【Spark】(十三)Spark数据分析及处理
用例一:数据清洗
基本步骤:
- 1、读入日志文件并转化为RDD[Row]类型
按照Tab切割数据
过滤掉字段数量少于8个的 - 2、对数据进行清洗
按照第一列和第二列对数据进行去重
过滤掉状态码非200
过滤掉event_time为空的数据
将url按照”&”以及”=”切割 - 3、保存数据
将数据写入mysql表中
日志拆分字段:
event_time
url
method
status
sip
user_uip
action_prepend
action_client
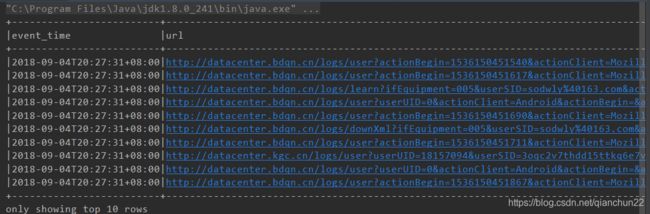
如下是日志中的一条数据按照Tab分隔后的示例,每一行代表一个字段,分别以上一一对应

1、读入日志文件并转化为RDD[Row]类型
按照Tab切割数据
过滤掉字段数量少于8个的
val spark = SparkSession.builder().master("local[*]")
.appName("DataClear").getOrCreate()
val sc = spark.sparkContext
import spark.implicits._
val linesRdd = sc.textFile("in/test.log")
//按照Tab切割数据
// 过滤掉字段数量少于8个的
val rdd = linesRdd.map(x=>x.split("\t"))
.filter(x => x.length == 8)
.map(x => Row(x(0).trim,x(1).trim,x(2).trim,x(3).trim,x(4).trim,x(5).trim,x(6).trim,x(7).trim))
val schema = StructType(
Array(
StructField("event_time", StringType,false),
StructField("url", StringType,false),
StructField("method", StringType,false),
StructField("status", StringType,false),
StructField("sip", StringType,false),
StructField("user_uip", StringType,false),
StructField("action_prepend", StringType,false),
StructField("action_client", StringType,false)
)
)
val orgDF = spark.createDataFrame(rdd,schema)
2、对数据进行清洗
按照第一列和第二列对数据进行去重
过滤掉状态码非200
过滤掉event_time为空的数据
// 按照第一列和第二列对数组进行去重; 过滤掉状态码非200; 过滤掉event_time为空的数据
val ds1 = orgDF.dropDuplicates("event_time", "url")
.filter(x => x(3) == "200")
.filter(x => StringUtils.isNotEmpty(x(0).toString))
将url按照”&”以及”=”切割
//先将url按照”?”切割
val dfDetail = ds1.map(row => {
val urlArray = row.getAs[String]("url").split("\\?")
// val urlArray2 = row(1).toString.split("\\?")
//将url按照”&”以及”=”切割
var map: Map[String, String] = Map("params" -> "null")
if (urlArray.length == 2) {
map = urlArray(1).split("&")
.map(x => x.split("="))
.filter(_.length == 2)
.map(x => (x(0), x(1)))
.toMap
}
(row.getAs[String]("event_time"),
map.getOrElse("actionBegin", ""),
map.getOrElse("actionClient", ""),
map.getOrElse("actionEnd", ""),
map.getOrElse("actionName", ""),
map.getOrElse("actionTest", ""),
map.getOrElse("actionType", ""),
map.getOrElse("actionValue", ""),
map.getOrElse("clientType", ""),
map.getOrElse("examType", ""),
map.getOrElse("ifEquipment", ""),
map.getOrElse("isFromContinue", ""),
map.getOrElse("skillIdCount", ""),
map.getOrElse("skillLevel", ""),
map.getOrElse("testType", ""),
// map.getOrElse("userSID", ""),
map.getOrElse("userUID", ""),
// map.getOrElse("userUIP", ""),
row.getAs[String]("method"),
row.getAs[String]("status"),
row.getAs[String]("sip"),
row.getAs[String]("user_uip"),
row.getAs[String]("action_prepend"),
row.getAs[String]("action_client"))
}).toDF()
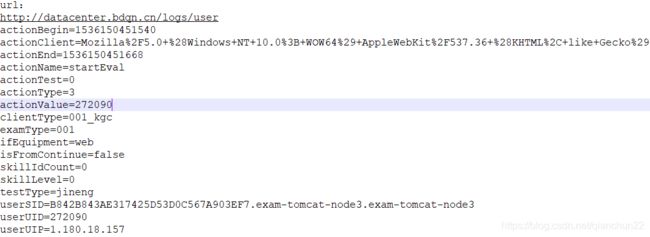
url按?及&分割后如下:
3、数据清洗完成
现将上面的dfDetail转成rdd
创建表结构detailschema
最后生成DataFrame完成数据清洗
val detailRdd = dfDetail.rdd
val detailSchema = StructType(
Array(
StructField("event_time", StringType,true),
StructField("actionBegin", StringType,true),
StructField("actionClient", StringType,true),
StructField("actionEnd", StringType,true),
StructField("actionName", StringType,true),
StructField("actionTest", StringType,true),
StructField("actionType", StringType,true),
StructField("actionValue", StringType,true),
StructField("clientType", StringType,true),
StructField("examType", StringType,true),
StructField("ifEquipment", StringType,true),
StructField("isFromContinue", StringType,true),
StructField("skillIdCount", StringType,true),
StructField("skillLevel", StringType,true),
StructField("testType", StringType,true),
// StructField("userSID", StringType,true),
StructField("userUID", StringType,true),
