重磅!蚂蚁开源可信隐私计算框架“隐语”,主流技术灵活组装、开发者友好分层设计...

7月4日,蚂蚁集团宣布面向全球开发者正式开源可信隐私计算框架“隐语”,采用 Apache-2.0 协议,代码托管至 GitHub、Gitee 两大平台。“隐语”通过良好可扩展的架构设计,用一套通用框架统一支持了包括 MPC、TEE、FL、HE、DP 在内的多种主流隐私计算技术,可以对多种技术进行灵活组合,针对不同应用场景提供不同的解决方案。
![]()
六年技术沉淀,“隐语”攻破一道隐私计算应用难题
2016 年,“隐语”作为一个“实验项目”在蚂蚁诞生,从矩阵变换技术踩下第一个脚印,到可信执行环境(TEE),再到多方安全计算(MPC)、联邦学习(FL)等,一路以来不断丰富自身技术内涵,在金融、医疗等领域实际应用场景中有成功的落地应用经验。
尽管隐私计算理论发展四十余年,在应用层面,至今依然存在着诸多行业必须跨越的障碍:
-
隐私计算技术方向多样,不同场景下有其各自更为合适的技术解决方案;
-
隐私计算学习曲线很高,非隐私计算背景的用户使用困难;
-
隐私计算涉及领域众多 需要领域专家共同协作。
隐私计算现阶段依旧是相对新兴的跨学科领域,涉及密码学、机器学习、数据库、可信硬件等多个领域,包含多方安全计算(MPC)、联邦学习(FL)、可信执行环境(TEE)、可信密态计算(TECC)等多种技术路线,涉及众多专业技术栈,要实现完善并保障安全并非易事。“隐语”的设计目标,是使得数据科学家和机器学习开发者无需了解底层技术细节,就可以非常容易地使用隐私计算技术进行数据分析和机器学习建模。
那么,如何才能够适配不同层次开发者的不同需求?
为了达到这个目标,隐语提供了一层设备抽象,将多方安全计算(MPC)、同态加密(HE)和可信执行环境(TEE)等隐私计算技术抽象为密文设备, 将单方计算抽象为明文设备。
基于这层抽象,数据分析和机器学习工作流可以表示为一张计算图,其中节点表示某个设备上的计算,边表示设备之间的数据流动,不同类型设备之间的数据流动会自动进行协议转换。在这一点上,隐语借鉴了主流的深度学习框架,后者将神经网络表示为一张由设备上的算子和设备间的张量流动构成的计算图。
以上流程对应拆解到框架分层,“隐语”对框架自下而上,进行了如下的设计及研发:
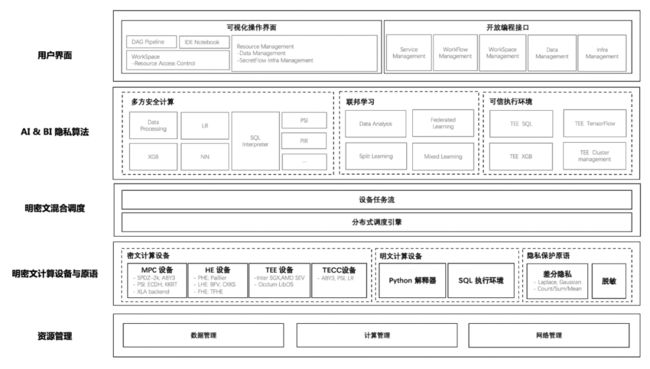
资源管理层:主要承担了两方面的职责。第一是面向业务交付团队,可以屏蔽不同机构底层基础设施的差异,降低业务交付团队的部署运维成本。另一方面,通过对不同机构的资源进行统一的调度和管理,解决了生产场景中的大规模和高可用问题。
明密文计算设备与原语层:提供了统一的可编程设备抽象,将多方安全计算(MPC)、同态加密(HE)、可信硬件(TEE)等隐私计算技术抽象为密态设备,将单方本地计算抽象为明文设备。同时,提供了一些不适合作为设备抽象的基础算法,如差分隐私(DP)、安全聚合(Secure Aggregation)等。未来当有新的密态计算技术出现时,可以通过这种松耦合的设计集成进隐私框架。
明密文混合调度层:这层一方面对上层提供了明密文混合编程的接口,同时也提供了统一的设备调度抽象。通过将上层算法描述为一张有向无环图,其中节点表示某个设备上的计算,边表示设备之间的数据流动,即逻辑计算图。然后由分布式框架进一步将逻辑计算图拆分并调度至物理节点。
AI & BI 隐私算法层:这一层的目的是屏蔽隐私计算技术细节,但保留隐私计算的本质,目的是降低隐私计算算法的开发门槛,提升开发效率。有隐私计算算法开发诉求的开发者,可以根据自身场景和业务的特点,设计出一些特化的隐私计算算法,来满足自身业务和场景对安全性、计算性能和计算精度的平衡。在这一层上,隐语本身也会提供一些通用的算法能力,比如 MPC 的 LR/XGB/NN,联邦学习算法,SQL 能力等。
用户界面层:隐语的目标并不是做一个端到端的产品,而是为了让不同的业务都能够通过快速集成隐语而具备全面的隐私计算能力。因此隐语会在最上层去提供一层比较薄的产品 API,以及一些原子化的前后端 SDK,去降低业务方集成隐语的成本。
![]()
以开放为核心 “隐语”致力于将开发者体验做到极致
总结隐语的架构分层,可以看出隐语框架始终围绕开放这一核心思想,通过不同层次的设计抽象,能够为不同类型的开发者都提供良好的开发体验:
设备层良好的设备接口和协议接口,支持更多的设备和协议插拔式的接入,对密码学、可信硬件、硬件加速等背景的开发者友好,利于不断扩展密态计算的类型和功能,不断提升协议的安全性和计算性能。
算法层为机器学习提供了灵活的编程接口,对算法开发者友好,他们可以像使用传统机器学习框架的方式去定义自己的算法。
那么在首个开源版本中,隐语已经开放了那些模块呢?支持的功能又有哪些?
 图:隐语框架V0.6开源模块
图:隐语框架V0.6开源模块
-
MPC设备
支持大部分 Numpy API,支持自动求导,提供 LR 和 NN 相关的 demo,支持pade 高精度定点数拟合算法,支持 ABY3、 Cheetah 协议。用户可以采用传统的算法编程模式,在不了解 MPC 协议的情况下开发出基于 MPC 协议的 AI 算法
-
HE设备
支持 Paillier 同态加密算法,向上层提供 Numpy 编程接口,用户可以使用 Numpy 接口做矩阵加法或者明密文矩阵乘法运算。且实现了与 MPC 密态设备之间的数据可流转。
-
差分隐私安全原语
实现了一些差分隐私噪声机制、安全噪声生成器、隐私开销计算器。
-
明密文混合编程
支持中心化编程模式,使用 @device 标记构建明文和密文设备混合计算图,基于计算图进行并行、异步任务调度。
-
数据预处理
提供水平场景下的数据标准化、离散化、分箱功能,提供垂直场景下的相关系数矩阵、WOE 分箱功能。无缝对接已有的 dataframe,提供和 sklearn 一致的使用体感。
-
AI & BI 隐私算法-多方安全计算
提供水平场景下的 XGBoost 算法、新增垂直场景下的 HESS-LR 算法,并结合差分隐私增强了对拆分学习的隐私保护。
-
AI & BI 隐私算法-联邦学习
提供联邦学习模型构建和包括 SecureAggregation,MPC Aggregation, 在内的多种安全模式的梯度聚合,用户只需要在模型构建时给出参与方 list 和聚合方法,之后的数据读取,预处理到模型训练的体验和传统明文编程几乎一致。
总结来看,主要如下:
对于算法/模型研发:使用隐语提供的编程能力,可以方便快捷地将更多算法和模型迁移过来,并得到隐私保护增强。
对于底层安全共建:可将底层密码/安全研究成果嵌入隐语,完善密态设备的能力、性能和安全,转化实际业务应用。
据隐语开源发布会消息,“隐语”也将在后续的开源版本更新中,逐步点亮更多模块。
![]()
到开发者中去,穿透技术壁垒练就“绝活”
回归这个现实问题,市面上的隐私计算框架有很多,比如 TFE,CrypTen,MP-SPDZ 等,因为现有无论是基于AI的框架(TFE/CrypTen),还是从安全计算出发的框架(SPDZ),都存在着一定的局限。前者往往难部署,难做安全领域特定的优化。后者往往会需要写一些 Toy AI 框架,学习成本高。
在“隐语”沉淀出的一整套“绝活”中,密态计算设备SPU是创新研发亮点之一。
SPU是 Secretflow Processing Unit 的简称,她作为隐语平台的密态计算单元,为隐语提供安全的计算服务:
近些年,密态计算(MPC/HE)在算力上都有巨大的进步,但是密态算力和 AI 的算法需求依然难以匹配。比如联邦学习,将算法的某一个子步骤使用安全计算实现,牺牲局部安全性以换取更高的性能。在算力无法匹配算法的时候,“隐语”的思路是“明密文混合”,来实现安全和性能的平衡。
隐语提供了非常自由的明密文混合编程范式,我们不限制明文的引擎,也不限制密文引擎,开发者可以用他自己熟悉的框架开发,然后标记其中的某一部分用明文引擎跑,另一部分用 SPU 跑。比如:
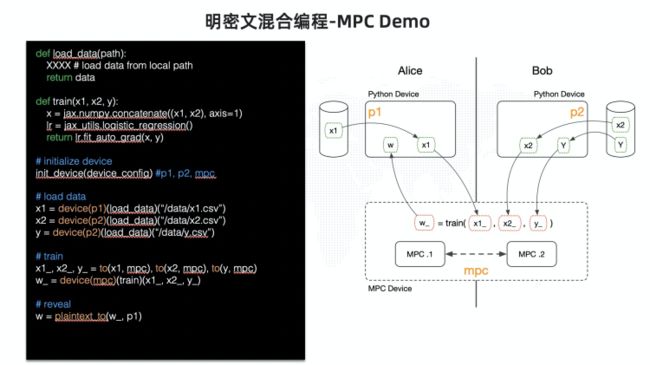 【注】图中MPC Device就是SPU实现的
【注】图中MPC Device就是SPU实现的
作为对比,从安全和性能这种的角度,无论 TFE/CrypTen/SPDZ 等都很难进行这种平衡。
