Pytorch学习笔记(3)——从0实现RNN情感分析
本文从0实现了用torch做基于RNN的情感分析。代码已上传到Github,链接为:https://github.com/Balding-Lee/torch-sentiment-analysis-based-on-RNN。但是效果并不是特别好,有可能是数据问题,也有可能是代码问题。如果是代码问题,欢迎指教。
目录
- 1 任务描述
- 2 数据处理
-
- 2.1 词语数目确定
- 2.2 未知词词向量给定
- 2.3 词嵌入
- 3 模型训练
-
- 3.1 RNN
- 3.2 k折交叉验证
- 3.3 获得准确率
- 3.4 训练
1 任务描述
我的任务目标是采用torch构建一个RNN,用于情感分析。选用的数据集是NLPCC2012情感分析任务,链接为:http://tcci.ccf.org.cn/conference/2012/pages/page10_dl.html,使用的是ipad.xml这份数据。采用的词向量为Word2Vec 300维的词向量。
整个模型框架结构如下:

上图是一层RNN的网络结构图,下图是两层RNN的网络结构图。
整体的实验思路如下:
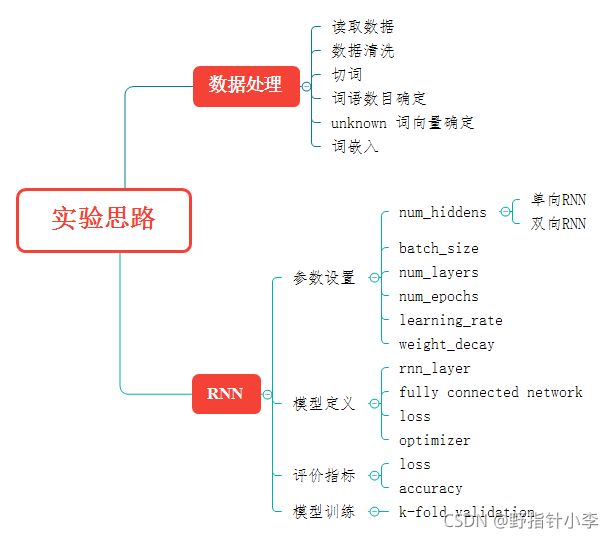
2 数据处理
数据处理的步骤在上面思维导图中已经有了。详细代码见Github中的preprocess.py文件。主要要说明的是词语数目确定,unknown词向量和词嵌入。
2.1 词语数目确定
def get_sentence_length_distribution(cleaned_X):
"""
获得句子的长度
:param cleaned_X: list
[[word11, word12, ...], [word21, word22, ...], ...]
清洗后的文本数据
"""
seq_length_frequency = {}
for sentence in cleaned_X:
seq_length = int(len(sentence) / 10) * 10 # 以10为间隔
try:
seq_length_frequency[seq_length] += 1
except KeyError:
seq_length_frequency[seq_length] = 1
x = [] # 句子长度
y = [] # 出现次数
for length in seq_length_frequency.keys():
x.append(length)
y.append(seq_length_frequency[length])
plt.xlabel('sequence length')
plt.ylabel('The number of occurrences')
plt.bar(x, y)
plt.show()
由于文本长度是不固定的(比如曾经微博要求140字以内),如果我们不确定文本长度,就会导致神经网络无法进行训练(比如RNN中,如果不能确定文本长度,就无法确定sequence length)。同样,我们也不能将最大长度的句子作为文本长度。想象一下,假设最大长度为1000,但是其余句子的长度都在10。如果我们以1000作为文本长度,那么对于其余的句子,剩下的990维都要以0填充。这样不仅增大了内存的消耗,减慢了训练的速度,而且几乎整个语料库中有用的信息都集中在前10个向量中,会导致神经网络不一定学得到东西,或者过拟合。 于是我们选用以上的代码,统计整个语料库中词语数目的区间,用于确定sequence length。ipad语料库中输出的结果如下:
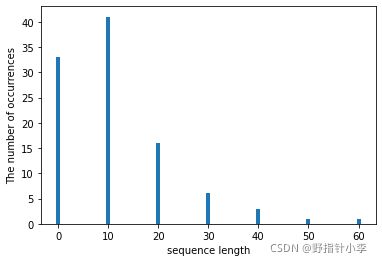
我们发现,句子词语数主要集中在 [ 0 , 20 ] [0, 20] [0,20]这个区间范围内。但是实验中我选用的是max_seq_length=30,可能这也是效果不好的一个原因。
2.2 未知词词向量给定
由于中文博大精深,网友们又卧龙凤雏,导致每年都有大量的新词出现。使得预训练好的词向量不一定能够包含语料库中的所有词语。所以我们需要解决未知词的词向量问题。
def get_unknown_word_embedding(w2v, word_set):
"""
获得未知词的embedding
:param w2v: Object
词向量
:param word_set: set
数据中的所有词
:return unknown_embedding: ndarray
句子中所有出现过的词语的词向量的平均数
"""
all_vectors = np.zeros((len(word_set), 300))
# unknown_embedding = np.zeros((len(word_set), w2v[0]))
count = 0
for word in word_set:
try:
all_vectors[count] = w2v[word]
count += 1
except KeyError:
count += 1
continue
# 删除all_vectors中的全0向量
flag = (all_vectors == 0).all(1) # 计算哪些行全0
word_vectors = all_vectors[~flag, :] # 删除全0元素
unknown_embedding = np.mean(word_vectors, axis=0)
return unknown_embedding
在我的实验中,我将语料库中所有词语的词向量的平均值拿来当做是unknown vector。
2.3 词嵌入
词嵌入分为以下三点:
- 不足
max_seq_length的句子,空缺的部分以0填充; - 超过
max_seq_length的句子,之后的部分截断; unknown word用unknown vector。
def word_embedding(w2v, unknown_embedding, cleaned_X):
"""
获得词嵌入
:param w2v: Object
word2vec向量
:param unknown_embedding: ndarray
shape: (300, )
未知词向量
:param cleaned_X: list
[[word11, word12, ...], [word21, word22, ...], ...]
