MySQL进阶---约束、多表操作、视图、范式、备份与恢复
约束
1. 分类
对表中的数据进行限定,保证数据的正确性、有效性和完整性。
主键约束(Primary Key constraint):要求主键列数据唯一,并且不允许为空。
唯一约束(Unique constraint):要求该列唯一,允许为空,但只能出现一个空值。
检查约束(Check constraint):某列取值范围限制,格式限制等,如有关年龄、邮箱(必须有@)的约束。
默认约束(Default constraint):某列的默认值,如在数据库里有一项数据很多重复,可以设为默认值。
外键约束(Foreign Key constraint):用于在两个表之间建立关系,需要指定引用主表的哪一列。
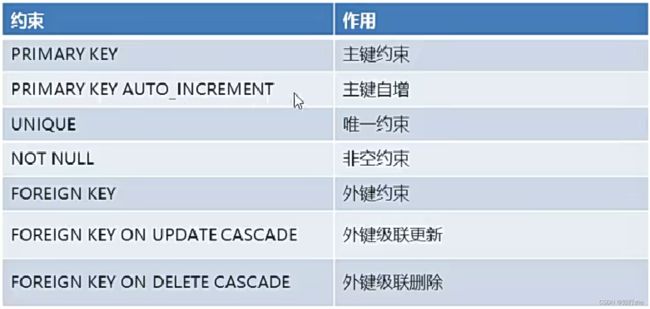
* 分类:
1. 主键约束:primary key
2. 非空约束:not null
3. 唯一约束:unique
4. 外键约束:foreign key
2. 主键约束
primary key,非空并且唯一,一张表只能有一个主键,主键是表的唯一标识
主键约束:primary key。
1. 注意:
1. 含义:非空且唯一
2. 一张表只能有一个字段为主键
3. 主键就是表中记录的唯一标识
2. 在创建表时,添加主键约束
create table stu(
id int primary key,-- 给id添加主键约束
name varchar(20)
);3. 删除主键
-- 错误 alter table stu modify id int ;
ALTER TABLE stu DROP PRIMARY KEY;4. 创建完表后,添加主键
ALTER TABLE stu MODIFY id INT PRIMARY KEY;主键是一个表中能标识唯一行的标志(也有其他方法表示唯一行,如唯一列)。
主键主要用在查询单调数据,修改单调数据和删除单调数据上。
3. 主键自动增长
1. 概念:如果某一列是数值类型的,使用 auto_increment 可以来完成值得自动增长
2. 在创建表时,添加主键约束,并且完成主键自增长
create table stu(
id int primary key auto_increment,-- 给id添加主键约束
name varchar(20)
); 3. 删除自动增长
ALTER TABLE stu MODIFY id INT;4. 添加自动增长
ALTER TABLE stu MODIFY id INT AUTO_INCREMENT;自增主键
这种方式是使用数据库提供的自增数值型字段作为自增主键,它的优点是:
(1)数据库自动编号,速度快,而且是增量增长,按顺序存放,对于检索非常有利;
(2)数字型,占用空间小,易排序,在程序中传递也方便;
(3)如果通过非系统增加记录时,可以不用指定该字段,不用担心主键重复问题。
其实它的缺点也就是来自其优点,缺点如下:
(1)因为自动增长,在手动要插入指定ID的记录时会显得麻烦,尤其是当系统与其它系统集成时,需要数据导入时,很难保证原系统的ID不发生主键冲突(前提是老系统也是数字型的)。特别是在新系统上线时,新旧系统并行存在,并且是异库异构的数据库的情况下,需要双向同步时,自增主键将是你的噩梦;
(2)在系统集成或割接时,如果新旧系统主键不同是数字型就会导致修改主键数据类型,这也会导致其它有外键关联的表的修改,后果同样很严重;
(3)若系统也是数字型的,在导入时,为了区分新老数据,可能想在老数据主键前统一加一个字符标识(例如“o”,old)来表示这是老数据,那么自动增长的数字型又面临一个挑战。
4. 唯一约束
* 唯一约束:unique,某一列的值不能重复
1. 注意:
* 唯一约束可以有NULL值,但是只能有一条记录为null
2. 在创建表时,添加唯一约束
CREATE TABLE stu(
id INT,
phone_number VARCHAR(20) UNIQUE -- 手机号
);
3. 删除唯一约束
ALTER TABLE stu DROP INDEX phone_number;4. 在表创建完后,添加唯一约束
ALTER TABLE stu MODIFY phone_number VARCHAR(20) UNIQUE;唯一约束在实际应用中,也要根据实际情况来进行使用。
例如:注册账户时需要用到手机号,每个手机号只能注册一个账号,这时就要用到唯一约束。
5. 非空约束
* 非空约束:not null,某一列的值不能为null
1. 创建表时添加约束
CREATE TABLE stu(
id INT,
NAME VARCHAR(20) NOT NULL -- name为非空
);2. 创建表完后,添加非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20) NOT NULL;3. 删除name的非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20);在实际应用中,根据实际情况来确定是否使用非空约束。
例如:注册用户时,用户名和密码必须不为null
6. 外键约束
* 外键约束:foreign key,让表于表产生关系,从而保证数据的正确性。
1. 在创建表时,可以添加外键
* 语法:
create table 表名(
....
外键列
constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称)
);
2. 删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
3. 创建表之后,添加外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称);
-- 外键约束
-- 用户表
create table user(
id int primary key auto_increment, -- id
name varchar(20) not null -- 姓名
);
-- 添加用户
insert into user values (1,'张三'),(2,'李四');
-- 订单表
create table orderlist(
id int primary key auto_increment, -- id
number varchar(20) not null, -- 订单编号
uid int, -- 外键列
constraint ou_fk1 foreign key (uid) references user(id)
);
-- 添加订单数据
-- 要user表中有id的用户才能成功添加
insert into orderlist values (null,'hm001',1),(null,'hm002',1),(null,'hm003',2),(null,'hm004',2);
-- 删除外键约束
alter table orderlist drop foreign key ou_fk1;
insert into orderlist values (null, 'hm005',3); -- user表无id为3的用户,orderlist表插入成功
-- 添加外键约束
-- 注意上方orderlist添加了有uid为3的数据,如果user表中没有id为3的则此时添加约束会失败,可以在user表添加id为3的数据后再添加约束
insert into user values (3,'王五');
alter table orderlist add constraint ou_fk1 foreign key (uid) references user(id);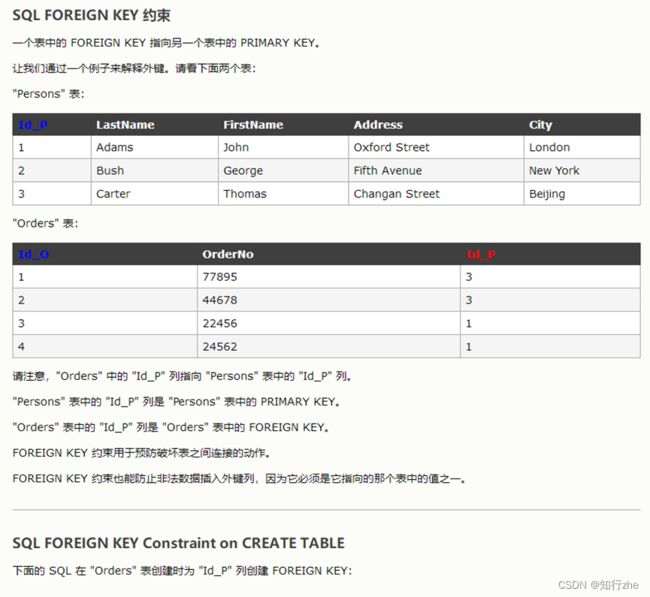 7. 外键级联操作
7. 外键级联操作
A表与B表有外键约束,A中有外键,B中数据改变时,A中的外键字段对应做出改变。
1. 添加级联操作
语法:ALTER TABLE 表名 ADD CONSTRAINT 外键名称
FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称) ON UPDATE CASCADE ON DELETE CASCADE ;
2. 分类:
1. 级联更新:ON UPDATE CASCADE
2. 级联删除:ON DELETE CASCADE
级联操作有四种类型:级联更新(合并),级联保存,级联刷新,和级联删除。
详情:现在分别介绍以上四种级联类型的详细情况。
1.CascadeType.REFRESH 级联刷新(使用场景,当我们从数据库中请求了一条数据,在我们对这条数据进行业务处理的时候,另一个用户可能会修改数据库中的这条数据的记录,那么此时我们就需要进行级联刷新了,否则我们处理的数据就失去了意义。)
2.CascadeType.PERSIST 级联持久化(比如在发出保存订单操作时,会同时发出保存订单项的操作语句) *订单和订单项之间是一对多的关系。
3.CascadeType.MERGE 级联合并 也就是级联更新(当处于游离状态下的对象被修改了,那么与他相关联的实体中的对象也会执行修改,如果开启了级联更新,那么此实体对象的更新会波及到与其关联的实体对象)
4.CascadeType.REMOVE 级联删除 (比如:如果设置了级联删除,当删除订单时,会同时删除对应的订单项,但是需要注意此操作的先后顺序为先删除订单项,再删除订单)
注:即使我们定义了级联操作,也只有在我们使用EntityManage 对象的api方法时才会生效。比如说当我们调用了refresh();方法时,级联刷新才会生效。当调用了remove()方法时,级联删除才会生效。而使用HQL语句进行删除,则不会触发级联删除操作。
