差分隐私技术概论
目录
1.隐私保护的挑战
2.差分隐私定义及原理
3.差分隐私算法
3.1.拉普拉斯机制
3.2.随机化回答
4.差分隐私应用
4.1.差分隐私数据库
4.2.差分隐私机器学习
4.3.差分隐私数据采集
4.4.差分隐私数据合成
5.前景展望
1.隐私保护的挑战
场景:
在上面场景中,我们要与研究者分享病人的医疗数据,怎样才能保护病人的隐私?

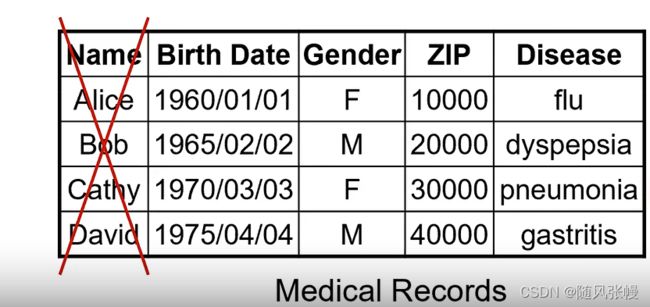
做法1:将数据匿名化,也就是将数据中病人的名字和身份证号码等可以唯一识别病人的信息去掉,将其余的信息提供给研究者,如下图所示
分析:这样的作法其实并不能真的保护隐私,因为匿名化之后的数据往往还保留着许多可能泄漏隐私的信息,如上图所示,还保留着病人的出生日期、性别和邮编,如果攻击者能在别处获得许多人的姓名、出生日期、性别和邮编的话,与上图病人的数据进行对应,就能反推出病人的姓名
做法2:下面左边图是源数据,将该数据以右边两种图的形式发送,右边第一个图统计了源数据中各年龄段对应其工作状态的数据组合的人数,右边第二个图统计了各年龄段对应其性别的数据组合的人数
分析:根据上面右图1和右图2的后面两行数据可以推出源数据中一定有两个元组年龄大于18岁性别为女性且有工作


总结:可以看出做法一的匿名化方法容易被攻击,即使考虑做法二不发布详细的元组,转而发布粗粒度的统计数据,这样的统计信息理论上也可以用来重构部分源数据,统计数据也有可能泄漏隐私
为降低数据重构的可能,可以做一些额外的保护措施:
1.把太小的统计数据删除(如把做法二右图中count为0和1的统计数据删除,因为这些统计数据往往和源数据存在一一对应关系)
2.在统计数据中加入一定噪声(将上面右图中count的数据进行小幅度更改,如下图所示,加入少量的噪声并不会对统计数据的可用性带来太大的影响,并且可以提高数据重构的难度)
但上面的保护措施依然不安全,可以用线性规划的方法重构数据,如下
解方程,我们得到的最小的
和其对应的x1 x2......x8就可以认为是对源数据大致的重构
数据重构攻击的实际效果:美国普查局用他们2010年所发布的一组统计数据试验了数据重构攻击,结果表明他们能重构17%美国人口的数据,因此他们宣布将于2020年的统计数据中使用差分隐私


既然发布统计数据容易被重构算法攻击,能否发布更复杂的数据形式,使重构难以进行?比如发布机器学习模型
分析:机器学习模型往往会不经意的“记住”源数据中的元组,因此模型在那些元组上的表现可能跟在其他元组上的表现会不一样(类比:学生考试时,碰上之前做过的题和碰上没做过的题的反应是不一样的)
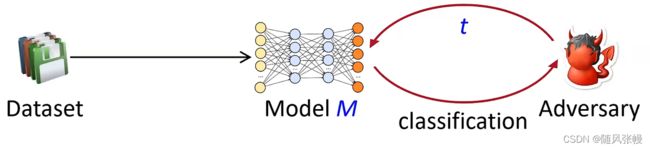
对机器学习模型的隐私攻击:假设被发布的模型是一个分类器,把一些人的元组挨个作为模型的输入,并观察模型的分类结果,通过分类结果,反推每一个人是否有出现在源数据中,如下图所示(具体较为复杂,不做阐述)
因此即便是机器学习模型也可能泄漏隐私

总而言之,攻击者可以有很多种不同的方式来对隐私数据进行攻击,为防范这些可能的攻击,我们需要有一个严谨的框架来对数据隐私进行保护,差分隐私正是这样的一个理论框架
2.差分隐私定义及原理
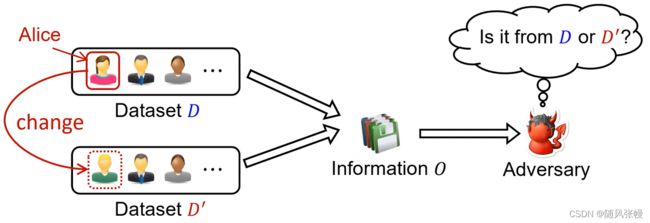
差分隐私的直观原理:
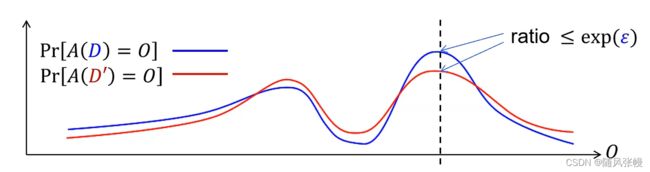
直观原理:如果攻击者无法判别信息O是来自于D还是D',那么我们可以认为Alice的隐私受到了保护
差分隐私要求任何被发布的信息都应当与上图中的信息O类似:应当避免让攻击者分辨出任何具体的个人数据
为此,差分隐私要求被发布的信息需经一个随机算法所处理,且该随机算法会对信息做一些扰动

差分隐私定义:
一随机算法A满足
对任意“相邻”数据集D和D'及任意输出O都成立
其中,
上面的定义意味着:修改一个人的数据,不会对算法A输出的分布带来太大的影响,也就是说当一个攻击者观察算法A的输出的时候,很难分辨出源数据到底是D还是D'
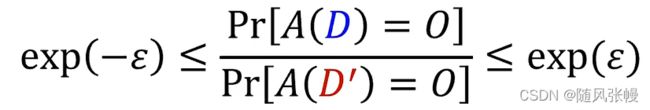
差分隐私定义的图示:
曲线差距越小,说明安全性越好,隐私保护越强
如何设计满足差分隐私的算法?
差分隐私算法应满足:算法的输出不会过分依赖于某一个人的数据,而只能依赖于数据中的一些普遍模式(例如:如果发布病人的平均数据就比较容易满足差分隐私)
一般做法:从一个不满足差分隐私的算法出发,往算法里适当的加入一定噪声,以使其输出满足差分隐私的要求
注:当我们设计差分隐私算法用来发布信息的时候,我们需要考虑需要发布的信息对于个体的依赖性到底有多大。如果发布的信息对于个体依赖性大的话,需要对发布信息加入非常大的噪声,如果发布的信息对于个体依赖性小的话,对发布信息加入的噪声量可以较小,
3.差分隐私算法
拉普拉斯机制和随机化回答是两个经典的差分隐私算法,还有许多其他不同的算法
一般而言,不同的应用场景、不同的数据集、不同的输出往往需要不同的算法设计
3.1.拉普拉斯机制
当发布数值型数据的时候,可以用拉普拉斯机制来引入噪声
假设我们有一个病患数据集 D
考虑以下数据库查询:
如果我们要发布这个查询结果,如何才能满足
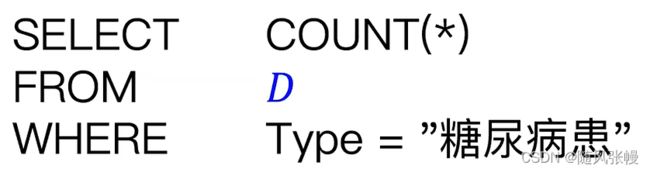
首先,我们应该考虑这个查询的结果有多依赖于某个特定病人的信息
如果我们修改D中任意一个病患的数据,上述查询结果最多会改变1。这里的1代表了查询结果对于个体数据的依赖程度。如果我们能用噪声掩盖这个最多为1的改变的话,我们就能满足差分隐私
其次,我们可以往查询结果中加入一个服从拉普拉斯分布的噪声
噪声分布如上图所示,该函数中值当x=0时,pdf(x)=
为最大,两边成指数型下降;尺度参数
越大,说明
当参数
(根据上面假设
分子为1是因为上面假设的查询结果最多会改变1(敏感度为1),查询结果最多改变量不同,分子应跟着改变),即能满足
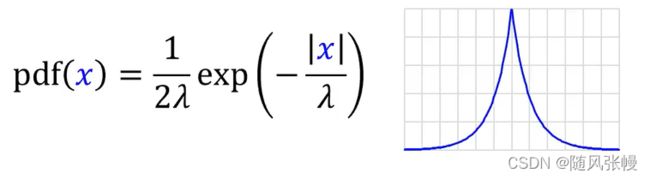
上面的b就是尺度参数
尺度参数

