幅
stride = int(model.stride.max())
#检查图像大小
imgsz = check_img_size(imgsz, s=stride)
#获取类名
names = model.module.names if hasattr(model, 'module') else model.names
#toFP16
if half:
model.half()
#------运行推理------
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # 跑一次
#-----进入循环:ESC退出-----
picnum=0
while(True):
image_array = grab_screen(region=(0, 0, 1280, 720))
array_to_image = Image.fromarray(image_array, mode='RGB') #将array转成图像,才能送入yolo进行预测
img = np.asarray(array_to_image) #将图像转成array
#设置labels--记录标签/概率/位置
labels = []
#计时
t0 = time.time()
img0=img
#填充调整大小
img = letterbox(img0, imgsz, stride=stride)[0]
# 转换
img = img[:, :, ::-1].transpose(2, 0, 1) #BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
#uint8 to fp16/32
img = img.half() if half else img.float()
#0 - 255 to 0.0 - 1.0
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# 推断
#t1 = time_synchronized()
pred = model(img, augment=augment)[0]
# 添加 NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
#t2 = time_synchronized()
#目标进程
for i, det in enumerate(pred): # 每幅图像的检测率
s, im0 = '', img0.copy()
#输出字符串
s += '%gx%g ' % img.shape[2:]
#归一化增益
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]]
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# 将框从img_大小重新缩放为im0大小
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# 输出结果
for c in det[:, -1].unique():
#每类检测数
n = (det[:, -1] == c).sum()
#添加到字符串
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, "
# 结果输出
for *xyxy, conf, cls in reversed(det):
#归一化xywh
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist()
#标签格式
line = (cls, *xywh, conf)
#整数类
c = int(cls)
#建立标签
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
#画预测框
if crop:
#print('right')
annotator.box_label(xyxy, label, color=colors(c, True))
#plot_one_box(xyxy, im0, label=label, color=colors(c, True), line_thickness=line_thickness)
#记录标签/概率/位置
labels.append([names[c],conf,xyxy])
#print(labels)
#设定延迟时间,以画面中的圆圈数来区分速度,画面中只有一个圈的时候就要慢一点,反之则快
ys=0
if len(labels)<2:
ys=0.17
elif len(labels)<4:
ye=0.14
elif len(labels)<6:
ys=0.12
else:
ys=0.1
#获取中心点,即分别求横、纵坐标的中间点
pointx=int((xyxy[0]+xyxy[2])/2)
pointy=int((xyxy[1]+xyxy[3])/2)
#移动鼠标到中心点位置,并点击
pyautogui.moveTo(pointx,pointy,duration=ys)
pyautogui.click()
pyautogui.click()
# 显示图片
imshow=cv2.cvtColor(im0, cv2.COLOR_RGB2BGRA)
cv2.imshow("copy window",imshow)
#输出计算时间
print(f'消耗时间: ({time.time() - t0:.3f}s)')
key = cv2.waitKey(2)
#这里设置ESC退出
if key == 'q':
break
#--------------------END--------------------
#-------------------------------------------------
cv2.destroyAllWindows()
if __name__ == "__main__":
detect()运行界面大概是这样的:
这里要注意的是,圆圈出现的时间节奏是不一样的,所以我利用pyautogui.moveTo()中的duration参数来控制延迟时间去点击圆圈。我大概做了一个判断,当屏幕上只有1个圆圈的时候,大约延迟0.17秒去点,其余类推。当然这个根据不同电脑的机器环境网络环境,自己去微调。
最终实现的效果如下:
哈利波特自动识别跳舞
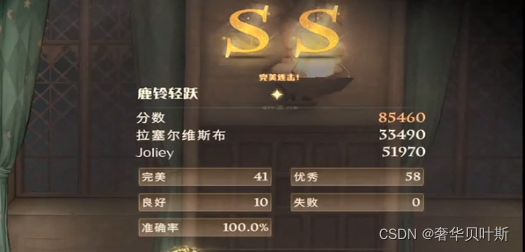
可以看到,程序最终打出了SS的成绩,圆圈的识别率是100%的,但是完美率不够高,很多只是优秀,甚至还有10个只是良好,这些自己可以再去微调以获得更好的效果。
当然,要想真正实战使用的话,那可以考虑再多一点,比如再识别个外圈,根据外圈收敛的情况来判断鼠标点击的时机等等。因为我的目的还是学习yolov5目标识别,不是制作外挂,所以这里就不展开讨论了。
结论:这个方法可以推广到各种需要根据画面内容来进行判断并点击完成的游戏。当然也可用于实时监测并作出相关反应的程序,比如自动驾驶、比如播放中的视频实时检测等等。