多表操作
1. 概述
1. 分类:
1. 一对一(了解):
* 如:人和身份证
* 分析:一个人只有一个身份证,一个身份证只能对应一个人
2. 一对多(多对一):
* 如:部门和员工
* 分析:一个部门有多个员工,一个员工只能对应一个部门
3. 多对多:
* 如:学生和课程
* 分析:一个学生可以选择很多门课程,一个课程也可以被很多学生选择
2. 实现关系:
1. 一对多(多对一):
* 如:分类和商品
* 实现方式:在多的一方建立外键,指向一的一方的主键。
/*
商品分类和商品
*/
-- 创建category表
CREATE TABLE category(
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
NAME VARCHAR(10) -- 分类名称
);
-- 添加数据
INSERT INTO category VALUES (NULL,'手机数码'),(NULL,'电脑办公');
-- 创建product表
CREATE TABLE product(
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
NAME VARCHAR(30), -- 商品名称
cid INT, -- 外键列
CONSTRAINT pc_fk1 FOREIGN KEY (cid) REFERENCES category(id)
);
-- 添加数据
INSERT INTO product VALUES (NULL,'华为P30',1),(NULL,'小米note3',1),
(NULL,'联想电脑',2),(NULL,'苹果电脑',2);2. 多对多:
* 如:学生和课程
* 实现方式:多对多关系实现需要借助第三张中间表。中间表至少包含两个字段,这两个字段作为第三张表的外键,分别指向两张表的主键
-- 创建student表
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
NAME VARCHAR(20) -- 学生姓名
);
-- 添加数据
INSERT INTO student VALUES (NULL,'张三'),(NULL,'李四');
-- 创建course表
CREATE TABLE course(
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
NAME VARCHAR(10) -- 课程名称
);
-- 添加数据
INSERT INTO course VALUES (NULL,'语文'),(NULL,'数学');
-- 创建中间表
CREATE TABLE stu_course(
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
sid INT, -- 用于和student表中的id进行外键关联
cid INT, -- 用于和course表中的id进行外键关联
CONSTRAINT sc_fk1 FOREIGN KEY (sid) REFERENCES student(id), -- 添加外键约束
CONSTRAINT sc_fk2 FOREIGN KEY (cid) REFERENCES course(id) -- 添加外键约束
);
-- 添加数据
INSERT INTO stu_course VALUES (NULL,1,1),(NULL,1,2),(NULL,2,1),(NULL,2,2);3. 一对一(了解):
* 如:人和身份证
* 实现方式:一对一关系实现,可以在任意一方添加唯一外键指向另一方的主键。
-- 创建db3数据库
CREATE DATABASE db3;
-- 使用db3数据库
USE db3;
-- 创建person表
CREATE TABLE person(
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
NAME VARCHAR(20) -- 姓名
);
-- 添加数据
INSERT INTO person VALUES (NULL,'张三'),(NULL,'李四');
-- 创建card表
CREATE TABLE card(
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
number VARCHAR(20) UNIQUE NOT NULL, -- 身份证号
pid INT UNIQUE, -- 外键列
CONSTRAINT cp_fk1 FOREIGN KEY (pid) REFERENCES person(id)
);
-- 添加数据
INSERT INTO card VALUES (NULL,'12345',1),(NULL,'56789',2);2. 多表查询
1. 分类
内连接查询
外连接查询
子查询
自关联查询
2. 内连接查询
查询原理
内连接查询的是两张表有交集的部分数据(在主外键关联的数据)
查询语法:
显式内连接
SELECT 列名 FROM 表名1 [INNFR] JOIN 表名2 ON 条件;
隐式内连接
SELECT 列名 FROM 表名1,表名2 WHERE 条件;
/*
显示内连接
标准语法:
SELECT 列名 FROM 表名1 [INNER] JOIN 表名2 ON 关联条件;
*/
-- 查询用户信息和对应的订单信息
SELECT * FROM USER INNER JOIN orderlist ON orderlist.uid = user.id;
-- 查询用户信息和对应的订单信息,起别名
SELECT * FROM USER u INNER JOIN orderlist o ON o.uid=u.id;
-- 查询用户姓名,年龄。和订单编号
SELECT
u.name, -- 用户姓名
u.age, -- 用户年龄
o.number -- 订单编号
FROM
USER u -- 用户表
INNER JOIN
orderlist o -- 订单表
ON
o.uid=u.id;
/*
隐式内连接
标准语法:
SELECT 列名 FROM 表名1,表名2 WHERE 关联条件;
*/
-- 查询用户姓名,年龄。和订单编号
SELECT
u.name, -- 用户姓名
u.age, -- 用户年龄
o.number -- 订单编号
FROM
USER u, -- 用户表
orderlist o -- 订单表
WHERE
o.uid=u.id;
3. 外连接查询
1. 左外连接
查询原理
查询左表的全部数据,和左右两张表有交集部分的数据
查询语法:
SELECT 列名 FROM 表名1 LEFT [OUTER] JOIN 表名2 ON 条件;
2. 右外连接
查询原理
查询右表的全部数据,和左右两张表有交集部分的数据
查询语法:
SELECT 列名 FROM 表名1 RIGHT [OUTER] JOIN 表名2 ON 条件;
/*
左外连接
标准语法:
SELECT 列名 FROM 表名1 LEFT [OUTER] JOIN 表名2 ON 条件;
*/
-- 查询所有用户信息,以及用户对应的订单信息
SELECT
u.*,
o.number
FROM
USER u
LEFT OUTER JOIN
orderlist o
ON
o.uid=u.id;
/*
右外连接
标准语法:
SELECT 列名 FROM 表名1 RIGHT [OUTER] JOIN 表名2 ON 条件;
*/
-- 查询所有订单信息,以及订单所属的用户信息
SELECT
o.*,
u.name
FROM
USER u
RIGHT OUTER JOIN
orderlist o
ON
o.uid=u.id;4. 子查询
概念:查询语句中嵌套的查询语句,我们就将嵌套的查询称为子查询。
结果是多行单列的
查询作用
可以将查询的结果作为另一条语句的查询条件,使用运算符= > >= < <=等判断
查询语法
SELECT 列名 FROM 表名 WHERE 列名=(SELECT 列名 FROM 表名 [WHERE 条件]);
结果是多行单列的
查询作用
可以作为条件,使用运算符 IN 和 NOT IN进行判断
查询语法
SELECT 列名 FROM 表名 WHERE 列名 [NOT] IN (SELECT 列名 FROM 表名 [WHERE 条件]);
结果是多行单列的
查询作用
查询的结果可以作为一张虚拟表参与查询
查询语法
SELECT 列名 FROM 表名 别名, (SELECT 列名 FROM 表名 [WHERE 条件]) [别名] [WHERE 条件];
/*
结果是单行单列的
标准语法:
