数据科学实战系列之ML-KNN(一)
写在开头:最近确实事情比较多,每天没有啥时间去学习其他的东西,也就没有时间来继续创作博客,不过最近学习了一些多标签分类的东西,并简单的实现了一下。
内容安排
对于多标签分类任务还有许多常见的方法比如ML-DT(决策树)、Rank-SVM等,由于ML-KNN沿袭KNN的思想比较容易上手,于是本文将对多标签分类任务中的ML-KNN算法进行简单的介绍,并通过代码进行实例操作,使用数据及为MULAN的eurlex-directory-codes(点击可下载)。
1.ML-KNN算法简介
ML-KNN的核心思想与KNN相似,即通过寻找K个最近的样本来判断当前测试样本类别,不过在ML-KNN中是运用贝叶斯条件概率,来计算当前测试样本标签是存在还是不存在,如果存在的概率大于不存在的概率,那么该标签存在。这里将论文的伪代码放过来,讲述思路借鉴基于ML-KNN的多标签分类算法,伪代码如下:
 其主要思想是单独观察样本的每个标签存在的概率,那么通过伪代码可以看到
其主要思想是单独观察样本的每个标签存在的概率,那么通过伪代码可以看到
Step1.(训练阶段第1到3行)利用knn算法计算出样本集中每个样本的K个最近邻;
Step2.(第4到6行)计算标签出现的概率、已经在K近邻中出现的次数统计,计算公式如下
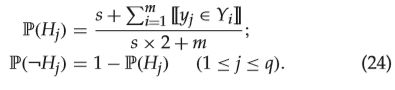 第一个式子表示的时某个标签在样本总体中存在的频率,其中, H j H_j Hj表示的是标签 j j j的出现, m m m表示的是样本总量,分子中的求和项表示的是存在标签 j j j的个数总计, s s s是拉普拉斯平滑项,避免某个标签计算出的概率为0,具体解释可以参考这篇文章:平滑处理-拉普拉斯。与之对应的第二个式子表示的则是某个标签在样本总体中不存在的频率。
第一个式子表示的时某个标签在样本总体中存在的频率,其中, H j H_j Hj表示的是标签 j j j的出现, m m m表示的是样本总量,分子中的求和项表示的是存在标签 j j j的个数总计, s s s是拉普拉斯平滑项,避免某个标签计算出的概率为0,具体解释可以参考这篇文章:平滑处理-拉普拉斯。与之对应的第二个式子表示的则是某个标签在样本总体中不存在的频率。
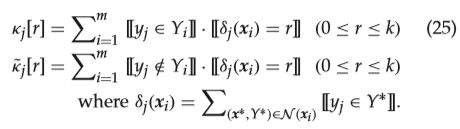 计算 κ j [ r ] \kappa_j[r] κj[r]表示的就是当前标签存在,并且当前样本的K近邻中标签 j j j存在数为 r r r的样本总数。也就是统计多少样本的K近邻在标签 j j j上出现 r r r次。其中 δ j ( x i ) \delta_j(x_i) δj(xi)就表示的是当前样本的K近邻中标签 j j j存在的个数。简单来说就是看总体情况下标签 j j j存在,那么其每个样本的KNN近邻存在次数的一个分布,反之 κ ~ j [ r ] \tilde{\kappa}_j[r] κ~j[r]就是计算当总体中标签 j j j不存在时,每个样本的K近邻在标签 j j j上的一个分布;
计算 κ j [ r ] \kappa_j[r] κj[r]表示的就是当前标签存在,并且当前样本的K近邻中标签 j j j存在数为 r r r的样本总数。也就是统计多少样本的K近邻在标签 j j j上出现 r r r次。其中 δ j ( x i ) \delta_j(x_i) δj(xi)就表示的是当前样本的K近邻中标签 j j j存在的个数。简单来说就是看总体情况下标签 j j j存在,那么其每个样本的KNN近邻存在次数的一个分布,反之 κ ~ j [ r ] \tilde{\kappa}_j[r] κ~j[r]就是计算当总体中标签 j j j不存在时,每个样本的K近邻在标签 j j j上的一个分布;
Step3.(预测阶段第8行)计算测试样本的K近邻;
Step4.(第9到11行)计算测试样本K近邻中标签 j j j为1的个数
![]()
Step5.(第12行)计算测试样本每个标签出现的概率,并进行判断,其计算公式如下,
![]() 该式表示的是当测试样本K近邻中的标签 j j j有 C j C_j Cj个是存在时,其真实标签也存在的概率如果大于真实标签不存在的概率时,即认为测试样本的标签 j j j存在的。然后可以对上述概率计算的式子进行变形,使用贝叶斯公式进行展开得到,
该式表示的是当测试样本K近邻中的标签 j j j有 C j C_j Cj个是存在时,其真实标签也存在的概率如果大于真实标签不存在的概率时,即认为测试样本的标签 j j j存在的。然后可以对上述概率计算的式子进行变形,使用贝叶斯公式进行展开得到,
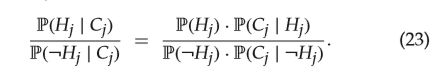
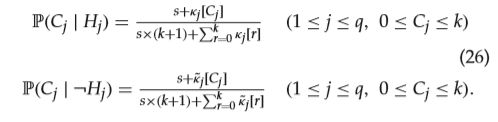 其中 P ( H j ∣ C j ) P(H_j|C_j) P(Hj∣Cj)通过贝叶斯公式转变后的分子为 P ( H j ) ⋅ P ( C j ∣ H j ) P(H_j)\cdot P(C_j|H_j) P(Hj)⋅P(Cj∣Hj), P ( C j ∣ H j ) P(C_j|H_j) P(Cj∣Hj)表示的是当测试样本标签 j j j存在的条件下,其K近邻中标签 j j j的个数为 C j C_j Cj的概率。那么通过这样的计算流程就能够实现对数据进行多分类处理。
其中 P ( H j ∣ C j ) P(H_j|C_j) P(Hj∣Cj)通过贝叶斯公式转变后的分子为 P ( H j ) ⋅ P ( C j ∣ H j ) P(H_j)\cdot P(C_j|H_j) P(Hj)⋅P(Cj∣Hj), P ( C j ∣ H j ) P(C_j|H_j) P(Cj∣Hj)表示的是当测试样本标签 j j j存在的条件下,其K近邻中标签 j j j的个数为 C j C_j Cj的概率。那么通过这样的计算流程就能够实现对数据进行多分类处理。
2.ML-KNN优缺点
优点:
训练时间复杂度比支持向量机之类的算法低,仅为O(n)
和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感
KNN主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合
缺点:
计算复杂性高;空间复杂性高;
样本不平衡的时候,对稀有类别的预测准确率低
可解释性差,无法给出决策树那样的规则。
优缺点参考博文ML模型1:KNN概述及优缺点。
3.ML-KNN算法实现
对于ML-KNN的实现首先需要对KNN进行实现,代码如下:
import numpy as np
from numba import jit
class knn():
def __init__(self, _train_data):
self.train_data = _train_data
@jit
def knn_train(self, nth, k):
self.distance = np.square(self.train_data - self.train_data[nth]).sum(axis=1) #计算距离
self.distance[self.distance == 0] = float("inf")
Knn = np.argpartition(self.distance, k)[:k] #选择距离最小的K个数
return Knn
@jit
def knn_test(self, _test_data, k):
self.distance = np.square(self.train_data - _test_data).sum(axis=1)
self.distance[self.distance == 0] = float("inf")
Knn = np.argpartition(self.distance, k)[:k]
return Knn
然后本文选用的是MULAN数据所以还需要对数据进行预处理,代码如下,
import numpy as np
class mulan_loader():
def __init__(self, _filepath):
self.f = open(_filepath)
self.lines = self.f.readlines()
def sample_label_num(self, lines, label=False):
num = 0
if label == False:
for line in self.lines:
if '@' not in line:
if '\n' != line:
num += 1
else:
for line in self.lines:
if '@attribute' in line:
num += 1
return num
def input_matrix(self):
mat = np.zeros((self.sample_label_num(self.lines), self.sample_label_num(self.lines, label=True)))
m = 0
for i in range(len(self.lines)):
if '@' not in self.lines[i]:
if '\n' != self.lines[i]:
m += 1
sample = self.lines[i].split(',')
l = []
for key_value in sample:
l.append(key_value.split(' '))
l[0][0] = '0'
l[-1][1] = l[-1][1][0]
for j in range(len(l)):
mat[m-1][eval(l[j][0])] = eval(l[j][1])
return mat
def data_target_split(self, data_num):
mat = self.input_matrix()
data = mat[:, :data_num]
target = mat[:, data_num:]
return data, target
filepath = 'D:\\eurlex-directory-codes\\eurlex-dc-leaves-fold1-train.arff'
data, target = mulan_loader(filepath).data_target_split(5000)
print("数据维度为",data.shape)
print("目标维度为",target.shape)
数据维度为 (17413, 5000)
目标维度为 (17413, 412)
可以看到载入的数据维度挺大的,最后编写ML-KNN的代码按照前文的算法逻辑即可,
import numpy as np
from sklearn.model_selection import KFold
from Mulan_load import mulan_loader
from KNN import knn
import gc
class ML_KNN():
def __init__(self, _train_data, _train_target, _k, _s, _it):
# 初始化参数
self.train_data = _train_data
self.train_target = _train_target
self.train_num = self.train_data.shape[0]
self.labels_num = self.train_target.shape[1]
self.k = _k
self.s = _s
self.Peh1 = np.zeros((self.labels_num, self.k + 1))
self.Peh0 = np.zeros((self.labels_num, self.k + 1))
self.it = _it
def fit(self):
self.PH1 = (self.s + self.train_target.sum(axis=0))/(self.s*2 + self.train_num)
self.PH0 = 1 - self.PH1
for i in range(self.labels_num):
if i % 5 == 0:
print("第%d轮训练进度:%d|%d (%.2f %%)"%(self.it, i, self.labels_num, i*100/self.labels_num))
c1, c0= np.zeros((self.k + 1,)), np.zeros((self.k + 1,)) #c对应花k
target = self.train_target[:, i]
for j in range(self.train_num):
if j % 100 == 0:
print("第%d轮中第%d个指标训练进度:%d|%d (%.2f %%)"%(self.it, i, j, self.train_num, j*100/self.train_num))
temp = 0
KNN = knn(self.train_data).knn_train(j, self.k)
temp = int(target[KNN].sum())
if self.train_target[j][i] == 1:
c1[temp] = c1[temp] + 1
else:
c0[temp] = c0[temp] + 1
for l in range(self.k + 1):
self.Peh1[i][l] = (self.s + c1[l])/(self.s*(self.k + 1) + c1.sum())
self.Peh0[i][l] = (self.s + c0[l])/(self.s*(self.k + 1) + c0.sum())
print("第%d轮训练完成!%d|%d (100.00 %%)"%(self.it, self.labels_num, self.labels_num))
def predict(self, _test_data):
print("开始预测!")
test_num = _test_data.shape[0]
self.rtl = np.zeros((test_num, self.labels_num))
self.predict_labels = np.zeros((test_num, self.labels_num))
for i in range(test_num):
if i % 5 == 0:
print("测试进度:%d|%d (%.2f %%)"%(i, test_num, i*100/test_num))
target = self.train_target[:,i]
KNN = knn(self.train_data).knn_test(_test_data[i], self.k)
for j in range(self.labels_num):
temp = 0
temp = int(target[KNN].sum())
y1 = self.PH1[j] * self.Peh1[j][temp]
y0 = self.PH0[j] * self.Peh0[j][temp]
self.rtl[i][j] = y1 / (y1 + y0)
if y1 > y0: #判断条件
self.predict_labels[i][j] = 1
else:
self.predict_labels[i][j] = 0
print("预测完成!%d|%d (100.00 %%)"%(test_num, test_num))
return self.predict_labels
if __name__ == "__main__":
gc.disable()
print("开始读取数据,请等待>>>")
filepath = 'D:\\eurlex-directory-codes\\eurlex-dc-leaves-fold1-train.arff'
data, target = mulan_loader(filepath).data_target_split(5000)
print("读取数据完成,准备进行训练>>>")
kf = KFold(n_splits=10, shuffle=True, random_state=529)
it = 0
for trian_index , test_index in kf.split(data):
it += 1
print("*"*30)
print("开始第%d轮训练"%it)
train_X, test_X = data[trian_index], data[test_index]
train_Y, test_Y = target[trian_index], target[test_index]
ml_knn = ML_KNN(train_X, train_Y, 5, 1, it)
ml_knn.fit()
labels = ml_knn.predict(test_X)
结语
这里就不运行这个程序的结果了,因为输入的数据维度过大几乎要大半年才能运行出结果,所以可以得到ML-KNN的缺点之一就是不适用大维度数据,计算复杂度过高。所以笔者将在下一篇文章拟提出一种方法能够运行如此庞大的矩阵。
谢谢阅读。
参考
1.基于ML-KNN的多标签分类算法
2.平滑处理-拉普拉斯
3.ML模型1:KNN概述及优缺点