NLP第四范式:Prompt概述【Pre-train,Prompt(提示),Predict】【刘鹏飞】
一、概述
1、prompt的含义
prompt顾名思义就是“提示”的意思,应该有人玩过你画我猜这个游戏吧,对方根据一个词语画一幅画,我们来猜他画的是什么,因为有太多灵魂画手了,画风清奇,或者你们没有心有灵犀,根本就不好猜啊!这时候屏幕上会出现一些提示词比如3个字,水果,那岂不是好猜一点了嘛,毕竟3个字的水果也不多呀。看到了吧,这就是prompt的魅力,让我们心有灵犀一点通!(我不太会画哈,大家想象一下就行啦,嘿嘿嘿~~~)
2、摘要
论文以一种新的自然语言处理范式,称为“prompt-based learning”。
- 与传统的监督学习不同,传统的监督学习训练模型接收输入 x \boldsymbol{x} x ,并将输出y预测为 P ( y ∣ x ) P(\boldsymbol{y} \mid \boldsymbol{x}) P(y∣x)。
- 基于prompt的学习是直接建模文本概率的语言模型。为了使用这些模型执行预测任务,使用模板将原始输入 x \boldsymbol{x} x 修改为具有一些未填充槽的文本字符串提示 x ′ \boldsymbol{x}^{\prime} x′ ,然后使用语言模型概率填充 未填充信息 以获得最终字符串 x ^ \hat{\boldsymbol{x}} x^ ,从中可以导出最终输出 y \boldsymbol{y} y 。
该框架功能强大且具有吸引力,原因有很多:
- 它允许语言模型在大量原始文本上进行预训练;
- 并且通过定义新的提示函数,该模型能够执行few-shot甚至zero-shot学习,以适应标记数据很少或没有数据的新场景;
3、NLP的几次重大变化
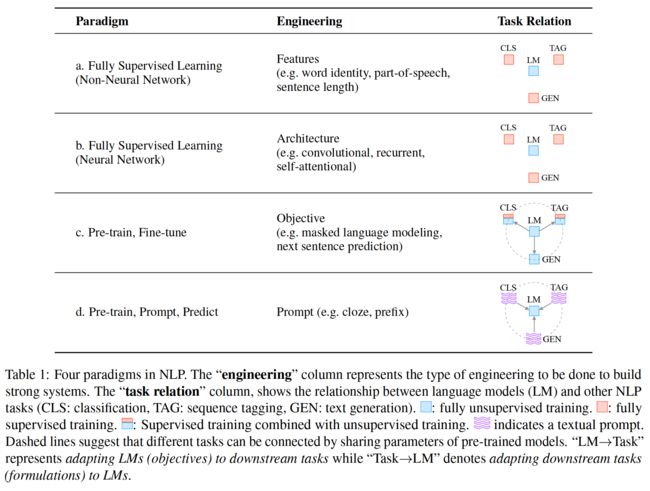
3.1 范式一:非神经网络时代的完全监督学习(特征工程)
完全监督学习,即任务特定模型仅在目标任务的输入-输出示例数据集上训练,长期以来在许多机器学习任务中发挥着核心作用,自然语言处理(NLP)也不例外。
由于这种完全监督的数据集不足以学习高质量的模型,早期NLP模型严重依赖于特征工程,NLP研究人员或工程师利用其领域知识从原始数据中定义和提取显著特征,并为模型提供适当的归纳偏差,以从这些有限的数据中学习。
3.2 范式二:基于神经网络的完全监督学习(架构工程)
随着NLP神经网络模型的出现,在对模型本身进行训练的同时,学习了显著的特征,因此重点转移到 结构工程,其中,通过设计有助于学习此类特征的合适网络架构来提供感应偏差。
3.3 范式三:预训练,精调范式(目标工程)
然而,从2017-2019年,NLP模型的学习发生了巨大变化,这种完全监督的范式现在发挥着越来越小的作用。具体而言,标准转向了预训练和微调范式(表1 c)。在此范式中,具有固定体系结构的模型被预先训练为语言模型(LM),预测观察到的文本数据的概率。
由于训练LMs所需的原始文本数据非常丰富,因此可以在大型数据集上训练这些LMs,学习建模语言的健壮通用特性。然后,通过引入额外的参数并使用特定于任务的目标函数对其进行微调,使上述预先训练的LM适应不同的下游任务。在这一范式中,重点主要转向目标工程,设计训练前和微调阶段使用的训练目标。例如,Zhang等人(2020a)表明,引入从文档中预测显著句子的损失函数将为文本摘要提供更好的预训练模型。
值得注意的是,预先训练的LM的主体通常经过微调,以使其更适合解决下游任务。
3.4 范式四:预训练,提示,预测范式(Prompt工程)
截至2021撰写该论文时,我们正处于第二次大变革的中间,“pre-train, fine-tune”程序被我们称为“pre-train, prompt, and predict”的程序所取代。在这种范式中,
- 不是通过目标工程使预先训练的LMs适应下游任务;
- 而是在文本提示的帮助下重新制定下游任务,使其看起来更像原始LM训练期间解决的任务;
例如:
- 当识别社交媒体帖子的情绪时,“我今天没赶上公共汽车。”,我们可以继续提示“我感觉到__”,并要求LM用一个带感情的词来填补空白。
- 或者,如果我们选择提示“英语:我今天没赶上公共汽车。法语:__”,LM可能可以用法语翻译来填补空白。
通过这种方式,通过选择适当的提示,我们可以操纵模型行为,以便预先训练的LM本身可以用于预测所需的输出,有时甚至不需要任何额外的特定任务训练。
- 这种方法的优点是,在给出一套适当提示的情况下,以完全无监督的方式训练的单个LM可用于解决大量任务。
- 然而,有一个陷阱:这种方法引入了即时工程的必要性,即找到最合适的提示,以允许LM解决手头的任务。
表1:NLP中的四种范式。“Task Relation”列显示了语言模型(LM)和其他NLP任务(CLS:分类、标记:序列标记、GEN:文本生成)之间的关系。虚线表示可以通过共享预训练模型的参数来连接不同的任务。“LM→Task”表示使LMs(目标)适应下游任务,而“Task”→LM”表示将下游任务调整到LMs。
二、对提示(Prompting)的正式描述
1、NLP中的监督学习
在传统的NLP监督学习系统中,获取输入 x \boldsymbol{x} x ,通常是文本,并基于模型 P ( y ∣ x ; θ ) P(\boldsymbol{y} \mid \boldsymbol{x} ; \theta) P(y∣x;θ) 预测输出 y \boldsymbol{y} y 。 y \boldsymbol{y} y 可以是标签、文本或其他各种输出。为了学习该模型的参数θ,使用包含输入和输出对的数据集,并训练一个模型来预测该条件概率。例如:
- 首先,文本分类采用输入文本 x \boldsymbol{x} x ,并从固定标签集 Y \mathcal{Y} Y 预测标签 y \boldsymbol{y} y 。举个例子,情感分析输入x=“我喜欢这部电影。”并预测标签y=++(标签集y={++、+、~、-、–})。
- 其次,条件文本生成采用输入 x \boldsymbol{x} x 并生成另一个文本 y \boldsymbol{y} y 。机器翻译就是一个例子,其中输入是一种语言的文本,例如芬兰语 x \boldsymbol{x} x=“Hyv ̈ a ̈ a huomenta.“输出为英语 y \boldsymbol{y} y =“Good morning.”。
2、提示(Prompting)
监督学习的主要问题是,为了训练模型 P ( y ∣ x ; θ ) P(\boldsymbol{y} \mid \boldsymbol{x} ; \theta) P(y∣x;θ) ,有必要为任务提供监督数据,而对于许多任务,这些数据是无法大量找到的。
NLP基于提示(Prompt)的学习方法试图通过学习建模文本 x \boldsymbol{x} x 自身概率 P ( x ; θ ) P(\boldsymbol{x} ; \theta) P(x;θ) 的LM,并使用该概率预测 y y y,从而避免或减少对大型有监督数据集的需求,从而绕过这一问题。
在本节中,论文对最基本的prompting形式进行了数学描述,其中包括许多关于prompting的工作,还可以扩展到其他工作。具体而言,提示(prompting)在三个步骤中预测得分最高的 y ^ \hat{\boldsymbol{y}} y^ 。
2.1 添加提示(Prompting)
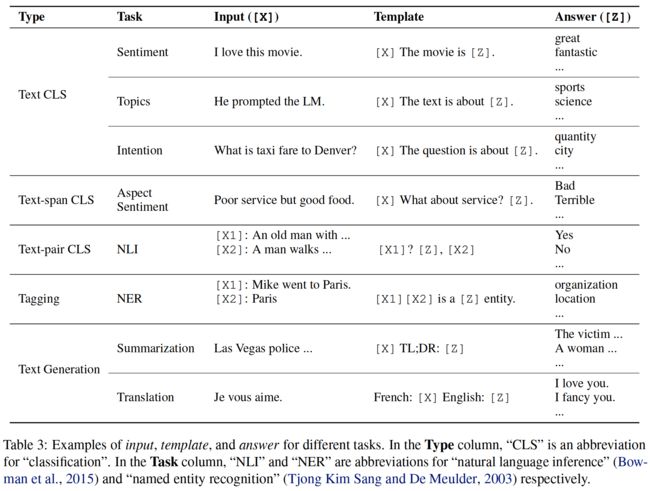
在此步骤中,应用提示函数 f prompt ( ⋅ ) f_{\text {prompt }}(\cdot) fprompt (⋅) 将输入文本 x \boldsymbol{x} x 修改为提示 x ′ = f prompt ( x ) \boldsymbol{x}^{\prime}=f_{\text {prompt }}(\boldsymbol{x}) x′=fprompt (x) 。包括两个步骤:
- 应用一个模板,这是一个文本字符串,有两个槽:一个输入槽 [X] 用于输入 X,另一个答案槽 [Z] 用于中间生成的答案文本 Z,该答案文本 Z 稍后将映射到 y \boldsymbol{y} y 。
- 用输入文本 x \boldsymbol{x} x 填充槽[X]。
在情感分析中, x \boldsymbol{x} x=“我喜欢这部电影。”,模板的形式可能是“[X]总体而言,这是一部[Z]电影”。然后,x′会变成“我喜欢这部电影。总的来说,这是一部[Z]电影。”给出了前面的示例。
在机器翻译的情况下,模板可以采用“Finnish:[X]English:[Z]”等形式,其中输入和答案的文本与指示语言的标题连接在一起。
表3有更多示例。
值得注意的是:
- 上面的提示(prompt)将在提示的 中间 或 末尾 为 z \boldsymbol{z} z 填充一个空槽。在下面的文本中,将第一种类型的提示称为完形填空提示(cloze prompt,),而第二种类型的提示称为前缀提示(prefix prompt),其中输入文本完全位于 z \boldsymbol{z} z 之前。
- 在许多情况下,这些模板词不一定由自然语言标记组成;它们可以是虚拟词(例如,由数字ID表示),稍后会嵌入到连续空间中,一些提示方法甚至会直接生成连续向量。
- [X]槽的数量和[Z]槽的数量可以根据手头任务的需要灵活更改。
2.2 答案搜索
接下来,搜索得分最高的文本 z ^ \hat{\boldsymbol{z}} z^ ,以最大化LM的得分。
我们首先将 Z 定义为 z \boldsymbol{z} z 的一组允许值。对于生成型任务, Z \mathcal{Z} Z 可以是整个语言的范围,或者在分类的情况下, Z \mathcal{Z} Z 可以是语言中单词的一小部分,例如定义 Z \mathcal{Z} Z ={“优秀”、“好”、“好”、“坏”、“可怕”},以表示 Y \mathcal{Y} Y ={++、+、~、-、–}中的每个类。
表2:提示(prompting)方法的术语和符号

然后,定义一个函数 f fill ( x ′ , z ) f_{\text {fill }}\left(\boldsymbol{x}^{\prime}, \boldsymbol{z}\right) ffill (x′,z) ,用可能的答案 z \boldsymbol{z} z 填充提示 x ′ \boldsymbol{x}^{\prime} x′ 中的位置 [Z]。我们将调用经过此过程的任何提示(prompt)作为填充提示(prompt)。特别是,如果提示中填写的是真实答案,将其称为已回答提示(answered prompt)(表2显示了一个示例)。最后,我们通过使用预先训练的LM P ( ⋅ ; θ ) P(\cdot ; \theta) P(⋅;θ) 计算相应填充提示的概率来搜索潜在答案集 z \boldsymbol{z} z 。
z ^ = search z ∈ Z P ( f fill ( x ′ , z ) ; θ ) \hat{\boldsymbol{z}}=\operatorname{search}_{\boldsymbol{z} \in \mathcal{Z}} P\left(f_{\text {fill }}\left(\boldsymbol{x}^{\prime}, \boldsymbol{z}\right) ; \theta\right) z^=searchz∈ZP(ffill (x′,z);θ)
此搜索函数可以是搜索得分最高的输出的argmax搜索,也可以是根据LM的概率分布随机生成输出的采样。
2.3 答案映射
最后,想从得分最高的答案 z ^ \hat{\boldsymbol{z}} z^ 到得分最高的输出 y ^ \hat{\boldsymbol{y}} y^ 。在某些情况下,这很简单,因为答案本身就是输出(如在语言生成任务中,如翻译),但在其他情况下,多个答案可能会导致相同的输出。例如,可以使用多个不同的情感词(例如“优秀”、“神话般”、“美妙”)来表示单个类别(例如“+”),在这种情况下,有必要在搜索的答案和输出值之间进行映射。
3、提示(Prompting)的设计注意事项
现在,我们已经有了基本的数学公式,我们将阐述一些基本的设计考虑因素,这些考虑因素将进入提示(prompting)方法,我们将在以下部分中详细阐述:
图1:提示(prompting)方法的类型

3.1 预训练模型选择
预训练模型选择:有多种预训练LMs可用于计算 P ( x ; θ ) P(\boldsymbol{x} ; \theta) P(x;θ)。在图1 §3中,介绍了预先训练的LMs,特别是对于解释其在提示(prompting)方法中的效用非常重要的维度。
3.2 提示设计(Prompt Engineering)
提示设计(Prompt Engineering):如果提示(prompt)指定了任务,那么选择合适的提示不仅对准确性有很大影响,而且对模型首先执行的任务也有很大影响。在图1 §4中,讨论了选择应使用哪个提示作为 f prompt ( x ) f_{\text {prompt }}(\boldsymbol{x}) fprompt (x) 的方法。
3.3 回答设计
回答设计:根据任务的不同,我们可能希望设计不同的 Z \mathcal{Z} Z,可能还有映射功能。在图1 §5中,讨论了不同的方法。
3.4 扩展范式
扩展范式:如上所述,上述方程式仅代表了为实现这种prompting而提出的各种底层框架中最简单的一种。在图1 §6中,论文讨论了扩展这一基本范式的方法,以进一步改进结果或适用性。
3.5 基于提示(prompt)的训练策略
基于提示(prompt)的训练策略:也有训练参数的方法,可以是提示、LM或两者兼有。在图1 §7中,论文总结了不同的策略,并详细介绍了它们的相对优势。
三、预训练的语言模型
鉴于预训练LMs在预训练和微调范式中对NLP产生的巨大影响。论文将从主要训练目标、文本噪声类型、辅助训练目标、注意力掩码、典型架构和首选应用场景等方面对其进行详细介绍。
1、训练目标
预训练LM的主要训练目标几乎总是由预测文本 x \boldsymbol{x} x 概率的某种目标组成。
标准语言模型(SLM)的目标正是这样做的,训练模型以优化训练语料库中文本的概率 P ( x ) P(\boldsymbol{x}) P(x) 。在这些情况下,文本通常以自回归的方式进行预测,一次一个地预测序列中的标记。这通常是从左到右进行的(如下所述),但也可以按其他顺序进行。
标准LM目标的一个流行替代方案是去噪目标,该目标将一些去噪函数 x ~ = f noise ( x ) \tilde{\boldsymbol{x}}=f_{\text {noise }}(\boldsymbol{x}) x~=fnoise (x) 应用于输入句子,然后在给出带噪文本 P ( x ∣ x ~ ) P(\boldsymbol{x} \mid \tilde{\boldsymbol{x}}) P(x∣x~) 的情况下,尝试预测原始输入句子。这些目标有两种常见的风格:
- 受损文本重建(CTR)这些目标通过仅计算输入句子中有噪声部分的损失,将处理后的文本恢复到其未受损状态。
- 全文重构(FTR)这些目标通过计算整个输入文本的损失来重构文本,无论输入文本是否有噪声。
预训练的LMs的主要训练目标在确定其对特定提示任务的适用性方面起着重要作用。例如:
- 从左到右的自回归LMs可能特别适合前缀提示(prefix prompts),
- 而重建目标可能更适合完形填空提示(cloze prompts)。
此外,使用标准LM和FTR目标训练的模型可能更适合文本生成任务,而其他任务(如分类)可以使用使用任何这些目标训练的模型来制定。
2、噪声类型
表4:不同噪声操作的详细示例

在基于重建的训练目标中,用于获取带噪文本 x ~ \tilde{\boldsymbol{x}} x~ 的特定类型的损坏会影响学习算法的效果。此外,可以通过控制噪声类型来整合先验知识,例如,噪声可以集中在句子的实体上,这允许我们学习对实体具有特别高预测性能的预训练模型。论文介绍几种类型的增加噪声方式,并在表4中给出详细示例。
- 掩码(Masking),文本将在不同的级别上掩码遮罩,用一个特殊的token(如[MASK]替换一个token或多个tokens片段。值得注意的是,掩码可以是来自某些分布的随机掩码,也可以是专门设计用于引入先验知识的掩码,例如上述掩码实体的示例,以鼓励模型擅长预测实体。
- 替换(Replacement) 替换与掩码相似,不同之处在于token或multi-token span不是用[MASK]替换,而是用另一个token或信息片段。
- 删除(Deletion) token或multi-token 片段将从文本中删除,而无需添加[MASK]或任何其他token。此操作通常与FTR loss一起使用。
- 排列(Permutation) 首先将文本分为不同的片段(tokens、次句子片段或句子),然后将这些片段排列成新的文本。
3、表示的方向性
在理解预训练LMs及其差异时,应考虑的最后一个重要因素是表示计算的方向性。通常,有两种广泛使用的方法来计算此类表示:
- 从左到右(Left-to-Right),每个单词的表示都是根据单词本身和句子中之前的所有单词计算的。例如,如果我们有一个句子“这是一部好电影”,那么“好”一词的表示将根据前面的单词进行计算。在计算标准LM目标或计算FTR目标的输出端时,这种因式分解尤其广泛使用。
- 双向(Bidirectional),基于句子中的所有单词(包括当前单词左侧的单词)计算每个单词的表示形式。在上面的例子中,“好”会受到句子中所有单词的影响,甚至下面的“电影”。
除了上述两个最常见的方向外,还可以将这两种策略混合在一个模型中,或以随机排列的顺序对表示进行调节,尽管这些策略的使用不太广泛。值得注意的是,当在神经模型中实施这些策略时,这种调节通常通过注意力掩码来实现,它遮罩了注意力模型中的值,例如流行的Transformer架构(Vaswani et al.,2017)。图2显示了此类注意掩码的一些示例。
图2:三种流行的注意力掩码模式,其中下标t表示第t个时间步。(i,j)处的阴影框表示允许注意力机制在输出时间步骤j关注输入元素i。白色框表示不允许注意力机制关注相应的i和j组合。

4、典型的预训练方法
这里介绍了四种流行的预训练方法,它们来自目标、噪声函数和方向性的不同组合。
下面对其进行了描述,并在图3和表5中进行了总结。
图3:预训练 LMs的典型范例
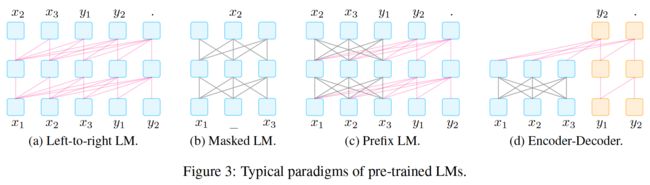
表5:预训练LMs的典型架构。x和y分别表示要编码和解码的文本。SLM:标准语言模型。CTR:损坏的文本重建。FTR:全文重建。†:编码器解码器体系结构通常只对解码器应用目标函数。

4.1 从左到右的语言模型
从左到右LMs(L2R LMs)是一种自回归LM,预测即将出现的单词,或为单词序列 x = x 1 , ⋯ , x n \boldsymbol{x}=x_{1}, \cdots, x_{n} x=x1,⋯,xn 分配概率 P ( x ) P(\boldsymbol{x}) P(x) 。通常使用从左到右的链式规则来分解概率: P ( x ) = P ( x 1 ) × ⋯ P ( x n ∣ x 1 ⋯ x n − 1 ) P(\boldsymbol{x})=P\left(x_{1}\right) \times \cdots P\left(x_{n} \mid x_{1} \cdots x_{n-1}\right) P(x)=P(x1)×⋯P(xn∣x1⋯xn−1) 。从左到右的LMs包括 GPT-3 和 GPT-Neo 等。
4.2 掩码语言模型
虽然自回归语言模型为文本的概率建模提供了一个强大的工具,但它们也有缺点,例如要求从左到右计算表示。当重点转移到为下游任务(如分类)生成最佳表示时,许多其他选项成为可能,并且通常更可取。在表征学习中广泛使用的一种流行的双向目标函数是掩码语言模型(MLM;Devlin et al.(2019)),该模型旨在根据包围的上下文预测掩码文本片段。例如, P ( x i ∣ x 1 , … , x i − 1 , x i + 1 , … , x n ) P\left(x_{i} \mid x_{1}, \ldots, x_{i-1}, x_{i+1}, \ldots, x_{n}\right) P(xi∣x1,…,xi−1,xi+1,…,xn) 表示给定周围上下文的单词 x i x_i xi 的概率。
使用MLM的代表性预训练模型包括:BERT(Devlin等人,2019)、ERNIE(Zhang等人,2019;Sun等人,2019b)和许多变体。
在提示方法中,MLM通常最适合于自然语言理解或分析任务(例如,文本分类、自然语言推理和抽取式问答)。这些任务通常相对容易被重新表述为完形填空问题,这与传统的训练目标是一致的。此外,在探索将prompt与微调相结合的方法时,MLMs是一种经过预训练的选择模型。
4.3 前缀和编码解码器
对于条件文本生成任务,如翻译和摘要,其中输入文本 x = x 1 , ⋯ , x n \boldsymbol{x}=x_{1}, \cdots, x_{n} x=x1,⋯,xn 是给定的,目标是生成目标文本 y \boldsymbol{y} y ,我们需要一个预训练的模型,该模型既能对输入文本进行编码,又能生成输出文本。为此,有两种流行的体系结构共享一个共同的线程:(1)使用带完全连接掩码的编码器首先对源 x \boldsymbol{x} x 进行编码,然后(2)对目标 y \boldsymbol{y} y 进行自回归解码(从左到右)。
- 前缀语言模型,前缀LM是一个从左到右的LM,以前缀序列 x \boldsymbol{x} x 为条件对 y \boldsymbol{y} y 进行解码,该序列由相同的模型参数编码,但具有完全连接的掩码。值得注意的是,为了鼓励前缀LM学习更好的输入表示,除了 y \boldsymbol{y} y上的标准条件语言建模目标外,通常在 x \boldsymbol{x} x上应用损坏的文本重建目标。
- 编码器-解码器,编码器-解码器模型是一种使用从左到右LM解码的模型,条件 y \boldsymbol{y} y 是文本 x \boldsymbol{x} x 的单独编码器具有完全连接的掩码;编码器和解码器的参数不共享。与前缀LM类似,可以对输入 x \boldsymbol{x} x 应用不同类型的噪声。
UniLM 1-2(Dong et al.,2019;Bao et al.,2020)和ERNIE-M(Ouyang et al.,2020)中使用了前缀LMs,而编码器-解码器模型广泛用于预训练模型,如T5(Raffel et al.,2020)、BART(Lewis et al.,2020a)、MASS(Song et al.,2019)及其变体。
带有前缀LMs和编解码器范例的预训练模型可以自然地用于文本生成任务,使用输入文本进行promting(Dou等人,2021)或不进行promting(Yuan等人,2021a;Liu和Liu,2021)。
然而,最近的研究表明,其他非生成任务,如信息提取(Cui et al.,2021)、问答(Khashabi et al.,2020)和文本生成评估(Yuan et al.,2021b),可以通过提供适当的提示来重新表述生成问题。
因此,promting方法
- 拓宽了这些面向生成的预训练模型的适用性。例如,像BART这样的预训练模型在NER中使用较少,而promting方法使BART适用,
- 打破了不同任务之间统一建模的困难(Khashabi et al.,2020)。
四、提示(Prompt)设计
提示设计(Prompt engineering)是创建提示函数 f prompt ( x ) f_{\text {prompt }}(\boldsymbol{x}) fprompt (x) 的过程,该函数可在下游任务中产生最有效的性能。
在以前的许多工作中,这涉及到prompt模板设计,即人工或算法为模型预期执行的每个任务搜索最佳模板。如图1的“Prompt Engineering”部分所示,必须首先考虑prompt shape,然后决定是手动还是自动创建所需类型的prompt,如下所述。
1、提示类型(Prompt shape)
如上所述,提示有两种主要类型:完形填空prompt(Petroni et al.,2019;Cui et al.,2021),用于填充文本字符串的空白;前缀prompt(Li和Liang,2021;Lester et al.,2021),用于延续字符串前缀。选择哪一个取决于任务和用于解决任务的模型。通常,对于与生成相关的任务,或使用标准自回归LM解决的任务,前缀提示往往更有用,因为它们与模型的从左到右的特性很好地匹配。对于使用掩码LMs解决的任务,完形填空提示非常适合,因为它们与训练前任务的形式非常匹配。全文重构模型更通用,可以与完形填空或前缀提示一起使用。最后,对于一些涉及多个输入的任务,如文本对分类,提示模板必须包含两个输入的空间,[X1]和[X2],或更多。
2、手动模板设计
也许创建提示(prompt)最自然的方法是基于人类的内省手动创建直观的模板。例如:
- 开创性的LAMA数据集(Petroni et al.,2019)提供了手动创建的完形填空模板,以探索LMs中的知识。
- Brown等人(2020年)创建手工制作的前缀提示(prompt),以处理各种任务,包括问答、翻译和常识推理的探测任务。
- Schick和Sch̉utze(2020、2021a、b)在文本分类和有条件文本生成任务的少量快照学习设置中使用预定义模板。
3、自动模板学习
虽然手工制作模板的策略是直观的,并允许以一定程度的准确性解决各种任务,但这种方法也存在一些问题:
- 创建和试验这些提示是一门需要时间和经验的艺术,特别是对于一些复杂的任务,如语义分析(Shin等人,2021);
- 即使是经验丰富的提示设计者也可能无法手动发现最佳提示(Jiang等人,2020c)。
为了解决这些问题,已经提出了许多方法来自动化模板设计过程。特别是,自动生成的提示可以进一步分为:
- 离散提示(其中提示是实际的文本字符串);
- 连续提示(其中提示直接在底层LM的嵌入空间中描述);
另一个正交设计考虑因素是提示函数 f prompt ( x ) f_{\text {prompt }}(\boldsymbol{x}) fprompt (x) 是静态的,为每个输入使用基本相同的提示模板,还是动态的,为每个输入生成自定义模板。静态和动态策略都被用于不同种类的离散和连续提示,论文将在下面提到。
3.1 离散提示(Discrete Prompts)
D1:Prompt Mining
Jiang等人(2020c)的挖掘方法是一种基于挖掘的方法,可以在给定一组训练输入 x \boldsymbol{x} x 和输出 y \boldsymbol{y} y 的情况下自动找到模板。该方法从大型文本语料库(如维基百科)中提取包含 x \boldsymbol{x} x 和 y \boldsymbol{y} y 的字符串,并在输入和输出之间找到中间词或依赖路径。频繁的中间词或依赖路径可以用作模板,如“[X]中间词[Z]”。
D2: Prompt Paraphrasing
基于释义的方法采用现有的种子提示(例如手动构建或挖掘),并将其释义为一组其他候选提示,然后选择在目标任务上达到最高训练精度的提示。这种释义可以通过多种方式完成,包括将提示翻译成另一种语言,然后再翻译回来(Jiang等人,2020c),使用同义词库中的短语替换(Yuan等人,2021b),或使用专门优化的神经提示重写器,以提高使用提示的系统的准确性(Haviv等人,2021)。值得注意的是,Haviv等人(2021)在将输入 x \boldsymbol{x} x 输入到提示模板后进行复述,允许为每个单独的输入生成不同的复述。
D3: Gradient-based Search
Wallace et al.(2019a)对实际token进行了基于梯度的搜索,以找到可以触发基础预训练LM生成所需目标预测的短序列。此搜索以迭代方式完成,在提示符中单步搜索标记。Shin et al.(2020)基于这种方法,使用下游应用程序训练样本自动搜索模板tokens,并在提示场景中表现出强大的性能。
D4: Prompt Generation
其他工作将提示的生成视为文本生成任务,并使用标准的自然语言生成模型来执行此任务。例如,Gao等人(2021)将seq2seq预训练模型T5引入模板搜索过程。由于T5已经在填充缺失跨度的任务上接受了预训练,他们使用T5生成模板标记(tokens),方法是
- 指定在模板中插入模板标记的位置
- 为T5提供解码模板标记的训练样本。
Ben David等人(2021)提出了一种域自适应算法,该算法训练T5为每个输入生成唯一的域相关特征(DRF;一组描述域信息的关键字)。然后,可以将这些DRF与输入连接起来,形成一个模板,供下游任务进一步使用。
D5: Prompt Scoring
Davison等人(2019年)研究了知识库完成的任务,并使用LMs为输入(头-关系-尾三元组)设计了一个模板。他们首先手工制作一组模板作为潜在的候选,然后填充输入和答案槽,形成一个填充提示。然后,他们使用单向LM对已填写的提示进行评分,选择LM概率最高的提示。这将为每个单独的输入生成自定义模板。
3.2 连续提示(Continuous Prompts)
由于提示构造的目的是找到一种方法,使LM能够有效地执行任务,而不是供人类使用,因此没有必要将提示限制为人类可解释的自然语言。
因此,还有一些方法可以检查直接在模型嵌入空间中执行提示的continuous prompts(也称为soft prompts))。
具体来说,连续提示消除了两个约束:
- 放宽模板词的嵌入是自然语言(如英语)词的嵌入的约束。
- 取消模板由预先训练的LM参数参数化的限制。相反,模板有自己的参数,可以根据下游任务的训练数据进行调整。
下面论文重点介绍几种有代表性的方法:
- C1:前缀调整
前缀调整(Li和Liang,2021)是一种将连续的任务特定向量序列预先添加到输入的方法,同时保持LM参数冻结。从数学上讲,这包括在给定可训练前缀矩阵 M ϕ M_{\phi} Mϕ 和由 θ \theta θ 参数化的固定预训练LM的情况下,对以下对数似然目标进行优化。
max ϕ log P ( y ∣ x ; θ ; ϕ ) = max ϕ ∑ y i log P ( y i ∣ h < i ; θ ; ϕ ) \max _{\phi} \log P(\boldsymbol{y} \mid \boldsymbol{x} ; \theta ; \phi)=\max _{\phi} \sum_{y_{i}} \log P\left(y_{i} \mid h_{
在等式2中, h < i = [ h < i ( 1 ) ; ⋯ ; h < i ( n ) ] h_{
实验上,Li和Liang(2021)观察到,这种基于前缀的连续学习比使用实词的离散提示对低数据环境下的不同初始化更敏感。
类似地,Lester等人(2021)使用特殊标记预先设置输入序列,以形成模板并直接调整这些标记的嵌入。与Li和Liang(2021)的方法相比,这种方法增加的参数更少,因为它不会在每个网络层中引入额外的可调参数。Tsinpoukelli等人(2021)训练了一种视觉编码器,该编码器将图像编码为一系列嵌入,可用于提示冻结的自回归LM生成适当的字幕。他们表明,结果模型可以对视觉语言任务(如视觉问答等)执行少量镜头学习。与上述两项工作不同,在(Tsinpoukelli et al.,2021)中使用的前缀依赖于样本,即输入图像的表示,而不是任务嵌入。 - C2:使用离散提示初始化调整
还有一些方法可以使用已经使用离散提示搜索方法创建或发现的提示来初始化对连续提示的搜索。
例如,Zhong等人(2021b)首先使用诸如AUTOPROMPT(Shin等人,2020)的离散搜索方法定义模板,根据发现的提示初始化虚拟tokens,然后微调嵌入以提高任务准确性。这项工作发现,使用手动模板初始化可以为搜索过程提供更好的起点。Qin和Eisner(2021)建议为每个输入学习一个混合的软模板,其中每个模板的权重和参数是使用训练样本联合学习的。他们使用的初始模板集要么是手工制作的模板,要么是使用“提示挖掘”方法获得的模板。类似地,Hambardzumyan等人(2021)介绍了连续模板的使用,其形状遵循手动提示模板。 - 硬-软提示混合动力调整
这些方法没有使用纯可学习的提示模板,而是将一些可调的嵌入插入到硬提示模板中。Liu等人(2021b)提出了“P-tuning”,即通过在嵌入式输入中插入可训练变量来学习连续提示。为了说明提示标记之间的交互,它们将提示嵌入表示为BiLSTM的输出(Graves et al.,2013)。P-tuning还引入了在模板中使用与任务相关的锚标记(例如关系提取中的“capital”),以进一步改进。这些锚标记在训练期间未调整。Han等人(2021)提出了规则提示调优(PTR),它使用手工制作的子模板,使用逻辑规则组成完整的模板。为了增强结果模板的表示能力,他们还插入了几个虚拟tokens,这些虚拟tokens的嵌入可以使用训练样本与预先训练的LMs参数一起进行调整。PTR中的模板令牌包含实际tokens和tokens。实验结果证明了这种快速设计方法在关系分类任务中的有效性。
五、应答设计
与为提示方法设计适当输入的提示设计不同,应答设计旨在搜索答案空间 Z \mathcal{Z} Z 和原始输出 Y \mathcal{Y} Y 的映射,从而生成有效的预测模型。图1的“应答设计”部分说明了在执行答案工程时必须考虑的两个方面:
- 确定答案粒度;
- 选择答案设计方法;
1、答案粒度
在实践中,如何选择可接受答案的粒度取决于我们想要执行的任务。
- Tokens:预训练的LM词汇表中的一个token,或词汇表的子集。
- Span:短的multi-token 片段。这些提示通常与完形填空提示一起使用。
- Sentence:一个句子或文件。这些通常与前缀提示一起使用。
token或文本范围答案空间广泛用于分类任务(例如,情感分类;Yin等人(2019)),但也用于其他任务,如关系提取(Petroni等人,2019)或命名实体识别(Cui等人,2021)。
较长的短语或句子回答通常用于语言生成任务(Radford et al.,2019),但也用于其他任务,如多项选择题回答(其中多个短语的分数相互比较;Khashabi et al.(2020))。
2、答案空间设计方法
下一个要回答的问题是,如果答案没有用作最终输出,如何设计适当的答案空间 Z \mathcal{Z} Z 以及到输出空间 Y \mathcal{Y} Y 的映射。
2.1 手动设计
在手动设计中,潜在答案的空间 Z \mathcal{Z} Z 及其到 Y \mathcal{Y} Y 的映射是由感兴趣的系统或基准设计人员手动构建的。可以采取多种策略来执行此设计。
- 无约束空间
- 在许多情况下,答案空间 Z \mathcal{Z} Z 是所有标记(Petroni et al.,2019)、固定长度跨度(Jiang et al.,2020a)或标记序列(Radford et al.,2019)的空间。在这些情况下,最常见的是使用标识映射将答案 Z \mathcal{Z} Z 直接映射到最终输出 Y \mathcal{Y} Y 。
- 受限空间
然而,也存在可能输出的空间受到约束的情况。这通常用于标签空间有限的任务,如文本分类或实体识别,或多项选择问答系统。
为了举例说明,Yin等人(2019)手动设计了与相关主题(“健康”、“金融”、“政治”、“体育”等)、情绪(“愤怒”、“喜悦”、“悲伤”、“恐惧”等)或待分类输入文本的其他方面相关的单词列表。Cui等人(2021)手动设计NER任务的列表,如“人员”、“位置”等。在这些情况下,有必要在答案 Z \mathcal{Z} Z 和基础类 Y \mathcal{Y} Y 之间进行映射。
关于多项选择题回答,通常使用LM来计算多项选择中的输出概率,Zweig et al.(2012)就是一个早期的例子。
2.2 离散答案搜索
与手动创建的提示一样,手动创建的答案对于获得LM以实现理想的预测性能来说可能是次优的。因此,在自动答案搜索方面有一些工作,尽管比搜索理想提示的工作要少。这些函数同时适用于离散答案空间(本节)和连续答案空间(以下)。
答案释义(Answer Paraphrasing) 这些方法从初始答案空间 Z ′ \mathcal{Z}^{\prime} Z′ 开始,然后使用意译扩展该答案空间以扩大其覆盖范围(Jiang等人,2020b)。给定一对答案和输出 ⟨ z ′ , y ⟩ \left\langle\boldsymbol{z}^{\prime}, \boldsymbol{y}\right\rangle ⟨z′,y⟩ ,我们定义一个函数,该函数生成一组解释过的答案 z ′ z^{\prime} z′ 。最终输出的概率被定义为该释义集中所有答案的边际概率 P ( y ∣ x ) = ∑ z ∈ nara ( z ′ ) P ( z ∣ x ) P(\boldsymbol{y} \mid \boldsymbol{x})=\sum_{\boldsymbol{z} \in \operatorname{nara}\left(\boldsymbol{z}^{\prime}\right)} P(\boldsymbol{z} \mid \boldsymbol{x}) P(y∣x)=∑z∈nara(z′)P(z∣x) 。这种释义可以使用任何方法进行,但Jiang等人(2020b)特别使用回译方法,首先翻译成另一种语言,然后再回译,以生成多个释义答案的列表。
剪枝然后搜索(Prune-then-Search) 在这些方法中,首先生成多个似是而非答案 Z ′ \mathcal{Z}^{\prime} Z′ 的初始修剪答案空间,然后算法在该修剪空间上进一步搜索以选择最终答案集。请注意,在下面介绍的一些论文中,他们定义了一个从标签 y \boldsymbol{y} y 到单个答案标记 z \boldsymbol{z} z 的函数,该标记通常被称为描述器(Schick和Sch̉utze,2021a)。Schick和Sch̉utze(2021a);
- Schick等人(2020年)发现了包含至少两个字母字符的标记,这些字符在大型未标记数据集中很常见。在搜索步骤中,他们通过最大化标签对训练数据的可能性,迭代计算单词作为标签 y \boldsymbol{y} y 的代表性答案 z \boldsymbol{z} z 的适用性。
- Shin等人(2020年)使用[Z]标记的上下文表示作为输入学习逻辑分类器。在搜索步骤中,他们在第一步中使用学习的logistic分类器选择概率得分最高的前k个标记。这些选定的标记将构成答案。
- Gao等人(2021)首先构建了一个修剪的搜索空间 Z ′ \mathcal{Z}^{\prime} Z′,根据训练样本确定的[Z]位置的生成概率,选择前k个词汇。然后,根据训练样本的zero-shot精度,仅选择 Z ′ \mathcal{Z}^{\prime} Z′ 内的一个子集,进一步缩减搜索空间。在搜索步骤中,他们使用固定模板和使用训练数据的每个答案映射对LM进行微调,并根据开发集的准确性选择最佳标签词作为答案。
标签分解(Label Decomposition) 当执行关系提取时,Chen等人(2021b)会自动将每个关系标签分解为其组成词,并将其用作答案。例如,对于per:city_of_death的关系,分解后的标签词将是{person,city,death}。答案范围的概率将计算为每个token的概率之和。
2.3 连续答案搜索
很少有作品探讨使用软应答token的可能性,软应答token可以通过梯度下降进行优化。
Hambardzumyan等人(2021)为每个类别标签分配一个虚拟token,并优化每个类别的token嵌入以及提示token嵌入,因为答案token直接在嵌入空间中优化,它们不使用LM学习的嵌入,而是从头开始为每个标签学习嵌入。
六、多提示(Multi-Prompt)学习
到目前为止,论文讨论的提示工程方法主要集中于构建输入的单个提示。然而,大量研究表明,使用多重提示可以进一步提高提示方法的有效性,论文将这些方法称为多提示学习方法。
在实践中,有几种方法可以将单提示学习扩展到使用多个提示,这些提示具有多种动机。我们在图1和图4的“多提示学习”部分总结了有代表性的方法。
图4:不同的多提示学习策略。我们使用不同的颜色来区分不同的组件,使用以下缩写,“PR”表示提示,“Ans PR”表示应答提示,“Sub PR”表示子提示

1、提示(Prompt)集成
Prompt ensembling是在推理时对输入使用多个未应答提示进行预测的过程。图4-(a)中示出了一个示例。多个提示可以是离散提示,也可以是连续提示。这种快速集成可以(1)利用不同提示的互补优势,(2)降低快速设计的成本,因为选择一个性能最好的提示是很有挑战性的,(3)稳定下游任务的性能。
即时感知与用于组合多个系统的感知方法有关,这些系统在机器学习方面有着悠久的历史(Ting和Witten,1997;Zhou等人,2002;Duh等人,2011)。当前的研究还借鉴了这些作品的思想,得出了快速集成的有效方法,如下所述。
七、提示(Prompting)方法的训练策略
使用上述部分中的方法,现在可以清楚地了解如何获得适当的提示和相应的答案。现在,论文讨论与提示方法一致的显式训练模型的方法,如图1的“训练策略”部分所述。
1、训练设置
在许多情况下,可以使用提示方法,而无需对下游任务的LM进行任何明确的训练,只需使用经过训练的LM来预测文本 P ( x ) P(\boldsymbol{x}) P(x) 的概率,并按原样应用它来填充为指定任务而定义的完形填空或前缀提示。这通常被称为zero-shot设置,因为感兴趣的任务没有训练数据。
然而,也有一些方法使用训练数据来训练模型,并配合提示方法。这些包括完全数据学习,其中使用了相当多的训练示例来训练模型,或使用了很少的示例来训练模型的few-shot learning。在后一种情况下,提示方法特别有用,因为通常没有足够的训练示例来完全指定所需的行为,因此使用提示将模型推向正确的方向尤其有效。
需要注意的一点是,对于§4中描述的许多提示工程方法,虽然带注释的训练样本未明确用于下游任务模型的训练,但它们通常用于构建或验证下游任务将使用的提示。正如Perez et al.(2021)所指出的,这可以说并不是关于下游任务的真正zero-shot learning。
2、参数更新方法
在基于提示的下游任务学习中,通常有两种类型的参数,即来自:
- 预训练模型;
- 提示的参数;
应更新哪一部分参数是一个重要的设计决策,这可能导致在不同场景中具有不同的适用性级别。
论文总结了五种调整策略(如表6所示)(i)是否调整了基础LM的参数,(ii)是否有额外的提示相关参数,(iii)如果有额外的提示相关参数,是否调整了这些参数。
表6:不同调整策略的特点。“Additional”(附加)表示LM参数之外是否有其他参数,“Tuned”(调整)表示参数是否更新。

2.1 Promptless Fine-tuning
自提示方法普及之前,预训练和微调策略就已广泛应用于NLP。在这里,我们将无提示的预训练和微调称为promptless fine-tuning,以与以下部分介绍的基于提示的学习方法形成对比。
在该策略中,给定一个任务数据集,所有(或部分(Howard and Ruder,2018;Peters et al.,2019))预训练LM的参数将通过从下游训练样本中引入的梯度进行更新。
以这种方式调整的预训练模型的典型示例包括BERT和RoBERTa。
这是一种简单、功能强大且广泛使用的方法,但它可能会在小数据集上过度拟合或学习不稳定(Dodge et al.,2020)。模型也容易发生灾难性遗忘,LM失去了做微调之前能够做的事情的能力(McCloskey和Cohen,1989)。
优点是简单,无需prompt设计。调整所有LM参数可使模型适应更大的训练数据集。缺点是LMs可能过度拟合或在较小的数据集上学习不稳定。
2.2 Tuning-free Prompting
无调整提示直接生成答案,仅根据提示无需更改预先训练的LMs的参数,如§2中最简单的提示形式所述。如§6.2所述,可以选择使用应答提示来增加输入,这种无调整提示和提示增加的组合也被称为上下文学习(Brown et al.,2020)。
无调整提示的典型示例包括LAMA【133】和GPT-3【16】。
- 优点是效率高,无需参数更新过程。没有灾难性遗忘,因为LM参数保持不变。适用于zero-shot learning。
- 缺点是由于提示是提供任务规范的唯一方法,因此需要进行大量的工程设计才能实现高精度。特别是在上下文学习环境中,在测试时提供许多回答提示可能很慢,因此无法轻松使用大型训练数据集
2.3 Fixed-LM Prompt Tuning
在除了预训练模型的参数之外还引入了其他提示相关参数的场景中,固定LM提示调整使用从下游训练样本获得的监控信号仅更新提示的参数,同时保持整个预训练LM不变。典型的例子是Prefix-Tuning 和WARP。
- 优点是与无调整提示类似,它可以保留LMs中的知识,适用于few-shot场景。通常比无调整提示更精确。
- 缺点是不适用于zero-shot场景。虽然在few-shot场景中有效,但在大数据设置中表示能力有限。有必要通过选择超参数或种子提示进行提示工程。提示通常不可人工解释或操作。
2.4 Fixed-prompt LM Tuning
Fixed-prompt LM调整LM的参数,就像在标准预训练和微调范例中一样,但还使用带有固定参数的提示来指定模型行为。这可能会带来改进,尤其是在few-shot场景中。
最自然的方法是提供一个离散的文本模板,应用于每个训练和测试示例。典型示例包括PET-TC、PET-Gen、LM-BFF。
Logan IV等人(2021)最近观察到,通过允许应答工程和部分LM微调相结合,可以减少提示设计。例如,他们定义了一个非常简单的模板,null prompt,其中输入和掩码直接连在一起“[X][Z]”,没有任何模板词,并发现这可以实现具有竞争力的准确性。
- 优点是提示或回答工程更全面地指定任务,允许更有效的学习,尤其是在少数镜头场景中。
- 缺点是尽管可能没有没有提示那么多,但仍然需要提示或应答设计。对一个下游任务进行微调的LMs可能对另一个任务无效。
2.5 Prompt+LM Tuning
在此设置中,会提示相关参数,这些参数可以和预训练模型的全部或部分参数一起微调。代表性示例包括PADA、P-Tuning。
值得注意的是,此设置与标准的预训练和微调范例非常相似,但添加提示可以在模型训练开始时提供额外的引导。
- 优点是这是最具表现力的方法,可能适用于高数据设置。
- 缺点是需要训练和存储模型的所有参数。可能过度适合小型数据集。
八、应用
在前面的章节中,论文从方法本身的机制角度来研究prompting方法。
在本节中,论文将从应用程序的角度来组织提示方法。我们在表7-8中列出了这些应用程序。并在以下章节中进行总结。
表7-8:关于promting的工作汇总


表7-8缩写说明:任务列列出了在相应的论文中执行的任务。
- 论文使用以下缩写。
- CR:常识推理。
- QA:问答。
- SUM:文本摘要。
- MT:机器翻译。
- LCP:语言能力探索。
- GCG:通用条件生成。
- CKM:常识知识挖掘。
- FP:事实探索。
- TC:文本分类。
- MR:数学推理。
- SR:符号推理。
- AR:类比推理。
- Theory:理论分析。
- IE:信息提取。
- D2T:数据到文本。
- TAG:序列标记。
- SEMP:语义分析。
- EVALG:文本生成的评估。
- VQA:可视化问答。视觉事实探测。
- MG:多模接地。
- CodeGen:代码生成。
- PLM列列出了在下游任务的相应论文中使用的所有预训练的LMs。GPT-like是一种自回归语言模型,它对原始GPT-2体系结构进行了微小的修改。
- Setting列列出了基于提示的学习的设置,可以是zero-shot learning (Zero)、few-shot learning (Few)、fully supervised learning (Full).。
- 在提示设计中:
- Shape表示模板的类型(Clo表示完形填空,Pre表示前缀),
- Man表示是否需要人力,
- Auto表示数据驱动的搜索方法(Disc表示离散搜索,Cont表示连续搜索)。
- 在“答案设计”下,Shape表示答案的粒度(Tok表示token级别,Sp表示片段级别,Sen表示句子或文档级别),Man和Auto与上述相同。
- Tuning列列出了调整策略(§7)。TFP:无需调整提示。LMT:固定提示LM调整。PT:固定LM提示调谐。LMPT:LM+提示调整。Mul-Pr列列出了多提示学习方法。PA:提示扩增。PE:提示集成。PC:提示合成。PD:提示分解。
1、知识探索
事实探索(Factual Probing) 事实探索(又称事实检索)是最早应用提示方法的场景之一。探索这项任务的动机是量化经过预训练的LM的内部表示所承载的事实知识量。在这项任务中,预训练模型的参数通常是固定的,通过将原始输入转换为§2.2中定义的完形填空提示来检索知识,完形填空提示可以手动制作或自动发现。相关数据集包括LAMA(Petroni et al.,2019)和X-FACTR(Jiang et al.,2020a)。由于答案是预定义的,事实检索只关注于找到有效的模板,并使用这些模板分析不同模型的结果。离散模板搜索(Petroni et al.,2019,2020;Jiang et al.,2020c,a;Haviv et al.,2021;Shin et al.,2020;Perez et al.,2021)和连续模板学习(Qin and Eisner,2021;Liu et al.,2021b;Zhong et al.,2021b)以及快速集成学习(Jiang et al.,2020c;Qin and Eisner,2021)都已在此背景下进行了探索。
语言探索(Linguistic Probing) 除了事实知识外,大规模的预训练还允许LMs处理语言现象,如类比(Brown et al.,2020)、否定(Ettinger,2020)、语义角色敏感性(Ettinger,2020)、语义相似性(Sun et al.,2021)、不能理解(Sun et al.,2021)和罕见词理解(Schick and Sch̉utze,2020)。上述知识也可以通过以自然语言句子的形式呈现语言探索任务来获得,这些任务将由LM完成。
2、基于分类的任务
基于提示的学习在基于分类的任务中得到了广泛的探索,在这些任务中,提示模板可以相对容易地构建,例如文本分类(Yin等人,2019)和自然语言推理(Schick和Sch̉utze,2021a)。提示基于分类的任务的关键是将其重新格式化为适当的提示。例如,Yin et al.(2019)使用提示,如“本文档的主题是[Z]”,然后将其喂给掩码预训练LMs中进行槽填充。
文本分类(Text Classification) 对于文本分类任务,以前的大多数工作都使用完形填空提示,提示设计(Gao等人,2021;Hambardzumyan等人,2021;Lester等人,2021)和答案设计(Schick和Sch̉utze,2021a;Schick等人,2020;Gao等人,2021)都得到了广泛的探索。大多数现有研究探索了在“固定提示LM调整”策略(定义见§7.2.4)的few-show设置下,提示学习对文本分类的有效性。
自然语言推理(Natural Language Inference-NLI)NLI旨在预测两个给定句子的关系(例如,蕴涵(entailment))。与文本分类任务类似,对于自然语言推理任务,通常使用完形填空提示(Schick和Sch̉utze,2021a)。关于提示设计,研究人员主要关注在few-shot学习环境中的模板搜索,答案空间 $$ 通常是从词汇表中手动预先选择的。
3、信息提取
与分类任务不同,在分类任务中,完形填空问题通常可以直观地构建,而对于信息提取任务,构建提示通常需要更精细的技巧。
3.1 命名实体识别
命名实体识别(NER)是在给定句子中识别命名实体(例如人名、位置)的任务。
基于提示的学习应用于序列表住任务(如NER)的困难在于,与分类不同:
- 要预测的每个单元是一个token或片段,而不是整个输入文本,
- 样本上下文中的标记(token)标签之间存在潜在关系。
总的来说,基于提示的学习在标记任务中的应用还没有得到充分的探索。
Cui等人(2021)最近提出了一种使用BART的基于模板的NER模型,该模型列举了文本跨度,并考虑了手动制作模板中每种类型的生成概率。例如,给定一个输入“Mike昨天去了纽约”,为了确定实体“Mike”的类型,他们使用模板“Mike是一个[Z]实体”,答案空间Z由“person”或“organization”等值组成。
3.2 关系抽取
关系抽取是一项预测句子中两个实体之间关系的任务。Chen等人(2021b)首先探讨了固定提示LM调整(fixed-prompt LM Tuning)在关系提取中的应用,并讨论了阻碍提示方法从分类任务直接继承的两个主要挑战:
- 标签空间越大(例如,在二元情感分类(2)vs关系抽取(80)),导致应答设计越困难。
- 在关系抽取中,输入句子中的不同标记可能或多或少重要(例如,实体提及更有可能参与关系),但是,由于原始提示模板对每个单词都一视同仁,因此很难在分类提示模板中反映出来。
为了解决上述问题,Chen等人(2021b)提出了一种自适应答案选择方法来解决问题(1),并针对问题(2)构建面向任务的提示模板,其中他们使用特殊标记(如[e])来突出模板中提到的实体。类似地,Han等人(2021)通过多种提示合成技术(如图4所示)合并实体类型信息。
3.3 语义分析
语义分析是在给定自然语言输入的情况下生成结构化语义表示的任务。Shin等人(2021)通过(1)将语义分析任务框架化为释义任务(Berant和Liang,2014)和(2)通过仅允许根据语法有效的输出来限制解码过程,探索了使用LMs进行few-shot语义分析的任务。他们使用§7.2.2中描述的上下文学习设置进行实验,选择语义上接近给定测试示例的已回答提示(由给定另一个训练示例生成测试示例的条件生成概率确定)。结果表明,使用预训练好的LMs对语义分析任务进行改写是有效的。
4、NLP中的“推理”
关于深层神经网络是否能够执行“推理”或仅仅基于大量训练数据记忆模式,仍存在争议(Arpit等人,2017年;Niven和Kao,2019年)。因此,有很多人试图通过定义跨越不同场景的基准任务来探索模型的推理能力。下面论文将详细介绍如何在这些任务中使用提示方法。
4.1 常识推理
有许多基准数据集测试NLP系统中的常识推理(Huang et al.,2019;Rajani et al.,2019;Lin et al.,2020;Ponti et al.,2020)。
一些经常尝试的任务涉及解决Winograd模式(Leveque等人,2012),这需要模型在上下文中识别歧义代词的先行词,或者涉及完成给定多项选择的句子。对于前者,一个例子可能是“奖杯放不进棕色的手提箱,因为它太大了。”该模型的任务是推断“它”是指奖杯还是“手提箱”。通过用原始句子中的潜在候选词替换“它”,并计算不同选择的概率,经过预训练的LMs可以通过选择实现最高概率的选择来表现得相当好(Trinh和Le,2018)。对于后者,一个例子可以是“埃莉诺主动为她的客人准备了一些咖啡。然后她意识到她没有干净的咖啡。”。候选人的选择是“杯子”、“碗”和“勺子”。预训练的LM的任务是从三位候选人中选出最符合常识的一位。对于这类任务,我们还可以对每个候选任务的生成概率进行评分,并选择概率最高的任务(Ettinger,2020)。
4.2 数学推理
数学推理是解决数学问题的能力,例如算术加法、函数求值。
在预训练LMs的背景下,研究人员发现,预训练嵌入和LMs可以在位数较小时执行简单的运算,如加减运算,但在位数较大时会失败(Naik等人,2019;Wallace等人,2019b;Brown等人,2020)。Reynolds和McDonell(2021)探讨了更复杂的数学问题(例如 、 、 、 )推理问题,并通过序列化问题推理来提高LM性能。
5、问答系统
问答系统(QA)旨在回答给定的输入问题,通常基于上下文文档。
QA可以采用多种格式,例如:
- 抽取式QA(从包含答案的上下文文档中识别内容;例如,SQuAD(Rajpurkar et al.,2016));
- 多选QA(其中模型必须从多个选项中进行选择;例如RACE(Lai et al.,2017));
- 自由形式QA(其中模型可以返回任意文本字符串作为响应;例如叙事QA(Koˇcisḱy et al.,2018))。
通常,使用不同的建模框架处理这些不同的格式。使用LMs解决QA问题(可能使用提示方法)的一个好处是,可以在同一框架内解决不同格式的QA任务。例如,Khashabi et al.(2020)通过微调基于seq2seq的预先训练模型(如T5)和来自上下文和问题的适当提示,将许多QA任务重新表述为文本生成问题。Jiang等人(2020b)使用序列到序列预训练模型(T5、BART、GPT2)仔细研究了此类基于提示的QA系统,并观察到这些预训练模型在QA任务中的概率并不能很好地预测模型是否正确。
6、文本生成
文本生成是一系列涉及生成文本的任务,通常以其他信息为条件。通过使用前缀提示和自回归预训练LMs,提示方法可以很容易地应用于这些任务。Radford et al.(2019)展示了此类模型在执行生成任务(如文本摘要和机器翻译)方面令人印象深刻的能力,使用提示(如“翻译成法语,[X],[Z])。Brown等人(2020年)针对文本生成执行上下文学习(§7.2.2),使用手动模板创建提示,并使用多个回答的提示增加输入。Schick和Sch̉utze(2020)探索了固定提示LM调整(§7.2.4),以便使用手工制作的模板进行few-shot文本摘要。(Li和Liang,2021)研究固定LM提示调整(§7.2.3),以便在few-shot设置中进行文本摘要和数据到文本生成,其中可学习前缀标记预先添加到输入中,而预训练模型中的参数保持冻结。Dou等人(2021)探索了文本摘要任务中的提示+LM调整策略(§7.2.5),其中使用可学习的前缀提示,并由不同类型的引导信号初始化,然后可以与预先训练的LMs参数一起更新。
7、文本生成的自动评估
Yuan等人(2021b)证明,prompting学习可以用于自动评估生成的文本。具体而言,他们将生成文本的评估概念化为文本生成问题,使用预先训练的序列进行建模,然后使用前缀提示使评估任务更接近预训练任务。他们通过实验发现,在使用预训练好的模型时,只需在翻译文本中添加短语“such as”,就可以显著改善德英机器翻译(MT)评估的相关性。
8、多模态学习
Tsinpoukelli等人(2021)将prompting学习的应用从基于文本的NLP转移到多模态环境(视觉和语言)。通常,它们采用固定LM提示调整策略和提示扩增技术。它们具体地将每个图像表示为一系列连续嵌入,并使用此前缀提示其参数已冻结的预训练LM生成文本,如图像标题。实验结果表明,镜头学习能力很低:在一些演示(回答提示)的帮助下,系统可以快速学习新对象和新视觉类别的单词。
9、元应用
还有许多提示技术的应用程序本身并不是NLP任务,而是为任何应用程序训练强模型的有用元素。
领域适应 领域适应是将模型从一个领域(如新闻文本)调整到另一个领域(如社交媒体文本)的实践。Ben David等人(2021)使用domain related features(DRF)来增加原始文本输入,并使用seq2seq预训练模型将序列标记作为序列间问题。
借记(Debiasing)Schick等人(2021)发现LMs可以根据有偏差或有偏差的指令执行自我诊断和自我借记。例如,要自我诊断生成的文本是否包含暴力信息,我们可以使用以下模板“以下文本包含暴力。[X][Z]”。然后我们用输入文本填充[X],并查看[Z]处的生成概率,如果“是”的概率大于“否”,那么我们将假设给定文本包含暴力,反之亦然。为了在生成文本时执行借记,我们首先计算给定原始输入的下一个单词 P ( x t ∣ x < t ; θ ) P\left(x_{t} \mid \boldsymbol{x}_{
数据集构建 Schick和Sch̉utze(2021)建议使用预训练的LMs生成给定特定指令的数据集。例如,假设我们有一个未标记的数据集,其中每个样本都是一个句子。如果我们想构建一个包含语义相似句子对的数据集,那么我们可以为每个输入句子使用以下模板:“写出两个意思相同的句子[X][Z]”,并尝试生成一个与输入句子具有相同含义的句子。
10、资源
论文还为不同的基于提示的应用程序收集了一些有用的资源。
表9:用于基于提示的学习的few-shot和zero-shot数据集。
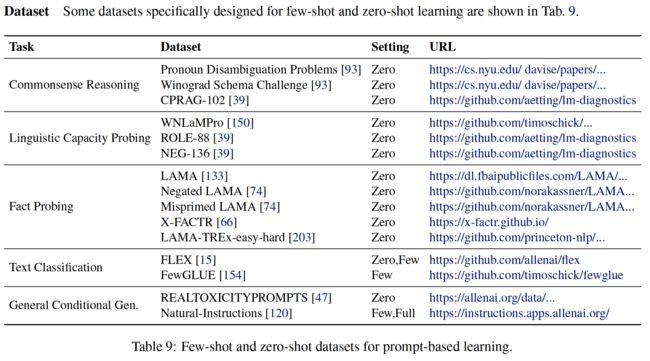
表10:不同任务的常用提示和答案。[十] 和[Z]分别表示用于输入和应答的槽位。V表示LM的词汇表。可以使用资源列找到每个任务的更多提示。

如表10、论文收集了现有的手工设计的常用prompt,可以作为未来研究和应用的现成资源。
十、提示(Prompt)相关主题
Prompt学习的本质是什么?它与其他学习方法有什么关系?在本节中,论文将prompt学习与其他类似的学习方法联系起来。
表11:与promting方法相关的其他研究课题
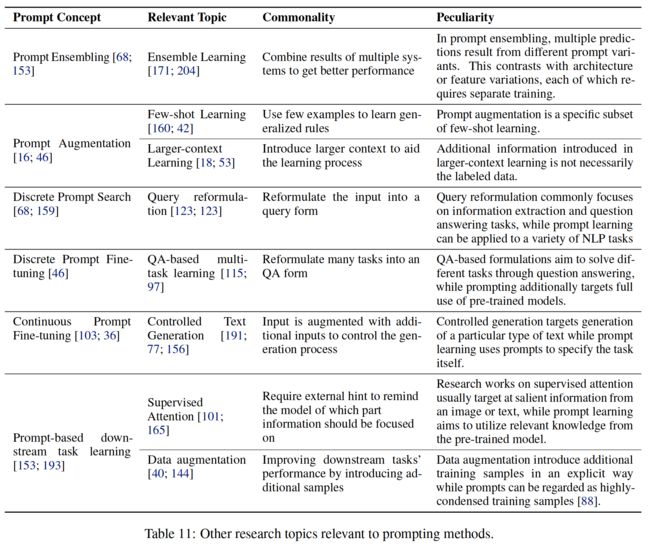
1、集成学习
集成学习(Ting和Witten,1997;Zhou等人,2002)是一种旨在利用多个系统的互补性来提高任务性能的技术。通常,集成中使用的不同系统是由于架构、训练策略、数据排序和/或随机初始化的不同选择造成的。在prompt ensembling(§6.1)中,选择提示模板成为生成要组合的多个结果的另一种方式。这有一个明显的优点,即不一定需要多次训练模型。例如,当使用离散提示时,可以在推理阶段简单地更改这些提示(Jiang等人,2020c)。
2、Few-shot Learning
Few-shot Learning旨在利用较少的训练样本,在数据稀缺的场景中学习机器学习系统。
实现Few-shot Learning的方法多种多样,包括模型不可知元学习(Finn et al.,2017b)(学习特征快速适应新任务)、嵌入学习(Bertineto et al.,2016)(将每个样本嵌入相似样本密集的低维空间),基于记忆的学习(Kaiser et al.,2017)(通过记忆内容的加权平均值表示每个样本)等(Wang et al.,2020)。
Prompt扩增可以被视为实现few-shot Learning的另一种方式(也称为基于启动的Few-shot Learning(Kumar和Talukdar,2021))。
与以前的方法相比,Prompt 扩增直接在当前处理的样本中预先加入几个标记样本,从预先训练的LMs中获取知识,即使没有任何参数调整。
3、Larger-context Learning
Larger-context Learning旨在通过使用额外的背景信息来增加输入,例如从训练集(Cao等人,2018)或外部数据源(Guu等人,2020)检索的信息,从而提高系统的性能。提示增强可以看作是将相关的标记样本添加到输入中,但一个较小的区别是在较大的上下文学习中,引入的上下文不一定是标记数据。
4、查询重写
查询重写(Mathieu和Sabatier,1986;Dauḿe III和Brill,2004)通常用于信息检索(Nogueira和Cho,2017)和问答任务(Buck等人,2017;Vakulenko等人,2020),其目的是通过使用相关查询词扩展输入查询(Hassan,2013)或生成释义来获取更多相关文本(文档或答案)。基于Prompt的学习和查询重构之间有几个共同点,例如(1)两者都旨在通过提出正确的问题来更好地利用一些现有的知识库(2)知识库通常是一个黑箱,用户无法使用,因此研究人员必须学习如何仅基于问题进行最佳探索。
也存在差异:传统查询重写问题中的知识库通常是搜索引擎(Nogueira和Cho,2017),或QA系统(Buck等人,2017)。相比之下,对于基于提示的学习,论文通常将此知识库定义为LM,并且需要找到适当的查询以从中得出适当的答案。即时学习中的输入格式改变了任务的形式。例如,一个原始的文本分类任务已转换为完形填空问题,因此在如何(1)制定适当的任务公式,以及(2)相应地更改建模框架方面带来了额外的复杂性。在传统的查询公式中不需要这些步骤。尽管存在这些差异,但仍可以借鉴查询重写研究中的一些方法进行快速学习,例如将输入查询分解为多个子查询(Nogueira et al.,2019),类似于快速分解。
5、QA-based Task Formulation
QA-based Task Formulation旨在将不同的NLP任务概念化为一个问答问题。(Kumar et al.,2016;McCann et al.,2018)是试图将多个NLP任务统一到QA框架中的早期作品。后来,在信息提取(Li et al.,2020;Wu et al.,2020)和文本分类(Chai et al.,2020)中进一步探讨了这一想法。这些方法与此处介绍的提示方法非常相似,因为它们使用文本问题来指定要执行的任务。然而,Prompting方法的一个关键点是如何更好地使用预训练的LMs中的知识,而之前提倡QA的工作中并未广泛涉及这些知识。
6、受控生成
受控生成旨在将输入文本以外的各种类型的指南纳入生成模型(Yu等人,2020年)。具体而言,指导信号可以是样式标记(Sennrich et al.,2016b;Fan et al.,2018)、长度规范(Kikuchi et al.,2016)、域标记(Chu et al.,2017)或用于控制生成文本的任何其他信息。它也可以是关键字(Saito等人,2020年)、关系三元组(Zhu等人,2020年)甚至是突出显示的短语或句子(Grangier和Auli,2018年;Liu等人,2021c),以规划生成文本的内容。在某种程度上,这里描述的许多提示方法都是一种可控生成,其中提示通常用于指定任务本身。因此,比较容易找到这两种类型之间的共性:(1)都向输入文本添加额外信息以更好地生成,并且这些额外的信号(通常)是可学习的参数。(2) 如果“受控生成”配备了基于seq2seq的预训练模型(如BART),则可将其视为使用依赖于输入的提示和提示+LM微调策略的提示学习(§7.2.5),例如GSum(Dou等人,2021),其中提示和预训练的LM参数都可以调整。
