【SpringBoot】SpringBoot——整合持久层技术
文章目录
- 5. 整合持久层技术
-
- 5.1 整合JdbcTemplate
- 5.2 整合MyBatis
- 5.3 Spring Data JPA
-
- 5.3.1 JPA、Spring Data、Spring Data JPA的故事
- 5.3.2 整合Spring Data JPA
- 5.3.3 CORS跨域配置
5. 整合持久层技术
持久层的实现是和数据库紧密相连的,在JAva领域内,访问数据库的通常做法是使用JDBC,JDBC使用灵活而且访问速度较快,但JDBC不仅需要操作对象,还需要操作关系,并不是完全面向对象编程。目前主流的持久层框架包括:MyBatis、JPA等。这些框架都对JDBC进行了封装,使得业务逻辑开发人员不再面对关系型操作,简化了持久型开发。
5.1 整合JdbcTemplate
Spring JDBC抽象框架core包提供了JDBC模板类,其中JdbcTemplate是core包的核心类,所以其他模板类都是基于它封装完成的。JDBC模板类是第一种工作模式。
JdbcTemplate类通过模板设计模式帮助我们消除了冗长的代码,只做需要做的事情(即可变部分),并且帮我们做了固定部分,如连接的创建及关闭等。
SpringBoot自动配置了JdbcTemplate数据模板。
-
配置文件
在application.yml中添加如下配置:
spring: datasource: url: jdbc:mysql://localhost:3306/test?serverTimezone=GMT%2B8 username: root password: admin123 driver-class-name: com.mysql.jdbc.DriverJDBC默认采用org.apache.tomcat.jdbc.pool.DataSource数据源,数据源的相关配置参考都封装在org.springframework.boot.autoconfigure.jdbc.DataSourceConfiguration类中。默认使用Tomcat连接池,可以使用spring.datasource.type指定自定义数据源类型。
SpringBoot默认支持的数据源:
- org.apache.tomcat.jdbc.pool.DataSource
- HikariDataSource
- BasicDataSource
-
整合Druid数据源
导入Druid依赖:
<dependency> <groupId>com.alibabagroupId> <artifactId>druidartifactId> <version>1.2.3version> dependency>修改application.yml配置文件:
spring: datasource: url: jdbc:mysql://localhost:3306/test?serverTimezone=GMT%2B8 username: root password: admin123 driver-class-name: com.mysql.jdbc.Driver type: com.alibaba.druid.pool.DruidDataSource tomcat: initial-size: 5 min-idle: 5 max-active: 20 max-wait: 60000 time-between-eviction-runs-millis: 60000 min-evictable-idle-time-millis: 300000 validation-query: SELECT 1 FROM DUAL test-on-borrow: false test-while-idle: true test-on-return: false dbcp2: pool-prepared-statements: true filter: stat: enabled:true log-show-sql:true wall: enabled:true配置type:com.alibaba.druid.pool.DruidDataSource来切换数据源,但是文件中数据源其他配置信息还不会起任何作用。
因为Druid是第三方数据源,在SpringBoot中并没有自动配置类,需要自己配置数据。所以我们需要自定义一个Druid数据源进行绑定:
package com.shenziyi.config; import com.alibaba.druid.pool.DruidDataSource; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class Config { /*把配置文件中的spring.datasource.initialSize等属性和DruidDataSource中属性进行绑定*/ @ConfigurationProperties(prefix = "spring.datasource") @Bean public DruidDataSource druidDataSource(){ return new DruidDataSource(); } }配置Druid的监控和过滤器:
