python办公自动化(一)jupyter的使用和python读取excel数据
01-Jupyter使用
Jupyter介绍
基于ipython的一款IDLE,进行封装的编辑器,适用于做数据处理、科学计算、自动化办公的编辑器。
Jupyter Notebooks
Jupyter Notebooks是一款开源的网络应用,用于创建和共享代码。无需离开自带的环境,就可以在其中编写、运行代码,查看输出,可视化数据并查看结果。同时也是一款交互式的编辑器,可以执行端到端的数据科学工作流程的便捷工具,比较适用于做数据清理、统计建模、构建和训练机器学习模型、可视化数据等。
Jupyter Notebooks特点
1. 基于web的在线编辑器
2. 可交互式,运行后可直接返回结果
3. 支持.ipynb文件分享
4. 支持markdown语法
Jupyter Notebooks安装
1.需要先安装Python,建议版本为3.6 --- 3.7
2.win+R,输入cmd进入windows终端
3.安装命令:pip install jupyter
Jupyter Notebooks使用
1.建立单独项目的文件夹
2.win+R,输入cmd进入windows终端
3.切换到该文件的目录下
4.打开命令:jupyter notebook

输入命令后,会在浏览器中打开,本地链接的网址为:http://localhost:8888/tree,切记运行时不要关掉cmd窗口。

打开笔记本后,会看到顶部由三个选项卡:File、Running、Cluster。其中File列出所有的文件(重点),Running展示的是当前打开的终端(Terminals)和笔记本(Notebooks),Cluster 是由Ipython提供的。
要打开一个新的Jupyter笔记本,点击右侧的New选项。
Python3:创建python file,代码是输入python的代码,标记用# 标记为标题。
Text File:记事本txt的文档,可以选择编辑的语言
Folder:创建文件夹
Teminal:终端,类似windows上的cmd


快捷键的使用
运行 ---> CTRL(shift)+ Enter
命令模式 ---> Esc 对整个文件进行操作
编辑模式 ---> Enter 进入单元内部进行操作
在进入命令模式后:
A ---> 在活跃单元之上插入一个新单元
B ---> 在活跃单元之下插入一个新单元
D(连续两次) ---> 删除一个单元
Z ---> 撤销被删除的单元
Y ---> 将当前活跃的单元变成一个代码单元
Shift+ 上下箭头 ---> 选择多个单元
Shift+ M ---> 合并选择的单元
在进入编辑模式后:
CTRL + Home ---> 到达单元起始位置
CTRL + End ---> 到达单元最后的位置
CTRL + S ---> 保存进度
CTRL + Enter ---> 运行整个单元块
Alt + Enter ---> 运行整个单元块,还会在下面添加一个新单元
在命令模式下,输入H,就可以看到所有的快捷键的命令。

02-Python读取excel数据
在工作中用到excel比较多,关于数据的一般都会用excel,把数据导入到excel中做柱状图、折线图等等。也可以用Python代码实现相应的操作,不必花时间去调整表格的样式等内容。
xlrd介绍
xlrd是⼀个⽤于从Excel文件(⽆论是.xls还是.xlsx文件)读取数据和格式化信息的库。
可参考⽹址:https://xlrd.readthedocs.io/en/latest/index.html
xlrd安装
1.需要先安装Python,建议版本为3.6-3.7
2.win+R,输入cmd进入windows终端
3.安装命令:pip install xlrd,安装完成后用 pip list 查看安装的版本信息
xlrd使用
当我们要调用库中的方法时,用import关键字来导入库。
import xlrd
Python操作工作簿
xlrd.open_workbook(filename) ---> 获取工作簿
filename ---> 文件名以及路径,如果路径或者文件名有中文给前⾯加⼀个r保留原生字符。
book = xlrd.open_workbook(filename)
Python操作工作表
创建新的文件夹,传入“weather_expectation.xlsx”文件,跟新创建的python3文件在同一个文件夹下。
会出现的问题
a.Excel xlsx file; not supported
提示出现,Excel xlsx file; not supported 的错误,出现问题的原因居然是新版本的xlrd不支持xlsx文件,我安装的xlrd是2.0.1版本,需要先下载xlrd,pip uninstall xlrd ,然后输入y进行卸载,卸载完成后 pip install xlrd==1.2.0,重新安装1.2.0的版本,问题就可以解决了。
b.没有tab键提示
如果输入代码时没有tab键提示的话,可以在最开始的代码里输入 %config Completer.use_jedi = False ,运行后再输入代码就可以用tab键提示代码输入了。
也可以指定ipython的安装版本为7.1.1. pip install ipython == 7.1.1
1.读取工作簿
工作簿的名称为weather_expectation.xlsx。

运行后可以发现输出了一个book.Book的对象所在的内存地址。
2.通过工作簿读取工作表
把读取的过程赋值给变量book。
book.nsheets ---> 获取工作表个数,返回值为int
book.sheet_names() ---> 获取工作表名,返回值为list
book.sheets() ---> 以列表的形式返回工作簿中的所有工作表

传入的excel工作簿中有两个工作表,所以返回值为2。
由于book.sheets()获取的是以列表返回工作簿中的所有工作表,那就可以通过索引来获取单个工作表。
book.sheet_by_index(sheetx) ---> 通过索引获取工作表,sheetx 是工作表索引(索引从0开始)
book.sheet_by_name(sheet_name) ---> 通过工作表名获取工作表,sheet_name为工作表名
book.sheet_loaded(sheet_name or index) ---> 判断是否存在工作表,返回值为布尔。sheet_name or index ---> 工作表名或者(or)索引
book.sheets()[0] ---> 获取第⼀个工作表
book.sheet_by_index(0) ---> 获取第⼀个工作表
book.sheet_loaded(index or sheet_name) ---> 作or运算

通过xlrd去定位到工作簿,进而定位到工作表,以及对工作表的操作。
3.读取行列数据
3.1 python读取excel行数据
工作表“数据集1”的格式如下

rowx ---> 指定行(默认从0开始)
start_colx ---> 开始列
end_colx ---> 结束列
table.nrows ---> 返回工作表的总行数
table.row(rowx) ---> 返回由该行中所有的单元格对象组成的列表
table.row_slice(rowx, start_colx=0, end_colx=None) ---> 返回由该行中开始列到结束列的单元格对象组成的列表
table.row_types(rowx, start_colx=0, end_colx=None) ---> 返回该行切片后列表中每单元格的数据类型
table.row_values(rowx, start_colx=0, end_colx=None) ---> 返回该行切片后列表中每单元格的值
table.row_len(rowx) ---> 返回该行有效单元格
| ctype | 数据类型 |
|---|---|
| 0 | empty(空值) |
| 1 | string(字符串) |
| 2 | number(数字) |
| 3 | data(⽇期) |
| 4 | boolean(布尔) |
| 5 | error(错误) |

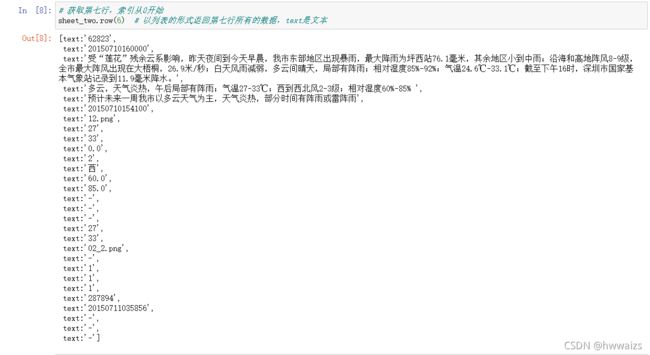

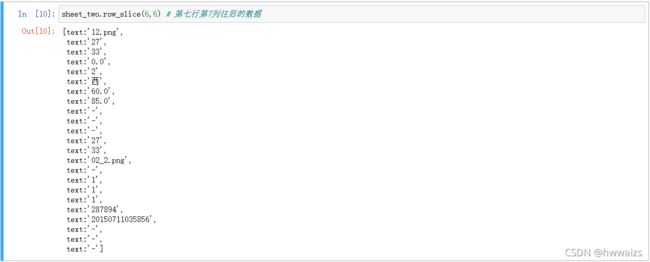

可以用“??”来看一下代码的使用方法

3.2 python读取excel列数据
table.ncols ---> 返回工作表的总列数
table.col(colx, start_rowx=0, end_rowx=None) ---> 返回由该列中所有的单元格对象组成的列表
table.col_slice(colx, start_rowx=0, end_rowx=None) ---> 返回由该列中开始行到结束行的单元格对象组成的列表
table.col_types(colx, start_rowx=0, end_rowx=None) ---> 返回该行切片后列表中每单元格的数据类型
table.col_values(colx, start_rowx=0, end_rowx=None) ---> 返回该行切片后列表中每单元格的值


