GMM(高斯混合模型)的动态背景分割
以下是GMM(高斯混合模型)的动态背景分割的实验报告以及源码,另外用到了形态学操作与多通道的处理,提升了实验结果的性能。
一.实验名称
基于混合高斯模型的动态背景分割
二.实验目的
探索如何对Wavingtrees等具有动态背景的数据集进行有效的建模并分割,检测前景物体。
三.实验原理
3.1 前言
时域中的同一个点的像素值看做是一个像素过程,由一组像素组成,如果这里只考虑灰度图的话,对于点x0 ,y0 处于时间t 的像素历史值为
![]()
其中I 代表着图像序列,由于各种因素,环境中的背景往往不是完全不变的,下图展示在wavingtrees中两个像素点随着帧数其像素值的变化。

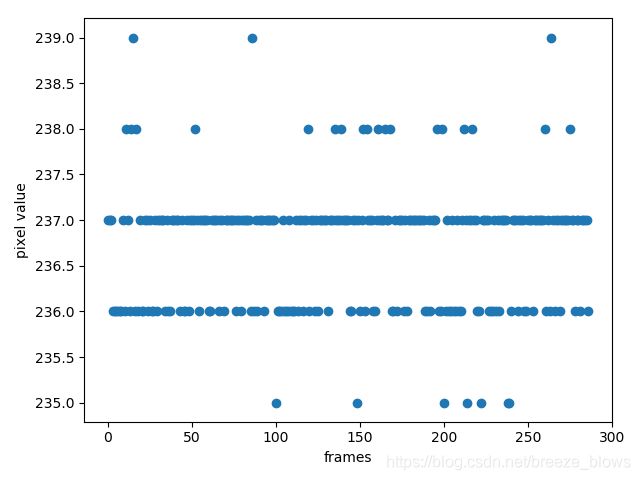

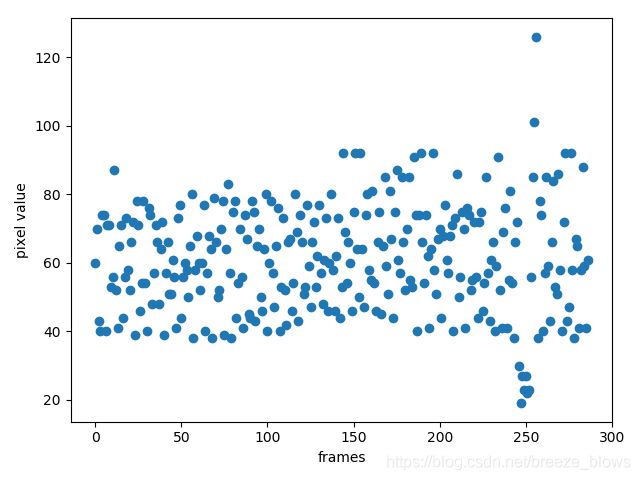
图3.1 像素值变化图
从上图可以看出,我们在第一帧中选取了两个点,一个点坐标值为(11,14).位于较为远离树的位置,另一个点坐标值为(102,78)。位于树与人交叉的位置。从右上角与右下角的图表示像素值随着帧数的变化。横坐标为帧数,纵坐标为像素值的大小。可以明显的看出,随着时间的推移,即随着帧数的增加,像素点的值的分布较为分散,特别是前景与背景交叉的区域。所以单个模型,比如单个高斯模型难以适应这种场景。采用高斯混合模型就可以较好的适应这种变换。
3.2 高斯混合模型
3.2.1 背景建模
(1)高斯模型定义
鉴于由于背景环境的复杂变化,单个高斯模型难以适应,考虑对每个像素值序列X1,…,Xn 建立K 个高斯分布综合描述。当前像素值得到的概率密度函数由以下公式进行描述:

![]() 是该点对应的高斯模型的最大数目,
是该点对应的高斯模型的最大数目,![]() 是时间
是时间![]() 时的第
时的第![]() 个高斯模型的权重,即当前高斯模型对于该像素点对应的所有模型占得权重,
个高斯模型的权重,即当前高斯模型对于该像素点对应的所有模型占得权重,![]() 是时间
是时间![]() 时的第
时的第![]() 个高斯模型的期望,
个高斯模型的期望,![]() 是时间
是时间![]() 时的第
时的第![]() 个高斯模型的协方差矩阵,
个高斯模型的协方差矩阵,![]() 代表高斯概率密度方程:
代表高斯概率密度方程:
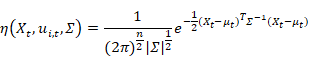
考虑到程序的空间与时间复杂度,![]() 的取值一般为3-5.而且协方差矩阵被简化为
的取值一般为3-5.而且协方差矩阵被简化为
![]()
因为在这里我们假设RGB三通道的数据具有互相独立而且相同的方差。虽然有些不符合现实,但是在损失了一些精度的代价下减少了程序的时间复杂度。
(2)训练过程
这里先采用若干张图片进行训练,即更新每个响度点对应的高斯混合模型的个数,高斯模型的参数等。背景建模的算法流程图如下
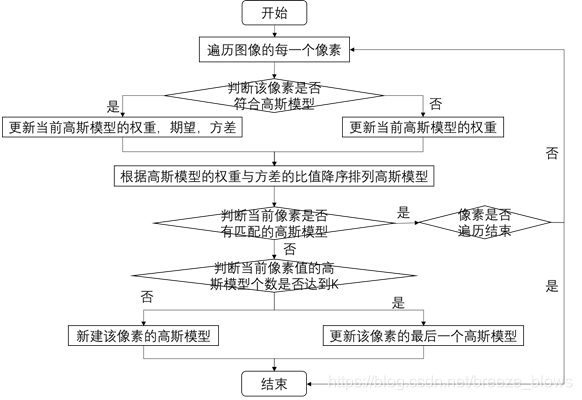
图3.2 算法流程图
在上图中,判断一个像素点是否服从高斯分布:像素值是否位于高斯分布的2.5倍标准差内。对于每个像素点对应的高斯模型,如果该像素值匹配到了某个高斯模型,则更新公式如下:
![]()
![]()
![]()
对于没有匹配到的高斯模型,其方差与期望不变,权重的更新按照上述公式。其中当像素点匹配了某个高斯模型的时候![]() 值为1,否则值为0。
值为1,否则值为0。
如果该像素值与其对应的高斯模型都不匹配,则判断当前像素值的高斯模型个数是否已到达上限阈值K。
1.如果达到的话,侧取权重与方差比值最低的那个高斯分布重新进行初始化。权重赋予一个较低的值,这个值在程序中取得0.05.方差赋值为一个较高的值,程序中取值为30.高斯分布的期望赋值为该像素点的值。
2.如果没有达到的话。则新建一个高斯分布。初始化步骤同上。权重赋予一个较低的值,这个值在程序中取得0.05.方差赋值为一个较高的值,程序中取值为30.高斯分布的期望赋值为该像素点的值。
当前像素值与其对应的高斯模型匹配结束之后,把该像素值对应的高斯模型按照权重与方差的比例降序排列,接着对所有高斯模型对应的权重进行归一化。
3.2.2 前景检测
