mybatis之执行sql语句
写在前面
通过这篇文章的分析,已经生成了可以执行的sql语句了,本文来分析SQL语句具体的执行过程。
想要系统学习的,可以参考这篇文章,重要!!!。
入口
当我们执行一次数据查询的时候,mybatis会通过org.apache.ibatis.executor.Executor的API完成调用,其中接口源码如下:
public interface Executor {
ResultHandler NO_RESULT_HANDLER = null;
// 更新操作
int update(MappedStatement ms, Object parameter) throws SQLException;
// 查询
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey cacheKey, BoundSql boundSql) throws SQLException;
// 查询
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException;
List<BatchResult> flushStatements() throws SQLException;
// 提交事务
void commit(boolean required) throws SQLException;
// 回滚事务
void rollback(boolean required) throws SQLException;
CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql);
// 是否已经缓存
boolean isCached(MappedStatement ms, CacheKey key);
// 清空本地缓存
void clearLocalCache();
// 延迟加载
void deferLoad(MappedStatement ms, MetaObject resultObject, String property, CacheKey key, Class<?> targetType);
// 获取事务对象
Transaction getTransaction();
void close(boolean forceRollback);
boolean isClosed();
void setExecutorWrapper(Executor executor);
}
这个也是我们的入口类。具体参考1:CachingExecutor。
1:CachingExecutor
关于执行器,详细可以参考这篇文章。
CachingExecutor是org.apache.ibatis.executor.Executor的子类,这里我们分为查询和更新两种情况来进行分析,不管哪种情况执行的入口都是在CachingExecutor类中。关于查询的场景,参考1.1:查询场景分析,关于更新的场景,参考1.2:更新场景分析。
1.1:查询场景分析
假设有如下的配置:
<select id="getByQueryParamter" resultMap="myResultMap">
select * from test_mapper_sql2222 where id=#{id}
select>
源码如下:
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 通过MappedStatement获取BoundSql对象,这是一个封装sql和相关参数等信息的对象
// <2021-08-19 17:31:53>
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 创建CacheKey,用于后续查询的缓存工作
// <2021-08-19 17:38:37>
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
// 2021-08-20 13:43:18
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
<2021-08-19 17:31:53>处是通过MappedStatement获取BoundSql对象,具体可以参考这篇文章。如下图是一个可能的结果:
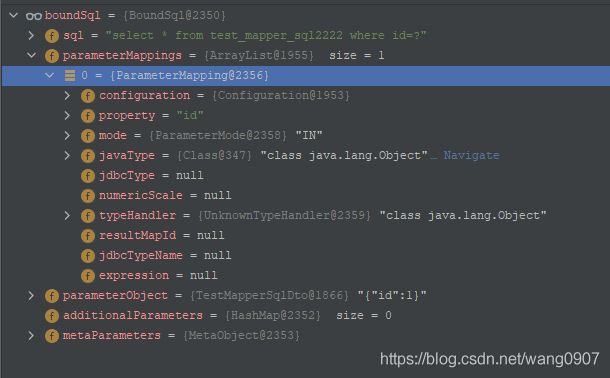
<2021-08-19 17:38:37>处是创建缓存键,具体参考1.1.1:创建缓存key。2021-08-20 13:43:18处是通过带有缓存逻辑的查询方法查询数据,具体参考1.1.3:查询数据。
1.1.1:创建缓存key
源码如下:
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
// 2021-08-19 17:38:37
return delegate.createCacheKey(ms, parameterObject, rowBounds, boundSql);
}
2021-08-19 17:38:37处源码如下:
org.apache.ibatis.executor.BaseExecutor#createCacheKey
// ms: 当前执行的statement对应的对象
// parameterObject:当前执行的statemnet中的SQL语句参数信息
// rowBounds:查询偏移量和查询数量对象,默认offset->0,limit->2147483647,可以认为是不限制
// boundSql:封装要执行的sql语句以及其需要的参数等信息的对象
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) throw new ExecutorException("Executor was closed.");
CacheKey cacheKey = new CacheKey();
// 添加需要作为缓存键的信息到CacheKey中
// 如下是一个可能的toString CacheKey的结果:
// 61930333:1684626551:yudaosourcecode.mybatis.mapper.TestMapperSqlMapper.getByQueryParamter:0:2147483647:select * from test_mapper_sql2222 where id=?
// 2021-08-19 17:55:38
// 添加当前statement的id到CacheKey中,作为缓存键的一部分
cacheKey.update(ms.getId());
// 添加偏移量到CacheKey中,作为缓存键的一部分
cacheKey.update(rowBounds.getOffset());
// 添加limit到CacheKey中,作为缓存键的一部分
cacheKey.update(rowBounds.getLimit());
// 添加当前的sql语句到CacheKey中,作为缓存键的一部分
cacheKey.update(boundSql.getSql());
// 获取参数映射
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
// 获取类型处理器的注册器
// 会注册“数据库类型->Java类型”类型处理器信息,也会注册"java类型->数据库类型"类型处理器信息
// 在向数据库写入数据,或者是从数据库读取数据时会使用相关的组合key获取对应的类型处理器
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// 循环遍历所有的参数对象信息,获取参数值,更新的cacheKey对象中,作为缓存键的一部分
for (int i = 0; i < parameterMappings.size(); i++) {
// 当前的参数信息
ParameterMapping parameterMapping = parameterMappings.get(i);
// 非OUT类型参数才处理
if (parameterMapping.getMode() != ParameterMode.OUT) {
// 当前参数的值
Object value;
// 获取当前参数#{xxx}中的属性名称
String propertyName = parameterMapping.getProperty();
// 如果是在额外自动生成参数中包含当前属性,则优先从其获取
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
// 如果是没有用户传入参数,则赋值为null
} else if (parameterObject == null) {
// 赋值为null
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
// 获取传入参数值,一般走这里的逻辑
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
// 将当前值更新到cacheKey中,作为缓存键的一部分,用于后续的缓存工作
cacheKey.update(value);
}
}
// 返回缓存key
return cacheKey;
}
2021-08-19 17:55:38处通过update方法添加缓存键信息到CacheKey中,具体参考1.1.2:添加CacheKey的缓存键信息。
1.1.2:添加CacheKey的缓存键信息
源码如下:
org.apache.ibatis.cache.CacheKey#update
public void update(Object object) {
// 如果是数组,则循环每个元素处理
if (object != null && object.getClass().isArray()) {
int length = Array.getLength(object);
for (int i = 0; i < length; i++) {
Object element = Array.get(object, i);
doUpdate(element);
}
} else {
// 2021-08-19 17:57:59
doUpdate(object);
}
}
2021-08-19 17:57:59处是更新相关属性,以便影响最终生成缓存键,源码如下:
org.apache.ibatis.cache.CacheKey#doUpdate
private void doUpdate(Object object) {
// 计算缓存键相关内容
int baseHashCode = object == null ? 1 : object.hashCode();
count++;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;
// 添加当前值到缓存键的集合中,最终会循环该集合生成键值,参考如下toString:
/*
public String toString() {
StringBuilder returnValue = new StringBuilder().append(hashcode).append(':').append(checksum);
for (int i = 0; i < updateList.size(); i++) {
returnValue.append(':').append(updateList.get(i));
}
return returnValue.toString();
}
*/
updateList.add(object);
}
1.1.3:查询数据
源码如下:
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 获取二级缓存org.apache.ibatis.cache.Cache
// 2021-08-20 13:50:45
Cache cache = ms.getCache();
// 如果是配置了二级缓存
if (cache != null) {
// 必要时刷新缓存
// 2021-08-20 13:56:32
flushCacheIfRequired(ms);
// ms.isUseCache():对应的是xml中userCache配置,或者是注解中@Options(useCache = false)
// 配置的值,默认为false
// resultHandler:查询一般为null
// 如果最终结果为true,则从二级缓存中获取数据
if (ms.isUseCache() && resultHandler == null) {
// 检查存储过程是否包含参数类型为OUT的参数
// 2021-08-20 14:23:07
ensureNoOutParams(ms, parameterObject, boundSql);
// 从二级缓存中获取结果
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
// 如果是二级缓存中没有,则直接查询
if (list == null) {
// 调用数据库查询数据库
// 2021-08-20 15:17:44
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list);
}
return list;
}
}
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
2021-08-20 13:50:45处是获取配置二级缓存对象org.apache.ibatis.cache.Cache,配置的的方式是在mapper xml中配置
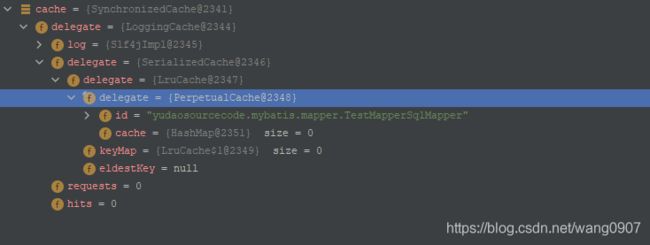
2021-08-20 13:56:32处是必要时进行刷新缓存的操作,源码如下:
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
// 缓存对象不为null,并且配置了刷新缓存则刷新
// 这里ms.isFlushCacheRequired()的值获取的是statement中flushCache属性配置的值
// 默认是false,即不刷新缓存,注解形式大概为"@Options(flushCache = Options.FlushCachePolicy.TRUE)"
if (cache != null && ms.isFlushCacheRequired()) {
// 清空缓存,因为二级缓存是跨SqlSession的,因此在本事务提交前影响的清空的仅仅是本事务
// 产生的缓存数据,不会影响已产生的缓存,只有在事务提交时才会真正的清空当前命名空间的缓存
tcm.clear(cache);
}
}
2021-08-20 14:23:07处是判断当为存储过程时是否包含类型为OUT的参数,源码如下:
private void ensureNoOutParams(MappedStatement ms, Object parameter, BoundSql boundSql) {
// 存储过程才继续判断
if (ms.getStatementType() == StatementType.CALLABLE) {
// 遍历所有的参数
for (ParameterMapping parameterMapping : boundSql.getParameterMappings()) {
// 一旦发现不是IN的则直接异常,这里异常的原因是,数据库的出参是不确定的,
// 所以没有办法进行缓存,或者说已经查询过了再去缓存也没有任何意义
if (parameterMapping.getMode() != ParameterMode.IN) {
throw new ExecutorException("Caching stored procedures with OUT params is not supported. Please configure useCache=false in " + ms.getId() + " statement.");
}
}
}
}
2021-08-20 15:17:4处是通过数据库查询数据,具体参考1.1.4:通过数据库查询数据。
1.1.4:通过数据库查询数据
源码如下:
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// 创建ErroContext对象并链式调用方法设置相关信息
// resource:maper 路径信息
// ms.getId():statement的id属性值
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
// 执行器已经关闭,则异常
if (closed) throw new ExecutorException("Executor was closed.");
// 如果是queryStack为0,并且ms.isFlushCacheRequired()为true,
// 该参数通过statement中flushCache设置,或者是注解中的@Options(flushCache = Options.FlushCachePolicy.TRUE)设置,默认为false,即使用缓存
if (queryStack == 0 && ms.isFlushCacheRequired()) {
// 清空缓存
// 2021-08-20 15:34:43
clearLocalCache();
}
// 结果
List<E> list;
try {
queryStack++;
// 从一级缓存中获取
// 比如我这里的key:-2003544970:1684626552:yudaosourcecode.mybatis.mapper.TestMapperSqlMapper.getByQueryParamter:0:2147483647:select * from test_mapper_sql2222 where id=?:1
// protected PerpetualCache localCache;
// 构造函数初始化:this.localCache = new PerpetualCache("LocalCache");
// 到这里才从一级缓存中查询可以看出,二级缓存的优先级是高于一级缓存的
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
// 如果是一级缓存中有
if (list != null) {
// 处理存储过程相关内容,可以忽略
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 一级缓存中没有,从数据库查询
// 2021-08-20 15:52:10
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear(); // issue #601
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache(); // issue #482
}
}
return list;
}
2021-08-20 15:34:43处是清空本地的一级缓存,源码如下:
org.apache.ibatis.executor.BaseExecutor#clearLocalCache
public void clearLocalCache() {
if (!closed) {
// 清空一级缓存localCache
// protected PerpetualCache localCache;
// 构造函数赋值:this.localCache = new PerpetualCache("LocalCache");
localCache.clear();
// 清空一级缓存localOutputParameterCache
localOutputParameterCache.clear();
}
}
2021-08-20 15:52:10处是真正的从数据库中查询数据,具体参考1.1.5:真正的从数据库查询数据。
1.1.5:真正的从数据库查询数据
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 一级缓存中添加占位符枚举对象,这样做是和延迟加载相关
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 查询数据
// 2021-08-20 16:00:02
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
// 查询过程中发生了异常则删除缓存key
localCache.removeObject(key);
}
// 将查询结果放到一级缓存中
localCache.putObject(key, list);
// 存储过程时,忽略
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
2021-08-20 16:00:02处源码如下:
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
// java.sql.Statement,JDBC的API
Statement stmt = null;
try {
// 获取全局配置文件对应的org.apache.ibatis.session.Configuration对象
Configuration configuration = ms.getConfiguration();
// 通过全局配置文件的configuration对象创建StatementHanlder对象,该对象负责利用JDBC的API执行数据库查询
// 2021-08-20 16:15:42
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 获取Statement
// 2021-08-20 17:10:32
stmt = prepareStatement(handler, ms.getStatementLog());
// 从数据库查询数据
// 2021-08-20 18:03:16
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
2021-08-20 16:15:42处是创建StatementHandler,具体参考2.1:通过configuration创建StatementHandler。
2021-08-20 17:10:32处是获取Statement,源码如下:
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
// 获取JDBC的连接对象
Connection connection = getConnection(statementLog);
// 创建Statement
// 2021-08-20 17:17:27
stmt = handler.prepare(connection);
// 设置statement的参数
// 2021-08-20 17:35:52
handler.parameterize(stmt);
return stmt;
}
2021-08-20 17:17:27处是创建Statement,具体参考2.2:prepare方法生成Statement。2021-08-20 17:35:52处是设置statement的参数,具体参考2.3:parameterize设置参数信息。2021-08-20 18:03:16处是真真正正的从数据库查询数据,具体参考1.1.6:真真正正的从数据库查询数据。
1.1.6:真真正正的从数据库查询数据
源码如下:
org.apache.ibatis.executor.statement.RoutingStatementHandler#query
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
// 通过代理类查询数据,如果是statementType="PREPARED",则这里就是PreparedStatementHandler
// 2021-08-20 18:05:56
return delegate.<E>query(statement, resultHandler);
}
2021-08-20 18:05:56处源码如下:
org.apache.ibatis.executor.statement.PreparedStatementHandler#query
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
// 强转为PreparedStatement
PreparedStatement ps = (PreparedStatement) statement;
// 执行查询,此时ps中就已经有数据了
ps.execute();
// 使用ResultSetHandler处理查询结果集
// 2021-08-20 18:09:17
return resultSetHandler.<E> handleResultSets(ps);
}
2021-08-20 18:09:17处是使用ResultSetHandler处理结果集并返回,具体参考4.1:handleResultSets处理结果集。
1.2:更新场景分析
如下的mapper xml:
<parameterMap id="myParameterMap" type="yudaosourcecode.mybatis.dto.TestResultmapCollectionManyDto">
<parameter property="id" javaType="integer" jdbcType="INTEGER"/>
<parameter property="manyname" javaType="string" jdbcType="VARCHAR"/>
<parameter property="manynage" javaType="integer" jdbcType="INTEGER"/>
<parameter property="oneid" javaType="integer" jdbcType="INTEGER"/>
parameterMap>
<insert id="insertByQueryParamter" parameterMap="myParameterMap">
INSERTINTO `test_resultmap_collection_many`
(`manyname`,
`manyage`,
`oneid`)
VALUES (#{manyname},
#{manyage},
#{oneid})
insert>
当我们执行插入的时候,首先会通过会话对象org.apache.ibatis.session.SqlSession对象执行操作,具体调用的是org.apache.ibatis.session.DefaultSqlSession#insert(String statement, Object parameter)方法,我们就从这里开始分析吧,源码如下:
org.apache.ibatis.session.defaults.DefaultSqlSession#insert(java.lang.String, java.lang.Object)
public int insert(String statement, Object parameter) {
// 2021-08-27 16:28:51
return update(statement, parameter);
}
2021-08-27 16:28:51调用更新方法插入也是一种更新,源码如下:
org.apache.ibatis.session.defaults.DefaultSqlSession#update(java.lang.String, java.lang.Object)
public int update(String statement, Object parameter) {
try {
dirty = true;
//根据statement的id获取对应的MappedStatement对象
MappedStatement ms = configuration.getMappedStatement(statement);
// 通过执行器更新
// 2021-08-27 16:39:44
return executor.update(ms, wrapCollection(parameter));
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error updating database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
2021-08-27 16:39:44处是通过执行器org.apache.ibatis.executor.Executor,执行更新,具体参考1.2.1:通过执行器执行更新操作。
1.2.1:通过执行器执行更新操作
源码如下:
org.apache.ibatis.executor.CachingExecutor#update
public int update(MappedStatement ms, Object parameterObject) throws SQLException {
// 刷新缓存如果需要的话,具体在本文搜索"2021-08-20 13:56:32"查看
flushCacheIfRequired(ms);
// 通过代理执行器类执行更新
// 2021-08-27 16:43:41
return delegate.update(ms, parameterObject);
}
2021-08-27 16:43:41处源码如下:
org.apache.ibatis.executor.BaseExecutor#update
public int update(MappedStatement ms, Object parameter) throws SQLException {
// 创建ErrorContext,并通过构造器方式设置相关需要的属性
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
// 检测处理器是否关闭
if (closed) throw new ExecutorException("Executor was closed.");
// 更新操作,默认清空一级缓存信息
clearLocalCache();
// 执行更新
// 2021-08-27 17:17:34
return doUpdate(ms, parameter);
}
2021-08-27 17:17:34处是执行更新,具体参考1.2.2:执行更新。
1.2.2:执行更新
源码如下:
org.apache.ibatis.executor.SimpleExecutor#doUpdate
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
Statement stmt = null;
try {
// 获取全局配置文件对应的Configuration对象
Configuration configuration = ms.getConfiguration();
// 创建StatementHandler,这里创建的是RoutingStatementHandler
StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, null, null);
// 准备JDBC的Statement对象
stmt = prepareStatement(handler, ms.getStatementLog());
// statement处理器使用JDBC的Statement执行更新
// 2021-08-27 17:38:20
return handler.update(stmt);
} finally {
closeStatement(stmt);
}
}
2021-08-27 17:38:20处是使用statement处理器执行更新,具体参考1.2.3:使用statement处理器执行更新。
1.2.3:使用statement处理器执行更新
源码如下:
org.apache.ibatis.executor.statement.RoutingStatementHandler#update
public int update(Statement statement) throws SQLException {
// 2021-08-27 17:40:28
return delegate.update(statement);
}
2021-08-27 17:40:28处delagate源码如下:
org.apache.ibatis.executor.statement.PreparedStatementHandler#update
public int update(Statement statement) throws SQLException {
// 强转为java.sql.PreparedStatement
PreparedStatement ps = (PreparedStatement) statement;
// 执行更新!!!