清洗后的文本数据
:return X_w2v: ndarray
shape: (num_seq, max_seq_length, w2v_dim)
词嵌入后的数据
"""
max_seq_length = 30 # 句子中的最大词语数
w2v_dim = 300 # 词向量维度
num_seq = len(cleaned_X) # 句子数
X_w2v = np.zeros((num_seq, max_seq_length, w2v_dim))
seq_count = 0
for seq in cleaned_X:
word_count = 0
for word in seq:
try:
X_w2v[seq_count][word_count] = w2v[word]
except KeyError:
X_w2v[seq_count][word_count] = unknown_embedding
word_count += 1
# 如果词比max_seq_length多就跳过
if word_count >= max_seq_length:
break
seq_count += 1
return X_w2v
3 模型训练
3.1 RNN
class RNN(nn.Module):
def __init__(self, num_hiddens, num_inputs, num_outputs, bidirectional=False,
num_layers=1):
super().__init__()
self.num_hiddens_rnn = num_hiddens
self.num_hiddens_linear = (2 * num_hiddens) if bidirectional else num_hiddens
self.rnn_layer = nn.RNN(input_size=num_inputs, hidden_size=self.num_hiddens_rnn,
batch_first=True, bidirectional=bidirectional,
num_layers=num_layers)
self.linear = nn.Linear(in_features=self.num_hiddens_linear, out_features=num_outputs)
self.softmax = nn.Softmax()
self.state = None
def forward(self, input, state):
"""
前向传播
:param input: tensor
shape: (batch_size, max_seq_length, w2v_dim)
输入数据
:param state: tensor
shape: (num_layers, batch_size, num_outputs)
隐藏层状态
:return output: tensor
shape: (batch_size, num_outputs)
输出结果
:return state: tensor
shape: (num_layers, batch_size, num_outputs)
隐藏层状态
"""
# rnn_y shape: (batch_size, seq_length, w2v_dim)
rnn_y, self.state = self.rnn_layer(input, state)
rnn_last_y = rnn_y[:, -1, :]
linear_y = self.linear(rnn_last_y.view(-1, rnn_last_y.shape[-1]))
output = self.softmax(linear_y)
return output, self.state
在模型定义中,要考虑RNN是否为双向的。由于双向RNN的隐藏层个数是双倍的,所以如果是单向RNN,则FC的输入是RNN隐藏层个数;但是如果是双向RNN,则FC的输入是RNN隐藏层个数的两倍。同时在前向传播的时候,由于RNN在自身循环的过程中,每个步长(step)都会有输出,所以RNN的输出rnn_y的shape为(batch_size, seq_length, w2v_dim)。但是我们输入到FC中,只需要考虑RNN最后一个步长的输出,也就是只需要rnn_y[:, -1, :]。
3.2 k折交叉验证
由于数据量过少(ipad数据集中带有情感倾向的句子仅101条),为了使得训练有效果,这里采用k折交叉验证的方法来进行训练。
def get_k_fold_data(k, i, X, y):
"""
获得第i折交叉验证所需要的数据
:param k: int
交叉验证的折数
:param i: int
第i轮交叉验证
:param X: tensor
shape: (num_seq, seq_length, w2v_dim)
输入数据
:param y: tensor
shape: (num_seq, )
:return X_train: tensor
shape: ((num_seq // k) * (k - 1), seq_length, w2v_dim)
第i折训练数据
:return y_train: tensor
shape: ((num_seq // k) * (k - 1), )
第i折训练标签
:return X_valid: tensor
shape: (num_seq // k, seq_length, w2v_dim)
第i折验证数据
:return y_valid: tensor
shape: (num_seq // k, seq_length, w2v_dim)
第i折验证标签
"""
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train, X_valid, y_valid = None, None, None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size) # 获得元素切片
X_part, y_part = X[idx, :], y[idx]
if j == i:
# 如果是第i折数据, 则这部分数据为验证集的数据
X_valid, y_valid = X_part, y_part
elif X_train is None:
# 如果不是第i折数据, 且训练集为空, 则这部分数据为训练集第一部分数据
X_train, y_train = X_part, y_part
else:
# 如果不是第i折数据, 且训练集不为空, 则这部分数据拼接到训练集中
X_train = torch.cat((X_train, X_part), dim=0)
y_train = torch.cat((y_train, y_part), dim=0)
return X_train, y_train, X_valid, y_valid
由于这里切片不是随机切片,所以在之后训练的时候不同情况下每一折对应的数据都是相同的。
3.3 获得准确率
def get_accuracy(y_hat, y):
"""
判断预测准确率
:param y_hat: tensor
shape: (batch_size, num_outputs)
预测数据
:param y: tensor
shape: (batch_size, )
真实数据
:return: float
准确率
"""
return (y_hat.argmax(dim=1) == y).float().mean().item()
这里就是比较两个tensor中相同的数据,再将bool转为float,最后取个均值。
3.4 训练
def train(model, batch_size, X_train, y_train, X_test, y_test, lr, num_epochs,
weight_decay):
"""
训练数据
:param model: Object
模型的实例化对象
:param batch_size: int
每个batch的大小
:param X_train: tensor
shape: ((num_seq // k) * (k - 1), seq_length, w2v_dim)
训练数据
:param y_train: tensor
shape: ((num_seq // k) * (k - 1), )
训练标签
:param X_test: tensor
shape: (num_seq // k, seq_length, w2v_dim)
测试数据
:param y_test: tensor
shape: (num_seq // k, )
测试标签
:param lr: float
学习率
:param num_epochs: int
迭代次数
:param weight_decay: float
权重衰减参数
:return : float
该折训练集的平均损失
:return : float
该折训练集的平均准确率
:return : float
该折测试集的平均损失
:return : float
该折测试集的平均准确率
"""
state = None
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=lr, weight_decay=weight_decay)
train_dataset = Data.TensorDataset(X_train, y_train)
test_dataset = Data.TensorDataset(X_test, y_test)
train_iter = Data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True,
drop_last=True)
test_iter = Data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False,
drop_last=True)
train_ls_sum, train_acc_sum, test_ls_sum, test_acc_sum = [], [], [], []
for epoch in range(num_epochs):
start = time.time()
train_ls, test_ls, train_acc, test_acc = 0.0, 0.0, 0.0, 0.0
train_n = 0
model.train()
for X, y in train_iter:
if state is not None:
state = state.detach()
# y_hat: shape (batch_size, num_outputs)
y_hat, state = model(X, state)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_ls += l.item()
train_acc += get_accuracy(y_hat, y)
train_n += 1
train_ls_sum.append(train_ls / train_n)
train_acc_sum.append(train_acc / train_n)
test_n = 0
model.eval()
for X, y in test_iter:
state = state.detach()
y_hat, state = model(X, state)
l = loss(y_hat, y)
test_ls += l.item()
test_acc += get_accuracy(y_hat, y)
test_n += 1
test_ls_sum.append(test_ls / test_n)
test_acc_sum.append(test_acc / test_n)
if (epoch + 1) % 20 == 0:
print('epoch %d, train loss %f, train accuracy %f, test loss %f,'
' test accuracy %f, sec %.2f' % (epoch + 1, train_ls / train_n,
train_acc / train_n, test_ls / test_n,
test_acc / test_n, time.time() - start))
return np.array(train_ls_sum).mean(), np.array(train_acc_sum).mean(), np.array(test_ls_sum).mean(), np.array(test_acc_sum).mean()
训练就很简单,输入模型得到输出,将输出与ground truth计算得到损失,再将损失反向传播并进行优化。计算结果如下(由于计算结果太多,这里就只贴每一折的平均结果):
一层单向RNN:
fold 0, avg train loss 0.810535, avg train accuracy 0.502727, avg test loss 0.872012, avg test accuracy 0.441250
fold 1, avg train loss 0.822909, avg train accuracy 0.490455, avg test loss 0.804511, avg test accuracy 0.508750
fold 2, avg train loss 0.754017, avg train accuracy 0.558977, avg test loss 0.793262, avg test accuracy 0.520000
fold 3, avg train loss 0.692104, avg train accuracy 0.621364, avg test loss 0.938262, avg test accuracy 0.375000
fold 4, avg train loss 0.723584, avg train accuracy 0.589773, avg test loss 0.688262, avg test accuracy 0.625000
fold 5, avg train loss 0.783596, avg train accuracy 0.529659, avg test loss 0.672012, avg test accuracy 0.641250
fold 6, avg train loss 0.715181, avg train accuracy 0.598182, avg test loss 0.810762, avg test accuracy 0.502500
fold 7, avg train loss 0.879286, avg train accuracy 0.433977, avg test loss 1.188262, avg test accuracy 0.125000
fold 8, avg train loss 0.772638, avg train accuracy 0.540341, avg test loss 0.874512, avg test accuracy 0.438750
fold 9, avg train loss 0.734858, avg train accuracy 0.578295, avg test loss 0.688262, avg test accuracy 0.625000
一层双向RNN:
fold 0, avg train loss 0.822019, avg train accuracy 0.491023, avg test loss 0.884512, avg test accuracy 0.428750
fold 1, avg train loss 0.829646, avg train accuracy 0.483523, avg test loss 0.990762, avg test accuracy 0.322500
fold 2, avg train loss 0.709826, avg train accuracy 0.603182, avg test loss 0.820762, avg test accuracy 0.492500
fold 3, avg train loss 0.712125, avg train accuracy 0.601364, avg test loss 0.939512, avg test accuracy 0.373750
fold 4, avg train loss 0.904861, avg train accuracy 0.408182, avg test loss 0.938262, avg test accuracy 0.375000
fold 5, avg train loss 0.820200, avg train accuracy 0.492614, avg test loss 0.720762, avg test accuracy 0.592500
fold 6, avg train loss 0.888947, avg train accuracy 0.424205, avg test loss 0.878262, avg test accuracy 0.435000
fold 7, avg train loss 0.746789, avg train accuracy 0.566364, avg test loss 0.438262, avg test accuracy 0.875000
fold 8, avg train loss 0.857042, avg train accuracy 0.456023, avg test loss 0.809512, avg test accuracy 0.503750
fold 9, avg train loss 0.735992, avg train accuracy 0.577386, avg test loss 0.688262, avg test accuracy 0.625000
两层单向RNN:
fold 0, avg train loss 0.808604, avg train accuracy 0.504773, avg test loss 0.798262, avg test accuracy 0.515000
fold 1, avg train loss 0.810300, avg train accuracy 0.502841, avg test loss 0.798131, avg test accuracy 0.515000
fold 2, avg train loss 0.723536, avg train accuracy 0.589545, avg test loss 0.815762, avg test accuracy 0.497500
fold 3, avg train loss 0.796740, avg train accuracy 0.516250, avg test loss 0.828262, avg test accuracy 0.485000
fold 4, avg train loss 0.818769, avg train accuracy 0.494205, avg test loss 0.794512, avg test accuracy 0.518750
fold 5, avg train loss 0.859167, avg train accuracy 0.454091, avg test loss 1.077012, avg test accuracy 0.236250
fold 6, avg train loss 0.809155, avg train accuracy 0.504091, avg test loss 0.815762, avg test accuracy 0.497500
fold 7, avg train loss 0.820331, avg train accuracy 0.492841, avg test loss 0.785762, avg test accuracy 0.527500
fold 8, avg train loss 0.796669, avg train accuracy 0.516364, avg test loss 0.784512, avg test accuracy 0.528750
fold 9, avg train loss 0.796672, avg train accuracy 0.516477, avg test loss 0.792012, avg test accuracy 0.521250
两层双向RNN:
fold 0, avg train loss 0.703241, avg train accuracy 0.610114, avg test loss 0.938262, avg test accuracy 0.375000
fold 1, avg train loss 0.847246, avg train accuracy 0.465682, avg test loss 1.147012, avg test accuracy 0.166250
fold 2, avg train loss 0.810004, avg train accuracy 0.503182, avg test loss 0.818262, avg test accuracy 0.495000
fold 3, avg train loss 0.719913, avg train accuracy 0.593295, avg test loss 0.868262, avg test accuracy 0.445000
fold 4, avg train loss 0.787465, avg train accuracy 0.525568, avg test loss 0.827012, avg test accuracy 0.486250
fold 5, avg train loss 0.872139, avg train accuracy 0.440909, avg test loss 1.132012, avg test accuracy 0.181250
fold 6, avg train loss 0.766593, avg train accuracy 0.546364, avg test loss 0.830762, avg test accuracy 0.482500
fold 7, avg train loss 0.811224, avg train accuracy 0.501932, avg test loss 0.798262, avg test accuracy 0.515000
fold 8, avg train loss 0.819079, avg train accuracy 0.494091, avg test loss 0.845763, avg test accuracy 0.467500
fold 9, avg train loss 0.817585, avg train accuracy 0.495568, avg test loss 0.772012, avg test accuracy 0.541250