【前沿】详细讲解Transformer新型神经网络在机器翻译中的应用
嘉宾 | 于恒
来源 | AI科技大本营在线公开课
编辑 | Jane
于恒:直播间的朋友大家好!欢迎大家来到本次AI科技大本营公开课,我是本次讲师于恒。
在讲课开始之前先简短的做个自我介绍,我是博士毕业于中国科学院计算技术研究所,方向是机器翻译的方向,目前在阿里巴巴翻译平台担任翻译模型组负责人,主要是为阿里巴巴的跨境电商贸易提供丰富的语言支持,让跨境贸易没有语言障碍。

今天非常高兴受到CSDN AI科技大本营的邀请,给大家分享自己在机器翻译方面的研究和工作。大家可以看到我PPT下面的几个 LOGO,我们翻译团队是属于阿里巴巴机器智能技术实验室,中间是阿里翻译的 Logo和我们的口号“Translate and Beyond”。
这次分享的题目是“Transformer新型神经网络在机器翻译中的应用”。
关注AI的同学最近应该会看到,机器翻译是一个比较活跃的领域,很多大公司都争先推出了自己的机器翻译服务,包括还有一些机器翻译的硬件已经在市场上投放,比如翻译笔。
产业的兴旺离不开背后技术的巨大进步,从今天的课程当中,我会给大家介绍背后技术的神秘面纱,然后对Transformer这个神经网络做深入的解析。

神经网络机器翻翻译是目前比较主流的机器翻译方法,它是“Sequence to Sequence”model,也就是端到端的翻译框架。如左图所示,我们输入一个待翻译的句子,通过神经网络编码器,去把这个句子的信息编码成中间状态,就是这个图中红色的部分,它用数值的隐层来表示。经过中间状态、经过神经网络解码器去生成对应的翻译,是编码、解码的过程。翻译的知识和参数都是由神经网络自动进行学习的,它省去了之前传统方法之前的人工干预模块,使整个翻译过程统一化,并且简洁。
随着深度学习发展带来的红利,这个翻译模型的性能有显著提升。如右图所示,这是谷歌翻译当时Release的数据,传统的是基于短语的翻译系统,翻译的性能远低于基于神经网络的翻译,就是那根绿色的线。并且神经网络的翻译在某些语项上是接近人类的水平。我们还可以注意到,在“英语到西语”、“英语到法语”,同样是拉丁语系的翻译上,神经网络的翻译和human的gap比较小,在“英语到汉语”这两者语言差异比较大的、翻译难度大的语种上gap比较大,所以神经网络仍然有比较大的进步空间。这是目前神经网络目前翻译的总体质量情况。

它背后的技术是怎样呢?从这个图可以大概看出来传统的基于RNN的“Sequece to Sequence”model是怎么运行的,这个例子是一个“英文到中文”的翻译,英文“Economicgrowth has slowed down in recent years”通过这个循环的RNN神经网络去逐词读入源端的句子,最终把它编码成红色那个点隐层的信息,根据这个隐层的信息输入到另外一个目标端的循环神经网络,然后逐词生成中文的翻译“近几年经济发展变慢了。”这里的是一个句子结束符的表示,生成的过程在句子末尾添加这样一个标志表示翻译过程结束了。
传统的RNN神经网络结构是可以处理任意长度的输入,它非常适合于自然语言的建模,所以它在一段时间内占据了整个神经网络中的主流。随着学术的发展,我们也会看到RNN有些不足,它的缺点主要有两点:第一点,RNN序列的特性导致其非常难以并行化,从上图可以看出,如果把RNN展开来是一个序列型的网络,比如我要得到X4的结果时,必须先计算出X0-X3的结果,这样的串行关系使它的并行度非常低。举一个例子,谷歌的GNMT的神经网络系统,它是需要96块GPU卡训练一周的时间才能完成一个模型的训练。96块GPU卡对于一个研究机构或者小公司来说是个巨大的开销,基本是负担不起的,并且还要训练一周的时间,所以RNN特性使整体模型训练速度非常慢、成本非常高。
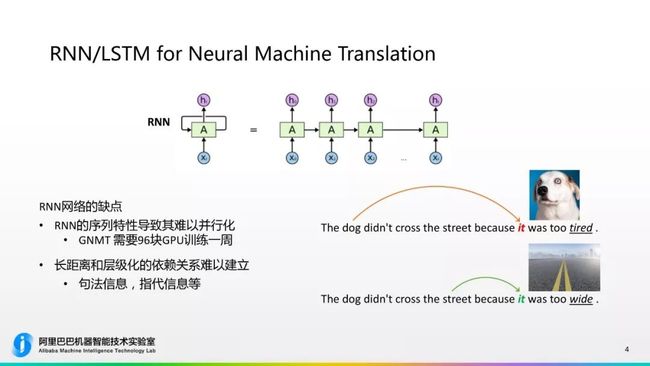
另外在RNN训练中,RNN的网络结构对于长距离和层级化的依赖关系难以建立,比如句法信息、指代信息的关系,由于它只是一个单一的序列 ,所以它很难对这些关系进行建模。举个例子,“The dog didn’t cross street because it wastoo tired”,当我们看到“tired”的时候知道这个it指dog 。如果把最后一个词换了,“The dog didn’t cross street because it was too wide”,这时候如果是人看了这句话就很容易发现it 指的是street,因为street because it was wide,不可能是dog too wide。对于人来说很简单,但是机器要分清楚指代关系是非常难的。如果将这个句子翻译成法文或者德文的话,法文、德文对于dog和street翻译所用的格是不一样的。所以在GNMT或者传统的翻译处理中,这些case时基本是做不对的,如果做对了可能也是蒙的,这是RNN一个比较显著的局限性。

基于以上RNN的缺陷,我们肯定希望有更好的神经网络去代替它。我们期望是这样的:第一,它是可以高度并行化的网络。RNN的特点导致我们要抛弃RNN的结构,实现速度成倍的提升。并且我们需要能够捕捉层次化的信息,就需要建立一个很深层的神经网络,而不是单层的一个序列的LSTM的网络。并且我们需要能够对指代信息丰富的上下文进行建模,这需要Self-Attention、Multi-head Attention这样的技术。左边这个演示的是Transformer整体的训练过程,在Encoding的部分简单可以看到,每个词是很并行化处理的过程。在Encoding之后Decoding是根据深层神经网络当中的输入不断逐词解码,最终生成翻译。
这引出我们今天讲座的主题,将会分四个部分对Transformer进行解析:
第一,对网络结构进行解析;
第二,对在机器翻译中的应用进行介绍;
第三,因为我是从阿里翻译过来的,所以我会从工业实践的角度对Transformer进行介绍。我们最近参加了WMT2018全球机器翻译评测,拿到了比较好的结果。
最后,从评测的结果对Transformer的表现进行分析。

▌一、对网络结构进行解析
Transformer这个网络命名,Transformer在英文翻译过来有变形金刚的意思,我想当时作者也是希望借助强大的变形金刚赋予这个网络更强的力量。
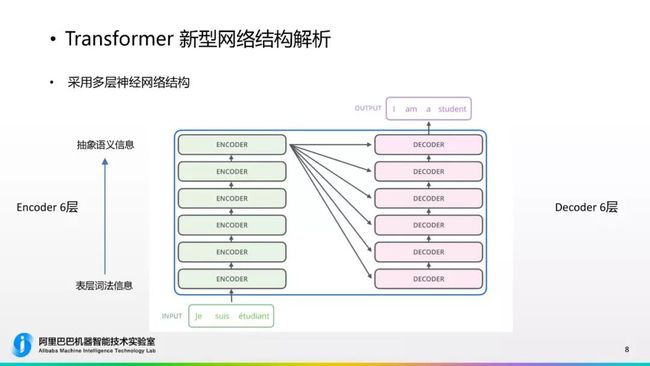
如果我们用放大镜高维度解析这个网络,拆开之后它仍然是“Sequence to Sequence”框架进行的,它分Encoder和Decoder两部分。我们再进一步细化的话,这个图包含很多信息。首先,我们看到Encoder有6层,Decoder也有6层,为什么要有多个层?从Encoder的角度,低层的Encoder是表层的词法信息,逐步向上进行抽象之后,在上层将表示抽象语义信息。Encoder部分还在最上层连了几条线到每个Encoder的部分,这就是刚才谈到Attention的部分,Decoder的网络中和Encoder也有信息传递和交互的。最后一个特点是Decoder和Encoder画的大小是一样的,因为它们层的维度大小是一样的。这个图表达了以上这些信息。
多层的神经网络结构能够对句子层级化信息进行建模,如果我们更精细的去看每一层的结构,就会发现这样的情况:Encode分两个子网络部分,第一个是Self-Attention,第二个部分是Feed Forward,大家比较熟悉,就是传统的前馈神经网络,我们摒弃了传统的并行化比较低,而且比较简单且高度并行化的前馈神经网络。
Self-Attention是自注意力机制层,表征句子当中不同位置词之间的关系,是我们前面提到的it和street 或dog之间的依赖关系。Decoder层比Encoder层多一个子网络,就是Encoder-Decoder Attention,它是源端到目标端的注意力机制,对源端词到目标端的助理机制,不是源端到目标端词的依赖关系,用到翻译里是说这个源端待翻译的词和源端生成翻译词之间的依赖关系。

我们如果进一步对Encoder部分进行细化,它长成这样。我们输入代翻译词是“Thinking Machines”,先会去查找这两个词分别表示成词向量的形式,再经过Self-Attention层得到Attention的输出,再经过Feed Forward自动生成Encoder1的输出,Encoder1的输出作为Encoder2的输入,这样以此类推,6层一直拼到上面去。在整个Encoder网络中,Feed Forward是大家比较熟悉的部分,但应该大多数观众的情况并不太了解Attention,因为它是神经网络机器翻译中提出的概念,在其他的网络这种概念并不常见。

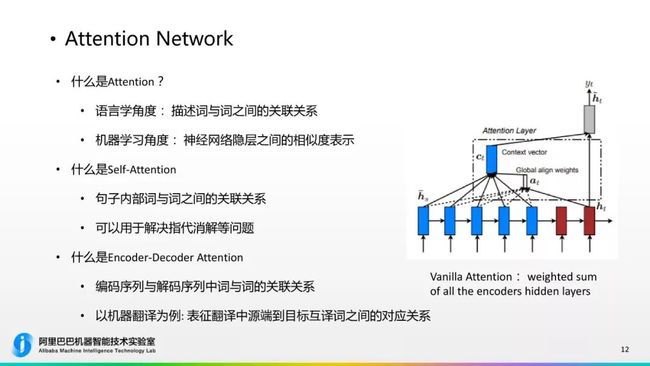
下面我们对Attention这个概念给大家进行进一步剖析,什么是Attention?从语言学的角度,它是表示词与词之间的关联关系,像下图所示,这是一个Self-Attention的示意,它这个it会和其他位置的词发生关系,颜色越深的是说关系越紧密,从中图中看到它很正确的关联到了animal它实际指代的一个词。