SELECT 列名 FROM 表名 WHERE 列名=(SELECT 列名 FROM 表名 [WHERE 条件]);
*/
-- 查询年龄最高的用户姓名
SELECT MAX(age) FROM USER;
-- 注意SELECT NAME,MAX(age) FROM USER;的写法中,除了聚合函数,其他字段显示的都是表的第一行数据
SELECT NAME,age FROM USER WHERE age=(SELECT MAX(age) FROM USER);
/*
结果是多行单列的
标准语法:
SELECT 列名 FROM 表名 WHERE 列名 [NOT] IN (SELECT 列名 FROM 表名 [WHERE 条件]);
*/
-- 查询张三和李四的订单信息
SELECT * FROM orderlist WHERE uid IN (1,2);
SELECT id FROM USER WHERE NAME IN ('张三','李四');
SELECT * FROM orderlist WHERE uid IN (SELECT id FROM USER WHERE NAME IN ('张三','李四'));
/*
结果是多行多列的
标准语法:
SELECT 列名 FROM 表名 [别名],(SELECT 列名 FROM 表名 [WHERE 条件]) [别名] [WHERE 条件];
*/
-- 查询订单表中id大于4的订单信息和所属用户信息
SELECT * FROM orderlist WHERE id > 4;
SELECT
u.name,
o.number
FROM
USER u,
(SELECT * FROM orderlist WHERE id > 4) o
WHERE
o.uid=u.id;这里的子查询可以把要求的语句先拆分小的子查询语句,然后再整合
5. 自关联查询
在同一张表中数据有关联性,我们可以把这张表当成多个表来查询。
-- 创建员工表
CREATE TABLE employee(
id INT PRIMARY KEY AUTO_INCREMENT, -- 员工编号
NAME VARCHAR(20), -- 员工姓名
mgr INT, -- 上级编号
salary DOUBLE -- 员工工资
);
-- 添加数据
INSERT INTO employee VALUES (1001,'孙悟空',1005,9000.00),
(1002,'猪八戒',1005,8000.00),
(1003,'沙和尚',1005,8500.00),
(1004,'小白龙',1005,7900.00),
(1005,'唐僧',NULL,15000.00),
(1006,'武松',1009,7600.00),
(1007,'李逵',1009,7400.00),
(1008,'林冲',1009,8100.00),
(1009,'宋江',NULL,16000.00);
-- 查询所有员工的姓名及其直接上级的姓名,没有上级的员工也需要查询
/*
分析
员工信息 employee表
条件:employee.mgr = employee.id
查询左表的全部数据,和左右两张表有交集部分数据,左外连接
*/
SELECT
e1.id,
e1.name,
e1.mgr,
e2.id,
e2.name
FROM
employee e1
LEFT OUTER JOIN
employee e2
ON
e1.mgr = e2.id;视图
1. 概述
视图:是种虚拟存在的数据表,这个虚拟表并不在数据库中实际存在。
作用:将一些较为复杂的查询语句的结果,封装到一个虚拟表中,后期再有相同需求时,直接查询该虚拟表即可。
2. 视图的创建与查询
创建视图语法:
CREATE VIEW 视图名称 [(列名列表)] AS 查询语句;
查询视图语法:
SELECT * FROM 视图名称;
/*
创建视图
标准语法
CREATE VIEW 视图名称 [(列名列表)] AS 查询语句;
*/
-- 创建city_country视图,保存城市和国家的信息(使用指定列名)
CREATE VIEW city_country (city_id,city_name,country_name) AS
SELECT
c1.id,
c1.name,
c2.name
FROM
city c1,
country c2
WHERE
c1.cid=c2.id;
/*
查询视图
标准语法
SELECT * FROM 视图名称;
*/
-- 查询视图
SELECT * FROM city_country;2. 视图的修改与删除
修改视图数据语法:
UPDATE 视图名称 SET 列名=值 WHERE 条件;
修改视图结构语法:
ALTER VIEW 视图名称 (列名列表) AS 查询语句;
删除视图语法:
DROP VIEW [IF EXISTS] 视图名称;
/*
修改视图数据
标准语法
UPDATE 视图名称 SET 列名=值 WHERE 条件;
修改视图结构
标准语法
ALTER VIEW 视图名称 (列名列表) AS 查询语句;
*/
-- 修改视图数据,将北京修改为深圳。(注意:修改视图数据后,源表中的数据也会随之修改)
SELECT * FROM city_country;
UPDATE city_country SET city_name='深圳' WHERE city_name='北京';
-- 将视图中的country_name修改为name
ALTER VIEW city_country (city_id,city_name,NAME) AS
SELECT
c1.id,
c1.name,
c2.name
FROM
city c1,
country c2
WHERE
c1.cid=c2.id;
/*
删除视图
标准语法
DROP VIEW [IF EXISTS] 视图名称;
*/
-- 删除city_country视图
DROP VIEW IF EXISTS city_country;范式
1. 概述
设计数据库时,需要遵循的一些规范。要遵循后边的范式要求,必须先遵循前边的所有范式要求
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。
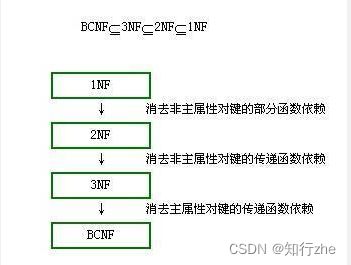
第一范式目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行。
2. 三大范式详解
1. 第一范式(1NF):每一列都是不可分割的原子数据项
2. 第二范式(2NF):在1NF的基础上,非码属性必须完全依赖于码(在1NF基础上消除非主属性对主码的部分函数依赖)
* 几个概念:
1. 函数依赖:A-->B,如果通过A属性(属性组)的值,可以确定唯一B属性的值。则称B依赖于A
例如:学号-->姓名。 (学号,课程名称) --> 分数
2. 完全函数依赖:A-->B, 如果A是一个属性组,则B属性值得确定需要依赖于A属性组中所有的属性值。
例如:(学号,课程名称) --> 分数
3. 部分函数依赖:A-->B, 如果A是一个属性组,则B属性值得确定只需要依赖于A属性组中某一些值即可。
例如:(学号,课程名称) -- > 姓名
4. 传递函数依赖:A-->B, B -- >C . 如果通过A属性(属性组)的值,可以确定唯一B属性的值,在通过B属性(属性组)的值可以确定唯一C属性的值,则称 C 传递函数依赖于A
例如:学号-->系名,系名-->系主任
5. 码:如果在一张表中,一个属性或属性组,被其他所有属性所完全依赖,则称这个属性(属性组)为该表的码
例如:该表中码为:(学号,课程名称)
* 主属性:码属性组中的所有属性
* 非主属性:除过码属性组的属性
3. 第三范式(3NF):在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
数据库的备份与恢复
为了数据库中数据的安全,例如误删数据库或者表及表数据,造成数据丢失等问题,所以要进行数据库的备份和还原。
1. 命令行方式
1. 备份
登录到MySQL服务器,输入:mysqldump -u root -p 数据库名称 > 文件保存路径
2. 恢复
1.登录MySQL数据库。
2.删除已备份的数据库。
3.重新创建名称相同的数据库。
4.使用该数据库。
5.导入文件执行:source备份文件全路径。
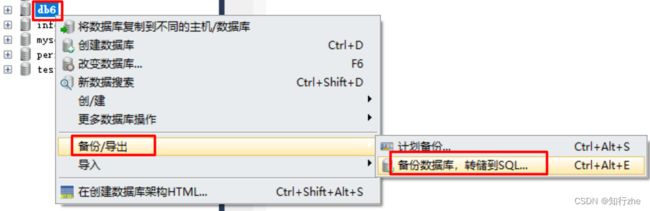
2. 图形化方式
1. 备份
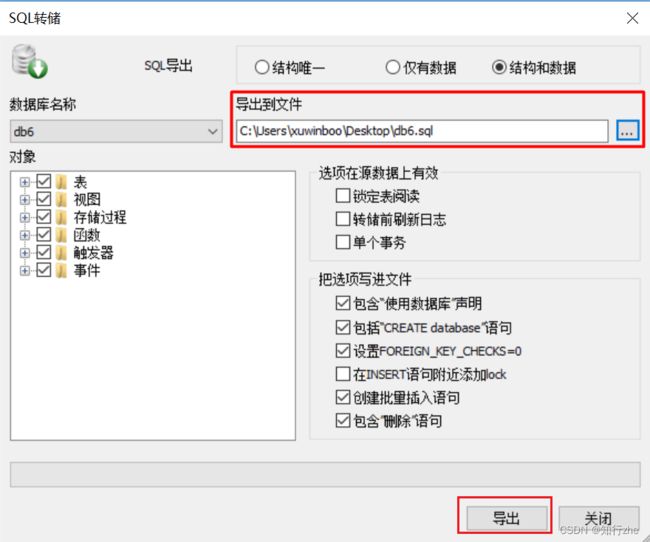
2. 恢复
-- 删除db6数据库
drop database db6;
-- 创建db6数据库
creat database db6;


