物体检测之FasterRCNN学习笔记
目标检测之FasterRCNN学习笔记
- 相关背景
-
- 涉及词汇
- RCNN Family发展历史
-
- RCNN
- FastRCNN
- FasterRCNN
-
- Proposal生成过程
-
- 锚点(Anchor)
- Region Proposal Network(RPN)
- ROI Pooling Layer
- 整体流程及容易混淆的地方
-
- 测试过程
- 训练过程
- 小结
相关背景
FasterRCNN是kaiming大神在RCNN, FastRCNN之后提出的一种新算法,在当时达到了检测领域SOTA的performance,如今已有超过18000次引用量,可以说是想要入门detection领域的同学必读的一篇文章。
本人在入门的时候看到的FasterRCNN解说大部分都囊括了所有的细节,包括IOU, NMS,BBOX regression算法等,看着看着会被绕晕,很少见到能把整个框架及流程解释的比较清楚的文章,我这次则想尝试,用简单易懂的语言,把整个pipeline从头到尾解释一遍,而不涉及太过细节的内容。
涉及词汇
因为主要是想把整个框架捋一遍,中间有些术语不想做太多解释,在这里粗略地介绍一下他们的意义和作用。
- IOU: Intersection Over Union,顾名思义,是用来衡量框与框之间的重叠程度,也就是相交面积除以总面积,越大说明两个框重叠程度越高。
- NMS: None Maximum Suppression, 从字面意思上理解,就是如果一个框跟真实框的重叠度不是最大的,我就要去抑制你。在检测过程中,最后输出的预测框有很多都是重叠的,这时候就要用NMS去过滤掉那些多余的框。
- Proposal:递给RCNN head的预测框,检测任务就是对这些框进行偏移和分类。这些proposal经过偏移和分类后就成了最终输出的结果。
- ROI: Region Of Interest,我的理解是跟proposal差不多,就是我们想去预测的区域。
- 正样本(pos),负样本(neg):等同于前景(fg),背景(bg),跟真实框重叠大于一个threshold(如0.7)的便是正样本,小于一个threshold(如0.3)的则是负样本
- Assigner:给框框们贴类别和回归量的标签,用来算loss,在后面会详细说到。
- Sampler:采样器,Sample一定数量的正负样本。在后面会详细说到。
RCNN Family发展历史
因为本文着重讲解FasterRCNN,对RCNN 和 FastRCNN不做过多赘述,解释的也可能不那么清楚,有兴趣了解的同学可以去看paper或者查阅其他资料。
RCNN
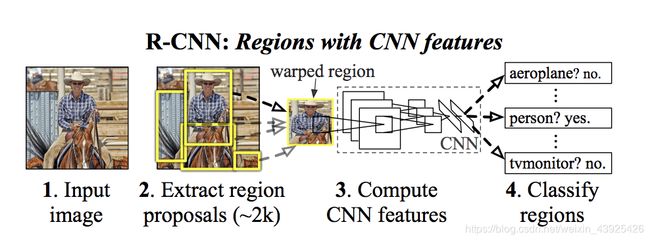
众所周知,检测任务就是在输入图片上框出图片里的物体,并对这些物体进行分类,那么RCNN是怎么得到这些框框的呢?作者提出用selective search的方法,在输入图片上先选出约2000个框框(这部分是无参操作,不能进行学习),我们称这些切割出来的图片区域为“proposal”,接下来将这些proposal输入卷积网络并获得图片特征,再通过SVM和BBOX regressor去进行分类和偏移。
很显然,这样做有很多弊端。
- 原本只有一张图片,被切割后变成2000多个小块,这些小块都要被输入网络,逐个进行分类和偏移,这样需要巨大计算量,毫无疑问是低效的。
- Selective search的方法并不能通过梯度回传进行学习。
FastRCNN

老牛仔又来了,同一张图片,不同的玩法,FastRCNN作者意识到了将原图片切割成proposal输入网络是比较低效的,于是他灵机一动,让一整张图片先通过卷积网络,得到图片的特征图(feature map)。注意,原图上的某一块区域,是可以通过用卷积网络每层的步长在特征图上找到与其相对应的一块区域的,我们称之为原图的映射。于是作者想到在输出特征图上做selective search, 再将得到的框框映射回原图,这样便只需要将图片过一次卷积网络,大大提升了效率。此外,作者也将RCNN用来分类的SVM替换成了全连接层+softmax分类。
FastRCNN解决了RCNN计算量过大的问题,然而仍然有不足的地方:
- FastRCNN在得到proposal时依然采用了selective search的算法, 这还是存在proposal生成过程中,梯度不可回传的问题
- 要注意的是,得到的proposal大小并不一样,而作者采用的解决方法是强行把proposal reshape成一个形状,这样明显是欠妥的,有些东西变了形,就不是那个东西了…
FasterRCNN
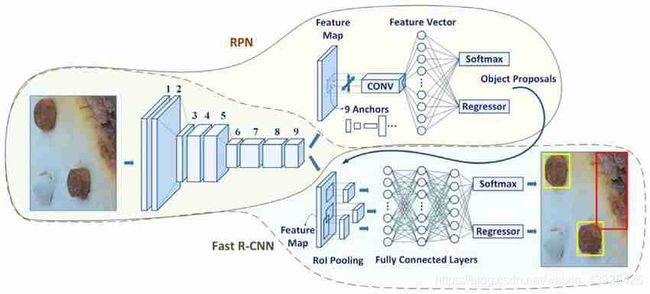
接下来就轮到我们今天的主角 FasterRCNN 了, 这样一篇神作,我不得不说paper里的图画的有点抽象,我当时也是看了好久才明白(其实想要真正明白还是得去看代码),所以在网上piao了一张图。FasterRCNN便是致力于解决RCNN和FastRCNN的一系列问题。咱来一一讨论。
Proposal生成过程
FasterRCNN最大的亮点便在于提出Region Proposal Network(RPN), 使网络可以通过学习,自动生成proposal。那么这又是怎么做到的呢?让我们来看看哈。
锚点(Anchor)

FasterRCNN提出锚点的方法来简化proposal的生成。所谓锚点(anchors),其实就是提前设定的一系列固定大小的框框,proposal则是RPN通过对anchor的矫正,再经过筛选得到的。Anchor是怎样生成的呢?在这里其实借鉴了FastRCNN的想法,featuremap上的每一个像素点都可以投射回原图,对应原图的一块区域,作者则在每个像素点上设定3种尺寸,3种边长比(一共3*3)的anchor,那这样一张featuremap则有HxWx3x3个anchor了。
Region Proposal Network(RPN)

接下来讲讲我们的RPN, 不瞒大家,我第一眼看到这个图是一脸懵逼的,这个到底再讲啥??其实很简单,只不过大佬图画的有点点抽象。
中间的feature map其实就是图片通过卷积网络得到的特征图(这里应该是取得最后一层,之后会提出用不同stage的featuremap生成proposal),而RPN则是由一层kernelsize为3x3的卷积层,加上两个kernelsize为1x1的卷积层构成的。3x3的conv是用来再融合一下featuremap的信息,而两个1x1的conv则分别负责预测分类得分和对anchor的偏移量。RPN处的分类其实是二分类任务,就是把所有anchor分成前景和背景(正样本和负样本),而偏移则是正常的bbox regression,对anchor进行偏移,使proposal更靠近真实的框。
RPN的两支1x1conv输出则分别是所有anchor的classification score和regression delta(偏移量)。假设有一张HxW的feature map输入RPN, 分类分支输出则是HxWx9x2的得分向量,9为每个像素上的anchor数,2则是类别数(前景和背景),而回归输出则是HxWx9x4的偏移向量,9维每个像素上的anchor数,4则是对anchor的修正(dx,dy,dw,dh)。
接下来,RPN会根据得分对anchor进行挑选,一般会选前景得分前topK的anchor,用delta对这些anchor进行偏移,然后再通过一步nms消除重叠面积较大的框,这些存活下来的优秀anchor会作为proposal递给rcnn head,再由head进行细分类和进一步矫正。
ROI Pooling Layer
还记得上面我们提到,之前解决proposal尺寸大小不一的问题,就是通过强行把proposal reshape成一个形状之后输入rcnn head, FasterRCNN则提出了一个更聪明的方法, 也就是ROI Pooling。
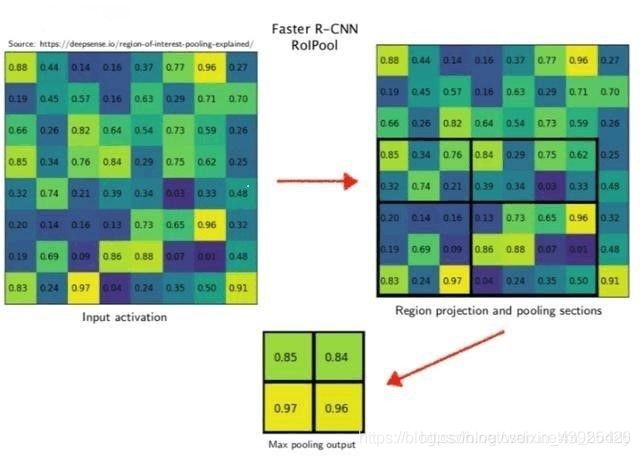
实际上这个操作很简单,就是把一个roi分成MxM的区域,再对每个区域做max pooling的操作,这样就能保证得到的roi feature大小一致,都是MxM的,maxpool也能保证得到的都是对应区域最显著的特征。文章中采用的是7x7的分割方法。
其实这个操作也有一定局限性,因为它的分割点必须是整数,这样其实会很大程度影响对小目标的识别。之后mask rcnn则提出了ROI align的方法, 采用的是双线性插值法,能够更精确地对featuremap 进行分割。在这里不过多讲解。
整体流程及容易混淆的地方
从别的文章中,大家也许会看到很多关于nms,sampler的东西,然而不是很清楚这些到底是在什么时候起作用的,对于训练过程和测试过程的具体区别也不是很明白,我这里就尝试帮大家疏通一下这些易混淆的知识点。
测试过程
因为测试过程比较简单,我们就先来拿下它。
FasterRCNN的测试整体流程pipeline:
- 图片进入网络,通过backbone的卷积网络,得到特征图(feature map)
- RPNHead对特征图进行操作,得到正负样本得分和估计偏移量
- RPNHead取正样本得分前K的anchorbox,用偏移估计量对它们进行修正,再通过NMS(non maximum suppression)操作,筛掉重合度较高的anchorbox,比较幸运活下来的,就成了接下来要用的proposal。
- 通过proposal取出的roi feature大小不一,所以需要用ROIpooling层对它们操作一波,得到固定大小的roi feature,再将他们递给RCNN head。
- RCNNhead拿到固定大小的roi feature,通过pooling操作将他们化成一长条儿,再通过两个全连接,分别输出每个proposal所有class的得分和矫正偏移量。
- Proposal根据偏移量被再次矫正,在通过NMS过滤掉重合度较高的box,终于得到最后的预测框和与之对应的分类预测。
细心的同学可能已经发现,RPNhead其实就是得到了比较粗糙的bbox,这里的分类一般只按正负样本分,意思就是只要你大概率框住了物体,我就把你留下。Anchors变成proposal已经经历了一次偏移。之后RCNNhead则是经历了二次偏移和class level的分类。
有些同学可能会问,那何必要经历两次偏移和分类呢?不能一次就做好吗?其实这种分类器是存在的。分类器分为一阶分类器和二阶分类器,FasterRCNN属于二阶分类器,包括之后的YOLO, RetinaNet,SSD 等等, 都属于一阶分类器。对于一阶分类器来说,他们就不存在proposal这个概念,是直接对featuremap上的全部像素点的全部anchor做一个细粒度的分类和偏移,一步到位。
然而这样效果也不见得会比二阶段好,我的理解是,分为两个阶段检测的话,学习难度对于RPN和RCNNhead都会一定程度上被降低, 有一个coarse grain-> fine grain的过程,精度上可能会稍占优势。通俗点说,我一步做不好的事情,分两步做可能会做的还不错。
训练过程
看完了上面的,也许你会问,那那些sampler, assigner是哪里用的呢?
首先,我们要清楚一点,ground truth label(数据标注)是只在训练阶段有的,测试阶段我们是不知道ground truth的,也就不存在assign label这一说(assign label就是对anchor或者proposal打标签)。
- 为啥要assign label呢?当然是要算loss,在RPN阶段,我们是对所有anchor进行分类和回归,每个anchor的ground truth则是:他们是不是包含了物体(正负样本)和他们回归到真实的框框需要的偏移量。在assign的过程中,所有的anchor要去找它对应的真实框,如果他们的重合度超过一个threshold(比如0.5),就算它和这个框overlap, 如果和多个真实框都有overlap,就选择IOU最大的那个框当作它对应的ground truth,而偏移量的label也是用这个框算的, 如果没有找到重合比这个threshold大的框,那这个anchor就是背景(负样本)。
- 为啥要sample呢?我们知道,一张图片有成千上万的anchor,然而能包含物体的正样本框也许只有几百个,甚至几十个,这里就牵扯到了正负样本不均衡的问题,如果负样本过多,在计算loss的时候,正样本起到的作用就会微乎其微,所以我们这里用了sample的方法,给定用来算loss的正负样本数量,让它们能起到equal contribution。
其实训练的图片前传过程跟测试是一模一样的,只不过要在两处地方算loss并且回传梯度,这里简单讲一下。下面所提到的pipeline参照测试阶段的即可。
- 在pipeline的第二步,拿到anchor的分类得分和偏移量估计后,用assigner去给每个anchor发标签,告诉他们,他们是正样本还是负样本,回归到跟自己重合最大的框需要多少修正。接下来,再用sampler根据anchor正负样本的label去进行采样,保证算loss的时候正负样本数目相对均衡。最后就可以用label跟预测值去算loss了,这里的loss有分类loss和偏移loss。注意,bbox偏移loss只有正样本才有(负样本没有对应的框,也就没有这个loss了)。
- 在pipeline的第五步,拿到proposal得分和偏移量估计后,通过跟上面一样的操作,再算一波loss。这波loss的不同点在于分类loss是针对所有类别的(比如coco,加上背景一共81类)。
注意:一共两处算loss的地方,RPN和RCNNhead,一共四个loss,两个分类loss跟两个回归loss,分类loss一个是二分类(前景背景),一个是多分类(所有物体类别加背景)
小结
这篇文章简单总结了一下本菜鸡自己学习FasterRCNN的时候遇到的一些疑惑和困难,可能对一些大佬来说,这些理解起来都没有任何难度。检测任务相对于分类任务还算是比较复杂繁琐,刚上手的时候是让我有一点不知所措,还好有大佬carry,反复看过几遍code之后也有了相对深入的理解,可能有些地方讲解的不是那么准确,也可能有些错误,也欢迎大家指出并与我讨论,本菜鸡在这里先谢过各位了。
个人认为,如果向更加深入的了解一个领域,还是需要去读原文,看代码,总能产生自己的理解,啃下来这个领域里面比较重要的几篇工作,之后的大多数研究就都是基于这些的修修补补了。