从机器学习的角度,这个Attention是神经网络隐层之间一个相似度的表示,什么是Self-Attention?就是表示句子内部词与词之间的关联关系,就像这里的it到animal,可以用于指代消解等问题。什么是“Encoder-DecoderAttention”?就是编码序列和解码中词与词的关联关系,以机器翻译为例,它是表征翻译中源端到目标端可能互译词之间的对应关系。这个也比较好理解,比如你在翻译一个词的时候,源端每个词的贡献度是不一样的,它表示这种不同的注意力的关系。传统的Attention,就是RNN、LSTM网络中也是有Attention的,但是Attention的计算方式是相对简单的,蓝色是编码器的序列,红色是解码器的序列,当解码器序列当中的一个隐层是Attention的时候,它会这个层与Encoder每个层之间的相似度,然后通过这个相似度作为位置对Encoder每一层进行加权,生成Ct,Ct就是整个Attention的输入。这是一个比较简单的Attention计算,但是它的表现能力是非常有限的。
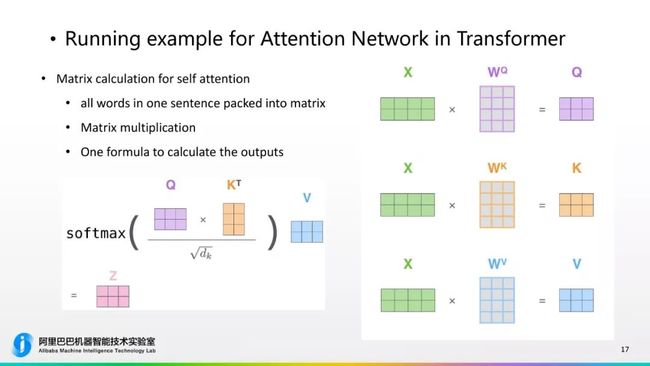
我们在Transformer中提出一种扩展性更高、并行度更高的Attention计算方式,它把Attention看作一个基于内容的查询的过程,content based query,它会设置3个vector:QueryVector、Key Vector、Value Vector。并且每一个Vector都是通过它的input embedding和权重的矩阵相乘得到的。我们利用这个Q、K、V进行各种数值的计算,最终得到Attentionscore。这个计算过程是相对复杂的。

我们用一个例子来给大家演示一下具体的Attention是怎么计算的。如果我们计算“Thinking”这个词,用Self-Attention的话,首先会用它的Query Vector乘以K的向量,如果计算和第二个位置的attention是乘以T2的矩阵得到一个score,这个score再去和它维度的平根根进行相除,这个相除有数学上的含义,能够使它回传的梯度更加稳定,除完后得到一个数值进行softmax,所有Attention都是正数并且相加之和等于1,这是从数学正确上考虑,并且最终得到概率这个值是去定义每一个词在当前位置的表现力。Softmax之后,我们会用softmax得到的乘以它Value的矩阵,这样实际得到Attention的值,最后会把不同位置得到Attention的score加到一起,形成当前位置Attention的Vector,就是Z1,加上逐词计算的话就得到所有位置的Attention。

刚才说到的是一个基于向量之间的运算,但是根据提到Transformer系统是一个高度并行化的系统,所以我们有一个很好的并行策略,就是基于将Vector计算变成基于矩阵的运算,因为我们在Encoder时所有的词都是并行计算,我们把所有词的词响亮拼在一起形成矩阵,用这个矩阵和它的Q、K、V的权重矩阵进行相乘,方便得到Q、K、V矩阵,Q、K、V矩阵用一个公式表示数值操作,就得到Attention的矩阵,这是一个高度并行化的操作,可以通过一步运算直接完成的,这个在GPU上很容易、速度很快。
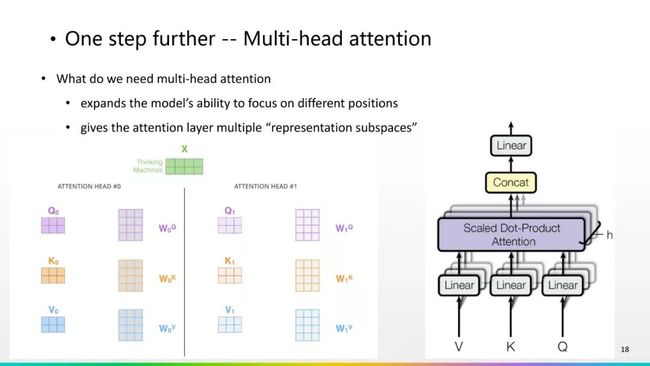
这是Attention的一种计算方法,我们对计算方法进行了拓展,提出了“Multi-head Attention”的方式,就是“多头”Attention,我们设置多个Q、K、V矩阵和它实际值的矩阵。它这样设计是有两种好处,第一种好处是它的可训练参数更多,能提升模型能力,去考虑到不同位置的Attention,另一个好处是对于这个Attention赋予了多个子空间。这个从机器学习的角度来说,首先参数变多了,拟合数据的能力变强了。从语言学是这样的,不同的子空间可以表示不一样的关联关系,比如一个子空间是表示指代的Attention,另一个子空间可以表示依存的Attention,另一个子空间表示其他句法信息的Attention,它能够综合表示各种各样的位置之间的关联关系,这样极大的提升了Attention的表现能力,这是传统的RNN、LSTM系统当中所不具备的,也是最终实验时会对性能有巨大影响的一个工作。
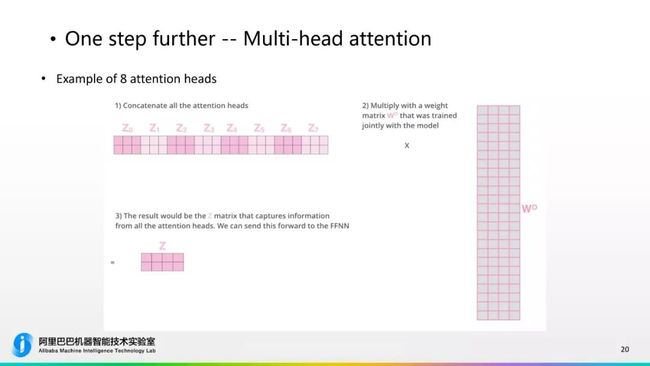
举个例子,比如我们有8个“Multi-headAttention”,输入一个“X”会计算出8个权重Attention输出的矩阵。那这8个矩阵怎么用呢?我们还需要把8个矩阵拼起来,然后用一个降维矩阵对它进行矩阵操作,把它压缩到一个我们能够相对接受的大小,对于信息进行压缩,这样可以避免后面矩阵操作维度过大导致整个开销比较大。所以它最终会压缩到一个比较小的维度。

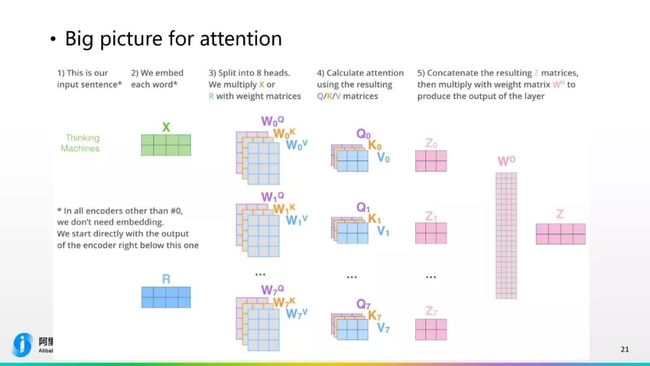
以上就是Transformer当中Attention机制的计算,从Big picture来看,它分几个部分:第一个部分是我们找到输入的句子,第二个部分去生成它的词向量的表示,并把它拼在一起,拼成matrices,这个matrices去和Q、K、V的权重矩阵进行数值运算,得到Q、K、V三个矩阵的数值,三个矩阵的数值通过之前的公式得到Multi-head Attention的值,Multi-head Attention拼在一起,通过一个降维矩阵,最终压缩到我们觉得比较合适的一个维度,来作为Attention子网络的输出。
以上是Attention的主要内容,当然,Transformer还有其他的网络,也可以给大家介绍一下。“Positional Encoding”是对于这个序列中每一个位置进行建模。
刚刚提到完全并行的矩阵操作时,大家可能会有一个疑问:这个不是一种指代模型吗?之间位置不考虑了,但不同位置在翻译中是很重要的关系,就是哪个词在哪个词前面,前后关系有非常大的意义。我们通过这个“Positional Encoding”去对位置进行建模。具体的时间、方法,我们对每一个词的embedding会加一个基于位置的embedding,S1会加一个T1,这个T1是和它的位置相关,位置就是编码第0个位置、第1个位置,依次打下去。这个T是根据这个公式计算的,这个公式是数学上选择比较好的一个公式,并且它和实际的Position是相关的。举个例子,如图所示,这个三个词的句子,每个位置的positionEncoding的数值大概是这样的,它通过这个数值加到原始的embedding上面,使这个embedding天然具有了它的位置的信息,在后面建模过程中我们会考虑每个词位置的信息。


另外一个是直连层网络“Residual connection”,了解的同学知道“Residual connection”是对于较为深层的神经网络有比较好的作用,比如网络层很深时,数值的传播随着weight不断的减弱,“Residual connection”是从输入的部分,就是图中虚线的部分,实际连到它输出层的部分,把输入的信息原封不动copy到输出的部分,减少信息的损失。“layer-normalization”这种归一化层是为了防止在某些层中由于某些位置过大或者过小导致数值过大或过小,对神经网络梯度回传时有训练的问题,保证训练的稳定性,这是神经网络设计当中两个比较常用的case,基本在每个子网络后面都要加上“layer-normalization”、加上“Residual connection”,加上这两个部分能够使深层神经网络训练更加顺利。这是另一个主要的细节。
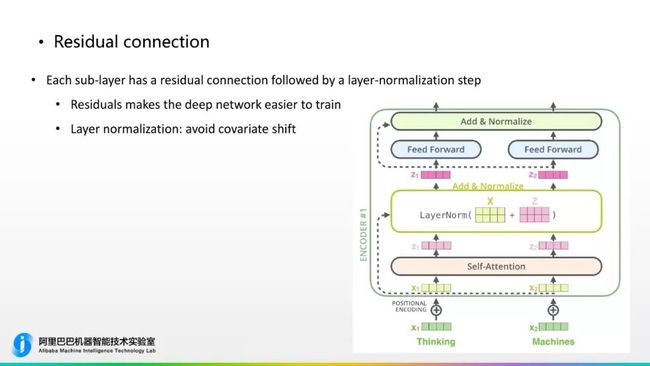
小结一下,刚才对神经网络做了比较详细的解释,它如下图所示,图里面画了两层的Encoder和Decoder,曾底层的词的输入到embedding的输入,X1、X2,加上“Positional Encoding”的输入,输入到第一个Encoder当中,经过self-Attention层,直连的“Residual connection”和归一化层,得到的输出再去输入到前馈神经网络中,前馈神经网络出来之后再经过直连层和归一化层,这样就完成了一个Encoder部分,再以这个输入到第二个Encoder之后,它会把第二个Encoder的输出作为第一个Decoder的输入,也是依次进行上面的过程。
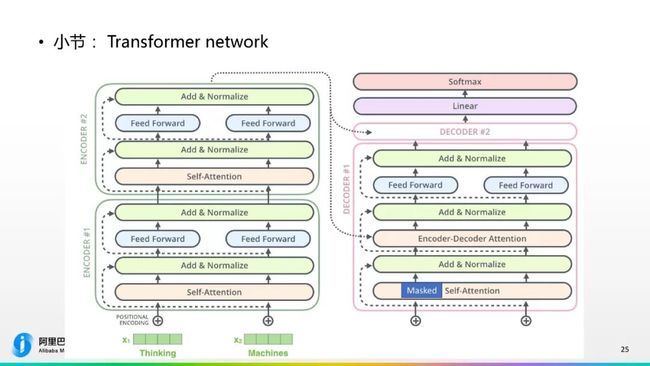
这个图中有一个细节需要大家注意,目标端的Attention注意力机制是一个masked注意力机制,为什么?比如在机器翻译当中,在源端能够看到所有的词,但如果你目标端生成翻译时是自左上右,生成翻译时能够看到前面已经生成词的信息,看不到后面层的,这是目标端Attention和源端Attention比较大的区别,所以在目标端所有的Attention都是加Masked的,这个Masked相当于把后面不该看到的信息屏蔽掉,这是Transformer network的小结。
▌二、基于Transformer的机器翻译系统

Transformer的网络是怎么用到机器翻译里的?Encoder端是源端的法语句子,目标端是英语的句子,随着时序的不断进行,每次生成一个词的翻译,最终它会生成一个
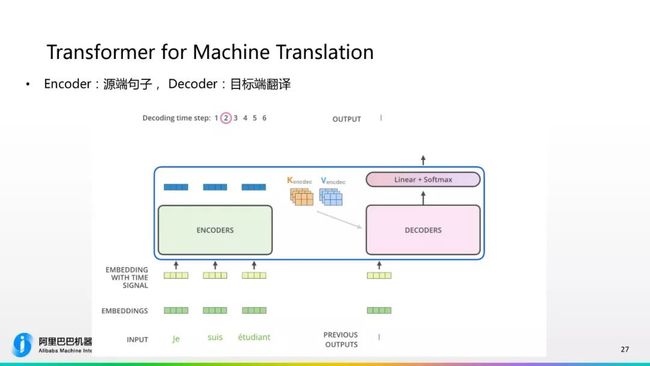
它是怎么生成每一个词的翻译呢?因为我们知道Decoder最上层的输入也是一个隐层,是2048或者1024的隐层。那么这个隐层是怎么对应到输出的那个词呢?后面的网络是这样的。首先,我们对每种语言会有一个固定的词表,比如这个语言到底有多少个词,比如中文里有2万词、3万词、5万词。对网络隐层会先过一个线性的投射层,去把它投射到一个词表大小的向量维度,形成一个词表大小向量,我们在这个向量基础上做softmax,把它转成概率。譬如是3万的词,去选取里面概率最大的那个词作为我们实际的输出,这里面第五位是最大的,它会输出一个am,这样就达到了通过Encoder输出隐层来去实际生成一个词翻译的效果。

另外一个部分是神经网络优化目标,在神经网络训练的过程中是需要平行语料的,所谓平行语料是源端和目标端都需要有。我们训练的目标是使神经网络生成这个翻译的概率分布尽量去贴合实际参考答案的概率分布。右边这个图我们希望它生成的概率分布,对于那个句子在第一个Position的时候希望i的概率是最大的,第二个希望am是最大的,以此类推。但这是训练好的,一开始训练时是随机处理化的概率分布,经过几千万句子的不断训练,会得到这样一个比较好的分布。