每个像素值对应的各个高斯分布的参数会一直发生改变,当一个物体趋于静止的时候,对应的像素高斯分布的方差会趋于更小,其对应的权重会趋于变得更大,相对于一个运动的物体,他一般不会匹配到像素对应的高斯模型,运动的物体会让高斯模型的方差变得更大,权重变得更低。
我们按照高斯模型的权重与方差的比值进行降序排列,由阈值T(程序中取值为0.7)选出B个高斯分布作为当前像素判断是否属于背景的模型:
![]()
如果一个新的像素值服从该B 个高斯模型中的某一个,我们就认为该像素属于背景。但是如果该像素服从某个高斯分布,但是该高斯分布位于该B 个高斯模型之后,该像素仍然会被判定为前景。T的取值不宜过大,否则会产生一个多峰分布模型,背景模型如果是单峰值的话,会选出一个可能性最高的高斯分布。
3.2.3 形态学处理
背景往往不是一直不变的,有些背景可能会一直处于一种细微变化的状态,比如本实验给出的数据集wavingtrees,背景中的树一直处于在摇晃的状态,所以在检测前景的时候总是会把一些树的枝丫之类识别为前景。
为了去除一些被误识别为前景的树枝,考虑采用以下三种形态学操作。
(1)中值滤波:中值滤波常被用来处理椒盐噪声,这里的树枝可以看成是前景中的椒盐噪声。中值滤波的原理就是将当前像素值替换为周围领域像素值的中值。
(2)腐蚀:在周围都是背景的情况下,被误识别为前景的树枝可以经过腐蚀操作进行消除,但是这个操作会对前景中的人轮廓有一定的影响。
(3)膨胀:由于中值滤波或者腐蚀操作会对前景中的人造成一定的影响,即会让人的轮廓出现空洞,所以可以采用膨胀操作在一定程度上减弱这个影响。
3.2.4 三通道的考虑
这里运用的三通道其实就是在三个通道上进行背景建模与前景检测。
背景建模:每个通道的像素点都会建立数目最多为K个的高斯模型。每个通道的建模过程跟3.2.1小节与3.3.2小节描述的一样。
前景检测:原来是灰度图的单通道进行判断,其接受为前景就认为是前景,而现在对于三通道就需要三个通道都认为是前景才认为当前像素是前景。
四.实验结果
本实验采用在线训练,在线测试的方式,为了对比3.2小节描述的形态学操作与三通道的有效性。实验中做了多组对比实验。
4.1 三通道运用
不采用任何的形态学操作,运用RGB三通道与只利用单通道的效果如下图4.1所示。


(a)单通道 (b)多通道
图4.1 rgb效果对比图
在图4.1中,左边的图是仅仅考虑单通道的时候第247帧的效果,右边的图是考虑三通道之后第247帧的效果。可以明显看出考虑了三通道之后,前景中的人轮廓显得更加丰满了,而对于单通道的情况,人的轮廓中就会存在许多的空洞区域。原因就在于三通道的时候是每个通道都接受为前景才认为是前景,从而是前景的判断更加准确合理。
4.2 形态学操作
实验中考虑了两种形态学组成操作对图像进行处理。
在实验中我们对比了在考虑三通道的情况下,采用开运算,即先腐蚀后膨胀;与先进行中值滤波,在进行膨胀的效果。如下图4.2所示。


(a)开运算 (b)中值滤波与膨胀
图4.2 形态学操作对比图
在上图4.2中,左边的图是第247帧采用了开运算的效果,其中核为十字架形,大小为3;右边的图为先进行中值滤波,再采用膨胀操作之后的效果,其中中值滤波的核大小为7,膨胀操作的核大小为3。从实验结果可以看出。直接利用开运算没有先进行中值滤波,再进行膨胀的效果好,前者会使人的轮廓产生一些空洞。这证明了中值滤波的效果比腐蚀的效果要好。
当形态学操作采用先进行中值滤波,后进行膨胀操作之后,对比了膨胀不同的核大小对于结果的影响。仍然采用第247帧的效果对比。


(a)核大小为3 (b)核大小为5
图4.3
在图4.3中,左图表示膨胀的核大小为3,右边的图表示核的大小为5。可以看出当采用核大小为5的时候,人的轮廓显得更加丰满了。证明了核大小为5比3要好。
该实验的最后结果就是采用先进行中值滤波,后进行膨胀操作之后的效果。其中中值滤波的核大小为7,膨胀操作的核大小为5。
最后我们对比了opencv自带的createBackgroundSubtractorMOG2函数处理的效果与本实验最后得到的效果图。如下图4.4所示。



(a)本实验结果 (b)opencv(MOG2) (c)groundtruth
图4.4
在图4.4中,仍然是展示第247帧的效果。左边的图是本实验最后得到的最好结果图,中间的图是opencv自带的MOG2函数得到的效果图。右边的图是groundtruth。可以看出本实验得到的效果图已经和后面两张图非常类似,这就证明了本实验的算法的有效性。不过其实也可以看出,由本实验得出的图由于采用了膨胀操作,导致人的轮廓有些略大。
五.实验总结
建立高斯混合模型可以较为有效的分割出背景与前景。得到了像素值在时间域上的拟合分布情况。运用高斯混合模型在wavingtrees上取得了较好的结果。
实验中运用的形态学操作一定程度上消除了被检测为前景的树,三通道在一定程度上消除了被误检测为背景的人的轮廓,使得人的轮廓更加的清晰。这都证明了实验中形态学操作与三通道运用的有效性。
但是从实验中也可以看出高斯混合模型对于这种动态背景还是不鲁棒的,仅仅是wavingtrees中背景中的树的轻微晃动,就会出现把树误检测为前景的情况,将前景中的人误检测为背景。这些情况在没有添加形态学操作与三通道的时候尤为明显。所以可以推断当背景发现较为明显的变化时,比如物体突然移动,光照突然变化。高斯混合模型都是无法适应这种变换的。
实验报告以及完成源码,数据集:https://download.csdn.net/download/breeze_blows/11975860
核心源代码:
import cv2
import numpy as np
import glob
GMM_MAX_COMPONT = 5
SIGMA = 30
gmm_thr_sumw = 0.6
train_num = 2
WEIGHT = 0.05
T = 0.7
alpha = 0.005
eps = pow(10, -10)
channel = 3
GMM_MAX_COMPONT = GMM_MAX_COMPONT
m_weight = [[] for i in range(GMM_MAX_COMPONT*channel)]#怎么先对numpy初始化为一维数组,后续在对每个元素重新复制为数组呢
m_mean = [[] for i in range(GMM_MAX_COMPONT*channel)]
m_sigma = [[] for i in range(GMM_MAX_COMPONT*channel)]
m_fit_num = None
def init(img):
row, col, channel = img.shape
global m_fit_num
for i in range(GMM_MAX_COMPONT*channel):
m_weight[i] = np.zeros((row, col), dtype='float32')
m_mean[i] = np.zeros((row, col), dtype='float32')
m_sigma[i] = np.ones((row, col), dtype='float32')
m_sigma[i] *= SIGMA
m_fit_num = np.zeros((row, col), dtype='int32')
def train_gmm(imgs):
row, col, channel = imgs.shape
B, G, R = cv2.split(imgs)
m_mask = np.zeros((row,col), dtype=np.uint8)
m_mask[:] = 255
for i in range(row):
for j in range(col):
cnt = 0
for c, img in enumerate((B,G,R)):
# img = imgs[:,:,c]
# img = B.copy()
num_fit = 0
for k in range(c*GMM_MAX_COMPONT, c*GMM_MAX_COMPONT+GMM_MAX_COMPONT):
if m_weight[k][i][j] != 0:
delta = abs(img[i][j]-m_mean[k][i][j])
if float(delta) < 2.5*m_sigma[k][i][j]:
m_weight[k][i][j] = (1-alpha)*m_weight[k][i][j] + alpha*1