ps.execute();
// 获取影响的行数
int rows = ps.getUpdateCount();
// 通过org.apache.ibatis.mapping.BoundSql获取传入的参数对象
Object parameterObject = boundSql.getParameterObject();
// 获取主键生成对象TODO
KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();
// 通过主键生成器KeyGenerator生成主键值并设置到传入实体中
// 2021-08-28 09:33:22
keyGenerator.processAfter(executor, mappedStatement, ps, parameterObject);
return rows;
}
2021-08-28 09:33:22处是通过主键生成器org.apache.ibattis.executor.keygen.KeyGenerator,生成主键,具体参考这篇文章。
2:StatementHandler
对应接口为org.apche.ibatis.executor.statement.StatementHandler,源码如下:
org.apache.ibatis.executor.statement.StatementHandler
public interface StatementHandler {
// 准备操作,可理解为创建JDBC的Statement
Statement prepare(Connection connection)
throws SQLException;
// 设置JDBC的Statment对应的参数
void parameterize(Statement statement)
throws SQLException;
// 设置JDBC的Statement的批量操作
void batch(Statement statement)
throws SQLException;
// 更新操作
int update(Statement statement)
throws SQLException;
// 查询操作
<E> List<E> query(Statement statement, ResultHandler resultHandler)
throws SQLException;
// 获取BoundSql对象
BoundSql getBoundSql();
// 获取用于处理参数的参数处理器
ParameterHandler getParameterHandler();
}
主要实现类如下图:

2.1:通过configuration创建StatementHandler
源码如下:
org.apache.ibatis.session.Configuration#newStatementHandler
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// 构造函数创建对象
// 2021-08-20 16:24:49
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
// 应用插件,关于插件,暂时忽略
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
// 返回statementhandler
return statementHandler;
}
2021-08-20 16:24:49处源码如下:
private final StatementHandler delegate;
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// 装饰器设置模式,动态设置被装饰类为对应的StatementHandler
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
2.2:prepare方法生成Statement
源码如下:
org.apache.ibatis.executor.statement.BaseStatementHandler#prepare
public Statement prepare(Connection connection) throws SQLException {
// 创建ErrorContext实例,并设置当前执行的sql信息
ErrorContext.instance().sql(boundSql.getSql());
// 结果
Statement statement = null;
try {
// 初始化Statement
// 2021-08-20 17:19:23
statement = instantiateStatement(connection);
// 设置超时时长
// 2021-08-20 17:30:07
setStatementTimeout(statement);
// 设置每次获取数据量
// 2021-08-20 17:32:07
setFetchSize(statement);
return statement;
} catch (SQLException e) {
closeStatement(statement);
throw e;
} catch (Exception e) {
closeStatement(statement);
throw new ExecutorException("Error preparing statement. Cause: " + e, e);
}
}
2021-08-20 17:19:23处是初始化statement,具体参考2.2.1:初始化Statement,2021-08-20 17:30:07处是设置Statement的超时时长,源码如下:
protected void setStatementTimeout(Statement stmt) throws SQLException {
// 分别获取statement中配置的超时时长,和全局配置文件中配置的超时时长,并分别设置
Integer timeout = mappedStatement.getTimeout();
Integer defaultTimeout = configuration.getDefaultStatementTimeout();
if (timeout != null) {
stmt.setQueryTimeout(timeout);
} else if (defaultTimeout != null) {
stmt.setQueryTimeout(defaultTimeout);
}
}
2021-08-20 17:32:07处是设置fetcheSize,源码如下:
protected void setFetchSize(Statement stmt) throws SQLException {
// 获取statement中配置的fetchSize,并进行设置
Integer fetchSize = mappedStatement.getFetchSize();
if (fetchSize != null) {
stmt.setFetchSize(fetchSize);
}
}
2.2.1:初始化Statement
源码如下:
org.apache.ibatis.executor.statement.PreparedStatementHandler#instantiateStatement
// 最终创建的就是JDBC的Statement的API。如PreparedStatement
protected Statement instantiateStatement(Connection connection) throws SQLException {
// 获取待执行的sql语句
String sql = boundSql.getSql();
// 处理Jdbc3KeyGenerator的情况
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = mappedStatement.getKeyColumns();
if (keyColumnNames == null) {
return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() != null) {
return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
} else {
return connection.prepareStatement(sql);
}
}
2.3:parameterize设置参数信息
源码如下:
org.apache.ibatis.executor.statement.RoutingStatementHandler#parameterize
public void parameterize(Statement statement) throws SQLException {
// 调用被代理类执行具体设置参数操作
// 2021-08-20 17:38:10
delegate.parameterize(statement);
}
2021-08-20 17:38:10处源码是调用具体类设置参数,具体参考2.3.4:设置参数。
2.3.4:设置参数
源码如下:
org.apache.ibatis.executor.statement.PreparedStatementHandler#parameterize
public void parameterize(Statement statement) throws SQLException {
// 通过paramterHandler具体设置参数
// 2021-08-20 17:40:08
parameterHandler.setParameters((PreparedStatement) statement);
}
2021-08-20 17:40:08处是通过ParamterHander设置参数,具体参考3.1:ParameterHandler设置参数。
3:ParameterHandler
该接口用于定义向Statement中设置参数信息的操作,源码如下:
org.apache.ibatis.executor.parameter.ParameterHandler
public interface ParameterHandler {
Object getParameterObject();
void setParameters(PreparedStatement ps)
throws SQLException;
}
3.1:ParameterHandler设置参数
源码如下:
public void setParameters(PreparedStatement ps) throws SQLException {
// 创建ErrorContext实例,并通过链式调用的方式设置相关参数
// activity:正在进行的活动信息
// object:parameterMap的id信息
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
// 获取所有#{xx}对应的参数信息对象
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
// 循环遍历,处理每一个参数的信息
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
// 非OUT才处理,一般只有存储过程才会有这种情况
if (parameterMapping.getMode() != ParameterMode.OUT) {
// 结果值
Object value;
// 获取#{xxx}中配置的属性名称
String propertyName = parameterMapping.getProperty();
// 优先使用动态生成的参数
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
// 直接使用用户传入的参数
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
// 获取当前#{xxx}的类型处理器
TypeHandler typeHandler = parameterMapping.getTypeHandler();
// 获取#{xxx}中配置的数据库类型
JdbcType jdbcType = parameterMapping.getJdbcType();
// 为null的情况
if (value == null && jdbcType == null) jdbcType = configuration.getJdbcTypeForNull();
// 使用类型处理的方法设置参数到PreparedStatement中,如果是当前mybatis默认提供的类型处理器
// 不支持转换到对应的数据库字段类型,如java类型是枚举,而数据库类型是VARCHAR,此时就需要自定义了
// ,当然一般情况下是不需要的
typeHandler.setParameter(ps, i + 1, value, jdbcType);
}
}
}
}
4:ResultSetHandler
该接口用于处理Statement中的结果集,接口定义如下:
org.apache.ibatis.executor.resultset.ResultSetHandler
public interface ResultSetHandler {
<E> List<E> handleResultSets(Statement stmt) throws SQLException;
void handleOutputParameters(CallableStatement cs) throws SQLException;
}
4.1:handleResultSets处理结果集
源码如下:
org.apache.ibatis.executor.resultset.DefaultResultSetHandler#handleResultSets
public List<Object> handleResultSets(Statement stmt) throws SQLException {
// 创建ErrorContext对象,并通过链式调用的方式设置当前正在
// 进行的活动信息和主体对象信息
// activity:handling results
// object:mappedStatment.getId()
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
// 最终的结果,正常如果不是存储过程的话,这里的结果是1,内部是一个集合元素
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0;
// 获取第一个ResultSet并封装为ResultSetWraper
// 正常如果不是存储过程的话,也只有一个,这里是考虑了
// 存储过程的情况,这里可以忽略存储过程,认为只有一个
// 2021-08-21 10:23:35
ResultSetWrapper rsw = getFirstResultSet(stmt);
// 获取resultMap的信息,id值,字段映射ResultMapping信息,用于生成
// 结果对象,可以认为只有一个
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
// resultMap的个数,认为只有1个
int resultMapCount = resultMaps.size();
// 验证配置信息
// 2021-08-22 10:18:58
validateResultMapsCount(rsw, resultMapCount);
// 按照一个resultSet对应一个resultMao的方式依次处理
// 但是这认为resultSet和resultMap都只有一个就可以了
while (rsw != null && resultMapCount > resultSetCount) {
// 获取当前的resultMap信息,即使用2021-08-21 10:23:35处是获取ResultSet并封装为ResultSetWrapper,具体参考4.1.1:获取首个ResultSet。2021-08-22 10:18:58是验证resultMap的配置信息,源码如下:
private void validateResultMapsCount(ResultSetWrapper rsw, int resultMapCount) {
// 有resultSet结果集,但是没有resultMap,则抛出异常
// 告知没有配置resultType或者是resultMap信息,其中resultType用于配置
// 返回一个对象,resultMap用于配置返回对相集合
if (rsw != null && resultMapCount < 1) {
throw new ExecutorException("A query was run and no Result Maps were found for the Mapped Statement '" + mappedStatement.getId()
+ "'. It's likely that neither a Result Type nor a Result Map was specified.");
}
}
2021-08-22 10:29:30处是处理根据映射信息处理结果集,并封装到结果集合中,具体参考4.1.2:根据映射信息处理结果集。
4.1.1:获取首个ResultSet
源码如下:
org.apache.ibatis.executor.resultset.DefaultResultSetHandler#getFirstResultSet
private ResultSetWrapper getFirstResultSet(Statement stmt) throws SQLException {
// 通过JDBC的statement对象获取查询结果ResultSet
ResultSet rs = stmt.getResultSet();
// 部分数据库驱动此时不返回第一个ResultSet,所以再这样处理一下
// 知道这里为什么这样写就可以了
while (rs == null) {
if (stmt.getMoreResults()) {
rs = stmt.getResultSet();
} else {
if (stmt.getUpdateCount() == -1) {
break;
}
}
}
// 将ResultSet封装为ResultSetWrapper
// 2021-08-21 10:28:58
return rs != null ? new ResultSetWrapper(rs, configuration) : null;
}
2021-08-1 10:28:58处是将ResultSet封装为ResultSetWrapper,源码如下:
// 类型处理器注册机,负责数据库字段到java属性值的映射处理,可能是mybatis提供的,也可能是自己扩展的,不过对于mybaits来说没有差别
private final TypeHandlerRegistry typeHandlerRegistry;
// java.sql.ResultSet JDBC的查询结果集API
private final ResultSet resultSet;
private final List<String> columnNames = new ArrayList<String>();
private final List<String> classNames = new ArrayList<String>();
private final List<JdbcType> jdbcTypes = new ArrayList<JdbcType>();
public ResultSetWrapper(ResultSet rs, Configuration configuration) throws SQLException {
super();
// 从全局配置文件对应的Configuration对象中获取mybaits默认提供
// 和通过4.1.2:根据映射信息处理结果集
源码如下:
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException {
try {
// 只有在存储过程时才会不等于null,所以这里先忽略
if (parentMapping != null) {
handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);
} else {
// resultHander默认传入的就是org.apache.ibatis.executor.Executor#NO_RESULT_HANDLER
// ResultHandler NO_RESULT_HANDLER = null;所以认为这里为null即可
if (resultHandler == null) {
// 创建默认的结果处理器DefaultResultHandler
DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);
// 处理当前ResultSet的结果集
// 2021-08-23 10:25:45
handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);
multipleResults.add(defaultResultHandler.getResultList());
// 如果是传入的结果处理器不为null
} else {
// 处理数据,但是注意并为添加到结果集对象multipleResults
// ,此时就需要将结果添加到结果处理器中,以便后续使用
handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);
}
}
} finally {
// 关闭java.sql.ResultSet
// 2021-08-23 10:21:08
closeResultSet(rsw.getResultSet());
}
}
2021-08-23 10:21:08处是关闭java.sql.ResultSet,源码如下:
org.apache.ibatis.executor.resultset.DefaultResultSetHandler#closeResultSet
private void closeResultSet(ResultSet rs) {
try{
if (rs != null) {
rs.close();
}
} catch (SQLException e) {
// ignore
}
}
2021-08-23 10:25:45处是处理结果集,具体参考4.1.3:处理结果集获取查询结果。
4.1.3:处理结果集获取查询结果
源码如下:
org.apache.ibatis.executor.resultset.DefaultResultSetHandler#handleRowValues
private void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
// 是否有内嵌resultMap情况,即一个对象里封装了另一个对象,想要完成封装对象的赋值
// 则需要通过引用另外一个resultMap来指定映射关系,一般在一对一或者是一对多的场景中存在
if (resultMap.hasNestedResultMaps()) {
// 检查RowBounds,即检查嵌套拆线的分页情况
// 2021-08-23 11:16:36
ensureNoRowBounds();
// 检查非自定义的reusltHandler,猜测因为自定义resultHandler不能正确处理嵌套resultMap
// 2021-08-23 11:26:53
checkResultHandler();
// 处理内嵌的resultMap
// 2021-08-23 11:32:08
handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
// 处理简单映射
} else {
// 处理简单映射
// 2021-08-23 11:49:03
handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
}
}
2021-08-23 11:16:36处是检查嵌套查询的分页情况,源码如下:
org.apache.ibatis.executor.resultset.DefaultResultSetHandler#ensureNoRowBounds
private void ensureNoRowBounds() {
// 如果是safeRowBoundsEnabled属性为true(该属性用于设置是否允许在嵌套查询中使用分页,默认为false)
// 并且,rowBounds != null
// 并且rowBounds.getLimit() < RowBounds.NO_ROW_LIMIT || rowBounds.getOffset() > RowBounds.NO_ROW_OFFSET
// public final static int NO_ROW_LIMIT = Integer.MAX_VALUE;
// public final static int NO_ROW_OFFSET = 0;
// 如果是存在嵌套查询并且分页的话,这里需要注意
if (configuration.isSafeRowBoundsEnabled() && rowBounds != null && (rowBounds.getLimit() < RowBounds.NO_ROW_LIMIT || rowBounds.getOffset() > RowBounds.NO_ROW_OFFSET)) {
// 抛出异常,并告知相关错误信息,以及如何处理规避当前异常
throw new ExecutorException("Mapped Statements with nested result mappings cannot be safely constrained by RowBounds. "
+ "Use safeRowBoundsEnabled=false setting to bypass this check.");
}
}
2021-08-23 11:26:53处是检查非自定义resultHandler,源码如下:
org.apache.ibatis.executor.resultset.DefaultResultSetHandler#checkResultHandler
protected void checkResultHandler() {
// resultHandler不为空:resultHandler != null
// safeResultHandlerEnabled:是否允许在嵌套语句中使用结果处理器,configuration.isSafeResultHandlerEnabled()
// resultOrdered:select的resultOrderd属性为false,!mappedStatement.isResultOrdered()
if(resultHandler != null && configuration.isSafeResultHandlerEnabled() && !mappedStatement.isResultOrdered()) {
throw new ExecutorException("Mapped Statements with nested result mappings cannot be safely used with a custom ResultHandler. "
+ "Use safeResultHandlerEnabled=false setting to bypass this check "
+ "or ensure your statement returns ordered data and set resultOrdered=true on it.");
}
}
2021-08-23 11:32:08处是处理内嵌的resultMap,具体参考4.2:处理内嵌resultMap。2021-08-23 11:49:03处理简单映射,具体参考4.3:处理简单resultMap。
4.2:处理内嵌resultMap
先把流程穿起来,所以这里先不研究,使用场景可以参考一对一,一对多映射,有需要了再看。
在这里插入代码片
源码也放到这里:
org.apache.ibatis.executor.resultset.DefaultResultSetHandler#handleRowValuesForNestedResultMap
private void handleRowValuesForNestedResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
final DefaultResultContext resultContext = new DefaultResultContext();
skipRows(rsw.getResultSet(), rowBounds);
Object rowValue = null;
while (shouldProcessMoreRows(resultContext, rowBounds) && rsw.getResultSet().next()) {
final ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(rsw.getResultSet(), resultMap, null);
final CacheKey rowKey = createRowKey(discriminatedResultMap, rsw, null);
Object partialObject = nestedResultObjects.get(rowKey);
if (mappedStatement.isResultOrdered()) { // issue #577 && #542
if (partialObject == null && rowValue != null) {
nestedResultObjects.clear();
storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet());
}
rowValue = getRowValue(rsw, discriminatedResultMap, rowKey, rowKey, null, partialObject);
} else {
rowValue = getRowValue(rsw, discriminatedResultMap, rowKey, rowKey, null, partialObject);
if (partialObject == null) {
storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet());
}
}
}
if (rowValue != null && mappedStatement.isResultOrdered() && shouldProcessMoreRows(resultContext, rowBounds)) {
storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet());
}
}
4.3:处理简单resultMap
这种方式是我们使用的最多的,即select引用的resultMap内部都是基础数据类型如果有对象类型,就需要其他的resultMap来表述映射关系了,此时就存在嵌套查询了,源码如下:
org.apache.ibatis.executor.resultset.DefaultResultSetHandler#handleRowValuesForSimpleResultMap
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping)
throws SQLException {
// 创建DefaultResultContext对象,封装查询结果上下文相关信息的对象,其实就是定义了一个对象来封装
// 获取数据的过程中需要的用到的信息,比如“是否查询完毕了”等
// 2021-08-23 13:17:29
DefaultResultContext resultContext = new DefaultResultContext();
// 跳过指定的行数,即执行分页逻辑
// 2021-08-23 13:35:43
skipRows(rsw.getResultSet(), rowBounds);
// 循环获取每一行数据,进行处理,直到达到offset,生成目标对象
// rsw.getResultSet().next()获取下一行数据
// 2021-08-23 13:53:46
while (shouldProcessMoreRows(resultContext, rowBounds) && rsw.getResultSet().next()) {
// 获取映射数据为对象要使用的ResultMap对象
// 2021-08-23 14:01:53
ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(rsw.getResultSet(), resultMap, null);
// 根据resultMap映射信息和当前的数据行信息创建对应对象
// 2021-08-23 15:20:18
Object rowValue = getRowValue(rsw, discriminatedResultMap);
// 存储查询结果对象
// 2021-08-25 16:52:25
storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet());
}
}
2021-08-23 13:17:29处是创建DefaultResultContext对象,具体参考5:ResultContext。2021-08-23 13:35:43处是跳过指定的行数,即执行分页逻辑,具体参考4.3.1:mybait默认的分页逻辑。2021-08-23 13:53:46处shouldProcessMoreRows(resultContext, rowBounds)源码如下:
org.apache.ibatis.executor.resultset.DefaultResultSetHandler#shouldProcessMoreRows
private boolean shouldProcessMoreRows(ResultContext context, RowBounds rowBounds) throws SQLException {
// 执行一些标记判断,和已查询数据行数判断
return !context.isStopped() && context.getResultCount() < rowBounds.getLimit();
}
2021-08-23 14:01:53处是获取用于映射数据库数据到对象的Result Map对象,具体参考4.3.2:获取ResultMap对象。2021-08-23 15:20:18处是根据resultMap映射信息和数据行信息创建结果对象,具体参考4.3.3:创建结果对象。2021-08-25 16:52:25处是存储查询结果对象,具体参考4.3.4:存储查询结果对象。
4.3.1:mybait默认的分页逻辑
源码如下:
org.apache.ibatis.executor.resultset.DefaultResultSetHandler#skipRows
private void skipRows(ResultSet rs, RowBounds rowBounds) throws SQLException {
// 如果是TYPE_FORWARD_ONLY,则直接向前跳指定的行数
if (rs.getType() != ResultSet.TYPE_FORWARD_ONLY) {
// 限制查询条数的话
if (rowBounds.getOffset() != RowBounds.NO_ROW_OFFSET) {
// 直接调用java.sql.ResultSet.absolute方法向前跳指定的行数
rs.absolute(rowBounds.getOffset());
}
// 非ResultSet.TYPE_FORWARD_ONLY
} else {
// 一行一行的向前跳
for (int i = 0; i < rowBounds.getOffset(); i++) {
rs.next();
}
}
}
从这里我们可以看出来,mybaits默认的RowBounds方式的分页并不是基于mysql的limit,offset,即并非物理分页,而是逻辑分页,即结果集是先查出来,然后对于结果集进行过滤,但是JCBC驱动并非一次将所有的结果集加载到内存中,而是如果有需要的话再从数据库中查询,这里单次获取的条数是通过fetchSize设置的,但是这种方式并非最优,最优的方式还是使用物理分页,即直接在sql语句上使用limit,offset关键字,关于这里的逻辑详细可以参考这篇文章。
4.3.2:获取ResultMap对象
关于org.apache.ibatis.mapping.ResultMap对象参考6:ResultMap。
源码如下:
public ResultMap resolveDiscriminatedResultMap(ResultSet rs, ResultMap resultMap, String columnPrefix) throws SQLException {
Set<String> pastDiscriminators = new HashSet<String>();
Discriminator discriminator = resultMap.getDiscriminator();
// 可以认为这里是false,因为不太常用,认为直接返回即可
// 2021-08-23 15:16:02
while (discriminator != null) {
final Object value = getDiscriminatorValue(rs, discriminator, columnPrefix);
final String discriminatedMapId = discriminator.getMapIdFor(String.valueOf(value));
if (configuration.hasResultMap(discriminatedMapId)) {
resultMap = configuration.getResultMap(discriminatedMapId);
Discriminator lastDiscriminator = discriminator;
discriminator = resultMap.getDiscriminator();
if (discriminator == lastDiscriminator || !pastDiscriminators.add(discriminatedMapId)) {
break;
}
} else {
break;
}
}
// 返回resultMap
return resultMap;
}
2021-08-23 15:16:02处discriminator鉴别器的作用就是动态的设置resultMap的值,根据某列的结果来动态的引用其他resultMap设置当前对象的对象类型的属性,具体用法可以参考这里的例子。
4.3.3:创建结果对象
源码如下:
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap) throws SQLException {
// 创建ResultLoaderMap对象,延迟加载相关
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
// 创建结果对象,只是有了对象,但是并没有将列数据赋值到对应的属性
// 2021-08-23 15:29:33
Object resultObject = createResultObject(rsw, resultMap, lazyLoader, null);
// 到这里,需要返回给用户的对象就已经创建完毕了,但是可能属性还没有值,所以还需要进行后续的逻辑
// !typeHandlerRegistry.hasTypeHandler(resultMap.getType()):非基础数据类型,基础数据类型已经获取值完毕了,不需要执行后续逻辑,直接返回给用户使用即可
if (resultObject != null && !typeHandlerRegistry.hasTypeHandler(resultMap.getType())) {
// 获取当前行值rowValue的元信息对象
final MetaObject metaObject = configuration.newMetaObject(resultObject);
// foundValues:是否成功映射了任意一个属性的标记,这里如果是通过构造函数创建了对象,则是成功映射了
// 至少一个属性
boolean foundValues = resultMap.getConstructorResultMappings().size() > 0;
// 是否需要应用自动映射配置,即列名称自动作为目标对象的属性名称
// 2021-08-25 13:17:26
if (shouldApplyAutomaticMappings(resultMap, !AutoMappingBehavior.NONE.equals(configuration.getAutoMappingBehavior()))) {
// 自动映射字段,即,将查询列名称作为属性或者是字段的名称赋值对象
// 2021-08-25 14:41:15
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, null) || foundValues;
}
// 应用在2021-08-23 15:29:33处是创建结果对象,但是并没有将列对应的值赋值到对象属性中,具体参考4.3.3.1:实例化结果对象。2021-08-25 13:17:26处是判断是否需要应用自动映射配置,具体参考4.3.3.4:是否需要应用自动映射。2021-08-25 14:41:15处是自动映射赋值,具体参考4.3.3.5:应用自动映射。2021-08-25 15:47:56处应用配置的映射信息,具体参考4.3.3.6:应用配置的映射信息。
4.3.3.1:实例化结果对象
源码如下:
private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
final List<Class<?>> constructorArgTypes = new ArrayList<Class<?>>();
final List<Object> constructorArgs = new ArrayList<Object>();
// 调用重载版本,实例化对象
// 2021-08-23 15:37:29
final Object resultObject = createResultObject(rsw, resultMap, constructorArgTypes, constructorArgs, columnPrefix);
// 执行到这里对象实例已经有了,但是如果是通过对象工厂创建的实例,属性还没有赋值
// 还需要通过后续操作将查询结果的列值赋值到对应的属性值上去
// 如果是创建了实例对象
// !typeHandlerRegistry.hasTypeHandler(resultMap.getType()):非基础数据类型
if (resultObject != null && !typeHandlerRegistry.hasTypeHandler(resultMap.getType())) {
// 获取配置的resultmapping信息,如下配置:
/*
*/
final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();
// 遍历每一个resultMapping信息
for (ResultMapping propertyMapping : propertyMappings) {
// 如果有内嵌查询,并且是延迟加载的,则创建代理对象,这里延迟加载延迟的是内嵌查询的查询信息
// 即select属性引用的statement
// 2021-08-25 10:16:38
if (propertyMapping.getNestedQueryId() != null && propertyMapping.isLazy()) {
// 2021-08-25 11:22:50
return configuration.getProxyFactory().createProxy(resultObject, lazyLoader, configuration, objectFactory, constructorArgTypes, constructorArgs);
}
}
}
// 返回创建的对象有两种情况已经是有数据库值的了
// 1:基础数据类型,2:resultMap中通过即构造函数设置,此时通过构造函数创建对象
// 其他情况对象属性还是没有值的,比如如下可能的配置就是这种情况:
/*
return resultObject;
}
2021-08-23 15:37:29是调用重载版本完成对象实例化,具体参考4.3.3.2:又实例化结果对象。2021-08-25 10:16:38处是处理延迟加载的情况,propertyMapping.getNestedQueryId()处是存在嵌套查询的情况,存在于association,collection标签中使用标签,如下是在collection标签中使用select标签的情况:
<resultMap id="myResultMap" type="yudaosourcecode.mybatis.model.TestResultmapCollectionMany">
<id property="id" column="id" javaType="integer" jdbcType="INTEGER"/>
<result property="manyname" column="manyname" javaType="string" jdbcType="VARCHAR"/>
<result property="manyage" column="manyage" javaType="integer" jdbcType="INTEGER"/>
<association property="testResultmapCollectionOne"
select="yudaosourcecode.mybatis.mapper.TestResultmapCollectionOneMapper.getById2"
column="id"/>
resultMap>
propertyMapping.isLazy()是判读是否为延迟加载,延迟加载通过在全局配置文件的settting标签中来设置,如下:
| 配置名称 | 作用 |
|---|---|
| lazyLoadingEnabled | 关联查询中是否开启延迟加载,默认为false,可通过在statement的映射配置中设置"fetchType=[eager’lazy]"来覆盖这里的配置 |
| aggressiveLazyLoading | 无论调用对象的哪个方法都加载该对象中延迟加载的属性,可通过设置lazyLoadTriggerMethods来覆盖这里的,指定只有调用特定的方法才加载延迟加载得对象 |
| lazyLoadTriggerMethods | 指定调用对象的哪些方法加载延迟加载的对象,逗号分隔,默认equals,clone,hashCode,toString,以及对应关联属性的读方法getXxxx |
2021-08-25 11:22:50处是如果是延迟加载的话,使用CGLIB创建代理对象,关于这部分内容详细可以参考这篇文章。
4.3.3.2:又实例化结果对象
源码如下:
private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, List<Class<?>> constructorArgTypes, List<Object> constructorArgs, String columnPrefix)
throws SQLException {
final Class<?> resultType = resultMap.getType();
final List<ResultMapping> constructorMappings = resultMap.getConstructorResultMappings();
// 如果是在结果处理器注册器中包含当前的返回类型,则说明返回的是基础数据类型,比如
if (typeHandlerRegistry.hasTypeHandler(resultType)) {
// 创建基础数据类型的对象实例
// 2021-08-23 15:51:12
return createPrimitiveResultObject(rsw, resultMap, columnPrefix);
// 如果是指定了2021-08-23 15:51:12处是当查询结果为基础数据类型时创建基础数据类型的对象,具体参考4.3.3.2.1:创建基础数据类型对象实例。2021-08-23 17:10:29处是设置了
<resultMap id="myResultMap" type="yudaosourcecode.mybatis.model.TestResultmapConstructor">
<constructor>
<idArg javaType="integer" jdbcType="INTEGER" column="id"/>
<arg javaType="string" jdbcType="VARCHAR" column="myname"/>
<arg javaType="integer" jdbcType="INTEGER" column="myage"/>
constructor>
resultMap>
具体参考4.3.3.2.2:通过构造函数创建对象实例。2021-08-23 17:54:10处是直接通过对象工厂类创建实例对象,如下就是这种情况:
<resultMap id="myResultMap" type="yudaosourcecode.mybatis.model.TestMapperSql">
<id property="id" column="id" javaType="integer" jdbcType="INTEGER"/>
<result property="myname" column="myname" javaType="string" jdbcType="VARCHAR"/>
<result property="myage" column="myage" javaType="integer" jdbcType="INTEGER"/>
resultMap>
具体参考7.1:对象工厂创建对象。
4.3.3.2.1:创建基础数据类型对象实例
源码如下:
private Object createPrimitiveResultObject(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix) throws SQLException {
// 获取
// 这里的结果就是java.lang.Integer
final Class<?> resultType = resultMap.getType();
// 从中获取值得列名称
final String columnName;
// 这里的if不知道何时为true,暂时忽略
if (resultMap.getResultMappings().size() > 0) {
final List<ResultMapping> resultMappingList = resultMap.getResultMappings();
final ResultMapping mapping = resultMappingList.get(0);
columnName = prependPrefix(mapping.getColumn(), columnPrefix);
} else {
// 以结果列的第一列的值作为结果
// 比如select count(*) * 3 sum1, count(*) sum2 from test_mapper_sql2222 where id>#{id}
// 会取sum1作为结果,在使用时需要注意
columnName = rsw.getColumnNames().get(0);
}
// 获取类型处理器,用于转换数据库插叙结果到目标基础数据类型的值
// 2021-08-23 16:06:27
final TypeHandler<?> typeHandler = rsw.getTypeHandler(resultType, columnName);
// 调用类型处理器的getResult方法获取结果值
// 2021-08-23 16:33:24
return typeHandler.getResult(rsw.getResultSet(), columnName);
}
2021-08-23 16:06:27处是获取对应的列值到目标基础数据类型值转换的类型转换器,具体参考4.3.3.3:获取数据库列到类属性结果处理器。2021-08-23 16:33:24处是调用类型处理器获取对应的结果,比如为IntegerTypeHandler时,源码如下:
org.apache.ibatis.type.BaseTypeHandler#getResult(java.sql.ResultSet, java.lang.String)
public T getResult(ResultSet rs, String columnName) throws SQLException {
T result = getNullableResult(rs, columnName);
if (rs.wasNull()) {
return null;
} else {
return result;
}
}
org.apache.ibatis.type.IntegerTypeHandler#getNullableResult(java.sql.ResultSet, java.lang.String)
public Integer getNullableResult(ResultSet rs, String columnName)
throws SQLException {
return rs.getInt(columnName);
}
4.3.3.2.2:通过构造函数创建对象实例
源码如下:
org.apache.ibatis.executor.resultset.DefaultResultSetHandler#createParameterizedResultObject
private Object createParameterizedResultObject(ResultSetWrapper rsw, Class<?> resultType, List<ResultMapping> constructorMappings, List<Class<?>> constructorArgTypes,
List<Object> constructorArgs, String columnPrefix) throws SQLException {
boolean foundValues = false;
// 遍历ResultMapping信息,获取对应的属性值
for (ResultMapping constructorMapping : constructorMappings) {
// 当前ResultMapping的java属性的类型
final Class<?> parameterType = constructorMapping.getJavaType();
// 当前ResultMapping的列名称
final String column = constructorMapping.getColumn();
// 需要赋值到目标属性的值
final Object value;
// 如果是内嵌查询,则通过内嵌查询获取对应的值,如下就是一个内嵌查询
// 2021-08-23 17:30:40
if (constructorMapping.getNestedQueryId() != null) {
// 直接通过内嵌查询获取当前属性需要赋予的结果值
value = getNestedQueryConstructorValue(rsw.getResultSet(), constructorMapping, columnPrefix);
// 如果是有resultMap信息,则重复调用getRowValue方法获取值,此时是属性是一个对象的情况
} else if (constructorMapping.getNestedResultMapId() != null) {
final ResultMap resultMap = configuration.getResultMap(constructorMapping.getNestedResultMapId());
value = getRowValue(rsw, resultMap);
// 这是最常见的情况,属性都是基础数据类型的
} else {
// 从ResultMapping中获取将数据行的列值到对应属性值的结果处理器
final TypeHandler<?> typeHandler = constructorMapping.getTypeHandler();
// 调用类型处理器获取目标属性值
value = typeHandler.getResult(rsw.getResultSet(), prependPrefix(column, columnPrefix));
}
// 添加到构造函数参数类型集合中
constructorArgTypes.add(parameterType);
// 添加到参数值集合中
constructorArgs.add(value);
// 如果是当前value不为空null则设置foundValues为true
foundValues = value != null || foundValues;
}
// 通过对象工厂类创建对象实例
// 2021-08-23 17:42:10
return foundValues ? objectFactory.create(resultType, constructorArgTypes, constructorArgs) : null;
}
2021-08-23 17:30:40处是处理内嵌查询的情况,如下就是一种内嵌查询:
<resultMap id="myResultMap" type="yudaosourcecode.mybatis.model.TestResultmapConstructor">
<constructor>
<idArg javaType="integer" jdbcType="INTEGER" column="id" select="select100"/>
<arg javaType="string" jdbcType="VARCHAR" column="myname"/>
<arg javaType="integer" jdbcType="INTEGER" column="myage"/>
constructor>
resultMap>
<select id="select100" resultType="integer">
select 1000
select>
2021-08-23 17:42:10处是通过对象工厂类创建对象实例,具体参考7.1:对象工厂创建对象。
4.3.3.3:获取数据库列到类属性结果处理器
源码如下:
public TypeHandler<?> getTypeHandler(Class<?> propertyType, String columnName) {
TypeHandler<?> handler = null;
// 根据列名称获取,一般为null,所以这里可以认为为null
Map<Class<?>, TypeHandler<?>> columnHandlers = typeHandlerMap.get(columnName);
if (columnHandlers == null) {
// 创建Map,并存储列名称对应的信息
columnHandlers = new HashMap<Class<?>, TypeHandler<?>>();
typeHandlerMap.put(columnName, columnHandlers);
} else {
handler = columnHandlers.get(propertyType);
}
// 到这里类型处理器一般为null,可以认为为null
if (handler == null) {
// 根据当前的属性类型获取类型处理器
// 比如当前属性类型是java.lang.Integer,则处理器结果就是org.apache.ibatis.type.IntegerTypeHandler,这里默认列结果能转换为
// 对应的属性类型,如果不行的话,运行过程中会抛出异常
handler = typeHandlerRegistry.getTypeHandler(propertyType);
// 如果是没有获取到期望的类型处理器
if (handler == null || handler instanceof UnknownTypeHandler) {
// 获取jdbc的类型和java的类型,并根据其进行获取类型处理器信息
final int index = columnNames.indexOf(columnName);
final JdbcType jdbcType = jdbcTypes.get(index);
final Class<?> javaType = resolveClass(classNames.get(index));
if (javaType != null && jdbcType != null) {
handler = typeHandlerRegistry.getTypeHandler(javaType, jdbcType);
} else if (javaType != null) {
handler = typeHandlerRegistry.getTypeHandler(javaType);
} else if (jdbcType != null) {
handler = typeHandlerRegistry.getTypeHandler(jdbcType);
}
}
// 如果是依然没有获取到期望的类型处理器,则使用通用的ObjecTypeHandler
if (handler == null || handler instanceof UnknownTypeHandler) {
handler = new ObjectTypeHandler();
}
columnHandlers.put(propertyType, handler);
}
// 返回类型处理器
return handler;
}
4.3.3.4:是否需要应用自动映射
调用方法为:shouldApplyAutomaticMappings(resultMap, !AutoMappingBehavior.NONE.equals(configuration.getAutoMappingBehavior()))。
其中AutoMappingBehavior是一个枚举类,源码如下:
org.apache.ibatis.session.AutoMappingBehavior
/**
* 指定mybatis如何将列映射到字段或者是属性
*/
public enum AutoMappingBehavior {
// 禁用自动映射
NONE,
// 开启部分自动映射功能
PARTIAL,
// 开启所有自动映射功能
FULL
}
其中配置的方式是通过在全局config配置文件中的settting标签中设置autoMappingBehavior,取值是枚举类的三个值的字面量,默认值是PARTIAL,即只自动映射不包含嵌套查询的字段。!AutoMappingBehavior.NONE.equals(configuration.getAutoMappingBehavior())是指定自动映射的默认值为只要不是NONE,就自动映射,shouldApplyAutomaticMappings源码如下:
org.apache.ibatis.executor.resultset.DefaultResultSetHandler#shouldApplyAutomaticMappings
private boolean shouldApplyAutomaticMappings(ResultMap resultMap, boolean def) {
// 如果是在4.3.3.5:应用自动映射
源码如下:
private boolean applyAutomaticMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String columnPrefix) throws SQLException {
// 获取在查询列中有,但是在4.3.3.6:应用配置的映射信息
源码如下:
private boolean applyPropertyMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
// 获取在
这里的结果就是:
0 = "ID"
1 = "MYNAME"
2 = "MYAGE"
*/
final List<String> mappedColumnNames = rsw.getMappedColumnNames(resultMap, columnPrefix);
// 是否找到其中任意一个属性的值
boolean foundValues = false;
// 获取配置的ResultMapping信息
final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();
for (ResultMapping propertyMapping : propertyMappings) {
// 获取列名称
final String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);
if (propertyMapping.isCompositeResult()
|| (column != null && mappedColumnNames.contains(column.toUpperCase(Locale.ENGLISH)))
|| propertyMapping.getResultSet() != null) {
// 获取属性值
// 2021-08-25 16:05:52
Object value = getPropertyMappingValue(rsw.getResultSet(), metaObject, propertyMapping, lazyLoader, columnPrefix);
// 获取属性名称
final String property = propertyMapping.getProperty();
if (value != NO_VALUE && property != null && (value != null || configuration.isCallSettersOnNulls())) {
if (value != null || !metaObject.getSetterType(property).isPrimitive()) {
// 设置属性值
metaObject.setValue(property, value);
}
// 设置至少一个属性值不为null为true
foundValues = true;
}
}
}
return foundValues;
}
2021-08-25 16:05:52处是从结果集ResultSet中获取结果值,具体参考4.3.3.6.1:从结果集中获取属性值。
4.3.3.6.1:从结果集中获取属性值
源码如下:
private Object getPropertyMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
// 有嵌套查询,即使用标签引用了其他的查询statement
if(propertyMapping.getNestedQueryId() != null) {
// 获取内嵌属性值
// 2021-08-25 16:13:10
return getNestedQueryMappingValue(rs, metaResultObject, propertyMapping, lazyLoader, columnPrefix);
} else if (propertyMapping.getResultSet() != null) { // 存储过程情况,忽略
addPendingChildRelation(rs, metaResultObject, propertyMapping);
return NO_VALUE;
} else if (propertyMapping.getNestedResultMapId() != null) {
// the user added a column attribute to a nested result map, ignore it
return NO_VALUE;
} else {
// 获取类型处理器
final TypeHandler<?> typeHandler = propertyMapping.getTypeHandler();
// 获取列名称
final String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);
// 通过类型处理器获取结果值
return typeHandler.getResult(rs, column);
}
}
2021-08-25 16:13:10处是获取内嵌属性值,具体参考4.3.3.6.2:获取内嵌属性值。
4.3.3.6.2:获取内嵌属性值
源码如下:
private Object getNestedQueryMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
// 内嵌查询id,即select属性设置的值
final String nestedQueryId = propertyMapping.getNestedQueryId();
// 获取属性名称
final String property = propertyMapping.getProperty();
// 从全局配置文件中获取内嵌查询对应的MappedStatement对象
final MappedStatement nestedQuery = configuration.getMappedStatement(nestedQueryId);
// 获取parameterMap的值
final Class<?> nestedQueryParameterType = nestedQuery.getParameterMap().getType();
// 获取内嵌查询的参数对象
final Object nestedQueryParameterObject = prepareParameterForNestedQuery(rs, propertyMapping, nestedQueryParameterType, columnPrefix);
Object value = NO_VALUE;
// 如果有内嵌参数值
if (nestedQueryParameterObject != null) {
// 从内嵌查询的statement中获取BoundSql对象
final BoundSql nestedBoundSql = nestedQuery.getBoundSql(nestedQueryParameterObject);
// 构造缓存对象
final CacheKey key = executor.createCacheKey(nestedQuery, nestedQueryParameterObject, RowBounds.DEFAULT, nestedBoundSql);
// 嵌套查询的对象的类型
final Class<?> targetType = propertyMapping.getJavaType();
// 判断以及缓存,即BaseExcutor的localCache中是否有值
if (executor.isCached(nestedQuery, key)) { // 已经缓存
// 如果是有缓存,则创建DeferLoad对象,并使用该对象从缓存中获取数据
// 2021-08-25 16:28:22
executor.deferLoad(nestedQuery, metaResultObject, property, key, targetType);
} else { // 没有缓存
// 创建ResultLoader对象
final ResultLoader resultLoader = new ResultLoader(configuration, executor, nestedQuery, nestedQueryParameterObject, targetType, key, nestedBoundSql);
if (propertyMapping.isLazy()) { // 延迟加载
// 延迟加载时将resultLoader存储起来,等到用户使用的时候在真正获取数据
// 2021-08-25 16:31:40
lazyLoader.addLoader(property, metaResultObject, resultLoader);
} else { // 非延迟加载
// 非延迟加载直接获取数据
value = resultLoader.loadResult();
}
}
}
// 返回数据
return value;
}
2021-08-25 16:28:22是通过DeferLoad加载缓存数据,具体参考这篇文章。2021-08-25 16:31:40处存储ResultLoader信息,供后续延迟加载使用,关于延迟加载参考这篇文章。
4.3.4:存储查询结果对象
源码如下:
private void storeObject(ResultHandler resultHandler, DefaultResultContext resultContext, Object rowValue, ResultMapping parentMapping, ResultSet rs) throws SQLException {
if (parentMapping != null) { // 忽略,只有存储过程才会有
linkToParents(rs, parentMapping, rowValue);
} else {
// 调用ResultHandler对结果进行处理
// 2021-08-25 16:54:54
callResultHandler(resultHandler, resultContext, rowValue);
}
}
2021-08-25 16:54:54处是通过ResultHandler处理结果,具体参考4.3.4.1:通过ResultHandler处理结果。
4.3.4.1:通过ResultHandler处理结果
源码如下:
private void callResultHandler(ResultHandler resultHandler, DefaultResultContext resultContext, Object rowValue) {
// 设置当前要处理的对象
resultContext.nextResultObject(rowValue);
// 使用ResultHandler处理对象
// 处理也非常简单,就是讲resultContext中封装的对象add到list集合中,源码如下:
/*
private final List
resultHandler.handleResult(resultContext);
}
5:ResultContext
接口源码如下:
org.apache.ibatis.session.ResultContext
public interface ResultContext {
// 获取当前的结果对象
Object getResultObject();
// 总的结果的数量
int getResultCount();
// 是否暂停
boolean isStopped();
// 停止
void stop();
}
唯一的实现类是org.apache.ibatis.executor.result.DefaultResultContext源码如下:
org.apache.ibatis.executor.result.DefaultResultContext
public class DefaultResultContext implements ResultContext {
// 当前的结果对象
private Object resultObject;
// 结果集对象的个数
private int resultCount;
// 是否停止
private boolean stopped;
public DefaultResultContext() {
resultObject = null;
resultCount = 0;
stopped = false;
}
public Object getResultObject() {
return resultObject;
}
public int getResultCount() {
return resultCount;
}
public boolean isStopped() {
return stopped;
}
public void nextResultObject(Object resultObject) {
resultCount++;
this.resultObject = resultObject;
}
// 停止
public void stop() {
this.stopped = true;
}
}
6:ResultMap
接口限定名称是org.apache.ibatis.mapping.ResultMap,对应的是
org.apache.ibatis.mapping.ResultMap
public class ResultMap {
// id属性值
private String id;
// type属性值
private Class<?> type;
// org.apache.ibatis.maping.ResultMapping代表的是

7:ObjectFactory
接口源码如下:
org.apache.ibatis.reflection.factory.ObjectFactory
// mybatis创建可能用到的所有对象的接口
public interface ObjectFactory {
void setProperties(Properties properties);
// 使用默认构造函数创建对象
<T> T create(Class<T> type);
// 使用指定的构造函数和对应的值创建实例对象
<T> T create(Class<T> type, List<Class<?>> constructorArgTypes, List<Object> constructorArgs);
// 暂时忽略该方法
<T> boolean isCollection(Class<T> type);
}
其默认的实现类是org.apache.ibatis.reflection.factory.DefaultObjectFactory,当然我们也可以自定义对象工厂类,然后在全局配置文件中通过
7.1:对象工厂创建对象
org.apache.ibatis.reflection.factory.DefaultObjectFactory#create(java.lang.Class<T>)
public <T> T create(Class<T> type) {
return create(type, null, null);
}
org.apache.ibatis.reflection.factory.DefaultObjectFactory#create(java.lang.Class<T>, java.util.List<java.lang.Class<?>>, java.util.List<java.lang.Object>)
public <T> T create(Class<T> type, List<Class<?>> constructorArgTypes, List<Object> constructorArgs) {
// 获取要创建的class类型
Class<?> classToCreate = resolveInterface(type);
// 创建对象
T created = (T) instantiateClass(classToCreate, constructorArgTypes, constructorArgs);
return created;
}
org.apache.ibatis.reflection.factory.DefaultObjectFactory#instantiateClass
private <T> T instantiateClass(Class<T> type, List<Class<?>> constructorArgTypes, List<Object> constructorArgs) {
try {
Constructor<T> constructor;
// 如果是参数类型和参数值都为null,则尝试使用无参数构造函数,即默认构造函数创建对象
if (constructorArgTypes == null || constructorArgs == null) {
// 获取默认构造函数
constructor = type.getDeclaredConstructor();
// 暴力访问如果需要的话
if (!constructor.isAccessible()) {
constructor.setAccessible(true);
}
// 使用默认构造函数创建实例
return constructor.newInstance();
}
// 根据参数类型数组,获取对应的构造函数
constructor = type.getDeclaredConstructor(constructorArgTypes.toArray(new Class[constructorArgTypes.size()]));
// 暴力访问,如果需要的话
if (!constructor.isAccessible()) {
constructor.setAccessible(true);
}
// 使用参数值数组调用对应的构造函数创建实例对象
return constructor.newInstance(constructorArgs.toArray(new Object[constructorArgs.size()]));
} catch (Exception e) {
// 发生了异常,则设置相关的参数类型和参数值信息,在异常中抛出
// ,以便用户查找问题,比如对象属性是int(基础数据类型不可为null)的,而
// 数据库是空串,此时将null值或者是空串值赋值给int就报错了
StringBuilder argTypes = new StringBuilder();
if (constructorArgTypes != null) {
for (Class<?> argType : constructorArgTypes) {
argTypes.append(argType.getSimpleName());
argTypes.append(",");
}
}
StringBuilder argValues = new StringBuilder();
if (constructorArgs != null) {
for (Object argValue : constructorArgs) {
argValues.append(String.valueOf(argValue));
argValues.append(",");
}
}
// 抛出异常信息
throw new ReflectionException("Error instantiating " + type + " with invalid types (" + argTypes + ") or values (" + argValues + "). Cause: " + e, e);
}
}