它的训练优化目标是概率的交叉熵cross entropy,以crossentropy作为梯度更新的优化目标。(上图)左边这个图优化目标的loss相当于它训练的轮数,因为是entropy,所以是稳定下降的过程。相应的,翻译的评价目标Bleu值是匹配度加权的分数,Bleu值越高越好,它随着训练过程的进行会有一个逐步向上升的过程。训练的优化目标就是这样的,通过交叉熵的优化来达到Bleu,就能翻译效果优化的过程。
我们看看Transformer的结果是什么样的,回到最开始的例子,用Trans网络对于句子的Attention进行了分析。得到了比较有意思的结果,(下图)左边这个句子,当最后一个词是too tired的时候,it所对应到的注意力机制最多的部分是animal,这是它对应到正确的部分,如果最后一个词是wide的时候它对到street是最多的。这样就非常有意思,Attention其实确实能够建模到比较难的指代消解问题,这也是比较好的,超越之前RNN和STLM的,就是Attention表示能力更强。
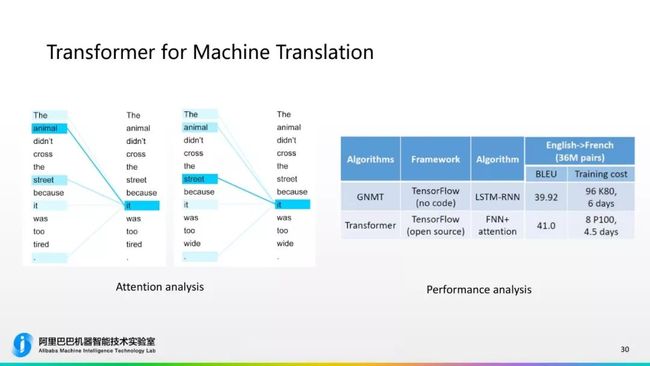
(上图)右边这个表是列出谷歌公布的数据,基于RNN的GNMT和Transformer的比较,在bleu值上Transformer有比较明显的提升,并且它在训练的时间上面只需要8块GPU卡,训练4.5天就可以达到一个比较好的模型,而传统的基于RNN需要90块GPU卡训练6天才,效果还不如Transformer的翻译系统。这相比原来的RNN有一个非常显著的提升,是目前工业界、学术界对于机器翻译来说最好的智能网络。
刚才对Transformer有了详尽的介绍,下面说一下Transformer在阿里翻译当中的表现。

▌三、Transformer在阿里翻译中的工业化实践
刚刚提到工业化实践,最大的一个问题是大数据,传统的实验室环境是几十万、几百万的语料,但对阿里这样大规模电商场景的机器翻译是需要很多语料的,需要上亿平行语料的训练,但对这么多平行语料用单GPU卡训练非常慢,基本是训不出来的。
第一个需要解决如何使用分布式训练,就是多机多卡的方式来去训练Transformer。但是Transformer的特点是对于训练超参数非常敏感的网络,我们当时尝试了各种各样的训练方法,试了异步梯度更新、同步梯度更新等不同的分布式训练策略。我们最终发现是基于同步的Adam,对于多机多卡是得到性能最稳定的一个更新方式。
这种方式在谷歌开源的那个Transformer系统和其他比较开源的Transformer系统中,大多数都是用这样的方式来进行多机多卡训练的。这个背后理论上也没有很好的解释为什么这个对于Transformer是更好的,主要是通过大量的实验去得到的一个结果,大家如果有多机多卡的训练需求,最好考虑基于同步梯度更新的Adam算法。

另外一个是跟机器翻译很相关的问题,通常GPU显存有固定的大小,比较差的卡是4个G、几个G,好的卡可能有12个G、24个G。对于Transformer而言,有些人做过实验,你如果训练时开更大Batch size,训练的效果会更好。这就带来一个问题,你如果想开大的Batch size的话,一个句子里面的长度就会很有限,因为你显存就那么大。假设长度设成40的话,那我Batch能开400或者500,如果我要开到800 Batch的话,能容纳的句子长度就会变小。这是一个搏弈的问题,因为硬件的限制导致你不得不做这个Tradeoff。
之前我们在TensorFlow低版本的时候都是不支持,只能用刚刚的方法。但是从tensorflow1.5以后,它引入了一个“Dynamic Batching”的机制,这是tensorflow的更新带来的变化,它会把原来写死的固定长度的图,用图中循环的方式表述,这样它可以支持动态的计算图,了解tensorflow的同学会比较清楚。通过用了这种机制之后,我们可以动态的改变这个batchsize,好处是当我们训练这个句长比较长的时候,就可以动态的把batch size缩小 。这样可以在训练的时候覆盖更长的句子,长的句子在翻译的案例中都有,比如电商描述或者新闻都有很长的句子,这样我们就能得到更多的训练语料,训练语料使用更加充分,对我们生产时性能得到很大的提升。
另外一个是“Moving average”机制,这个可能也是比较专业的一个说法,它能保证训练的稳定性。它主要的做法是,在训练比如5000个保持一个模型,中间模型有一个滑动的窗口,每次计算时会把窗口内所有的模型进行平均化。这个平均化有几个作用:第一个作用是可以避免脏数据带来的某个点梯度更新很差的情况,它每次都是多个模型去做平均化,这样模型更加稳定,另外,借助专家系统的机制,把多个模型的结果组合在一起,它得到的性能也会有一定的提升。需要指出的一点是,如果你训练当中用了这个策略,生成模型之后再用“Moving average”的时候性能是打折扣的,因为训练当中已经用了“Movingaverage”机制,把这部分的性能释放出来一些了。但总体上我们推荐使用“Moving average”机制,这样会使整个训练更加稳定。
提升模型鲁棒性的算法“Dropout”,这是机器学习或者神经网络中比较常见的机制,但是在真实场景中非常好用的一个机制。Dropout是在每层神经网络中随机屏蔽掉一些单元的神经输入,一般Droput是0.1,我们会屏蔽掉10%的输入,因为屏蔽掉10%的信息,模型需要学得更好,它的鲁棒性更加好。我们也做了相关的实验,黄色的线是基线系统,蓝色的线是Dropout,加入了Dropout时一开始模型训练得比较慢一些,但训练时间长了之后由于鲁棒性的提升,最后的曲线是会在那个之上的,最终收敛的性能也比那个更好。
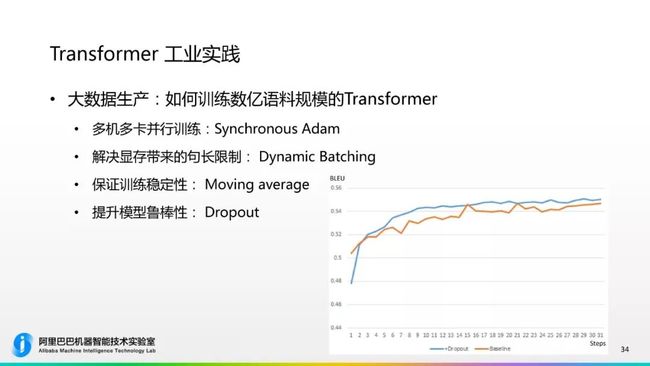
这是在训练过程中的一个小的改进,主要是我们在大数据生产时,如何训练数亿级别语料规模的Transformer的重要手段。
▌四、Transformer在WMT2018全球机器翻译评测中的表现
大家不知道这个评测或者对机器翻译不熟悉的话,我可以给大家介绍一下。这个评测是国际公认的顶级翻译赛事之一,也是各大科技公司与学术结构展示自身翻译实力的一个平台,2018年有很多霍普金斯大学、爱丁堡大学、亚琛工业大学、马里兰大学、微软、腾讯等很多机构参与,我们也取得了比较好的成绩。阿里巴巴翻译团队在WMT2018上“英文到中文”、“英文到俄罗斯语”、“英文到土耳其语”5个语项上获得了第一名的成绩,这个图也是最终比赛的冠军图。

从这个竞赛可以反映出一个特点,就是Transformer在2018年竞赛中已经获得非常普遍的认同,80%以上的系统都是采用Transformer,这是个非常惊喜的改变。在2017年WMT评测时大多数系统是基于RNN和LSTM的系统,包括最终获得冠军的系统也是基于这个的。仅仅过了一年时间,各大机构都争先使用的Transformer。这个是系统描述的图,参赛的几个系统当中大多数都有Transformer的关键词,还有一些其他一些基于RNN等系统是凤毛麟角的。所以Transformer网络在机器翻译领域已经受到广泛的认可。

这里给大家推荐几个比较好用的基于开源的机器翻译Transformer系统,在开源时代方便大家更好的学习,你有足够的语料,通过这些开源的机器翻译工具也可以搭建一个性能比较好的机器翻译引擎。主要推荐三个,第一个是Marian,是爱丁堡大学公开的开源工具,非常好用;第二个是 Nematus,也是爱丁堡大学开发的;第三个是 Sockeye,是亚马逊推出的机器翻译工具。感兴趣的同学可以去网上下载并使用这些工具去学习,看它里面的代码是如何实现的。
回到竞赛的部分,Transformer从竞赛的角度有哪些经验?我这里分享了几点,做评测跟做工程很不一样,评测是限定的数据级,在限定的数据级上达到极致的效果,我觉得有四点:

第一,精细的数据过滤和筛选,不会投入大量的精力用于基础语料集合确定,主办方会给你一个语料集合,但这个语料集合里有一些噪音或者不好的语料,怎么通过各种规则、分类模型选择或者基于n-gram过滤等等,去选择一个比较好的技术语料集合,这是花大力气做的,因为如果底层技术都不好的话,训练出来的上层建筑肯定是不行的。
第二,相信统计的力量。这是神经网络模型一个新的特点,成绩比较好的单位都训练很多模型,并且用很多策略训练不同的模型,最终用这些不同的模型去进行Ensemble learning或者进行组合,最终输出一个最好的系统。比如阿里可能会做100多个系统,采用Ensemble learning的方式。这也是成本越来越大的问题,为了达到更好的性能,我们需要介入更多GPU资源支持更多模型的训练,最后去达到这种微小几个点的性能提升。
第三,尽量用更多参数去合数据和领域,因为它的数据和领域都是很限定的,所以你需要去用更多的方法、更多的策略去拟合策略,比如Modelfine-tuning的策略,做微调的策略,你可以筛选更适合这个领域或者更拟合这个开发测试集的数据,去对你的model去进行fine-tuning。另外,还可以做global features去做Re-ranking,Re-ranking也是对性能有一定提升的点,你在翻译时可能只看到部分信息,但是当你的翻译都生成之后,可以提取更多双语的信息,去对开发集调一个更好的模型。
第四,尽可能用更多信息,因为主办方提供双语料的同时会提供大量的单语料,单语料可以有不同的方式,比如用Back-Translation的方式把它翻译回来,然后加入到你的模型里作为伪语料,伪的生成的双语语料加入到翻译系统里去训练,并且还可以去训练一个大规模的n-gram语言模型或者神经网络模型,最终加到Re-ranking模块里去调性能。
主要就这四点,其他的信息也期待WMT在后面Release出来的paper,我们会在文章里详细进行介绍。今天我们就结束了整个的介绍内容。
▌五、总结

Transformer新型神经网络的主要特点:
第一,并行化。并行化程度非常高。
第二,深度神经网络,可以表征层次化的信息。
第三,有复杂的Attention机制,可以表征指代消解或者各种不同词与词之间的依赖关系。
第四,性能非常好。
工业实践方面提出了:Synchronous Adam,Dynamic batching,Moving average,Dropout。四项比较实用的、值得尝试的方向。
竞赛经验方面:多模型ensemble,Fine-tuning,re-ranking,back-Translation这样一些竞赛比较适用的方法。也是从多维度给大家展现了Transformer的全貌。
▌六、对外思考和对目前Transformer问题的思考,我们还有哪些地方缺失了?

这是我参考微软刘教授的报告,我读完他的报告之后比较认同的几个观点:
第一个问题,我们在训练过程中提到优化目标是最大概率的优化目标,但是我们实际在去评价翻译质量时是用bleu去衡量的,这样等于优化目标和衡量的目标是不一致的,这样会带来一个显然的问题,就是优化目标和实际目标之间总是会存在差异的。给大家推荐两个可能的解决方案:第一个是MRT,ACL2015年提出的工作,把bleu值加入到神经网络优化目标方向之中。第二个是NAACL2018年的工作,利用GAN网络,用对抗网络的形式去对优化目标进行表示,这样也是能够使训练的优化目标和实际的评价目标能够一致的一种方式。
第二个问题,它还是需要大量的平行语料的数据,也就是标注数据。这个是对于一些小语种语言,比如东南亚的小语种平行语料是很稀缺的资源,如何对这些资源稀缺的语言搭建更好的翻译系统呢?目前有两个方向,一个是Unsupervised neural machineTranslation,这个做得比较好的是Facebook,目前走得比较远,它是利用完全非平行单语的语料去训练机器翻译系统,目前性能还不足够好,但它仍然在发展过程中。另外,微软也提出基于dual learning方法,也是通过非平行语料,通过dual learning的方式提升性能,也是一个比较值得尝试的工作。
第三个问题,它在生成翻译过程中是依赖知识搜索的。这个问题在于搜索是需要减值的,减值的标准是概率的大和小,但你在训练时是没有这个概念的,你的训练时是根本不会考虑到beam search的问题,但是在实际解码时对beam search模型是未知的,那在训练过程中如何把你搜索的过程也建模进去,这是一个比较好的方向。当时刘老师提到他想用AlphaGo基于reward计算的方式在模型训练的阶段去训练这个网络,你在每步beam search的时候它会给你计算一个reward,通过这个reward来进行减值,这样可以把训练和解码两者结合到一起,是个更好的解决方案。
第四个问题,由于Transformer它Attention的数据运算是比较复杂的,在生成翻译解码的阶段比较慢的,这是由于Attention的构造而导致的。这里给大家推荐的是基于AverageAttention Network(Zhang,ACL2018),它巧妙的改变了Attention的结构,最后可以很高效的计算出目标端的Attention,在性能不受损或受微小损失情况下有2-3倍的性能提升。未来期待更多能在Transformer上改进的工作,把神经网络推向更高的位置。
▌七、Q&A
以上是本次讲座的主要内容,现在是问答环节。
Q:为什么Conv Seq2Seq 不如Self-Attention?
A: Conv Seq2Seq是基于CNN的一个比较新的工作,是Facebook提出来的,这个众说纷纭,它在CNN上是比较好的,在性能上大家也都试过,大部分反馈不如谷歌提出的Self-Attention。从我个人观点来说,它在Attention计算上不然Transformer,所以它可能掺杂这个部分。
另外,Facebook没有投入更多人力去优化这个,而Transformer从一开始到后面迭代了很多版本,一开始性能可能不是那么好,但后来谷歌持续投入、维护、不断升级,从去年6月份提出开始一直到12份都有代码的更新 ,包括其他的像发电报大学也都跟踪这个方向,众人拾柴火焰高,大家不断投入这个领域,能够把这个越做越好。
Q:Transformer中三个地方用到的Attention能不能分开讲一讲每个地方的输入输出?
A: 这个是刚才给大家Miss掉的地方。回到之前的Attention计算方式的部分,看这个主要的图,是Encoder的部分用的是Self-Attention的部分,decoder用了Self-Attention和一个Decoder Attention,这确实是三个地方用到。第一个地方在Encoder端的输入是加了“Positional Encoding”的word embedding,直接输入到这个了Self-Attention里,输出是刚才提的的z矩阵,再输入到Feed Forward network里。
Decoder的部分也是一样,之前每次生成的词作为输入,然后加到PositionalEncoding之后输入到Self-Attention里,Encoder就是Self-Attention的输入。
Q:问了一个和阿里相关的:“阿里做电商描述训练的时候,如何解决领域内数据不足的问题”?
A:这是个比较具体的问题,首先,电商场景是阿里的一个重要场景,我们做电商时会收集一部分电商类的数据,阿里巴巴内部也有淘宝比较丰富的数据。有了这个以后会有基于n-gram或者基于分布式的筛选模块,基于这些之前互联网上收集到的大规模语料库中筛选相关的句子,得到充足的领域内的语料,领域内的训练语料应该越多越好。
Q:推荐一下深度学习、机器翻译方面的好书。
这个可以给大家推荐最近邓老师和清华大学刘老师合作发表的一部英文书,叫《Deep Learning in Natural Language Processing》,邓老师是语音识别方向的大牛,任老师是机器翻译、自然语言处理方面的大牛,这本书是2018年最新出版的,这本书会包含最新的机器翻译、神经网络内容,大家有兴趣的话可以考虑一下。
推荐阅读:
一大批历史精彩文章啦