// StructField("userUIP", StringType,true),
StructField("method", StringType,true),
StructField("status", StringType,true),
StructField("sip", StringType,true),
StructField("user_uip", StringType,true),
StructField("action_prepend", StringType,true),
StructField("action_client", StringType,true)
)
)
val detailDF = spark.createDataFrame(detailRdd,detailSchema)
4、保存数据
将数据写入mysql表中
//创建mysql连接
val url = "jdbc:mysql://192.168.247.201:3306/kb09db"
val prop = new Properties()
prop.setProperty("user","root")
prop.setProperty("password","ok")
prop.setProperty("driver","com.mysql.jdbc.Driver")
println("开始写入mysql")
//overwrite--->覆盖
//append--->追加
detailDF.write.mode("overwrite").jdbc(url,"logDetail",prop)
orgDF.write.mode("overwrite").jdbc(url,"logorg",prop)
println("写入mysql结束")
用例2:用户留存分析
需求:
1、计算用户的次日留存率
求当天新增用户总数n
求当天新增的用户ID与次日登录的用户ID的交集,得出新增用户次日登录总数m (次日留存数)
m/n*100%
2、计算用户的次周留存率
1、读取mysql数据
读取 mysql 中清洗好的数据表
val spark = SparkSession.builder().master("local")
.appName("UserAnalysis").getOrCreate()
val sc = spark.sparkContext
import spark.implicits._
//创建mysql连接
val url = "jdbc:mysql://192.168.247.201:3306/kb09db"
val prop = new Properties()
prop.setProperty("user","root")
prop.setProperty("password","ok")
prop.setProperty("driver","com.mysql.jdbc.Driver")
// 读取清洗好的数据表
val detailDF = spark.read.jdbc(url,"logDetail",prop)
2、自定义时间戳函数
先截取年月日部分,舍弃其余部分
再将截取的年月日转换成时间戳形式
// 自定义函数,得到时间戳
val changeTimeFun = spark.udf.register("changeTime", (x: String) => {
val time = new SimpleDateFormat("yyyy-MM-dd")
.parse(x.substring(1, 10)).getTime
time
})
3、注册用户信息
过滤出所有注册用户信息
利用时间戳函数将时间转换成时间戳
查询出行为Registered的注册时间、userUID
去重,即同一用户注册一次
// 所有的注册用户信息 DF(userUID、register_time、注册行为Registered)
val registerDF: DataFrame = detailDF.filter(detailDF("actionName") === ("Registered"))
.select("userUID","event_time", "actionName")
.withColumnRenamed("event_time","register_time")
.withColumnRenamed("userUID","regUID")
//时间戳转换,并去重
val registerDF2 = registerDF.select($"regUID"
,changeTimeFun($"register_time").as("register_date")
, $"actionName").distinct()
4、用户登录信息
过滤出所有用户登录信息
利用时间戳函数将时间转换成时间戳
查询出行为Registered的注册时间、userUID
去重,即计算留存率,同一用户在一天内的登录次数只能算一个用户
val signinDF: DataFrame = detailDF.filter(detailDF("actionName") === ("Signin"))
.select("userUID","event_time", "actionName")
.withColumnRenamed("event_time","signin_time")
.withColumnRenamed("userUID","sigUID")
.distinct()
val signinDF2 = signinDF.select($"sigUID"
,changeTimeFun($"signin_time").as("signin_date")
, $"actionName").distinct()
5、合并用户注册表和用户登录表
注意此处用join默认连接
// 两表连接
val joinDF = registerDF2.join(signinDF2
, registerDF2("regUID") === signinDF2("sigUID")
,"inner")
6、次日留存人数
计算一日的时间戳:86400000=246060*1000
计算一日留存人数
修改列名
// 得到次日留存用户数量
val frame = joinDF.filter(joinDF("register_date") === joinDF("signin_date")-86400000)
.groupBy($"register_date")
.count().withColumnRenamed("count","sigcount")
7、注册人数
count 计算注册的人数
修改列名
// 得到当日用户注册数量
val frame1 = registerDF2.groupBy($"register_date")
.count().withColumnRenamed("count","regcount")
8、合并留存人数表和注册人数表
val frame2 = frame.join(frame1,"register_date")
合并后的表如下:
+-------------+--------+--------+
|register_date|sigcount|regcount|
+-------------+--------+--------+
|1535990400000| 355| 381|
+-------------+--------+--------+
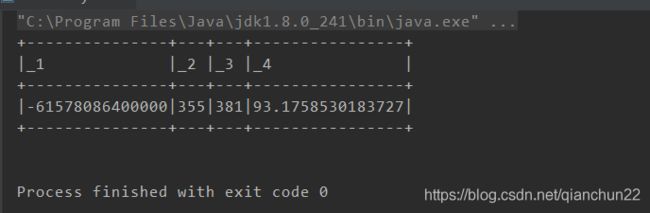
9、计算次日留存率
通过一日留存人数和注册人数计算留存率
注意数据类型,做除法计算是需要.toDouble,将其转换为Double类型
// 计算用户的次日留存率
frame2.map(x =>
(x.getAs[Long]("register_date")
, x.getAs[Long]("sigcount")
, x.getAs[Long]("regcount")
, (x.getAs[Long]("sigcount").toDouble / x.getAs[Long]("regcount").toDouble)*100
)).show(false)
计算结果: