大数据高级开发工程师——Spark学习笔记(1)
文章目录
- Spark内存计算框架
-
- Spark Core
-
- Spark 是什么?
- 四大特性
-
- 1. 速度快
- 2. 易用性
- 3. 通用性
- 4. 兼容性
- 内置组件
-
- 1. 集群资源管理
- 2. Spark Core(核心库)
- 3. Spark SQL(SQL解析)
- 4. Spark Streaming(实时处理)
- 5. Spark MLlib(机器学习)
- 6. Spark GraphX(图计算)
- 集群架构及核心概念
-
- 1. 集群架构
- 2. 核心概念
- Spark 集群
-
- 1. 搭建 Spark 集群
- 2. Spark 集群的启动
- 3. Spark 集群的停止
- 4. Spark 集群的 web 管理界面
- 5. 问题
- 任务提交 Spark-Submit
-
- 1. Spark-Submit 语法
- 2. 参数含义
- 运行模式
-
- 1. Local 模式
- 2. Standalone模式
- 3. Yarn模式
- Spark-Shell
-
- 1. WordCount案例
- 2. WordCount案例分析
- 3. Shuffle洗牌
- 使用 IDEA 开发 Spark
-
- 1. 使用 Java 语言开发
- 2. 使用 Scala 语言开发
- 3. 上传 jar 包提交 spark 任务
Spark内存计算框架
- spark 组成:
- spark core:核心模块
- spark sql:支持SQL
- spark streaming:支持流计算
- spark graphx:支持图计算
- spark mllib:支持机器学习
Spark Core
Spark 是什么?
- 官方网站

- Spark是一个快速(基于内存),通用、可扩展的计算引擎,采用Scala语言编写。
- 2009年诞生于UC Berkeley(加州大学伯克利分校,CAL的AMP实验室),2010年开源,2013年6月进入Apach孵化器。
- 同年由美国伯克利大学 AMP 实验室的 Spark 大数据处理系统多位创始人联合创立Databricks(属于 Spark 的商业化公司-业界称之为数砖-数据展现-砌墙-侧面应正其不是基石,只是数据计算)。
- 2014年成为 Apache 顶级项目,自2009年以来,已有1200多家开发商为Spark出力!
- Spark 支持 Java、Scala、Python、R、SQL 语言,并提供了几十种(目前80+种)高性能的算法,这些如果让我们自己来做,几乎不可能。
- Spark 得到众多公司支持,如:阿里、腾讯、京东、携程、百度、优酷、土豆、IBM、Cloudera、Hortonworks 等。
- Spark 是在 Hadoop 基础上的改进,是 UC Berkeley AMP lab 所开源的类 Hadoop MapReduce 的通用的并行计算框架,Spark 基于 map reduce 算法实现的分布式计算,拥有 Hadoop MapReduce 所具有的优点;但不同于 MapReduce 的是 Job 中间输出和结果可以保存在内存中,从而不再需要读写 HDFS,因此 Spark 能更好地适用于数据挖掘与机器学习等需要迭代的 map reduce 的算法。
- Spark 是基于内存计算框架,计算速度非常之快,但是它仅仅只是涉及到计算,并没有涉及到数据的存储,后期需要使用 spark 对接外部的数据源,比如 hdfs。
这里有个疑问?内存不够怎么办呢?
Does my data need to fit in memory to use Spark? 我的数据需要放入内存才能使用Spark吗?
No. Spark’s operators spill data to disk if it does not in memory, allowing it to run well on any sized data. Likewise, cached datasets that do not fit in memory are either spilled to disk or recomputed on the fly when needed, as determined by the RDD’s storage level.
不会。如果不合适存储在内存,那么Spark的操作员会将数据溢写到磁盘上,这样就可以不管数据大小如何而良好运行。同样,不适合内存的缓存数据集要么溢出到磁盘,要么在需要时实时重新计算,这由RDD的存储级别决定。
四大特性
1. 速度快

- 运行速度提高100倍(针对hadoop2.x比较,而hadoop3.x号称比spark又快10倍)
- Apache Spark 使用最先进的 DAG 调度程序,查询优化程序和物理执行引擎,实现批量和流式数据的高性能。
- spark 比 mapreduce 快的 2 个主要原因:
- 基于内存:mapreduce 任务后期再计算的时候,每一个 job 的输出结果会落地到磁盘,后续有其他的job 需要依赖于前面 job 的输出结果,这个时候就需要进行大量的磁盘 io 操作,性能就比较低。spark 任务后期再计算的时候,job 的输出结果可以保存在内存中,后续有其他的 job 需要依赖于前面 job 的输出结果,这个时候就直接从内存中获取得到,避免了磁盘 io 操作,性能比较高。对于spark程序和mapreduce程序都会产生shuffle阶段,在shuffle阶段中它们产生的数据都会落地到磁盘。
- 进程与线程:mapreduce任务以进程的方式运行在 yarn 集群中,比如程序中有100个MapTask,一个 task 就需要一个进程,这些task要运行就需要开启100个进程。spark 任务以线程的方式运行在进程中,比如程序中有100个 MapTask,后期一个 task 就对应一个线程,这里就不在是进程,这些 task 需要运行,这里可以极端一点:只需要开启1个进程,在这个进程中启动100个线程就可以了。进程中可以启动很多个线程,而开启一个进程与开启一个线程需要的时间和调度代价是不一样。 开启一个进程需要的时间远远大于开启一个线程。
2. 易用性

- 可以快速去编写spark程序通过 java/scala/python/R/SQL 等不同语言。
3. 通用性

- spark 框架不在是一个简单的框架,可以把 spark 理解成一个生态系统,它内部是包含了很多模块,基于不同的应用场景可以选择对应的模块去使用:
- spark sql:通过sql去开发spark程序做一些离线分析
- spark streaming:主要是用来解决公司有实时计算的这种场景
- spark graphx:支持图计算
- spark mllib:它封装了一些机器学习的算法库
4. 兼容性

- Spark运行在 Hadoop、ApacheMesos、Kubernetes、单机版或云中。它可以访问不同的数据源:
-
standAlone:它是 spark 自带的独立运行模式,整个任务的资源分配由 spark 集群的老大 Master 负责
-
yarn:可以把 spark 程序提交到 yarn 中运行,整个任务的资源分配由 yarn 中的老大 ResourceManager 负责
-
mesos:它也是 apache 开源的一个类似于 yarn 的资源调度平台
-
cassandra:是一套开源分布式 NoSQL 数据库系统
-
kubernetes:用于管理云平台中多个主机上的容器化的应用
-
hbase:是一个分布式的、面向列的开源数据库
-
内置组件
- 机器学习(MLlib),图计算(GraphicX),实时处理(SparkStreaming),SQL解析(SparkSql)
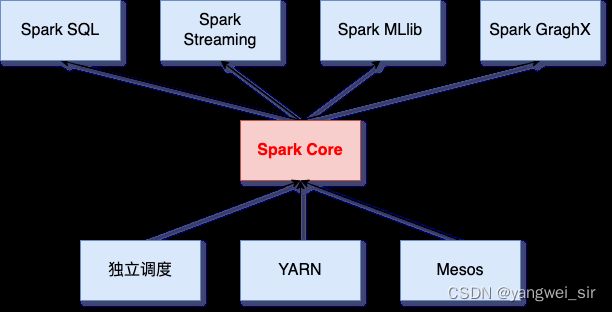
1. 集群资源管理
- Spark 设计为可以高效的在一个计算节点到数千个计算节点之间伸缩计算,为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群资源管理器上运行,目前支持的3种如下:(上图中下三个)
- Hadoop YARN(国内几乎都用)
- 可以把 spark 程序提交到 yarn 中运行,整个任务的资源分配由 yarn 中的老大 ResourceManager 负责
- Apach Mesos(国外使用较多)
- 它也是 apache 开源的一个类似于 yarn 的资源调度平台。
- Standalone(Spark自带的资源调度器,需要在集群中的每台节点上配置 Spark)
- 它是 spark 自带的集群模式,整个任务的资源分配由 spark 集群的老大 Master 负责
- Hadoop YARN(国内几乎都用)
2. Spark Core(核心库)
- 实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。
- 其中还包含了对**弹性分布式数据集(RDD:Resilient Distributed DataSet)**的API定义
3. Spark SQL(SQL解析)
- 是Spark用来操作结构化数据的程序包,通过Spark SQL 我们可以使用SQL或者HQL来查询数据。
- 且支持多种数据源:Hive、Parquet、Json等
4. Spark Streaming(实时处理)
- 是Spark提供的对实时数据进行流式计算的组件
5. Spark MLlib(机器学习)
- 提供常见的机器学习功能和程序库,包括分类、回归、聚类、协同过滤等。还提供了模型评估、数据导入等额外的支持功能。
6. Spark GraphX(图计算)
- 用于图形和图形并行计算的API。
集群架构及核心概念
1. 集群架构
- 执行架构图:

- 执行流程图:

- 应用结构图:

2. 核心概念
- 结合下图,理解这些核心概念

- Master
- Spark Standalone 模式下,Spark 特有的资源调度系统 Leader,掌控整个集群资源信息,类似于 Yarn 框架中的 ResourceManager
- 监听 Worker,检测 Worker 是否正常工作
- Master 对 Worker、Application 等的管理(接收 Worker 的注册并管理所有的 Worker,接收 Client 提交的 Application,调度等待 Application 并向 Worker 提交)
- Worker
- Spark Standalone 模式下,Spark 特有的资源调度 Slave,有多个。每个 Slave 掌握着所在节点的资源信息,类似于 Yarn 框架的 NodeManager
- 通过 RegisterWorker 注册到 Master
- 定时发送心跳给 Master
- 根据 Master 发送的 Application 配置进程环境,并启动 ExecutorBackend(执行 Task 所需的计算任务进程)
- Driver
- Spark 的驱动器,是执行开发程序中的 main 方法的线程
- 负责开发人员编写 SparkContext、RDD,以及进行 RDD 操作的代码执行
- 如果使用 Spark Shell,那么启动时后台自启动了一个 Spark 驱动器,预加载一个叫做 sc 的 SparkContext 对象(该对象是所有 spark 程序的执行入口),如果驱动器终止,那么 Spark 应用也就结束了
- 四大主要职责:
- 将用户程序转化为作业(Job)
- 在 Executor 之间调度任务(Task)
- 跟踪 Executor 的执行情况
- 通过 UI 展示查询运行情况
- Executor
- Spark Executor 是一个工作节点,负责在 Spark 作业中运行任务,任务间相互独立
- Spark 应用启动时,Executor 被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在
- 如果有 Executor 节点发生了故障或崩溃,Spark 应用也可以继续进行,会将出错节点上的任务调度到其它 Executor 节点上继续运行
- 两个核心功能:
- 负责运行组成 Spark 应用的任务,并将结果返回给驱动器(Driver)
- 它通过自身块管理器(BlockManager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
- RDDs
- Resilient Distributed DataSet:弹性分布式数据集
- 一旦拥有 SparkContext 对象,就可以用它来创建 RDD
- Application应用
- 一个 SparkContext 就是一个 Application(一个 Spark 的应用程序),它是包含了客户端的代码和任务运行的资源信息
- Job作业
- 一个行动算子(Action)就是一个 Job
- Stage阶段
- 一次宽依赖(一次 Shuffle)就是一个 Stage,划分是从后往前划分
- Task任务
- Spark 任务是以 Task 线程的方式运行在 Worker 节点对应的 Executor 进程中
- 一个核心就是一个 Task,体现任务的并行度
Spark 集群
1. 搭建 Spark 集群
实现要搭建好 Zookeeper 和 Hadoop 集群
- 下载安装包:这里选择 spark-2.3.3-bin-hadoop2.7.tgz 安装包
# 在 node01 的 /bigdata/soft 目录下载
wget https://archive.apache.org/dist/spark/spark-2.3.3/spark-2.3.3-bin-hadoop2.7.tgz
- 解压缩到指定安装目录
tar -zxvf spark-2.3.3-bin-hadoop2.7.tgz -C /bigdata/install
- 修改配置文件
spark-env.sh:进入到 spark 安装目录下对应的 conf 目录,先在 node01 进行如下文件的修改
# 修改 spark-env.sh
$ pwd
/bigdata/install/spark-2.3.3-bin-hadoop2.7/conf
$ cp spark-env.sh.template spark-env.sh
$ vim spark-env.sh
# 配置 JAVA 的环境变量
export JAVA_HOME=/usr/apps/jdk1.8.0_241
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log"
# 配置 ZK 相关信息
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark"
- 修改配置文件
slaves
$ cp slaves.template slaves
$ vim slaves
# 指定spark集群的worker节点
node01
node02
node03
- 修改配置文件
spark-defaults.conf
$ cp spark-defaults.conf.template spark-defaults.conf
$ vim spark-defaults.conf
# 修改内容如下
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:8020/spark_log
spark.eventLog.compress true
# 如果 spark 运行过程中报 lzo 错误,将以下两项添加进来
spark.driver.extraClassPath /bigdata/install/hadoop-3.1.4/share/hadoop/common/hadoop-lzo-0.4.20.jar
spark.executor.extraClassPath /bigdata/install/hadoop-3.1.4/share/hadoop/common/hadoop-lzo-0.4.20.jar
- 然后分发 spark 安装目录到 node02、node03
$ cd /bigdata/install/
$ scp -r spark-2.3.3-bin-hadoop2.7/ node02:$PWD
$ scp -r spark-2.3.3-bin-hadoop2.7/ node03:$PWD
- hdfs创建spark日志文件夹
hdfs dfs -mkdir -p /spark_log
- 配置环境变量
$ sudo su
# vim /etc/profile
# 配置Spark环境变量
export SPARK_HOME=/bigdata/install/spark-2.3.3-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
# source /etc/profile
2. Spark 集群的启动
- 先确保 ZK 集群、Hadoop 集群正常启动,可以在任意一台服务器执行如下启动命令(条件是需要任意2台机器之间实现ssh免密登录)
# node01 执行
$ pwd
/bigdata/install/spark-2.3.3-bin-hadoop2.7/sbin
# 在哪里启动start-all.sh脚本,就在当前该机器启动一个Master进程,整个集群的worker进程的启动由 workers 文件决定
$ ./start-all.sh
# 启动历史服务
$ ./start-history-server.sh
- 后期可以在其他机器单独在启动master:
$SPARK_HOME/sbin/start-master.sh - 进程查看
xcall jps

3. Spark 集群的停止
- 在处于 active Master 主节点执行:
$SPARK_HOME/sbin/stop-all.sh
- 在处于 standBy Master 主节点执行:
$SPARK_HOME/sbin/stop-master.sh
4. Spark 集群的 web 管理界面
- 访问master主节点web管理界面:http://node01:8080/,如果发现 8080 端口被占用,可以尝试 8081、8082、。。 端口


- 可以通过这个web界面观察到很多信息:
- 整个spark集群的详细信息
- 整个spark集群总的资源信息
- 整个spark集群已经使用的资源信息
- 整个spark集群还剩的资源信息
- 整个spark集群正在运行的任务信息
- 整个spark集群已经完成的任务信息
- 访问 history server 界面:http://node01:4000/
5. 问题
如何恢复到上一次活着的 master 挂掉之前的状态?
- 在高可用模式下,整个 spark 集群就有很多个 master,其中只有一个 master 被 zk 选举成活着的 master,其他的多个 master 都处于standby,同时把整个 spark 集群的元数据信息通过 zk 中节点进行保存。
- 后期如果活着的 master 挂掉。首先 zk 会感知到 active 的 master 挂掉,下面开始在多个处于 standby 中的 master 进行选举,再次产生一个 active 的 master,这个 active 的 master 会读取保存在 zk 节点中的 spark 集群元数据信息,恢复到上一次 master 的状态。
- 整个过程在恢复的时候经历过了很多个不同的阶段,每个阶段都需要一定时间,最终恢复到上个 active 的 master 的状态,整个恢复过程一般需要 1-2 分钟。
在master的恢复阶段对任务的影响?
- 对已经运行的任务是没有任何影响的:由于该任务正在运行,说明它已经拿到了计算资源,这个时候就不需要master。
- 对即将要提交的任务是有影响:由于该任务需要有计算资源,这个时候会找活着的 master 去申请计算资源,由于没有一个活着的 master,该任务是获取不到计算资源,也就是任务无法运行。
任务提交 Spark-Submit
1. Spark-Submit 语法
spark-submit \
--class <main-calss> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... #其他 options
<application-jar> \
[application-arguments]
2. 参数含义
| 参数名称 | 参数含义 | 参数默认值 | 适用模式 |
|---|---|---|---|
| –master | 指定主节访问路径 | spark://host:port, mesos://host:port, yarn, k8s, or local 默认local[*] |
不同模式 使用不同值 |
| –deploy-mode | 部署模式 | client ,cluster(默认client模式) | standAlone, on yarn |
| –class | 指定main方法所在的class类 | 无默认值 | 同上 |
| –name | application的名称 | 任意给定的名称 | 同上 |
| –jars | 使用逗号隔开的列表 用以指定多个依赖的外部jar包 |
无默认值 | 同上 |
| –packages | 通过maven坐标来搜索jar包 | 无默认值,一般不用这个参数 | 同上 |
| –exclude-packages | 排除掉某些jar包 | 无默认值 | 同上 |
| –repositories | 与–packages参数搭配使用 用于搜索指定远程仓库 |
无默认值,一般不用这个参数 | 同上 |
| –files | 逗号隔开的文件列表 用于传递文件到executor里面去 |
无默认值,可以用作广播变量 | 同上 |
| –conf | 指定spark的配置项 | 无默认值 | 同上 |
| –properties-file | 指定spark的配置文件 | 无默认值 | 同上 |
| –driver-memory | driver端内存大小 | 默认1024M,可以指定2G | 同上 |
| –driver-java-options | 额外的jar的配置选项传递到driver端 | 无默认值 | 同上 |
| –driver-library-path | driver端额外指定的jar包路径 | 无默认值 | 同上 |
| –driver-class-path | 为driver端指定额外的class文件 | 无默认值 | 同上 |
| –executor-memory | 每个executor的内存大小 | 默认 1G | 同上 |
| –proxy-user | 指定代理提交用户 | 无默认值 | 同上 |
| –driver-cores | driver的CPU核数 | 默认值 1 | cluster模式 |
| –supervise | 如果指定这个参数 任务失败就重启driver端 |
无默认值 | Spark standAlone cluster模式 |
| –kill | 杀死指定的driver | 无默认值 | 同上 |
| –status | 查看driver的状态 | 无默认值 | 同上 |
| –total-executor-cores | 总共分配多少核CPU给所有的executor | 无默认值 | Spark standalone |
| –executor-cores | 每个executor分配的CPU核数 | standAlone on yarn | |
| –queue | 提交到哪个yarn队列 | yarn | |
| –num-executors | 启动的executor的个数 | yarn | |
| –archives | 逗号隔开的列表 | yarn |
运行模式
1. Local 模式
- Local模式(单机)就是在一台计算机上运行Spark,通常用于开发中。
- Submit 提交方式-示例:
$ pwd
/bigdata/install/spark-2.3.3-bin-hadoop2.7
$ spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local \
--executor-memory 2G \
--total-executor-cores 4 \
examples/jars/spark-examples_2.11-2.3.3.jar \
10

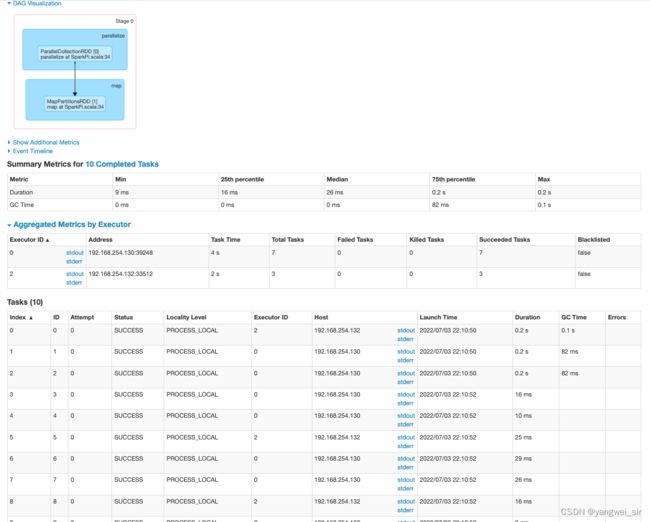
- 在历史服务查看:

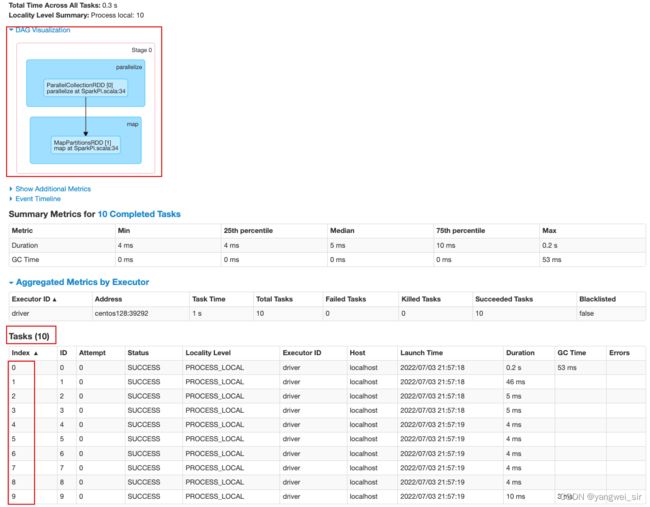
2. Standalone模式
- 构建一个由 Master + Slave 构成的Spark集群,Spark运行在集群中,只依赖Spark,不依赖别的组件(如:Yarn)。(独立的Spark集群)
- Standalone-Client
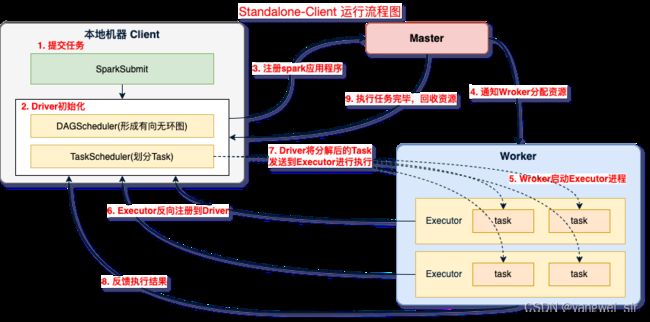
- 执行流程:
- ① spark-submit 提交任务,启动应用程序;
- ② Driver 初始化,在 SparkContext 启动过程中,先初始化 DAGScheduler 和 TaskSchedulerImpl 两个调度器;
- ③ Driver 向 Master 注册应用程序,Master 收到注册消息后把应用放到待运行应用列表;
- ④ Master 使用自己的资源调度算法分配 Worker 资源给应用程序;
- ⑤ 应用程序获得 Worker 时,Master 会通知 Worker 中的 WorkerEndpoint 创建CoarseGrainedExecutorBackend 进程,在该进程中创建执行容器Executor;
- ⑥ Executor 创建完毕后发送消息到 Master 和 DriverEndpoint,在SparkContext创建成功后, 等待Driver端发过来的任务;
- ⑦ SparkContext 分配任务给 CoarseGrainedExecutorBackend 执行,在 Executor 上按照一定调度执行任务(这些任务就是代码);
- ⑧ CoarseGrainedExecutorBackend 在处理任务的过程中把任务状态发送给 SparkContext,SparkContext 根据任务不同的结果进行处理,如果任务集处理完毕后,则继续发送其他任务集;
- ⑨ 应用程序运行完成后,SparkContext会进行资源回收。
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node01:7077 \
--deploy-mode client \
--executor-memory 2G \
--total-executor-cores 4 \
examples/jars/spark-examples_2.11-2.3.3.jar \
10
# 多master提交
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node01:7077,node02:7077 \
--deploy-mode client \
--executor-memory 2G \
--total-executor-cores 4 \
examples/jars/spark-examples_2.11-2.3.3.jar \
10

- Standalone-Cluster

spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node01:7077,node02:7077 \
--deploy-mode cluster \
--executor-memory 2G \
--total-executor-cores 4 \
examples/jars/spark-examples_2.11-2.3.3.jar \
10
spark集群中有很多个master,并不知道哪一个master是活着的master,即使你知道哪一个master是活着的master,它也有可能下一秒就挂掉,这里就可以把所有master都罗列出来
–master spark://node01:7077,node02:7077
后期程序会轮训整个master列表,最终找到活着的master,然后向它申请计算资源,最后运行程序。

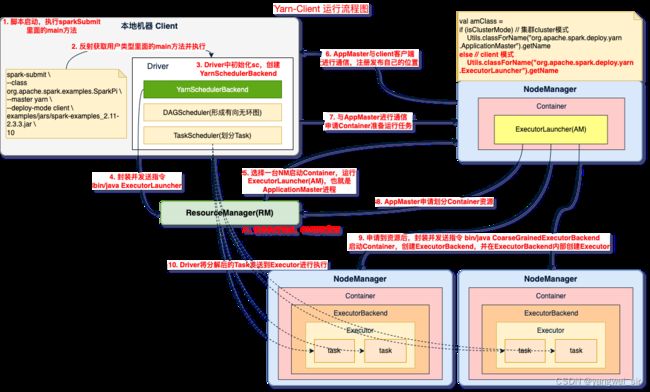
3. Yarn模式
- Spark 客户端可以直接连接 Yarn,不需要构建 Spark 集群。有yarn-client和yarn-cluster两种模式,主要区别在:Driver 程序的运行节点不同。
- ① yarn-client:Driver 程序运行在客户端,适用于交互、调试,希望立即看见APP输出;
- ② yarn-cluster:Driver 程序运行在由 ResourceManager 启动的 ApplicationMaster 上,适用于生产环境。
- 参考文档:http://spark.apache.org/docs/2.3.3/running-on-yarn.html

- 需要在 spark-env.sh 文件中添加:
export HADOOP_CONF_DIR=/bigdata/install/hadoop-3.1.4/etc/hadoop
- 客户端模式:Driver 是在 Client 端,日志结果可以直接在后台看见
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
examples/jars/spark-examples_2.11-2.3.3.jar \
10


- 如果想从 yarn 界面的 history 链接跳转到上图,需要在 spark 的 spark-defaults.conf 中添加两项
# 告诉yarn要跳转的spark的historyServer地址
spark.yarn.historyServer.address=node01:4000
# 设置spark的historyServer端口
spark.history.ui.port=4000
- 集群模式:Driver 是在 NodeManager 端,日志结果需要通过监控日志查看
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
examples/jars/spark-examples_2.11-2.3.3.jar \
10
- 总结:
- client 模式主要用来提交代码,查看结果,公司中常使用一台单独的提交机器来进行任务提交。
- cluster模式主要用在一些数据持久化,不需要查看结果的情况。
Spark-Shell
1. WordCount案例
- 数据准备
# 创建 word.txt 文件
vim words.txt
# 内容如下
hadoop flink spark
hive flink spark
flink datax
- 数据上传到 hadoop 集群
hadoop dfs -put words.txt /
- Spark 客户端连接
spark-shell
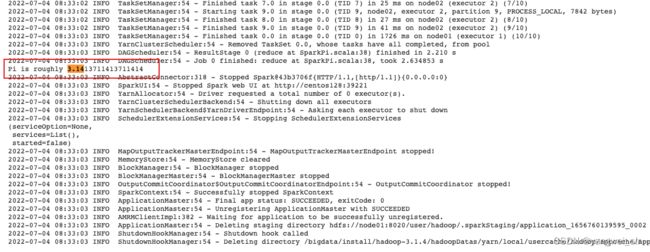
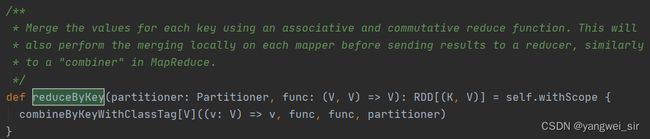
scala> sc.textFile("/words.txt").flatMap(line => line.split(' ')).map((_,1)).reduceByKey(_ + _).collect

- 每个 Spark 应用程序都包含一个驱动程序,驱动程序负责把并行操作发布到集群上,驱动程序包含 Spark 应用中的主函数,定义了分布式数据集以应用在集群中,在 wordcount 案例中,spark-shell 就是我们的驱动程序,所以我们键入我们任何想要的操作,然后由它负责发布,驱动程序通过 SparkContext 对象来访问Spark,SparkContext 对象相当于一个到 Spark 集群的链接。
2. WordCount案例分析
- 根据 spark-shell 提供的 UI 进入查看应用,或者应用执行完后,停止 spark-shell 进入历史日志 UI 查询。
- 一个行动算子 collect() 对应一个 job,如下源码中可以看出 runJob:

- 一次宽依赖 shuffle 算子 reduceByKey(),切分成 2 个 Stage 阶段,如下源码中很明显可以看出有 Shuffle 参与:
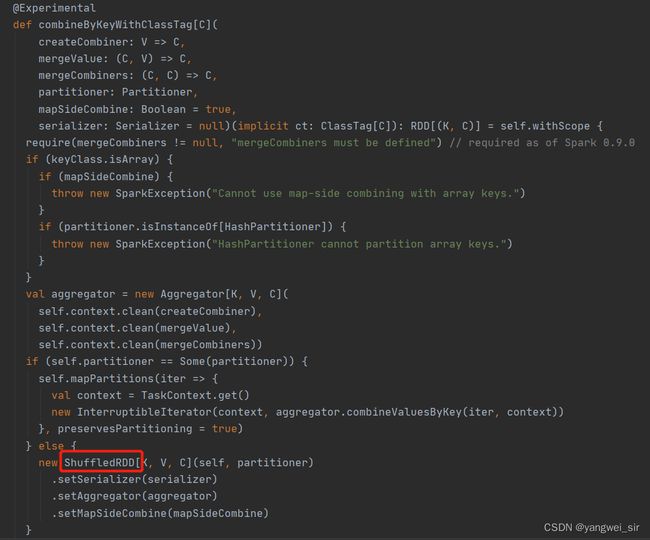

- Stage阶段,默认文件被切分成2份,所以有2个task
- Stage 0 阶段:

- Stage 1 阶段:

3. Shuffle洗牌

- 在划分 stage 时,最后一个 stage 称为 FinalStage,本质上是一个 ResultStage 对象,前面所有的 stage 被称为 ShuffleMapStage
- ShuffleMapStage 的结束伴随着 shuffle 文件写磁盘
- ResultStage 对应代码中的 action 算子,即将一个函数应用在 RDD 的各个 Partition(分区)的数据集上,意味着一个 Job 运行结束
使用 IDEA 开发 Spark
- 构建maven工程,添加pom依赖
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>2.3.3version>
dependency>
1. 使用 Java 语言开发
- 数据准备:在 resources 文件夹下,新建 word.csv 文件
hello,spark
hello,scala,hadoop
hello,hdfs
hello,spark,hadoop
hello
- 代码实现:
public class JavaWordCount {
public static void main(String[] args) {
// 1. 创建 SparkConf 对象
SparkConf sparkConf = new SparkConf()
.setAppName(JavaWordCount.class.getSimpleName())
.setMaster("local[*]");
// 2. 构建 JavaSparkContext 对象
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
// 3. 读取数据文件
JavaRDD<String> lines = jsc.textFile(ClassLoader.getSystemResource("word.csv").getPath());
// 4. 切分每一行获取所有的单词
// 将每行数据,生成一个由单词组成的数组;然后每行组成的数组进行 flat,生成最终的所有的单词组成的数组 ==>> RDD
JavaRDD<String> words = lines.flatMap(line -> Arrays.asList(line.split(",")).iterator());
// 5. 将单词变成(word, 1)
JavaPairRDD<String, Integer> wordAndOne = words.mapToPair(word -> new Tuple2<>(word, 1));
// 6. 将 wordAndOne 按照 key 分组,每组 value 进行聚合
JavaPairRDD<String, Integer> wordAndTotal = wordAndOne.reduceByKey(Integer::sum);
// 7. 结果,按照每组的个数进行排序
/**
* (hadoop, 2) (hive, 1)
* (spark, 3) ==>> (hadoop, 2)
* (hive, 1) (spark, 3)
*
* ① 为了实现按照数值进行排序的功能,首先将每个kv对的kv进行调换位置 (hadoop, 2) 变成了(2, hadoop)
* ② 然后按照k进行排序(这是的key是数值) (2, hadoop)
* ③ 排完顺序后,再将kv调换顺序,(word, totalCount)的形式
*/
JavaPairRDD<Integer, String> totalAndWord = wordAndTotal.mapToPair(v -> new Tuple2<>(v._2, v._1));
JavaPairRDD<Integer, String> sortedTotalAndWord = totalAndWord.sortByKey(true);
JavaPairRDD<String, Integer> sortedResult = sortedTotalAndWord.mapToPair(v -> new Tuple2<>(v._2, v._1));
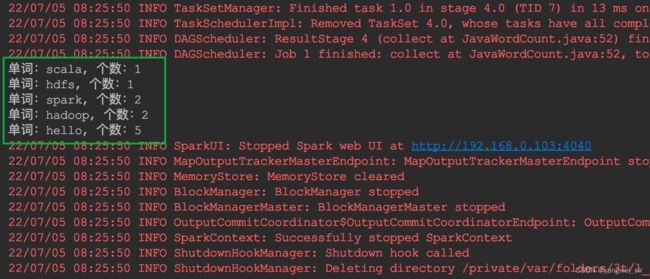
List<Tuple2<String, Integer>> result = sortedResult.collect();
for (Tuple2<String, Integer> tuple2 : result) {
System.out.println("单词:" + tuple2._1 + ", 个数:" + tuple2._2);
}
jsc.stop();
}
}
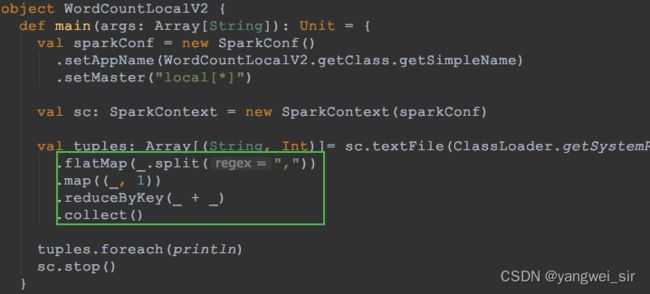
2. 使用 Scala 语言开发
object WordCountLocalV1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
.setAppName(WordCountLocalV1.getClass.getSimpleName)
.setMaster("local[*]")
val sc: SparkContext = new SparkContext(sparkConf)
val tuples: Array[(String, Int)]= sc.textFile(ClassLoader.getSystemResource("word.csv").getPath)
.flatMap(line => line.split(","))
.map(word => (word, 1))
.reduceByKey((x, y) => x + y)
.collect()
tuples.foreach(println)
sc.stop()
}
}
- 简写:
3. 上传 jar 包提交 spark 任务
/**
* 集群模式运行 简写版本
*/
object WordCountCluster {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
.setAppName(WordCountCluster.getClass.getSimpleName)
// .setMaster("local[*]")
val sc: SparkContext = new SparkContext(sparkConf)
val ret: RDD[(String, Int)]= sc.textFile(args(0))
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
// .collect()
ret.saveAsTextFile(args(1))
sc.stop()
}
}
- 将我们修改之后的程序打包,打包之后上传到node01服务器的 /bigdata/data 路径下
# spark standalone client模式
spark-submit --master spark://node01:7077,node02:7077 \
--deploy-mode client \
--class com.yw.spark.example.WordCountCluster \
--executor-memory 1g \
--total-executor-cores 2 \
original-spark-demo-1.0.jar \
hdfs://node01:8020/words.txt hdfs://node01:8020/words_output
# spark standalone cluster模式
spark-submit --master spark://node01:7077,node02:7077 \
--deploy-mode cluster \
--class com.yw.spark.example.WordCountCluster \
--executor-memory 1g \
--total-executor-cores 2 \
hdfs://node01:8020/original-spark-demo-1.0.jar \
hdfs://node01:8020/words.txt hdfs://node01:8020/words_output

注意:如果是cluster模式,需要将jar包上传到hdfs上,路径为->hdfs://node01:8020/xxx.jar
各参数的值根据自己的实际情况修改,如–master、–class、jar包名称等
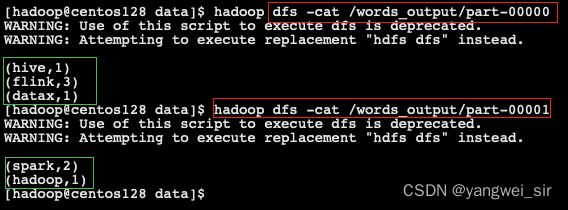
- 查看运行结果:
- github 代码地址:https://github.com/shouwangyw/bigdata/tree/master/spark-demo