博客项目知识点的总结和拓展
整体架构
后台目录:
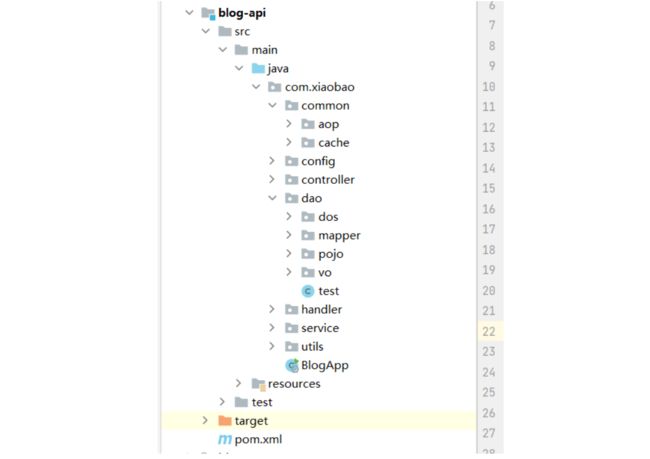
本项目后台是由SpringBoot框架为基础进行开发的一款Java项目。
通过上述目录图,大致能分为三层:
- 控制层:获取前端来的请求。
- 服务层:对控制层的一些请求进行相对应的逻辑处理。
- DAO层:对数据库数据的增删改查。
当然除了大致三层还有一些工具类、配置、缓存和aop等技术的加持。
数据表的分析
article表:
DROP TABLE IF EXISTS `article`; CREATE TABLE `article` ( `id` bigint(0) NOT NULL AUTO_INCREMENT, `comment_counts` int(0) NULL DEFAULT NULL COMMENT '评论数量', `create_date` bigint(0) NULL DEFAULT NULL COMMENT '创建时间', `summary` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '简介', `title` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '标题', `view_counts` int(0) NULL DEFAULT NULL COMMENT '浏览数量', `weight` int(0) NOT NULL COMMENT '是否置顶', `author_id` bigint(0) NULL DEFAULT NULL COMMENT '作者id', `body_id` bigint(0) NULL DEFAULT NULL COMMENT '内容id', `category_id` int(0) NULL DEFAULT NULL COMMENT '类别id', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1405916999732707331 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
从表结构中我们能知道id字段是自增不为空,且使用了BTREE索引。
补充:
B-TREE索引
B-TREE索引的特点
- B-TREEB-TREE以B+树结构存储数据,大大加快了数据的查询速度
- B-TREE索引在范围查找的SQL语句中更加适合(顺序存储)
B-TREE索引使用场景
- 全值匹配的查询SQL,如 where act_id= '1111_act'
- 联合索引汇中匹配到最左前缀查询,如联合索引 KEY idx_actid_name(act_id,act_name) USING BTREE,只要条件中使用到了联合索引的第一列,就会用到该索引,但如果查询使用到的是联合索引的第二列act_name,该SQL则便无法使用到该联合索引(注:覆盖索引除外)
- 匹配模糊查询的前匹配,如where act_name like '11_act%
- 匹配范围值的SQL查询,如where act_date > '9865123547215'(not in和<>无法使用索引)
- 覆盖索引的SQL查询,就是说select出来的字段都建立了索引
article_body表:
DROP TABLE IF EXISTS `article_body`; CREATE TABLE `article_body` ( `id` bigint(0) NOT NULL AUTO_INCREMENT, `content` longtext CHARACTER SET utf8 COLLATE utf8_general_ci NULL, `content_html` longtext CHARACTER SET utf8 COLLATE utf8_general_ci NULL, `article_id` bigint(0) NOT NULL, PRIMARY KEY (`id`) USING BTREE, INDEX `article_id`(`article_id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1405916999854342147 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
本表共有:
- 自身ID
- 评论
- 文章ID
主键为ID,然后给article_id增加BTREE索引。
article_tag表:
DROP TABLE IF EXISTS `article_tag`; CREATE TABLE `article_tag` ( `id` bigint(0) NOT NULL AUTO_INCREMENT, `article_id` bigint(0) NOT NULL, `tag_id` bigint(0) NOT NULL, PRIMARY KEY (`id`) USING BTREE, INDEX `article_id`(`article_id`) USING BTREE, INDEX `tag_id`(`tag_id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1405916999787233282 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
本表有:
- 自增的主键ID
- 文章ID
- 和tag_id
设置article和tag_id为BTREE索引。
category表:
DROP TABLE IF EXISTS `category`; CREATE TABLE `category` ( `id` bigint(0) NOT NULL AUTO_INCREMENT, `avatar` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL, `category_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL, `description` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 6 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
本表有:
- 非空自增ID
- 用户头像地址
- 分类名字
- 分类介绍
comment表:
DROP TABLE IF EXISTS `ms_comment`; CREATE TABLE `ms_comment` ( `id` bigint(0) NOT NULL AUTO_INCREMENT, `content` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL, `create_date` bigint(0) NOT NULL, `article_id` int(0) NOT NULL, `author_id` bigint(0) NOT NULL, `parent_id` bigint(0) NOT NULL, `to_uid` bigint(0) NOT NULL, `level` varchar(1) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, PRIMARY KEY (`id`) USING BTREE, INDEX `article_id`(`article_id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1405209691876790275 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
本表有:
- 非空自增ID
- 评论内容
- 创建时间
- 文章ID
- 作者ID
- 父评论ID
- 对谁评论ID
- 评论level
user表:
DROP TABLE IF EXISTS `user`; CREATE TABLE `user` ( `id` bigint(0) NOT NULL AUTO_INCREMENT, `account` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '账号', `admin` bit(1) NULL DEFAULT NULL COMMENT '是否管理员', `avatar` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '头像', `create_date` bigint(0) NULL DEFAULT NULL COMMENT '注册时间', `deleted` bit(1) NULL DEFAULT NULL COMMENT '是否删除', `email` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '邮箱', `last_login` bigint(0) NULL DEFAULT NULL COMMENT '最后登录时间', `mobile_phone_number` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '手机号', `nickname` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '昵称', `password` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '密码', `salt` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '加密盐', `status` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '状态', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1404448588146192387 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
tag表:
DROP TABLE IF EXISTS `tag`; CREATE TABLE `tag` ( `id` bigint(0) NOT NULL AUTO_INCREMENT, `avatar` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL, `tag_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 11 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
核心功能介绍
控制层
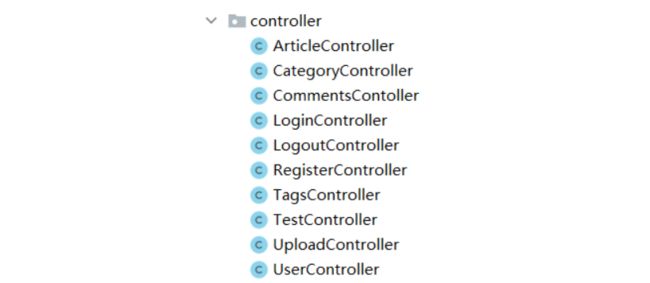
通过上图我们知道每一个Controller对应着前端页面相对应的请求功能。
注:本项目的所有代码都开源在Gitee上,有需要可以去自己看一下哦。
接下来我们举例看一下一些Controller的功能。
ArticleController:
//json数据交互
@RestController
@RequestMapping("articles")
public class ArticleController {
@Autowired
ArticleService articleService;
/**
* 首页文章列表
* @param pageParams
* @return
*/
//切面注解
@LogAnnotation(module = "文章",operation = "获取文章列表")
//放入缓存
@Cache(expire = 5 * 60 * 1000,name = "ListArticle")
@PostMapping
public Result listArticle(@RequestBody PageParams pageParams){
return articleService.listArticle(pageParams);
}
/**
* 首页最热文章
* @return
*/
@PostMapping("hot")
@Cache(expire = 5 * 60 * 1000,name = "hot_article")
public Result hotArticle(){
int limit = 5;
return articleService.hotArticle(limit);
}
@PostMapping("new")
@Cache(expire = 5 * 60 * 1000,name = "new_article")
public Result newArticle(){
int limit = 5;
return articleService.newArticles(limit);
}
/**
* 首页 文章归档
* @return
*/
@PostMapping("listArchives")
public Result listArchives(){
return articleService.listArchives();
}
@PostMapping("view/{id}")
public Result findArticleById(@PathVariable("id") Long articleId){
return articleService.findArticleById(articleId);
}
// @RequestBody主要用来接收前端传递给后端的json字符串中的数据的(请求体中的数据的);
// 而最常用的使用请求体传参的无疑是POST请求了,所以使用@RequestBody接收数据时,一般都用POST方式进行提交。
@PostMapping("publish")
public Result publish(@RequestBody ArticleParam articleParam){
return articleService.publish(articleParam);
}
服务层
Service层也就是来处理Controller层的一些请求。
我们接着上面的
ArticleServiceImpl:
@Service
public class ArticleServiceImpl implements ArticleService {
//通过注解来调用其他的Mapper和service层
@Autowired
ArticleMapper articleMapper;
@Autowired
private SysUserService sysUserService;
@Autowired
private TagService tagService;
@Autowired
private CategoryService categoryService;
@Override
public Result listArticle(PageParams pageParams) {
Page page = new Page<>(pageParams.getPage(),pageParams.getPageSize());
IPage articleIPage =
this.articleMapper.listArticle(page,pageParams.getCategoryId(),pageParams.getTagId(),pageParams.getYear(),pageParams.getMonth());
return Result.success(copyList(articleIPage.getRecords(),true,true));
}
@Override
public Result hotArticle(int limit) {
LambdaQueryWrapper queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.orderByDesc(Article::getViewCounts);
queryWrapper.orderByDesc(Article::getId,Article::getTitle);
//"limit"字待串后要加空格,不要忘记加空格,不然会把数据拼到一起
queryWrapper.last("limit "+limit);
List articles = articleMapper.selectList(queryWrapper);
return Result.success(copyList(articles,false,false));
}
@Override
public Result newArticles(int limit) {
LambdaQueryWrapper queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.orderByDesc(Article::getCreateDate);
queryWrapper.select(Article::getId,Article::getTitle);
queryWrapper.last("limit "+limit);
//select id,title from article order by create_date desc limit 5
List articles = articleMapper.selectList(queryWrapper);
return Result.success(copyList(articles,false,false));
}
private List copyList(List records,boolean isTag,boolean isAuthor) {
ArrayList articleVoList = new ArrayList<>();
for (Article record : records) {
articleVoList.add(copy(record,isTag,isAuthor,false,false));
}
return articleVoList;
}
private List copyList(List records, boolean isTag, boolean isAuthor,boolean isBody) {
List articleVoList = new ArrayList<>();
for (Article record : records) {
articleVoList.add(copy(record,isTag,isAuthor,isBody,false));
}
return articleVoList;
}
private List copyList(List records, boolean isTag, boolean isAuthor,boolean isBody,boolean isCategory) {
List articleVoList = new ArrayList<>();
for (Article record : records) {
articleVoList.add(copy(record,isTag,isAuthor,isBody,isCategory));
}
return articleVoList;
}
private ArticleVo copy(Article article,boolean isTag,boolean isAuthor, boolean isBody,boolean isCategory){
ArticleVo articleVo = new ArticleVo();
articleVo.setId(String.valueOf(article.getId()));
BeanUtils.copyProperties(article,articleVo);
articleVo.setCreateDate(new DateTime(article.getCreateDate()).toString("yyyy-MM-dd HH:mm"));
if(isTag){
Long id = article.getId();
articleVo.setTags(tagService.findTagsByArticleId(id));
}
if(isAuthor){
Long authorId = article.getAuthorId();
articleVo.setAuthor(sysUserService.findUserById(authorId).getNickname());
}
if (isBody){
Long bodyId = article.getBodyId();
articleVo.setBody(findArticleBodyById(bodyId));
}
if (isCategory){
Long categoryId = article.getCategoryId();
articleVo.setCategory(categoryService.findCategoryById(categoryId));
}
return articleVo;
}
@Override
public Result listArchives() {
/*
文章归档
*/
List archivesList = articleMapper.listArchives();
return Result.success(archivesList);
}
@Autowired
private ThreadService threadService;
@Override
public Result findArticleById(Long articleId) {
/**
* 1. 根据id查询 文章信息
* 2. 根据bodyId和categoryid 去做关联查询
*/
Article article = this.articleMapper.selectById(articleId);
ArticleVo articleVo = copy(article, true, true,true,true);
//查看完文章了,新增阅读数,有没有问题呢?
//查看完文章之后,本应该直接返回数据了,这时候做了一个更新操作,更新时加写锁,阻塞其他的读操作,性能就会比较低
// 更新 增加了此次接口的 耗时 如果一旦更新出问题,不能影响 查看文章的操作
//线程池 可以把更新操作 扔到线程池中去执行,和主线程就不相关了
//threadService.updateArticleViewCount(articleMapper,article);
threadService.updateArticleViewCount(articleMapper,article);
return Result.success(articleVo);
}
@Autowired
private ArticleTagMapper articleTagMapper;
@Override
@Transactional
public Result publish(ArticleParam articleParam) {
//注意想要拿到数据必须将接口加入拦截器
SysUser sysUser = UserThreadLocal.get();
/**
* 1. 发布文章 目的 构建Article对象
* 2. 作者id 当前的登录用户
* 3. 标签 要将标签加入到 关联列表当中
* 4. body 内容存储 article bodyId
*/
Article article = new Article();
article.setAuthorId(sysUser.getId());
article.setCategoryId(Long.parseLong(articleParam.getCategory().getId()));
article.setCreateDate(System.currentTimeMillis());
article.setCommentCounts(0);
article.setSummary(articleParam.getSummary());
article.setTitle(articleParam.getTitle());
article.setViewCounts(0);
article.setWeight(Article.Article_Common);
article.setBodyId(-1L);
//插入之后 会生成一个文章id(因为新建的文章没有文章id所以要insert一下
//官网解释:"insart后主键会自动'set到实体的ID字段。所以你只需要"getid()就好
// 利用主键自增,mp的insert操作后id值会回到参数对象中
//https://blog.csdn.net/HSJ0170/article/details/107982866
this.articleMapper.insert(article);
//tags
List tags = articleParam.getTags();
if (tags != null) {
for (TagVo tag : tags) {
ArticleTag articleTag = new ArticleTag();
articleTag.setArticleId(article.getId());
// System.out.println("这个是tag:"+tag);
articleTag.setTagId(Long.parseLong(tag.getId()));
this.articleTagMapper.insert(articleTag);
}
}
//body
ArticleBody articleBody = new ArticleBody();
articleBody.setContent(articleParam.getBody().getContent());
articleBody.setContentHtml(articleParam.getBody().getContentHtml());
articleBody.setArticleId(article.getId());
articleBodyMapper.insert(articleBody);
//插入完之后再给一个id
article.setBodyId(articleBody.getId());
//MybatisPlus中的save方法什么时候执行insert,什么时候执行update
//只有当更改数据库时才插入或者更新,一般查询就可以了
articleMapper.updateById(article);
ArticleVo articleVo = new ArticleVo();
articleVo.setId(String.valueOf(article.getId()));
return Result.success(articleVo);
}
private CategoryVo findCategory(Long categoryId) {
return categoryService.findCategoryById(categoryId);
}
//构建ArticleBodyMapper
@Autowired
private ArticleBodyMapper articleBodyMapper;
private ArticleBodyVo findArticleBodyById(Long bodyId) {
ArticleBody articleBody = articleBodyMapper.selectById(bodyId);
ArticleBodyVo articleBodyVo = new ArticleBodyVo();
articleBodyVo.setContent(articleBody.getContent());
return articleBodyVo;
}
}
服务层是需要调用其他服务的功能和DAO层的一个处理层,通过上诉代码我们能大概知道服务层是很关键的一层。处理很多相对应的接口功能。
DAO层
DAO层也就是对数据库进行操作的一个阶层,一般我们会称为Mapper层来,会使用Mybatis或者Mybatis-plus进行操作。
本次项目使用的是MyBatis-Pluss。
例如:
ArticleMapper:
public interface ArticleMapper extends BaseMapper{ List listArchives(); IPage listArticle(Page page , Long categoryId, Long tagId, String year, String month ); }
技术亮点
- 1、jwt + redis
-
- token令牌的登录方式,访问认证速度快,session共享,安全性
-
- redis做了令牌和用户信息的对应管理,
-
- 1,进一步增加了安全性
-
- 2、登录用户做了缓存
-
- 3、灵活控制用户的过期(续期,踢掉线等)
- 2、threadLocal使用了保存用户信息,请求的线程之内,可以随时获取登录的用户,做了线程隔离
- 3、在使用完ThreadLocal之后,做了value的删除,防止了内存泄漏(这面试说强引用。弱引用。不是明摆着让面试官间JVM嘛)
- 4·、线程安全-update table set value = newValue where id=1 and value=oldValue
- 5、线程池应用非常广,面试7个核心参数(对当前的主业务流程无影响的操作,放入线程池执行)
-
- 1.登录,记录日志
- 6·权限系统重点内容
- 7·统一日志记录,统一缓存处理
项目优化
- 文章可以放入es当中,便于后续中文分词搜索。springboot教程有和es的整合
- 评论数据,可以考虑放入mongodb当中 电商系统当中 评论数据放入mongodb中
- 阅读数和评论数 ,考虑把阅读数和评论数 增加的时候 放入redis
incr自增,使用定时任务 定时把数据固话到数据库当中
- 为了加快访问速度,部署的时候,可以把图片,js,css等放入七牛云存储中,加快网站访问速度
- 做一个后台 用springsecurity 做一个权限系统,对工作帮助比较大
面试
1、项目本身
- 1.1. 项目的背景是什么,解决一个什么样的问题?
- 1.2. 项目中你的职责是什么?
- 1.3. 项目的基础功能有哪些?
- 1.4. 项目使用的技术栈是什么,技术架构是怎么样的?
- 1.5. 使用微服务了吗? 项目是怎么搭建的,机器配置是什么样的,有做分布式吗?
- 1.6. 项目的具体功能细节,比如论坛项目中评论是如何存储的?怎么展示所有的评论?
- 1.7. 项目中框架或者中间件的使用细节。项目里怎么用ES的,ES怎么支持搜索的?缓存和DB是如何结合使用的?
2、项目扩展
- 2.1. 项日存在哪些问题,你准备怎么解决?
- 2.2. 项目的具体功能点如何优化?如论坛项目,查询评论是在DB里扫表查询吗?想要查询更快可以做哪些优化?
- 2.3. 项目中最有挑战的模块是哪个,你是怎么解决的?
- 2.4. 项目中使用某种框架的原因,比如使用了本地缓存Caffeine,为什么使用这个Caffeine,不使用Guava?
项目要增大10倍的qps,你会怎么设计?
- 2.5. 项目上线后出现线上问题怎么解决?如频繁fullGc,定时任务失败怎么办?
3、高频问题
- 1、找个印象最深的项目说说?(简历中不止一个项目)
- 2、你项目中遇到的最大的问题是什么?你是怎么解决的?
- 3、你项目中用到的技术栈是如何学习的?
- 4、为什么做这个项目,技术选型为什么是这样的?
- 5、登录怎么做的?单点登录说说你的理解?
- 6、项目遇到的最大挑战是什么?(类似问题2)
- 7、说说项目中的闪光点和亮点?
- 8、项目怎么没有尝试部署上线呢?
- 9、介绍项目具体做了什么?(项目背景)
- 10、如果让你对这个项目优化,你会从哪几个点来优化呢?
以上总结的10大高频问题,均来自网友的面试问题分享。
大家做完一个项目之后,一定要去细扣一两个模块,并在面试中与面试官进行深入的交流。
比如说登录,可以思考一下登录具体的流程,前后端如何执行步骤。
比如一些电商类的分布式锁,是如何实现的?分布式事务等?这些均可以细致去思考准备等。
通过自己具体介绍项目中的一两个模块,面试官就会对你有比较深入的了解,这样给你的面评就会比较好。
当然在项目中可能还会引出一些其他的内容,顺延可能就到八股文环节了~
如果是实现的比较简单,没有使用什么中间件,只有增删改查,就会针对表的设计,一些模块的设计思路,还有场景问题,大多是那些你没有使用的中间件解决的问题:问如果很多用户访问你的主页,你会怎么办(这种高并发的问题是使用中间件解决的,你没用到,看你能不能很好的回答上来怎么解决)
4、结合电商类面试题分析一些流程
- 秒杀三问题: 高并发, 少卖, 超卖. 问题描述和解决方法?
- 问秒杀项目:介绍一下你对项目高并发和高可用的理解?
- 库存超卖如何解决的?(商城类项目)
- Redis缓存的库存怎么解决库存的超卖?
- 项目支持多大的并发量?有没有测试过呢?
- 你这个项目中消息中间件用来做什么的? 限流如何实现? 分布式锁和分布式事务项目有用到吗?详细聊聊?
- 分布式锁有哪些实现方式?你项目中用到的是哪一种? 谈谈你对分布式事务的理解,你觉得重要吗? 分布式事务有哪些实现方式?Seata 用过吗?
- 抢购业务流程说说? 如何实现在秒杀场景下的限流服务? 流量削峰在秒杀场景下有考虑过存在的问题和解决方案吗?
- 如果请求的数据丢失该怎么办?有什么解决方法吗?
5、论坛问题参考
其实大家做的项目,不管是什么类型,面试官更多关注的是通过这个项目你学到了什么,有什么收获,有什么自己的思考等,这些才是更重要的。
强烈建议大家好好去看看推送的项目在面试中如何准备的第一期推文,里面包含了10个非常非常高频的问题。
尤其是自己在项目遇到最大困难或者问题是什么?是怎么思考和解决的?
很多朋友可能会说,这个项目是跟着视频和文档一步步来的,似乎也没遇到很大的问题。
你可以这么回答(提供两个点,其他的大家可以发散一下思维)
我在做xx项目的时候,可能遇到的最大的问题就是xx技术的问题,在处理xx模块的时候,对xx技术的使用不太熟练等。
再或者是一些细节的错误等,如Redis连接不上SpringBoot等,或者虚拟机配置网关错误等。
以上只是两个方面,仅供参考,一定要加入自己的思考!
论坛类项目
今天给大家分享一下论坛类项目的高频问题。
做论坛类项目的朋友也比较多,如仿牛客论坛、仿CSDN、仿博客园等。
这类项目主要涉及到文章或者帖子的发布,所以更多的面试问题是围绕这些实际问题来提问的。
通过一些面经问题和实际的论坛类项目的背景,整理出下面10个高频的项目问题。
论10大高频问题汇总
- 1、登录用微信或者QQ登录的方式,说一下有几次交互过程?
- 2、怎么同时多篇文章的提交,多个评论的产生,如何解决高并发问题。
- 3、项目中的xx技术栈的作用是什么?当时为何没有考虑其他技术栈呢?
- 4、对于帖子中的敏感词、评论区的敏感词是如何处理的?
- 5、关注、点赞和收藏是否会提醒?如何做到的呢?用了什么技术栈?
- 6、ES的功能是什么?如何解决ES和数据库的同步功能?
- 7、帖子是否有置顶、加精和删除的功能?置顶是如何实现的?
- 8、是否有热榜排序功能?使用的是Redis那个数据结构?
- 9、是否做过测试,同时支持多少人发帖?
- 10、对于同名的文章怎么处理?会检测恶意刷帖吗?
上述问答我会抽时间慢慢补充的哦,希望能够对大家有所帮助。