当上面数据库查询进行改变,如下图所示:
首先,如果我们修改一个病患的数据,则上述查询结果最多改变3
其实,我们对其加入拉普拉斯噪声,并把参数
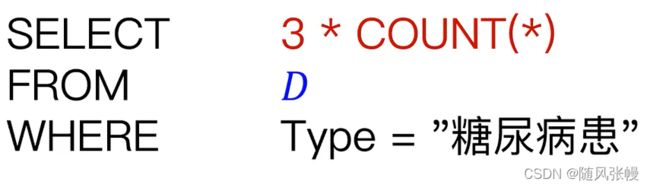
· 一般而言,如果我们要发布一组数值型查询结果,我们可以对每个结果加入独立的拉普拉斯噪声来满足差分隐私
· 噪声参数
· 一组查询总共的“最大改变”被称为他们的敏感度
· 取
3.2.随机化回答
数据采集的简单机制
假设我向一组人问一个敏感的是非题
出于隐私,有的人可能不愿意给真实答案
解决方案:让每个人在他的答案中加入噪声

让每个人以一个小概率回答其真实的答案,以一个大概率随机回答一个答案,如下图所示
随机化回答可以满足
直观原因:由于其随机性,攻击者并不能从随机化的输出反推出输入到底是“yes”还是“no”
只要根据

通过随机化回答我们依然可以通过随机化回答的输出得到一些有用的结果(比如大概有多少人真实回答是“yes”)
通过随机修改回复来满足差分隐私,由于修改时引入的噪声分布已知,因此我们仍可以反推源数据的大致分布,但无法反推出个体回复

4.差分隐私应用
4.1.差分隐私数据库
技术难点:
1.应该尽量减少聚合查询中的噪声,以免影响用户数据分析的准确性,因此如何用尽量少的噪声来达到
· 尤其是在查询需要连接多张数据库表的时候
2.要想减少噪声,就需要精确的计算查询的敏感度,如何高效的计算查询敏感度
3.如何将差分隐私模块整合到现有的数据库当中

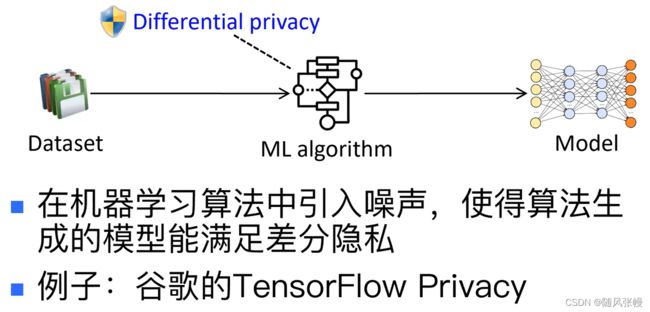
4.2.差分隐私机器学习

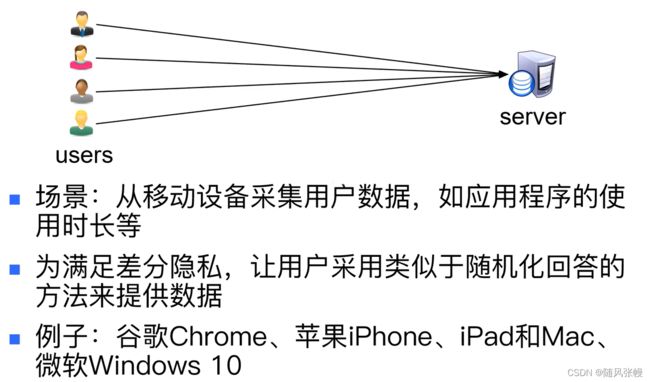
4.3.差分隐私数据采集
技术难点:需要采集的数据可能比较复杂,无法用传统随机化回答解决
例子:用户输入的新词(字典里面没有)
4.4.差分隐私数据合成
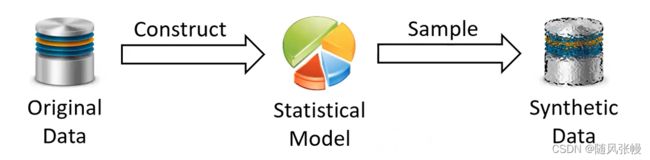
基本原理:
1.先对源数据进行建模,得到一个统计模型
2.用统计模型来合成出虚拟数据
3.将虚拟数据分享给第三方
这样做,虚拟数据中的元组会和源数据中的元组有一些差别,这样就有助于保护隐私,并且只要虚拟数据的分布和源数据的分布相近的话,那么虚拟数据对第三方来说也是有一定价值的
技术难点:
1.如何找到一个合适的统计模型
2.如何在统计模型中加入噪声,以满足差分隐私
5.前景展望
对于前面提到的几个应用,现有解决方案仍有不少需要提高的地方:
1.对于差分隐私数据库
2.对于差分隐私机器学习
3.对于差分隐私数据采集
4. 对于差分隐私数据合成




差分隐私本身的不足:
差分隐私要求,一个数据集即使攻击者已经知道了数据集中的n-1个数据,尝试对剩下那一个人的数据进行推断的时候,还是不能推断出剩下一个人的数据是怎样的