package com.shenziyi.config; import com.alibaba.druid.support.http.StatViewServlet; import com.alibaba.druid.support.http.WebStatFilter; import org.springframework.boot.web.servlet.FilterRegistrationBean; import org.springframework.boot.web.servlet.ServletRegistrationBean; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import java.util.Arrays; import java.util.HashMap; import java.util.Map; @Configuration public class DruidConfig { /** * 配置Druid监控 * 1、配置一个管理后台的Servlet,拦截登录 * @return */ @Bean public ServletRegistrationBean statViewServlet(){ ServletRegistrationBean servletRegistrationBean=new ServletRegistrationBean(new StatViewServlet(),"/druid/*"); Map<String,String>initParams=new HashMap<>(); initParams.put("loginUsername","admin"); initParams.put("loginPassword","123456"); initParams.put("allow","");//允许所有访问 servletRegistrationBean.setInitParameters(initParams); return servletRegistrationBean; } @Bean public FilterRegistrationBean webStatFilter(){ FilterRegistrationBean bean=new FilterRegistrationBean(new WebStatFilter()); Map<String,String>initParams=new HashMap<>(); initParams.put("exclusions","*.js,*.css,/druid/*"); bean.setInitParameters(initParams); bean.setUrlPatterns(Arrays.asList("/*")); return bean; } }代码解释如下:
- @Configuration:@Configuration用于定义配置类,可替换XML配置文件,被注解的类内部包含一个或多个@Bean注解方法。可以被AnnotationConfigApplicationContext或者AnnotationConfigWebApplicationContext进行扫描。用于构建Bean定义及初始化Spring容器。
- @Bean:等同于XML配置文件中的< bean >配置。
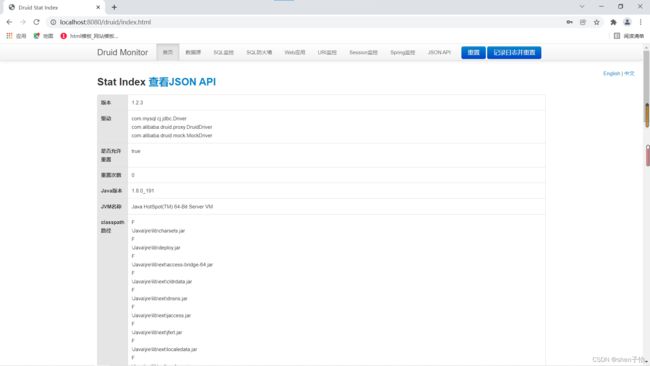
启动项目,当访问http://localhost:8080/druid时会进入监控的登录界面,如下:

登录成功之后,可以对数据源、SQL、Web应用等进行监控,如下:
5.2 整合MyBatis
MyBatis支持普通SQL查询,其存储过程和高级映射是优秀的持久层框架。MyBatis消除了绝大多数的JDBC代码和参数的手工设置及结果集的检索。MyBatis使用简单的XML或注解用于配置和原始映射,将接口和Java的POJOs(Plan Old Java Objects,普通的Java对象)映射成数据库中的记录。
JdbcTemplate虽然简单,但是用的并不多,因为它没有MyBatis方便,在Spring+Spring MVC中整合MyBatis步骤还是有点复杂,要配置多个Bean,SpringBoot中对此做了进一步简化,使MyBatis基本上可以做到开箱即用。
-
创建项目
创建SpringBoot Web项目,添加MyBatis、数据库驱动等依赖:
<dependency> <groupId>mysqlgroupId> <artifactId>mysql-connector-javaartifactId> dependency> <dependency> <groupId>org.mybatis.spring.bootgroupId> <artifactId>mybatis-spring-boot-starterartifactId> <version>2.1.0version> dependency> -
设计表和实体类
在test数据库中新建一张用户表user:(之前案例中已经建好)
表和数据准备好之后,在项目中新建User实体类(同上)
-
配置文件
在application.yml文件中配置数据库和MyBatis基本信息:
spring: datasource: url: jdbc:mysql://localhost:3306/test?serverTimezone=GMT%2B8&characterEncoding=utf-8 username: root password: admin123 driver-class-name: com.mysql.jdbc.Driver mybatis: mapper-locations: classpath:mappers/*.xml type-aliases-package: com.shenziyi.mapper configuration: map-underscore-to-camel-case: true -
编写Mapper接口
配置完成后,MyBatis就可以创建Mapper使用了,例如我们可以直接创建UserMapper接口:
package com.shenziyi.mapper; import com.shenziyi.entity.User; import org.apache.ibatis.annotations.Mapper; import java.util.List; @Mapper//指定这是一个操作数据库的mapper public interface UserMapper { List<User> findAll(); int addUser(User user); }代码解释如下:
- @Mapper:接口类上需要使用@Mapper注解,不然SpringBoot无法扫描到。
- 有两种方式指明该类是一个Mapper:一种方法是在上面的Mapper层对应的类上面添加@Mapper注解即可,但是这种方法有个弊端,当我们有很多个Mapper时,那么每一个类上面都需要添加@Mapper注解。另一种比较简单的方法是在SpringBoot启动类上添加@MapperScan注解,来扫描一个包下的所有的Mapper,如@MapperScan(“com.shenziyi.mapper”)表示扫描com.shenziyi.mapper包下所有为Mapper的接口。
-
Mapper映射
使用原始的XML方式,纯注解式不利于复杂SQL的编写,需要新建UserMapper.xml文件,在上面的application.yml配置文件中,我们已经定义了XML文件的路径:classpath:mappers/*.xml,所以在resources目录下新建一个mappers文件夹,然后创建一个UserMapper.xml文件:
DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace="com.shenziyi.mapper.UserMapper"> <resultMap id="UserResult" type="com.shenziyi.entity.User"> <id column="id" property="id" >id> <result column="name" property="name" >result> <result column="password" property="password" >result> resultMap> <select id="findAll" resultMap="UserResult"> SELECT * FROM user select> <insert id="addUser" parameterType="com.shenziyi.entity.User"> insert into user (name,password) values (#{name},#{password}); insert> mapper>注意:
- namespace中需要与使用@Mapper的接口对应。
- UserMapper.xml文件名称必须与使用@Mapper的接口一致。
- 标签中的id必须与@Mapper接口中的方法名一致,且参数一致。
-
创建Service和Controller
创建UserService和UserController类:
package com.shenziyi.service; import com.shenziyi.entity.User; import com.shenziyi.mapper.UserMapper; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import java.util.List; @Service public class UserService { @Autowired private UserMapper userMapper; public List<User> findAll() { return userMapper.findAll(); } public int addUser(User user){ return userMapper.addUser(user); } }
package com.shenziyi.controller; import com.shenziyi.entity.User; import com.shenziyi.service.UserService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.*; import java.util.List; @RestController @RequestMapping("/user") public class UserController { @Autowired private UserService userService; @RequestMapping("/findAll") public List<User> findAll(){ return userService.findAll(); } @PostMapping("/add") public String add( User user){ int i = userService.addUser(user); if (i>0) {return "success";} return "fail"; } } -
测试
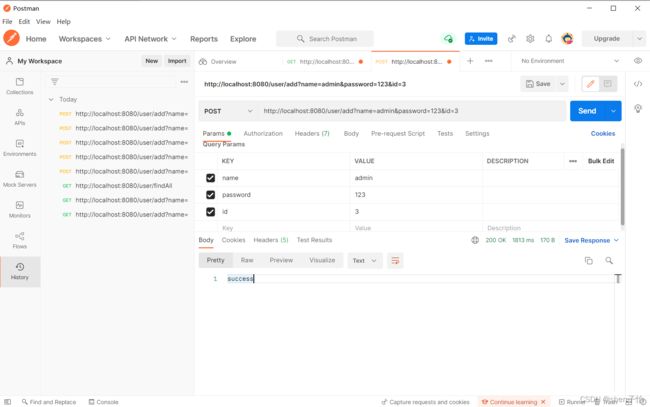
启动项目,在Postman中测试添加用户功能,如下所示,以及查询所有用户信息:(请忽略那些报错,因为作者对id好像是默认递增的,但我的数据库id只设置为非空,作者的示例代码没有对id的add,所以出了一些问题)

5.3 Spring Data JPA
Java持久层框架访问数据库的方式大致分为两种。一种以SQL核心,封装一定程度的JDBC操作,例如MyBatis。另一种以Java实体类为核心,将实体类和数据库表之间建立映射关系,也就是所说的ORM框架,如Hibernate、Spring Data JPA。
Spring Data JPA是建立在JPA基础上的。
5.3.1 JPA、Spring Data、Spring Data JPA的故事
-
什么是JPA?
JPA全称是Java Persistence API(Java持久层API),是一种Java持久化规范。它为Java开发人员提供了一种对象/关联映射工具,来管理Java应用中的关系数据。JPA吸取了目前Java持久化技术的优点,旨在规范、简化Java对象的持久化工作。很多ORM框架实现了JPA的规范,如Hibernate、EclipseLink。也就是JPA统一了Java应用程序访问ORM框架的规范,而Hibernate是一个ORM框架,Hibernate是JPA的一种实现,是一个框架。
-
什么是Spring Data?
Spring Data是Spring社区的一个子项目,主要用于简化数据访问,其主要目标是使数据库的访问变得方便快捷。它不仅支持关系型数据库,也支持非关系型数据库。
-
什么是Spring Data JPA?
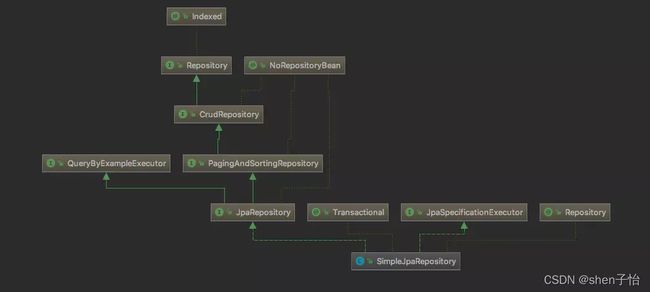
Spring Data JPA是在实现了JPA规范的基础上封装的一套JPA应用框架,虽然ORM框架都实现了JPA规范,但是在不同的ORM框架之间切换仍然需要编写不同的代码,而使用Spring Data JPA能够方便大家在不同的ORM框架之间进行切换而不需要更改代码。Spring Data JPA旨在通过将统一ORM框架的访问持久层的操作,来提高开发人员的效率。Spring Data JPA给我们提供的主要的类和接口如下:
(图片来源https://www.jianshu.com/p/c23c82a8fcfc)
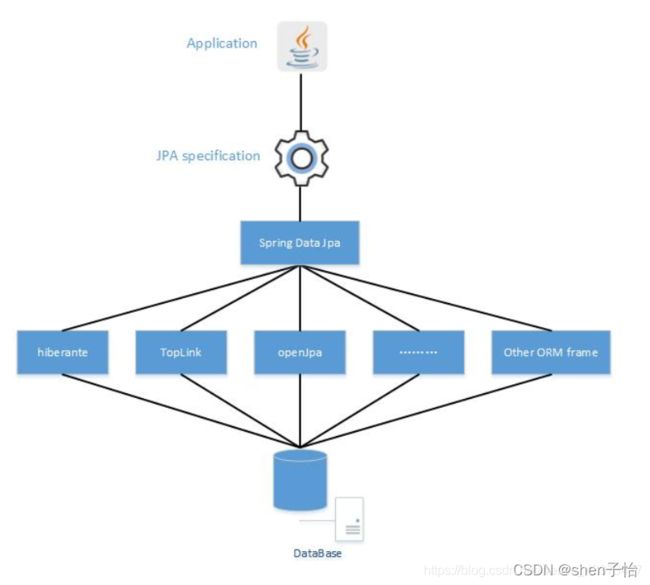
总的来说,JPA是ORM规范,Hibernate、TopLink等是JPA规范的具体实现,这样的好处是开发者可以面向JPA规范进行持久层的开发,而底层的实现则是可以切换的。Spring Data JPA则是在JPA之上的另一层抽象(Repository层的实现),极大的简化了持久层开发及ORM框架切换的成本,如下:
(图片来源:https://blog.csdn.net/weixin_43373417/article/details/107118137
JPA、Hibernate、Spring Data JPA之间的关系)
5.3.2 整合Spring Data JPA
本节主要介绍Spring Boot中集成Spring Data JPA、服务层类的开发,如何通过Spring Data JPA快速实现基本的增删改查以及自定义查询方法,步骤如下:
-
引入依赖:
<dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-data-jpaartifactId> dependency> <dependency> <groupId>mysqlgroupId> <artifactId>mysql-connector-javaartifactId> <scope>runtimescope> dependency> -
创建数据库:
只需要创建数据库,不需要创建表。当启动项目后,JPA会帮我们自动创建一个和实体类相对应的表。
-
配置文件:
在application.yml文件中添加如下配置:
server: port: 8080 servlet: context-path: / spring: datasource: url: jdbc:mysql://localhost:3306/jpa?serverTimezone=GMT%2B8&characterEncoding=utf-8 username: root password: admin123 jpa: database: MySQL database-platform: org.hibernate.dialect.MySQL5InnoDBDialect show-sql: true #日志中显示sql语句 hibernate: ddl-auto: update # 自动更新ddl-auto属性共有五个值:
- create:每次运行程序时,都会重新创建表,故而数据会丢失。
- create-drop:每次运行程序时会先创建表结构,然后待程序结束时清空表。
- update:每次运行程序,如果没有表则创建表,如果对象发生改变则更新表结构,原有数据不会清空,只会更新。(推荐)
- validate:运行程序会校验数据与数据库字段类型是否相同,字段不同会报错。
- none:禁用DDL处理。
-
实体类:
创建User实体类,代码如下:
package com.shenziyi.entity; import jdk.nashorn.internal.objects.annotations.Getter; import org.hibernate.annotations.GenericGenerator; import javax.persistence.*; @Entity @Table(name = "t_user") public class User { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Integer id; @Column(name = "username", unique = true, nullable = false, length = 64) private String username; @Column(name = "password", nullable = false, length = 64) private String password; @Column(name = "email", length = 64) private String email; public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getUsername() { return username; } public void setUsername(String username) { this.username = username; } public String getPassword() { return password; } public void setPassword(String password) { this.password = password; } public String getEmail() { return email; } public void setEmail(String email) { this.email = email; } } -
创建DAO层:
接着创建UserRepository接口,该接口只需继承JpaRepository接口,JpaRepository中封装了基本的数据操作方法,有基本的增删改查、分页、排序等:
public interface UserRepository extends JpaRepository<User, Integer> { // } -
Controller层:
这里为了结构简单省略Service层,创建UserController采用Restful风格实现增删改查:
package com.shenziyi.controller; import com.shenziyi.dao.UserRepository; import com.shenziyi.entity.User; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.data.domain.Page; import org.springframework.data.domain.PageRequest; import org.springframework.web.bind.annotation.*; import java.util.List; import java.util.Optional; @RestController @RequestMapping("/users") public class UserController { @Autowired private UserRepository userRepository; @PostMapping() //添加 public User saveUser(@RequestBody User user) { // response.setContentType("application/json;charset=UTF-8"); return userRepository.save(user); } @DeleteMapping("/{id}") //删除 public void deleteUser(@PathVariable("id") int id) { userRepository.deleteById(id); } @PutMapping("/{id}") public User updateUser(@PathVariable("id") int userId, @RequestBody User user) { user.setId(userId); return userRepository.saveAndFlush(user); } @GetMapping("/{id}") public User getUserInfo(@PathVariable("id") int userId) { Optional<User> optional = userRepository.findById(userId); return optional.orElseGet(User::new); } @GetMapping("/list") public Page<User> pageQuery(@RequestParam(value = "pageNum", defaultValue = "1") Integer pageNum, @RequestParam(value = "pageSize", defaultValue = "10") Integer pageSize) { return userRepository.findAll(PageRequest.of(pageNum - 1, pageSize)); } }上述类中使用的save()、deleteById()等方法是由JpaRepository接口提供的,可以很方便地使用。
-
测试:
启动程序,查询数据库就可以看到,JPA已经自动帮我们创建了表,如下:
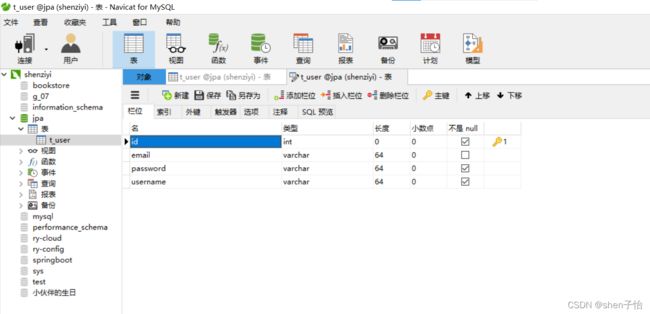
接下来使用Postman测试接口:
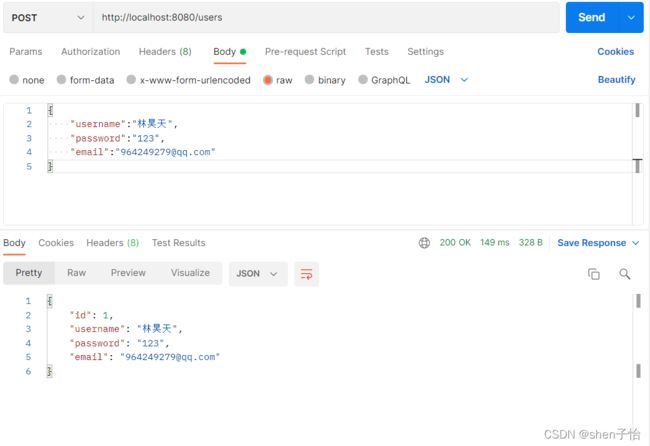
-
自定义查询方法
我们除了使用JpaRepository接口提供的方法之外还可以自定义查询方法。如我们要根据username和password查询User实例,可在UserController中添加一个Rest接口:
@PostMapping("/login") public User getPerson( String username,String password) { return userRepository.findByUsernameAndPassword(username, password); }并在UserRepository接口中添加如下查询方法:
/*相当于select * from t_user where username = ? and password = ?*/ User findByUsernameAndPassword(String username, String password);重启项目,在Postman中进行测试,如下:
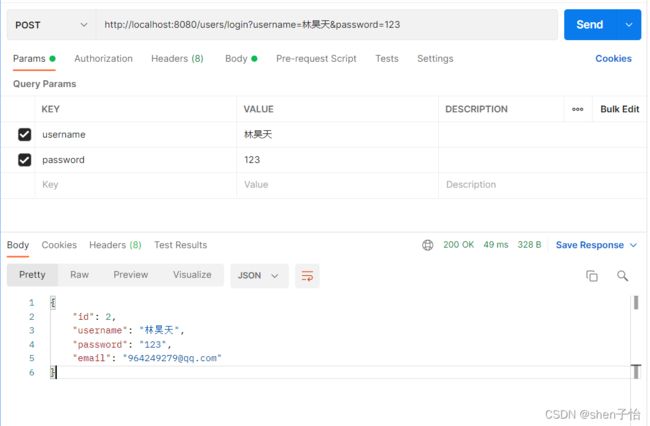
我们也可以在日志中看到Hibernate输出的SQL日志:Hibernate: select user0_.id as id1_0_, user0_.email as email2_0_, user0_.password as password3_0_, user0_.username as username4_0_ from t_user user0_ where user0_.username=? and user0_.password=?这是因为在Spring Data JPA中,只要自定义的方法符合既定规范,Spring Data就会分析开发者的意图,从而根据方法名生成相应的SQL查询语句。
JPA在这里遵循Convention over configuration(约定大约配置)的原则,遵循Spring及JPQL定义的方法命名。Spring提供了一套可以通过命名规则进行查询构建的机制。这套机制首先通过方法名过滤一些关键字,例如find…By、read…By、query…By、count…By和get…By。系统会根据关键字将命名解析成两个子语句,第一个By是区分这两个子语句的关键词。这个By之前的子语句是查询子语句(指明返回要查询的对象),后面部分是条件子语句。如果不区分就是find…By返回的就是定义Respository时指定的领域对象集合,同时JPQL中也定义了丰富的关键字:And、Or、Between等,Spring Data JPA支持的方法命名规则:
spring data JPA命名规范 关键字 方法命名 sql where字句 And findByNameAndPwd where name= ? and pwd =? Or findByNameOrSex where name= ? or sex=? Is,Equals findById,findByIdEquals where id= ? Between findByIdBetween where id between ? and ? LessThan findByIdLessThan where id < ? LessThanEquals findByIdLessThanEquals where id <= ? GreaterThan findByIdGreaterThan where id > ? GreaterThanEquals findByIdGreaterThanEquals where id > = ? After findByIdAfter where id > ? Before findByIdBefore where id < ? IsNull findByNameIsNull where name is null isNotNull,NotNull findByNameNotNull where name is not null Like findByNameLike where name like ? NotLike findByNameNotLike where name not like ? StartingWith findByNameStartingWith where name like '?%' EndingWith findByNameEndingWith where name like '%?' Containing findByNameContaining where name like '%?%' OrderBy findByIdOrderByXDesc where id=? order by x desc Not findByNameNot where name <> ? In findByIdIn(Collection c) where id in (?) NotIn findByIdNotIn(Collection c) where id not in (?) TRUE findByAaaTue where aaa = true FALSE findByAaaFalse where aaa = false IgnoreCase findByNameIgnoreCase where UPPER(name)=UPPER(?) -
自定义查询Using @Query
既定的方法命名规则不一定满足所有的开发需求,因此Spring Data JPA也支持自定义JPQL或者原生SQL。只需在声明的方法上标注@Query注解,同时提供一个JPQL查询语句即可。如需对username进行模糊查询,则需在UserRepository中添加如下代码:
@Query("select u from User u where u.username like %?1%") List<User> getUserByUsername(@Param("username") String username);接着在UserController中暴露接口:
@GetMapping("/ops") public List<User> getOPs( String username){ return userRepository.getUserByUsername(username); }
5.3.3 CORS跨域配置
在实际开发中我们经常会遇到跨域问题,跨域其实是浏览器对于Ajax请求的一种安全限制。目前比较常用的跨域解决方案有三种:
- Jsonp:最早的解决方案,利用script标签可以跨域的原理实现。
- nginx反向代理:利用nginx反向代理把跨域转为不跨域,支持各种请求方式。
- CORS:规范化的跨域请求解决方案,安全可靠。
这里采用CORS跨域方案。
CORS全称"跨域资源共享"(Cross-Origin Resource Sharing)。CORS需要浏览器和服务器同时支持,才可以实现跨域请求,目前绝大多数浏览器支持CORS,IE版本则不能低于IE10.CORS的整个过程都由浏览器自动完成,前端无需做任何设置,跟平时发送Ajax请求并无差异。实现CORS的关键在于服务器(后台),只要服务器实现CORS接口,就可以实现跨域通信。
Spring MVC已经帮我们写好了CORS的跨域过滤器:CorsFilter,内部已经实现了判定逻辑,我们直接使用即可。
-
配置CORS
在之前的基础上进行前后端分离开发,在该项目下新建GlobalCorsConfig类用于跨域的全局配置:
@Configuration public class GlobalCorsConfig { @Bean public CorsFilter corsFilter() { //1.添加CORS配置信息 CorsConfiguration config = new CorsConfiguration(); //1) 允许的域,不要写*,否则cookie就无法使用了 config.addAllowedOrigin("http://localhost:8081"); //2) 是否发送Cookie信息 config.setAllowCredentials(true); //3) 允许的请求方式 config.addAllowedMethod("OPTIONS"); config.addAllowedMethod("HEAD"); config.addAllowedMethod("GET"); config.addAllowedMethod("PUT"); config.addAllowedMethod("POST"); config.addAllowedMethod("DELETE"); config.addAllowedMethod("PATCH"); // 4)允许的头信息 config.addAllowedHeader("*"); //2.添加映射路径,我们拦截一切请求 UrlBasedCorsConfigurationSource configSource = new UrlBasedCorsConfigurationSource(); configSource.registerCorsConfiguration("/**", config); //3.返回新的CorsFilter. return new CorsFilter(configSource); } }配置完成后启动项目。
-
新建项目
新建一个Spring Boot Web项目,然后在resources/static目录下引入jquery.js,再在resources/static目录下创建index.html文件:
DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Titletitle> <script src="jquery-1.8.3.js">script> head> <body> <input type="button" value="添加数据" onclick="addUser()"><br> <input type="button" value="删除数据" onclick="deleteUser()"> <script> function addUser() { $.ajax({ type:'post', /*访问5.3.2小节项目中的添加接口*/ url:'http://localhost:8080/users', data:JSON.stringify({ "username":"admin", "password":"123456", "email":"635498720" }), dataType: "json", contentType:"application/json;charset=UTF-8", success:function (msg) { } }) } function deleteUser() { $.ajax({ type:'delete', /*访问5.3.2小节项目中的删除接口*/ url:'http://localhost:8080/users/5', success:function (msg) { } }) } script> body> html>在该文件中两个Ajax分别发送了跨域请求,请求5.3.2中添加和删除接口,然后在该项目中把端口设置为8081:
server.port=8081 -
测试
启动项目,在浏览器输入http://localhost:8081/index.html,查看页面如下:
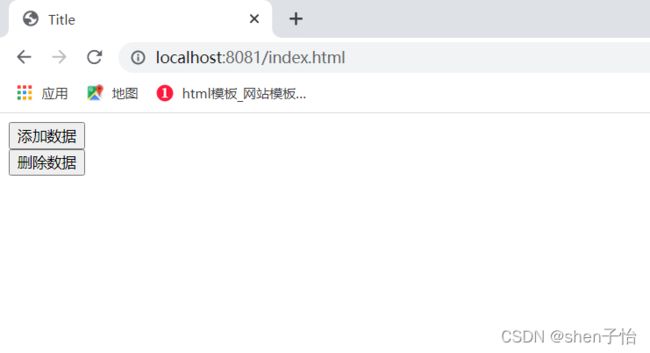
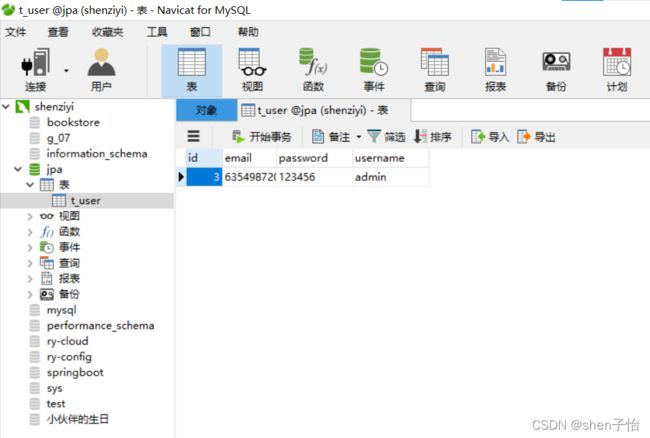
单击"添加数据"按钮,查看数据库变化:

单击"删除数据"按钮:(报错,因为数据库没有id为5的元组)

修改一下代码,删除id为2的元组,结果如下:
总的来说,CORS的配置完全在后端设置,配置起来比较容易,目前对于大部分浏览器的兼容性也比较好。CORS的优势也比较明显,可以实现任何类型的请求,相较于Jsonp跨域只能使用GET请求来说,更加便于使用。