DGL第一章(官方教程)个人笔记
DGL库很友好出了汉语教程地址就在这个地方,这里基本从那边粘贴过来,算作个人笔记。
第一章 图
DGL的核心数据结构DGLGraph提供了一个以图为中心的编程抽象。 DGLGraph提供了接口以处理图的结构、节点/边 的特征,以及使用这些组件可以执行的计算。
1.1 图的基本概念
了解基本概念,图、图的表示、加权图与未加权图、同构与异构图、多重图
1.2 图、节点和边
DGL用唯一整数表示节点,即点ID;对应的两个端点ID表示一条边。根据添加顺序每条边有边ID。DGL中边是有方向的,即边 ( u , v ) (u,v) (u,v)表示节点 u u u指向节点 v v v。
对于多节点,DGL使用一个一维整形张量(如,PyTorch的Tensor类)保持图的点ID,DGL称之为”节点张量”。对于多多条边,DGL使用一个包含2个节点张量的元组 ( U , V ) (U,V) (U,V) ,其中,用 ( U [ i ] , V [ i ] ) (U[i],V[i]) (U[i],V[i]) 指代一条 U [ i ] U[i] U[i] 到 V [ i ] V[i] V[i] 的边。
创建一个 DGLGraph 对象的一种方法是使用 dgl.graph() 函数。它接受一个边的集合作为输入。DGL也支持从其他的数据源来创建图对象。
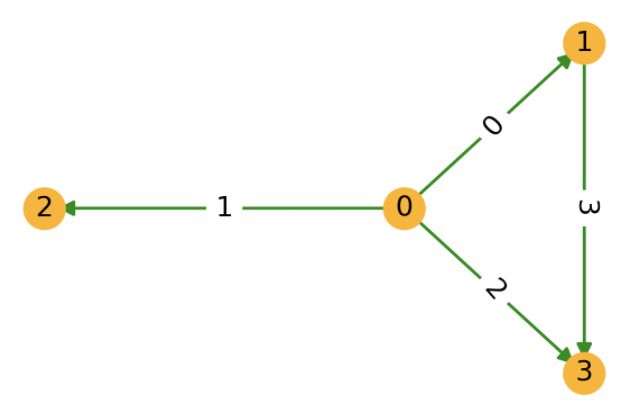
下面的代码段使用了 dgl.graph() 函数来构建一个 DGLGraph 对象,对应着下图所示的包含4个节点的图。 其中一些代码演示了查询图结构的部分API的使用方法。
import dgl
import torch as th
# 边 0->1, 0->2, 0->3, 1->3
u,v = th.tensor([0,0,0,1]), th.tensor([1,2,3,3])
g = dgl.graph((u,v))
print(g)
Using backend: pytorch
Graph(num_nodes=4, num_edges=4,
ndata_schemes={}
edata_schemes={})
# 获取节点
print(g.nodes())
tensor([0, 1, 2, 3])
# 获取边对应的点
print(g.edges())
(tensor([0, 0, 0, 1]), tensor([1, 2, 3, 3]))
# 获取边的对应端点和边ID
print(g.edges(form='all'))
(tensor([0, 0, 0, 1]), tensor([1, 2, 3, 3]), tensor([0, 1, 2, 3]))
# 如果具有最大ID的节点没有边,在创建图的时候,用户需要明确地指明节点的数量。
g = dgl.graph((u, v), num_nodes=8)
对于无向的图,用户需要为每条边都创建两个方向的边。可以使用 dgl.to_bidirected() 函数来实现这个目的。 如下面的代码段所示,这个函数可以把原图转换成一个包含反向边的图。
bg = dgl.to_bidirected(g)
bg.edges()
(tensor([0, 0, 0, 1, 1, 2, 3, 3]), tensor([1, 2, 3, 0, 3, 0, 0, 1]))
DGL可以用32或64位整数作为ID但类型要一致。下面是两种转换方法
edges = th.tensor([2, 5, 3]), th.tensor([3, 5, 0]) # 边:2->3, 5->5, 3->0
g64 = dgl.graph(edges) # DGL默认使用int64
print(g64.idtype)
torch.int64
g32 = dgl.graph(edges, idtype=th.int32) # 使用int32构建图
g32.idtype
torch.int32
g64_2 = g32.long() # 转换成int64
g64_2.idtype
torch.int64
g32_2 = g64.int() # 转换成int32
g32_2.idtype
torch.int32
1.3 节点和边的特征
DGLGraph对象的节点和边可具有多个用户定义的、可命名的特征,以储存图的节点和边的属性。
通过 ndata 和 edata 接口可访问这些特征。
例如,以下代码创建了2个节点特征(分别在第8、15行命名为 'x' 、 'y' )和1个边特征(在第9行命名为 'x' )。
import dgl
import torch as th
g = dgl.graph((th.tensor([0,0,1,5]), th.tensor([1,2,2,0]))) # 6个节点,四条边
# g = dgl.graph(([0, 0, 1, 5], [1, 2, 2, 0]))
g
Graph(num_nodes=6, num_edges=4,
ndata_schemes={}
edata_schemes={})
g.ndata['x'] = th.ones(g.num_nodes(), 3) # 长度为3的节点特征
g.edata['x'] = th.ones(g.num_edges(), dtype=th.int32) # # 标量整型特征
g
Graph(num_nodes=6, num_edges=4,
ndata_schemes={'x': Scheme(shape=(3,), dtype=torch.float32)}
edata_schemes={'x': Scheme(shape=(), dtype=torch.int32)})
# 不同名称的特征可以具有不同形状
g.ndata['y'] = th.randn(g.num_nodes(), 5) # x, y两种特征
g.ndata['x'][1] # 获取节点1的特征
tensor([1., 1., 1.])
g.edata['x'][th.tensor([0, 3])] # 获取边0和3的特征
tensor([1, 1], dtype=torch.int32)
关于 ndata 和 edata 接口的重要说明:
- 仅允许使用数值类型(如单精度浮点型、双精度浮点型和整型)的特征。这些特征可以是标量、向量或多维张量。
- 每个节点特征具有唯一名称,每个边特征也具有唯一名称。节点和边的特征可以具有相同的名称(如上述示例代码中的
'x') - 通过张量分配创建特征时,DGL会将特征赋给图中的每个节点和每条边。该张量的第一维必须与图中节点或边的数量一致。 不能将特征赋给图中节点或边的子集。
- 相同名称的特征必须具有相同的维度和数据类型。
- 特征张量使用”行优先”的原则,即每个行切片储存1个节点或1条边的特征(参考上述示例代码的第16和18行)。
对于加权图,用户可以将权重储存为一个边特征,如下。
# 边 0->1, 0->2, 0->3, 1->3
edges = th.tensor([0, 0, 0, 1]), th.tensor([1, 2, 3, 3])
weights = th.tensor([0.1, 0.6, 0.9, 0.7]) # 每条边的权重
g = dgl.graph(edges)
g.edata['w'] = weights # 将其命名为 'w'
g
Graph(num_nodes=4, num_edges=4,
ndata_schemes={}
edata_schemes={'w': Scheme(shape=(), dtype=torch.float32)})
edges
(tensor([0, 0, 0, 1]), tensor([1, 2, 3, 3]))
1.4 从外部源创建图
可以从外部来源构造一个 DGLGraph对象,包括:
- 从用于图和稀疏矩阵的外部Python库(NetworkX 和 SciPy)创建而来。
- 从磁盘加载图数据。
本节不涉及通过转换其他图来生成图的函数,相关概述请阅读API参考手册。
从外部库创建图
import dgl
import torch as th
import scipy.sparse as sp
spmat = sp.rand(100, 100, density=0.05) # 5%非零项 100*100 0.05非零项
dgl.from_scipy(spmat) # 来自SciPy
Graph(num_nodes=100, num_edges=500,
ndata_schemes={}
edata_schemes={})
import networkx as nx
nx_g = nx.path_graph(5) # 一条链路0-1-2-3-4
dgl.from_networkx(nx_g) # 来自NetworkX
Graph(num_nodes=5, num_edges=8,
ndata_schemes={}
edata_schemes={})
注意,当使用 nx.path_graph(5) 进行创建时, DGLGraph 对象有8条边,而非4条。 这是由于 nx.path_graph(5) 构建了一个无向的NetworkX图 networkx.Graph ,而 DGLGraph 的边总是有向的。 所以当将无向的NetworkX图转换为 DGLGraph 对象时,DGL会在内部将1条无向边转换为2条有向边。 使用有向的NetworkX图 networkx.DiGraph 可避免该行为。
nxg = nx.DiGraph([(2, 1), (1, 2), (2, 3), (0, 0)])
dgl.from_networkx(nxg)
Graph(num_nodes=4, num_edges=4,
ndata_schemes={}
edata_schemes={})
从磁盘加载
逗号分隔值(CSV)
CSV是一种常见的格式,以表格格式储存节点、边及其特征:
nodes.csv
| age, title |
|---|
| 43, 1 |
| 23, 3 |
| … |
edges.csv
| src, dst, weight |
|---|
| 0, 1, 0.4 |
| 0, 3, 0.9 |
| … |
许多知名Python库(如Pandas)可以将该类型数据加载到python对象(如 numpy.ndarray)中, 进而使用这些对象来构建DGLGraph对象。如果后端框架也提供了从磁盘中保存或加载张量的工具(如 torch.save(), torch.load()),可以遵循相同的原理来构建图。
JSON/GML 格式
如果对速度不太关注的话,读者可以使用NetworkX提供的工具来解析 各种数据格式, DGL可以间接地从这些来源创建图。
DGL 二进制格式
DGL提供了API以从磁盘中加载或向磁盘里保存二进制格式的图。除了图结构,API也能处理特征数据和图级别的标签数据。 DGL也支持直接从S3/HDFS中加载或向S3/HDFS保存图。参考手册提供了该用法的更多细节。
1.5 异构图
相比同构图,异构图里可以有不同类型的节点和边。这些不同类型的节点和边具有独立的ID空间和特征。 例如在下图中,”用户”和”游戏”节点的ID都是从0开始的,而且两种节点具有不同的特征。

一个异构图示例。该图具有两种类型的节点(“用户”和”游戏”)和两种类型的边(“关注”和”玩”)。
