【深度学习】(一)机器学习基础学习笔记
机器学习基础
作为一个图像算法工程师,传统图像算法和深度学习算法都应该掌握,这样在面对不同的实际场景时可以有更多得解决方法。之前的文章基本上都是以传统方法为主,所以今天一起来学习一下有关深度学习的算法。以后也会持续更新深度学习相关的内容。
AI人工智能包含的内容十分广泛,对于图像处理而言,机器学习、深度学习或者计算机视觉主要关注图像识别这部分内容,所以重点学习CNN卷积神经网络。今天先从上古时期的机器学习开始。
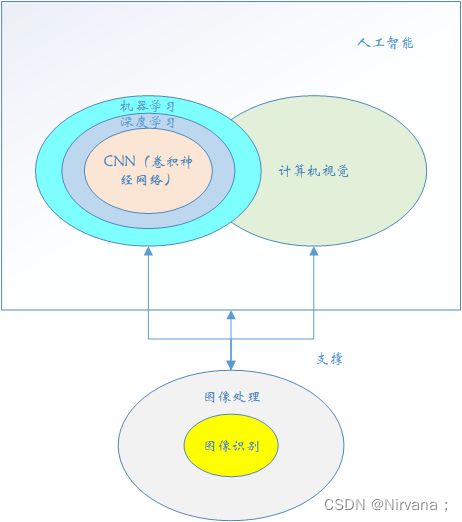
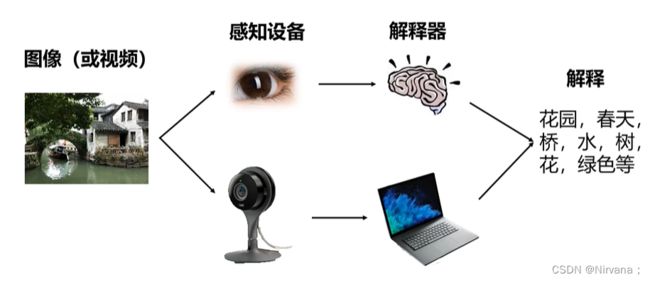
计算机视觉是人类希望机器可以像人眼一样去“看”,而机器学习(深度学习)是希望机器可以像人的大脑一样“思考”。
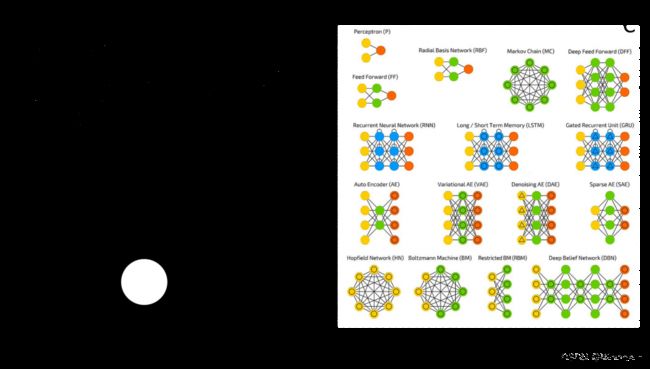
既然要机器拥有人类的大脑,那就要从人类的大脑结构出发。人脑中的神经网络是一个非常复杂的组织。成人的大脑中估计有1000亿个神经元之多。前人对神经的结构进行了数学建模,进而通过计算机进行数学映射,得到了神经网络。神经网络是一种模拟人脑的神经网络以期能够实现类人工智能的机器学习技术。
1958年,计算科学家Rosenblatt提出了由两层神经元组成的神经网络。他给它起了一个名字–“感知器”(Perceptron)(有的文献翻译成“感知机”,下文统一用“感知器”来指代)。每个神经元都是一个结构相似的独立单元,它接受前一层的输入,并将加权和输入非线性作用函数,最后输出结果传递给后一层。下图为单层感知机: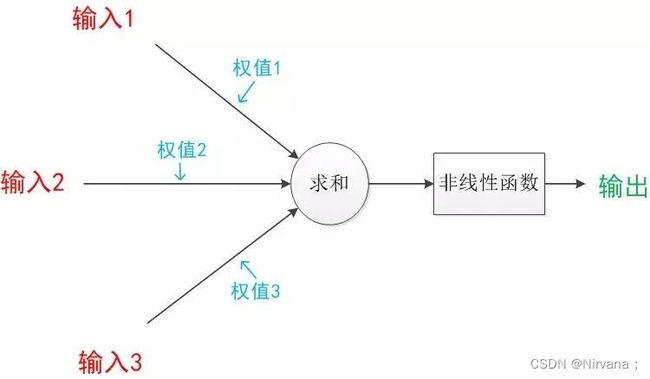 激活函数:一般采用sigmoid和tanh函数,主要是将数据进行非线性变换,将输入压缩到(0,1)和(-1,1)之间。
激活函数:一般采用sigmoid和tanh函数,主要是将数据进行非线性变换,将输入压缩到(0,1)和(-1,1)之间。
# 激活函数
def tanh(x):
return np.tanh(x)
def logistic(x):
return 1/(1 + np.exp(-x))
学习规则:设置学习率learning_rate和学习轮次epochs,机器学习是一个不断迭代优化的过程,需要学习率来调整实际输出和期望输出的差别。
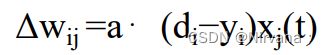
# 学习率
self.weights[i] += learning_rate * layer.T.dot(delta)
目标函数:主要采用均方误差,几乎所有的机器学习算法最后都归结为求解最优化问题,以达到我们想让算法达到的目标。为了完成某一目标,需要构造出一个“目标函数”来,然后让该函数取极大值或极小值,从而得到机器学习算法的模型参数。如何构造出一个合理的目标函数,是建立机器学习算法的关键,一旦目标函数确定,接下来就是求解最优化问题,这在数学上一般有现成的方案。

# cost/loss function
cost = -tf.reduce_mean(Y * tf.compat.v1.log(hypothesis) + (1 - Y) *
tf.compat.v1.log(1 - hypothesis))
梯度下降算法:主要采用SGD、Mini-batch GD,目的就是求解目标函数的最小值。这个过程可以理解为蒙着眼睛下山,每次都朝着梯度下降最快的方向往下走。当然随着不断的发展,之后深度学习还有更好的最优化算法,如Adam。

# 调用Tensorflow的API函数GradientDescentOptimizer实现
train = tf.compat.v1.train.GradientDescentOptimizer(learning_rate=learning_rate).minimize(cost)
BP算法:即误差反向传播算法,BP算法中核心的数学工具就是微积分的链式求导法则。
#开始反向计算误差,更新权重
for l in range(len(a) - 2, 0, -1): # we need to begin at the second to last layer
deltas.append(deltas[-1].dot(self.weights[l].T)*self.activation_deriv(a[l]))
deltas.reverse()
for i in range(len(self.weights)):
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
self.weights[i] += learning_rate * layer.T.dot(delta)
代码实现
开发环境:Python3.9+Tensorflow2.9.1
Tensorflow1.0到Tensorflow2.0还是有很多不同的地方,踩了不少坑
以一个经典的异或问题为例,构建了两层神经网络,输入为[0, 0], [0, 1], [1, 0], [1, 1],输出为[0, 1, 1, 0]。
无论神经网络简单还是复杂,机器学习都包括训练train和测试predict两个过程。
首先采用不调Tensorflow库,可以深入了解计算过程,代码如下:
#coding:utf-8
import numpy as np
# 激活函数
def tanh(x):
return np.tanh(x)
def tanh_deriv(x):
return 1.0 - np.tanh(x)**2
def logistic(x):
return 1/(1 + np.exp(-x))
def logistic_derivative(x):
return logistic(x)*(1-logistic(x))
# NeuralNetwork 神经网络算法
class NeuralNetwork:
#初始化,layes表示的是一个list,eg[10,10,3]表示第一层10个神经元,第二层10个神经元,第三层3个神经元
def __init__(self, layers, activation='tanh'):
"""
:param layers: A list containing the number of units in each layer.
Should be at least two values
:param activation: The activation function to be used. Can be
"logistic" or "tanh"
"""
if activation == 'logistic':
self.activation = logistic
self.activation_deriv = logistic_derivative
elif activation == 'tanh':
self.activation = tanh
self.activation_deriv = tanh_deriv
self.weights = []
# 循环从1开始,相当于以第二层为基准,进行权重的初始化
for i in range(1, len(layers) - 1):
#对当前神经节点的前驱赋值
self.weights.append((2*np.random.random((layers[i - 1] + 1, layers[i] + 1))-1)*0.25)
#对当前神经节点的后继赋值
self.weights.append((2*np.random.random((layers[i] + 1, layers[i + 1]))-1)*0.25)
# 训练函数,X矩阵,每行是一个实例 ,y是每个实例对应的结果,learning_rate 学习率,
# epochs,表示抽样的方法对神经网络进行更新的最大次数
def fit(self, X, y, learning_rate=0.1, epochs=10000):
X = np.atleast_2d(X) #确定X至少是二维的数据
temp = np.ones([X.shape[0], X.shape[1]+1]) #初始化矩阵
temp[:, 0:-1] = X # adding the bias unit to the input layer
X = temp
y = np.array(y) #把list转换成array的形式
for k in range(epochs):
#随机选取一行,对神经网络进行更新
i = np.random.randint(X.shape[0])
a = [X[i]]
#完成所有正向的更新
for l in range(len(self.weights)):
a.append(self.activation(np.dot(a[l], self.weights[l])))
#
error = y[i] - a[-1]
deltas = [error * self.activation_deriv(a[-1])]
if k%1000 == 0:
print(k,'...',error*error*100)
#开始反向计算误差,更新权重
for l in range(len(a) - 2, 0, -1): # we need to begin at the second to last layer
deltas.append(deltas[-1].dot(self.weights[l].T)*self.activation_deriv(a[l]))
deltas.reverse()
for i in range(len(self.weights)):
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
self.weights[i] += learning_rate * layer.T.dot(delta)
# 预测函数
def predict(self, x):
x = np.array(x)
temp = np.ones(x.shape[0]+1)
temp[0:-1] = x
a = temp
for l in range(0, len(self.weights)):
a = self.activation(np.dot(a, self.weights[l]))
return a
if __name__ == '__main__':
nn = NeuralNetwork([2,2,1], 'tanh')
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([0, 1, 1, 0])
nn.fit(X, y)
for i in [[0, 0], [0, 1], [1, 0], [1,1]]:
print(i,nn.predict(i))
采用Tensorflow库,工程实现过程中必然要在前人开发的框架上进行二次开发或者直接使用,代码如下:
# 两层感知机+BP算法 完美解决异或问题
import tensorflow as tf
import numpy as np
# tf.random.set_seed(777) # for reproducibility
learning_rate = 0.1
# 输入
x_data = [[0, 0],
[0, 1],
[1, 0],
[1, 1]]
y_data = [[0],
[1],
[1],
[0]]
x_data = np.array(x_data, dtype=np.float32)
y_data = np.array(y_data, dtype=np.float32)
# 占位符
tf.compat.v1.disable_eager_execution()
X = tf.compat.v1.placeholder(tf.float32, [None, 2]) # 2维
Y = tf.compat.v1.placeholder(tf.float32, [None, 1]) # 1维
# 权重
W1 = tf.Variable(tf.random.normal([2, 2]), name='weight1')
b1 = tf.Variable(tf.random.normal([2]), name='bias1')
layer1 = tf.sigmoid(tf.matmul(X, W1) + b1)
W2 = tf.Variable(tf.random.normal([2, 1]), name='weight2')
b2 = tf.Variable(tf.random.normal([1]), name='bias2')
hypothesis = tf.sigmoid(tf.matmul(layer1, W2) + b2)
# cost/loss function
cost = -tf.reduce_mean(Y * tf.compat.v1.log(hypothesis) + (1 - Y) *
tf.compat.v1.log(1 - hypothesis))
train = tf.compat.v1.train.GradientDescentOptimizer(learning_rate=learning_rate).minimize(cost)
# Accuracy computation
# True if hypothesis>0.5 else False
predicted = tf.cast(hypothesis > 0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, Y), dtype=tf.float32))
# Launch graph
with tf.compat.v1.Session() as sess:
# Initialize TensorFlow variables
sess.run(tf.compat.v1.global_variables_initializer())
for step in range(10001):
sess.run(train, feed_dict={X: x_data, Y: y_data})
if step % 100 == 0:
print(step, sess.run(cost, feed_dict={
X: x_data, Y: y_data}), sess.run([W1, W2]))
# Accuracy report
h, c, a = sess.run([hypothesis, predicted, accuracy],
feed_dict={X: x_data, Y: y_data})
print("\nHypothesis: ", h, "\nCorrect: ", c, "\nAccuracy: ", a)