m_mean[k][i][j] = (1-alpha)*m_mean[k][i][j] +alpha*img[i][j]
m_sigma[k][i][j] = np.sqrt((1-alpha)*m_sigma[k][i][j]*m_sigma[k][i][j]+alpha*(img[i][j]-m_mean[k][i][j])*(img[i][j]-m_mean[k][i][j]))
num_fit += 1
else:
m_weight[k][i][j] *= (1-alpha)
for ii in range(c*GMM_MAX_COMPONT, c*GMM_MAX_COMPONT+GMM_MAX_COMPONT):
for jj in range(ii + 1, c*GMM_MAX_COMPONT+GMM_MAX_COMPONT):
if (m_weight[ii][i][j] / m_sigma[ii][i][j]) <= (m_weight[jj][i][j] / m_sigma[jj][i][j]):
m_sigma[ii][i][j], m_sigma[jj][i][j] = m_sigma[jj][i][j], m_sigma[ii][i][j]
m_weight[ii][i][j], m_weight[jj][i][j] = m_weight[jj][i][j], m_weight[ii][i][j]
m_mean[ii][i][j], m_mean[jj][i][j] = m_mean[jj][i][j], m_mean[ii][i][j]
if num_fit == 0:
if 0==m_weight[c*GMM_MAX_COMPONT+GMM_MAX_COMPONT-1][i][j]:
for kk in range(c*GMM_MAX_COMPONT, c*GMM_MAX_COMPONT+GMM_MAX_COMPONT):
if (0 == m_weight[kk][i][j]):
m_weight[kk][i][j] = WEIGHT
m_mean[kk][i][j] = img[i][j]
m_sigma[kk][i][j] = SIGMA
break
else:
m_weight[c*GMM_MAX_COMPONT+GMM_MAX_COMPONT-1][i][j] = WEIGHT
m_mean[c*GMM_MAX_COMPONT+GMM_MAX_COMPONT-1][i][j] = img[i][j]
m_sigma[c*GMM_MAX_COMPONT+GMM_MAX_COMPONT-1][i][j] = SIGMA
weight_sum = 0
for nn in range(c*GMM_MAX_COMPONT, c*GMM_MAX_COMPONT+GMM_MAX_COMPONT):
if m_weight[nn][i][j] != 0:
weight_sum += m_weight[nn][i][j]
else:
break
weight_scale = 1.0/(weight_sum+eps)
weight_sum = 0
for nn in range(c*GMM_MAX_COMPONT, c*GMM_MAX_COMPONT+GMM_MAX_COMPONT):
if m_weight[nn][i][j] != 0:
m_weight[nn][i][j] *= weight_scale
weight_sum += m_weight[nn][i][j]
if abs(img[i][j] - m_mean[nn][i][j]) < 2 * m_sigma[nn][i][j]:
cnt += 1
break
if weight_sum > T:
if abs(img[i][j] - m_mean[nn][i][j]) < 2 * m_sigma[nn][i][j]:
cnt += 1
break
else:
break
if cnt == channel:
m_mask[i][j] = 0
# cv2.imshow('img_gray', img)
m_mask = cv2.medianBlur(m_mask, 7)
# kernel_e = np.ones((3, 3), np.uint8)
# m_mask = cv2.erode(m_mask, kernel_e)
kernel_d = np.ones((5, 5), np.uint8)
m_mask = cv2.dilate(m_mask, kernel_d)
# element = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3)) # 形态学去噪
# m_mask = cv2.morphologyEx(m_mask, cv2.MORPH_OPEN, element) # 开运算去噪
return m_mask
# cv2.imshow('img_mask', m_mask)
# cv2.waitKey(1)
def test_img(imgs):
row, col, channel = imgs.shape
B, G, R = cv2.split(imgs)
m_mask = np.zeros((row, col), dtype=np.uint8)
m_mask[:] = 255
for i in range(row):
for j in range(col):
cnt = 0
for c, img in enumerate((B, G, R)):
weight_sum = 0
for nn in range(c * GMM_MAX_COMPONT, c * GMM_MAX_COMPONT + GMM_MAX_COMPONT):
if m_weight[nn][i][j] != 0:
weight_sum += m_weight[nn][i][j]
if abs(img[i][j] - m_mean[nn][i][j]) < 2 * m_sigma[nn][i][j]:
cnt += 1
break
if weight_sum > T:
if abs(img[i][j] - m_mean[nn][i][j]) < 2 * m_sigma[nn][i][j]:
cnt += 1
break
else:
break
if cnt == channel:
m_mask[i][j] = 0
m_mask = cv2.medianBlur(m_mask, 7)
kernel_d = np.ones((5, 5), np.uint8)
m_mask = cv2.dilate(m_mask, kernel_d)
return m_mask
import time
if __name__ == '__main__':
data_dir = 'D:/images/'
file_list = glob.glob('D:/images/b*.bmp')
i = -1
for file in file_list:
# print(file)
i += 1
img = cv2.imread(file)
# img_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
if i == 0:
init(img)
if i <= 200:
t1 = time.time()
m_mask = train_gmm(img)
# cv2.imwrite("./rgb_morphologyEx3_MORPH_ELLIPSE/{}.jpg".format(i), m_mask)
t2 = time.time()
print(t2-t1)
if i == 286:
j = 0
for temp_file in file_list:
temp_img = cv2.imread(temp_file)
m_mask = test_img(temp_img)
cv2.imwrite("./rgb_mb7_dila5_train200/{:0>5d}.jpg".format(j), m_mask)
j += 1
参考:
https://blog.csdn.net/zouxy09/article/details/9622401
https://blog.csdn.net/lwx309025167/article/details/78513437#commentBox