3.3 python读取excel单元格
table.cell(rowx, colx) ---> 返回当前行列单元格内容
table.cell_value(rowx, colx) ---> 返回当前行列单元格的数值
table.cell_type(rowx, colx) ---> 返回当前行列单元格的类型
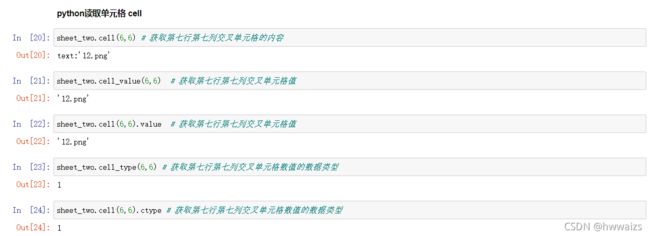
3.4 excel合并后的单元格获取
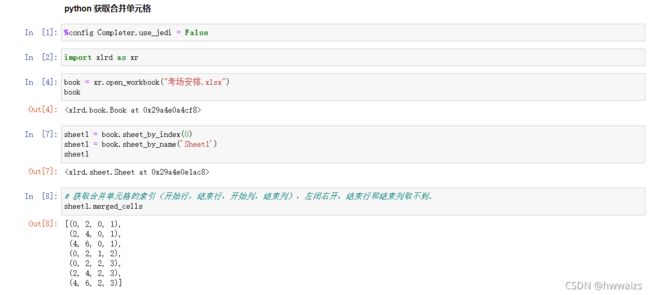
工作簿“考场安排.xlsx”,数据存放在工作簿“Sheet1”中
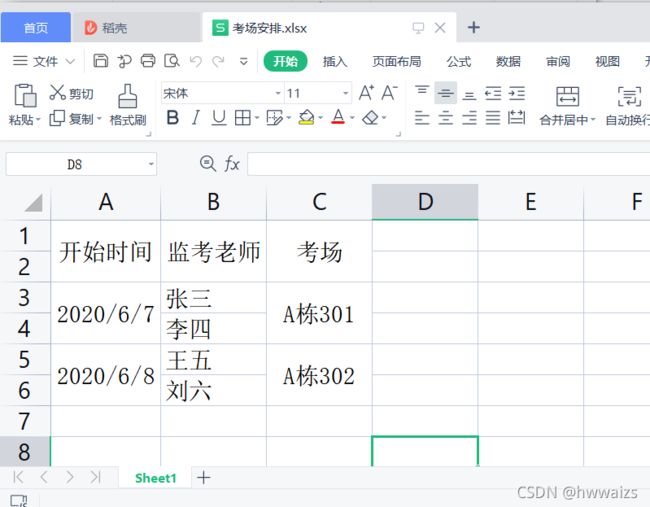
table.merged_cells ---> 返回所有合并后的单元格的索引,只获取合并的单元格(开始行数,结束行数,开始列数,结束列数)
table.cell_value(rowx, colx) ---> 通过开始行,开始列获取合并后单元格

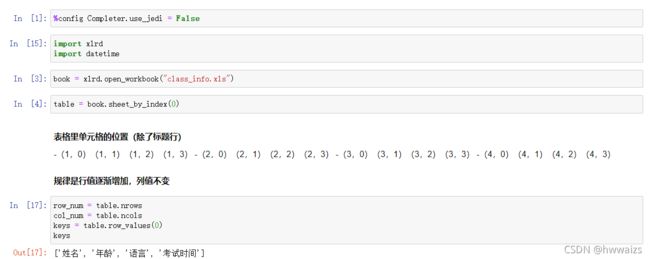
练习读取excel数据

数据存放在class_info.xls的文件中,读取出数据并以一下格式返回。

解题步骤如下: