爬虫日记01:爬取m3u8格式视频和解密
开发环境
·python3.10
·pycharm
相关模块的应用
import requests
from bs4 import BeautifulSoup
import asyncio
import aiohttp
import aiofiles确定目标需求
对某盗版网站进行浴血黑帮视频的爬取

嘿嘿
进行网页数据分析,找寻我们所需的数据来源

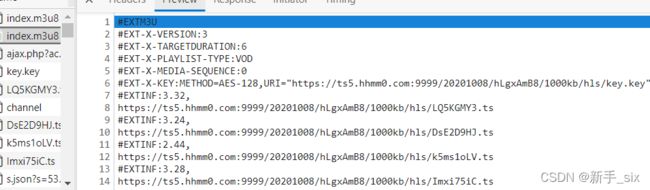
由于该视频存在2个m3u8
所以我们得先得到第一层的m3u8文件下载地址,再从第一层m3u8文件中得到第二层m3u8文件的下载地址。当然,你也可以直接在第二个m3u8里获取它的url进行视频下载。
整体思路
1.拿到主页面的页面源代码,找到iframe
2.从iframe的页面源代码中拿到m3u8文件
3.下载第一层m3u8文件,----》下载第二层m3u8文件(得到视频的全部ts路径)
4.下载视频
5.下载秘钥进行解密操作
6.合并所有ts文件为一个mp4文件(利用各种办法:工具或者代码都行)
代码的实现
1.对浴血黑帮视频的下载
import requests
from bs4 import BeautifulSoup
import asyncio
import aiohttp
import aiofiles
# 获取iframe_src
def get_iframe_src(url):
res = requests.get(url) # 获取页面源代码
main_page = BeautifulSoup(res.text,"html.parser") # 解析页面源码
src = main_page.find("iframe").get("src") # 得到我们所需的iframe的src
return src
# 得到第一层的m3u8下载地址
def get_first_m3u8(url):
# 取出第一层m3u8的真正下载地址
# 由于所得到的的url存在其他的字符,将它们进行删除
src_url = url.strip("/js/player/?url=")
src_url_2 = src_url.strip("&id=16721&num=1&count=6&vt=1")
# print(src_url_2)
return src_url_2
# 下载第m3u8文件
def download_m3u8_file(url, name):
res = requests.get(url) # 请求m3u8的url
with open(name,mode="wb") as f:
f.write(res.content)
async def download_ts(ts_url,name,session):
async with session.get(ts_url) as res_ts:
async with aiofiles.open(f"./m3u8/浴血黑帮第五季/{name}",mode="wb") as f:
await f.write(await res_ts.content.readany()) # 把下载到的内容写入文件中
print(f"{name}下载完毕!")
async def aio_download():
tasks = []
async with aiohttp.ClientSession() as session: # 因为有很多个视频片段所以提前准备好session
async with aiofiles.open("浴血黑帮第五季第一集_second_m3u8.txt",mode="r",encoding="utf-8") as f:
async for line in f:
if line.startswith("#"): #从第二层m3u8文件里读取文件内容,遇到#开始的内容就不要
continue
line = line.strip() # 去除空白换行符
name = line.rsplit("/",1)[1] # 取ts文件最后一个/后面的内容作为视频名字
task = asyncio.create_task(download_ts(line,name,session)) # 创建协程任务
tasks.append(task)
await asyncio.wait(tasks) #等待任务结束
def main(url):
# 1.拿到主页面的页面源代码,找到iframe对应的url
iframe_src = get_iframe_src(url)
# 2.拿到第一层的m3u8文件的下载地址
first_m3u8_url = get_first_m3u8(iframe_src)
# print(first_m3u8_url)
# 3.1下载第一层的m3u8文件
download_m3u8_file(first_m3u8_url,"浴血黑帮第五季第一集_first_m3u8.txt")
# 3.2下载第二层的m3u8文件
with open("浴血黑帮第五季第一集_first_m3u8.txt",mode="r",encoding="utf-8") as f2:
for line in f2:
if line.startswith("#"): # 读取本地文件,遇到#开始的内容不要
continue
else:
line = line.strip() # 去掉空白或换行符
# 拼接第二层m3u8的下载路径
second_m3u8_url = first_m3u8_url.split("/20201008")[0] +line
download_m3u8_file(second_m3u8_url,"浴血黑帮第五季第一集_second_m3u8.txt")
# print(second_m3u8_url)
# 4.下载视频
# 异步协程(利用异步协程下载速度会很快)
# 这俩个运行方法都会报警告,如果有大佬知道怎么解决希望能告知
# asyncio.run(aio_download())
loop = asyncio.get_event_loop()
loop.run_until_complete(aio_download())
if __name__ == '__main__':
url = "http://www.wbdy.tv/play/16721_1_1.html"
main(url)
print("下载完成!")
但这些视频不可播放,在第二层m3u8的文件里得知这些视频是被AES加密进行加密了

2.对视频进行解密
import asyncio
import aiofiles
import requests
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
# 得到秘钥
def get_key(url):
res = requests.get(url)
return res.text
async def dec_ts(name, key):
# 对key进行编码,不然会报错:Object type cannot be passed to C code
aes = AES.new(key=key.encode("utf-8"),IV=b"0102030405060708",mode=AES.MODE_CBC)
async with aiofiles.open(f"m3u8/浴血黑帮第五季/{name}",mode="rb") as f1,\
aiofiles.open(f"m3u8/浴血黑帮第五季/解密/{name}",mode="wb") as f2:
bs = await f1.read() # 从源文件获取
bs = pad(bs,16) # 对加密数据padding到16byte的整数倍,不然会报错:Data must be padded to 16 byte boundary in CBC mode
await f2.write(aes.decrypt(bs)) # 把解密好的内容写入文件
print(f"{name}处理完毕!")
async def aio_dec(key):
tasks = []
# 解密
async with aiofiles.open("浴血黑帮第五季第一集_second_m3u8.txt",mode="r",encoding="utf-8") as f:
async for line in f:
if line.startswith("#"):
continue
line = line.strip()
name = line.rsplit("/",1)[1]
# 创建异步任务
task = asyncio.create_task(dec_ts(name,key))
tasks.append(task)
await asyncio.wait(tasks) # 等待任务结束
if __name__ == '__main__':
# 5.1 拿到秘钥
# 从第二层m3u8文件里得到AES加密的url地址
key_url = "https://ts5.hhmm0.com:9999/20201008/hLgxAmB8/1000kb/hls/key.key"
key = get_key(key_url)
# 5.2 解密
loop = asyncio.get_event_loop()
loop.run_until_complete(aio_dec(key)) 因为视频是被AES进行加密,所以需要导入相关的库
![]()
如果不对加密数据填充到16byte的整数倍,会报错:
Data must be padded to 16 byte boundary in CBC mode
最后就是把视频合成了 ,你可以利用各种工具,也可以视频python的FFmpeg库,反正有手就行了。

新手一枚,还有很多不知,可以多交流交流!