此外,SPU 的部署模式透明,不用修改任何一行代码,既有模型都可以在上述任何一种部署场景上被安全且正确的执行。并且(相对于基于AI平台的隐私计算框架)SPU 运行时非常的轻量级,不需要 Python runtime,可以方便的进行部署和集成。
作为 AI 开发者,不需要任何安全背景,就可以将现有的模型安全的应用到多方数据上。
作为安全开发者,不需要任何 AI 背景,仅仅实现安全计算的基本算子,就可以支持多种前端框架。并且,你可以方便的部署和运维,在安全和性能之间折中,找到最佳的落地方案。
SPU 将 AI 前端和 MPC 后端解耦,使得在 SPU 中扩展的任何安全协议都可以无感的支持多种前端。这部分,已经有团队在“隐语”框架中取得了一些共建实现,如阿里安全双子座实验室将其 Cheetah(猎豹)协议部分贡献至隐语中,并进行了更好的优化。
另一个亮点是:目前业界最快的两方安全计算协议“猎豹”,贡献到了隐语,实现了深度协作。
当前业界的隐私计算需求场景以两方计算居多:Alice(数据需求方)希望借助Bob(数据源)的数据来增强自己的业务能力,但是 Bob 又不想直接给出自己的数据。因此如何高效的实现安全两方计算(2PC),便成为解决这一问题的关键。阿里安全双子座实验室为解决这一问题研发了 Cheetah(猎豹)安全两方计算框架,在 2PC 的多个底层瓶颈上都取得了突破,让两方计算的整体性能取得了大幅提升,最快可以比此前的最好成果-微软 CryptFLOW2(CCS20)提升5倍以上,已经被国际四大安全顶会之一的 USENIX Security Symposium 接收。
除了部分论文公开内容之外,猎豹已在“隐语”中实现了更好的优化(相较于公开代码支持 30-40 比特的秘密分享,猎豹在隐语中实现的是支持如 64 比特的更大秘密分享)以及一些未在论文中公开的算法。最重要的是这种实现对隐语上层业务逻辑无感知,即隐语已有逻辑代码无需改动以适配。
![]()
“隐语”开源社区的未来规划
“隐语”的逻辑设备抽象为算法开发者提供了极大的灵活性,他们可以像积木一样自由组合这些设备,在设备上自定义计算,从而构建自己的隐私计算算法。目前,“隐语” 开源采用 Apache-2.0,允许自由地下载和使用,不仅将在代码库中面向开发者逐步开放更多模块及功能,也已经在开发者文档中提供了一些隐私保护算法开发实例,如基于联邦学习的图片分类任务等,供开发者下载运行感受效果。
除了专注于技术本身,在框架的可编程性、可扩展性上做实现强化。“隐语”开源社区也正式成立,围绕开源社区,蚂蚁集团及隐语也将在多个方面与开发者、研究者联动共建隐私计算生态:
其一是通过多种渠道以文字、视频等多样的内容,普及隐私计算这一技术,通过开放的交流探讨增强与开发者的交流;
其二是联动高校科研等科研机构进行“线上授课”,形成产业视角与教学视角的结合,为开发者打造更多样的交流活动,沉淀体系化的隐私计算学习材料,公开分享,助力开发者个人成长;
除此之外,在隐语开源发布会上,蚂蚁集团宣布联合中国计算机学会(简称CCF)设立“CCF-蚂蚁隐私计算专项科研基金”,给予隐私计算研究者孵化支持,公开招募、评选、扶持有创新有价值的课题深度发展,支持隐私计算前沿研究。
即刻访问内容,基于隐语探索更多有趣的用法:
代码:
https://github.com/secretflow
文档:
SecretFlow:https://secretflow.readthedocs.io
SPU:https://spu.readthedocs.io
《新程序员001-004》已全面上市,欢迎扫描下方二维码或点击进入立即订阅,即可畅享电子书及精美纸质书