在DGL中,一个异构图由一系列子图构成,一个子图对应一种关系。每个关系由一个字符串三元组 定义 (源节点类型, 边类型, 目标节点类型) 。由于这里的关系定义消除了边类型的歧义,DGL称它们为规范边类型。
下面的代码是一个在DGL中创建异构图的示例。
import dgl
import torch as th
# 创建一个具有三种节点类型和三种边类型的异构图
graph_data = {
('drug', 'interacts', 'drug'): (th.tensor([0, 1]), th.tensor([1, 2])),
('drug', 'interacts', 'gene'): (th.tensor([0, 1]), th.tensor([2, 3])),
('drug', 'treats', 'disease'): (th.tensor([1]), th.tensor([2]))
}
g = dgl.heterograph(graph_data)
print("g.ntypes:", g.ntypes)
print("g.etypes:", g.etypes)
print("g.canonical_etypes:", g.canonical_etypes)
g.ntypes: ['disease', 'drug', 'gene']
g.etypes: ['interacts', 'interacts', 'treats']
g.canonical_etypes: [('drug', 'interacts', 'drug'), ('drug', 'interacts', 'gene'), ('drug', 'treats', 'disease')]
注意,同构图和二分图只是一种特殊的异构图,它们只包括一种关系。
# 一个同构图
dgl.heterograph({('node_type', 'edge_type', 'node_type'): (u, v)})
# 一个二分图
dgl.heterograph({('source_type', 'edge_type', 'destination_type'): (u, v)})
Graph(num_nodes={'destination_type': 4, 'source_type': 2},
num_edges={('source_type', 'edge_type', 'destination_type'): 4},
metagraph=[('source_type', 'destination_type', 'edge_type')])
与异构图相关联的 metagraph 就是图的模式。它指定节点集和节点之间的边的类型约束。 metagraph 中的一个节点 u u u 对应于相关异构图中的一个节点类型。 metagraph 中的边 (u,v) 表示在相关异构图中存在从 u u u 型节点到 v v v 型节点的边。
g
Graph(num_nodes={'disease': 3, 'drug': 3, 'gene': 4},
num_edges={('drug', 'interacts', 'drug'): 2, ('drug', 'interacts', 'gene'): 2, ('drug', 'treats', 'disease'): 1},
metagraph=[('drug', 'drug', 'interacts'), ('drug', 'gene', 'interacts'), ('drug', 'disease', 'treats')])
g.metagraph().edges()
OutMultiEdgeDataView([('drug', 'drug'), ('drug', 'gene'), ('drug', 'disease')])
g.metagraph().nodes()
NodeView(('drug', 'gene', 'disease'))
使用多种类型
当引入多种节点和边类型后,用户在调用DGLGraph API以获取特定类型的信息时,需要指定具体的节点和边类型。此外,不同类型的节点和边具有单独的ID。
# 获取图中所有节点的数量
print("g.num_nodes():", g.num_nodes())
# 获取drug节点的数量
print("g.num_nodes('drug'):", g.num_nodes('drug'))
# 不同类型的节点有单独的ID。因此,没有指定节点类型就没有明确的返回值。
# g.nodes()
# DGLError: Node type name must be specified if there are more than one node types.
print("g.nodes('drug'):", g.nodes('drug'))
g.num_nodes(): 10
g.num_nodes('drug'): 3
g.nodes('drug'): tensor([0, 1, 2])
为了设置/获取特定节点和边类型的特征,DGL提供了两种新类型的语法: g.nodes[‘node_type’].data[‘feat_name’] 和 g.edges[‘edge_type’].data[‘feat_name’] 。
# 设置/获取"drug"类型的节点的"hv"特征
g.nodes['drug'].data['hv'] = th.ones(3, 1)
g.nodes['drug'].data['hv']
tensor([[1.],
[1.],
[1.]])
# 设置/获取"treats"类型的边的"he"特征
g.edges['treats'].data['he'] = th.zeros(1, 1)
g.edges['treats'].data['he']
tensor([[0.]])
如果图里只有一种节点或边类型,则不需要指定节点或边的类型。
g = dgl.heterograph({
('drug', 'interacts', 'drug'): (th.tensor([0, 1]), th.tensor([1, 2])),
('drug', 'is similar', 'drug'): (th.tensor([0, 1]), th.tensor([2, 3]))
})
g.nodes()
tensor([0, 1, 2, 3])
# 设置/获取单一类型的节点或边特征,不必使用新的语法
g.ndata['hv'] = th.ones(4, 1)
g.ndata['hv']
tensor([[1.],
[1.],
[1.],
[1.]])
从磁盘加载异构图
逗号分隔值(CSV)
一种存储异构图的常见方法是在不同的CSV文件中存储不同类型的节点和边。下面是一个例子.
数据文件夹
data/
|-- drug.csv # drug节点
|-- gene.csv # gene节点
|-- disease.csv # disease节点
|-- drug-interact-drug.csv # drug-drug相互作用边
|-- drug-interact-gene.csv # drug-gene相互作用边
|-- drug-treat-disease.csv # drug-disease治疗边
与同构图的情况类似,用户可以使用像Pandas这样的包先将CSV文件解析为numpy数组或框架张量,再构建一个关系字典,并用它构造一个异构图。 这种方法也适用于其他流行的文件格式,比如GML或JSON。
DGL二进制格式
DGL提供了 dgl.save_graphs() 和 dgl.load_graphs() 函数,分别用于以二进制格式保存异构图和加载它们。
边类型子图
用户可以通过指定要保留的关系来创建异构图的子图,相关的特征也会被拷贝。
g = dgl.heterograph({
('drug', 'interacts', 'drug'): (th.tensor([0, 1]), th.tensor([1, 2])),
('drug', 'interacts', 'gene'): (th.tensor([0, 1]), th.tensor([2, 3])),
('drug', 'treats', 'disease'): (th.tensor([1]), th.tensor([2]))
})
g.nodes['drug'].data['hv'] = th.ones(3, 1)
# 保留关系 ('drug', 'interacts', 'drug') 和 ('drug', 'treats', 'disease') 。
# 'drug' 和 'disease' 类型的节点也会被保留
eg = dgl.edge_type_subgraph(g,[('drug', 'interacts', 'drug'),
('drug', 'treats', 'disease')])
eg
Graph(num_nodes={'disease': 3, 'drug': 3},
num_edges={('drug', 'interacts', 'drug'): 2, ('drug', 'treats', 'disease'): 1},
metagraph=[('drug', 'drug', 'interacts'), ('drug', 'disease', 'treats')])
eg.nodes['drug'].data['hv']
tensor([[1.],
[1.],
[1.]])
dgl.edge_type_subgraph(g, [('drug', 'interacts', 'gene')])
Graph(num_nodes={'drug': 3, 'gene': 4},
num_edges={('drug', 'interacts', 'gene'): 2},
metagraph=[('drug', 'gene', 'interacts')])
将异构图转化为同构图
异构图为管理不同类型的节点和边及其相关特征提供了一个清晰的接口。这在以下情况下尤其有用:
- 不同类型的节点和边的特征具有不同的数据类型或大小。
- 用户希望对不同类型的节点和边应用不同的操作。
如果上述情况不适用,并且用户不希望在建模中区分节点和边的类型,则DGL允许使用 dgl.DGLGraph.to_homogeneous() API将异构图转换为同构图。 具体行为如下:
g = dgl.heterograph({
('drug', 'interacts', 'drug'): (th.tensor([0, 1]), th.tensor([1, 2])),
('drug', 'treats', 'disease'): (th.tensor([1]), th.tensor([2]))})
g.nodes['drug'].data['hv'] = th.zeros(3, 1)
g.nodes['disease'].data['hv'] = th.ones(3, 1)
g.edges['interacts'].data['he'] = th.zeros(2, 1)
g.edges['treats'].data['he'] = th.zeros(1, 2)
# 默认情况下不进行特征合并
hg = dgl.to_homogeneous(g)
'hv' in hg.ndata
False
hg
Graph(num_nodes=6, num_edges=3,
ndata_schemes={'_ID': Scheme(shape=(), dtype=torch.int64), '_TYPE': Scheme(shape=(), dtype=torch.int64)}
edata_schemes={'_ID': Scheme(shape=(), dtype=torch.int64), '_TYPE': Scheme(shape=(), dtype=torch.int64)})
# 拷贝边的特征
# 对于要拷贝的特征,DGL假定不同类型的节点或边的需要合并的特征具有相同的大小和数据类型
g = dgl.to_homogeneous(g, edata=['he']) # 没有相同特征形状
# DGLError: Cannot concatenate column ‘he’ with shape Scheme(shape=(2,), dtype=torch.float32) and shape Scheme(shape=(1,), dtype=torch.float32)
# 拷贝节点特征
hg = dgl.to_homogeneous(g, ndata=['hv'])
hg.ndata['hv']
tensor([[1.],
[1.],
[1.],
[0.],
[0.],
[0.]])
原始的节点或边的类型和对应的ID被存储在ndata和edata中。
# 异构图中节点类型的顺序
g.ntypes
['disease', 'drug']
# 原始节点类型
hg.ndata[dgl.NTYPE]
tensor([0, 0, 0, 1, 1, 1])
# 原始的特定类型节点ID
hg.ndata[dgl.NID]
tensor([0, 1, 2, 0, 1, 2])
# 异构图中边类型的顺序
g.etypes
['interacts', 'treats']
# 原始边类型
hg.edata[dgl.ETYPE]
tensor([0, 0, 1])
# 原始的特定类型边ID
hg.edata[dgl.EID]
tensor([0, 1, 0])
出于建模的目的,用户可能需要将一些关系合并,并对它们应用相同的操作。为了实现这一目的,可以先抽取异构图的边类型子图,然后将该子图转换为同构图
g = dgl.heterograph({
('drug', 'interacts', 'drug'): (th.tensor([0, 1]), th.tensor([1, 2])),
('drug', 'interacts', 'gene'): (th.tensor([0, 1]), th.tensor([2, 3])),
('drug', 'treats', 'disease'): (th.tensor([1]), th.tensor([2]))
})
sub_g = dgl.edge_type_subgraph(g, [('drug', 'interacts', 'drug'),
('drug', 'interacts', 'gene')])
h_sub_g = dgl.to_homogeneous(sub_g)
h_sub_g
Graph(num_nodes=7, num_edges=4,
ndata_schemes={'_ID': Scheme(shape=(), dtype=torch.int64), '_TYPE': Scheme(shape=(), dtype=torch.int64)}
edata_schemes={'_ID': Scheme(shape=(), dtype=torch.int64), '_TYPE': Scheme(shape=(), dtype=torch.int64)})
1.6 在GPU上使用DGLGraph
用户可以通过在构造过程中传入两个GPU张量来创建GPU上的 DGLGraph 。 另一种方法是使用 to() API将 DGLGraph 复制到GPU,这会将图结构和特征数据都拷贝到指定的设备。
import dgl
import torch as th
u, v = th.tensor([0, 1, 2]), th.tensor([2, 3, 4])
g = dgl.graph((u, v))
g.ndata['x'] = th.rand(5, 3)
g.device
device(type='cpu')
cuda_g = g.to('cuda:0') # 接受来自后端框架上的任何设备对象
cuda_g.device
device(type='cuda', index=0)
cuda_g.ndata['x'].device # 特征数据也拷贝到GPU上
device(type='cuda', index=0)
# 由GPU张量构造的图也在GPU上
u, v = u.to('cuda:0'), v.to('cuda:0')
g = dgl.graph((u, v))
g.device
device(type='cuda', index=0)
任何涉及GPU图的操作都是在GPU上运行的。因此,这要求所有张量参数都已经放在GPU上,其结果(图或张量)也将在GPU上。 此外,GPU图只接受GPU上的特征数据。
cuda_g.in_degrees() # 入度
tensor([0, 0, 1, 1, 1], device='cuda:0')
cuda_g.in_edges([2, 3, 4]) # 可以接受非张量类型的参数
(tensor([0, 1, 2], device='cuda:0'), tensor([2, 3, 4], device='cuda:0'))
cuda_g.in_edges(th.tensor([2, 3, 4]).to('cuda:0')) # 张量类型的参数必须在GPU上
(tensor([0, 1, 2], device='cuda:0'), tensor([2, 3, 4], device='cuda:0'))
cuda_g.ndata['h'] = th.randn(5, 4)
# Cannot assign node feature "h" on device cpu to a graph on device cuda:0. Call DGLGraph.to() to copy the graph to the same device.