此外,受控生成和基于提示的文本生成之间的一些明显差异是:(1)在受控生成工作中,通常对生成的样式或内容进行控制(Fan et al.,2018;Dou et al.,2021),而基本任务保持不变。他们不一定需要预先训练好的模型。相反,使用提示生成文本的主要动机是指定任务本身并更好地利用预训练的模型。(2) 此外,目前关于文本生成中提示学习的大多数工作都共享一个数据集或任务级提示(Li和Liang,2021)。只有很少的作品探索了输入依赖型(Tsinpoukelli等人,2021)。然而,这在受控文本生成中是一种常见且有效的设置,这可能为将来的快速学习工作提供有价值的方向。
7、有监督注意力
从长文本序列(Liu et al.,2016;Sood et al.,2020)、图像(Sugano and Bulling,2016;Zhang et al.,2020b)或知识库(Yu et al.,2020;Dou et al.,2021)等对象中提取有用信息时,知道关注重要信息是一个关键步骤。监督注意(Liu等人,2017b)旨在基于完全数据驱动的注意力可能过度适应某些工件的事实,对模型的注意进行明确监督(Liu等人,2017a)。在这方面,即时学习和监督注意分享了一些想法,这两种想法都旨在提取具有一些线索的显著信息,这些线索需要单独提供。为了解决这个问题,监督注意方法尝试使用额外的损失函数来学习在手动标记的语料库上预测真实注意力(Jiang等人,2015;Qiao等人,2018;Gan等人,2017)。关于prompting学习的研究也可以借鉴这些文献的观点。
8、数据增强
数据增强是一种旨在通过修改现有数据来增加可用于培训的数据量的技术(Fadaee et al.,2017;Ratner et al.,2017)。正如(Scao和Rush,2021)最近观察到的那样,添加提示可以实现与在分类任务中平均添加100个数据点类似的精度改进,这表明在下游任务中使用提示类似于隐式进行数据扩充。
十、挑战
1、提示(Prompt)设计
1.1 分类和生成以外的任务
大多数现有的基于提示的学习工作都围绕文本分类或基于生成的任务展开。
对信息提取和文本分析任务的应用讨论较少,主要是因为提示的设计不那么简单。
我们预计,在未来将提示方法应用于这些任务时,需要重新制定这些任务,以便使用基于分类或文本生成的方法解决这些任务,或者执行有效的答案工程,以适当的文本格式表达结构化输出。
1.2 结构化信息Prompting
许多NLP任务中,输入都包含一些不同的结构,例如树、图、表或关系结构。
如何在即时或应答工程中最好地表达这些结构是一个重大挑战。
现有的研究(Chen等人,2021b)通过使用额外的标记进行提示来对词汇信息进行编码,例如实体标记。Aghajanyan等人(2021)提出了基于超文本标记语言的结构化提示,用于更细粒度的web文本生成。然而,除了这一点之外,更复杂的结构种类在很大程度上还没有得到探索,这是一个潜在的有趣的研究领域。
1.3 模板和答案组合
模型的性能将取决于使用的模板和考虑的答案。
如何同时搜索或学习模板和答案的最佳组合仍然是一个具有挑战性的问题。
当前作品通常在选择模板之前选择答案(Gao等人。2021;Shin等人,2020年),但Hambardzumyan等人(2021)已经证明了同时学习两者的初步潜力。
2、答案工程
多类别和长答案类别任务 对于基于分类的任务,答案工程面临两个主要挑战:
- 当类太多时,如何选择合适的答案空间成为一个困难的组合优化问题。
- 当使用多tokens应答时,尽管已经提出了一些多tokens解码方法,但如何使用LMs对多tokens进行最佳解码仍然未知(Jiang等人,2020a)。
生成任务的多答案 对于文本生成任务,限定答案可以在语义上等价,但在语法上不同。到目前为止,几乎所有的作品都使用prompting学习来生成文本,只依赖于一个答案,只有少数例外(Jiang等人,20
3、调整策略的选择
如§7所述,有多种方法可用于调整提示、LMs或两者的参数。然而,鉴于这一研究领域处于起步阶段,我们仍然缺乏对这些方法之间权衡的系统理解。该领域可以受益于系统性探索,例如在关于这些不同策略之间权衡的预训练和微调范式中进行的探索(Peters et al.,2019)。
4、多重提示(Prompt)学习
Prompt Ensembling 在提示式集成方法中,随着我们考虑更多提示,空间和时间复杂度会增加。如何从不同的提示中提取知识仍有待探索。Schick和Sch̉utze(2020、2021a、b)使用集成模型对大型数据集进行注释,以从多个提示中提取知识。此外,如何选择适合合奏的提示也有待探讨。对于文本生成任务,目前还没有对即时集成学习进行研究,这可能是因为文本生成中的集成学习本身比较复杂。为了解决这个问题,最近提出的一些神经融合方法,如重构(Liu等人,2021c),可以被视为文本生成任务中快速融合的一种方法。
Prompt合成和分解 提示合成和分解都旨在通过引入多个子提示来解决复杂任务输入的困难。在实践中,如何在两者之间做出正确的选择是至关重要的一步。从经验上看,对于那些标记(Ma和Hovy,2016)或span(Fu et al.,2021)预测任务(例如,NER),可以考虑进行提示分解,而对于那些span关系预测(Lee et al.,2017)任务(例如,实体共指),提示合成将是更好的选择。将来,可以在更多的场景中探索de-/组合的总体思想。
Prompt 扩增 现有的提示扩增方法受到输入长度的限制,即无法向输入提供太多提示。因此,如何选择信息丰富的提示,并以适当的顺序排列它们是一个有趣但具有挑战性的问题(Kumar和Talukdar,2021)。
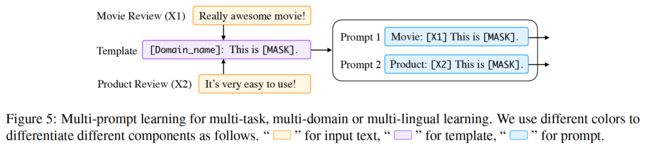
Prompt共享 以上所有注意事项都涉及在单个任务、域或语言中应用提示。我们也可以考虑prompt共享,即即时学习应用于多个任务、领域或语言。可能出现的一些关键问题包括如何为不同的任务设计单独的提示,以及如何调整它们之间的交互。到目前为止,这个领域还没有被探索过。图5展示了一个简单的多任务多提示学习策略,其中提示模板部分共享。
图5:多任务、多领域或多语言学习的多提示学习
5、预训练模型的选择
由于有大量预训练的LMs可供选择(见§3),如何选择它们以更好地利用基于提示的学习是一个有趣而困难的问题。虽然论文已经从概念上介绍了(§3.4)如何为不同的NLP任务选择不同的预训练模型范例,但很少或没有系统地比较不同预训练LMs的即时学习带来的好处。
6、提示(Prompting)的理论与经验分析
尽管他们在许多场景中都取得了成功,但缺乏对即时学习的理论分析和保证。Wei等人(2021)表明,软提示调整可以放松下游恢复所需的非简并性假设(每个标记的生成概率是线性独立的)(即恢复下游任务的地面真值标签),更容易提取特定于任务的信息。Saushi等人(2021)证实,文本分类任务可以重新表述为句子完成任务,从而使语言建模成为一项有意义的训练前任务。Scao和Rush(2021)的经验表明,在分类任务中,提示通常相当于平均100个数据点。
7、提示(Prompts)的可迁移性
理解提示在多大程度上特定于模型,并改进提示的可传递性也是重要的主题。(Perez et al.,2021)表明,在优化的少镜头学习场景下选择的提示(其中有一个更大的验证集来选择提示)可以很好地泛化相似大小的模型,而在真正的少镜头学习场景下选择的提示(其中只有几个训练样本)在相似大小的模型中的泛化效果不如前一个设置。当两种场景中的模型大小相差很大时,可迁移性很差。
8、不同范例的组合
值得注意的是,prompting范式的大部分成功都建立在为预训练和微调范式(如BERT)开发的预训练模型之上。然而,对于后者有效的预培训方法是否也适用于前者,或者我们是否可以完全重新思考我们的预训练方法,以进一步提高基于提示的学习的准确性或易用性?这是一个重要的研究问题,尚未被文献广泛涵盖。
9、提示方法的校准
校准(Gleser,1996)是指模型做出良好概率预测的能力。当使用预先训练的LMs(如BART)的生成概率来预测答案时,我们需要小心,因为概率分布通常没有得到很好的校准。Jiang等人(2020b)观察到,QA任务中预训练模型(如BART、T5、GPT-2)的概率得到了很好的校准。Zhao等人(2021)确定了三个陷阱(多数标签偏差、最近性偏差和共同标记偏差),这三个陷阱导致预先训练的LMs在提供回答提示时偏向于某些答案。例如,如果最终回答的提示有一个肯定的标签,那么这将使模型偏向于预测肯定的词。为了克服这些缺陷,Zhao等人(2021)首先使用上下文无关输入(例如,提示为“输入:亚角色表演。情绪:负面输入:美丽的电影。情绪:正面输入:不适用。情绪:”)来获得初始概率分布P0,然后他们使用真实的输入(例如,提示将是“输入:低于标准的表演。情绪:负面输入:美丽的电影。情绪:正面输入:惊人。情绪:”)来获得概率分布P1。最后,利用这两个分布可以得到经过校准的发电概率分布。然而,这种方法有两个缺点:(1)它带来了寻找适当的上下文无关输入的开销(例如,是使用“不适用”还是“无”),以及(2)基础预训练LM的概率分布仍未校准。
即使我们有一个经过校准的概率分布,当我们为一个输入假设一个真实答案时,我们也需要小心。这是因为同一物体的所有表面形式都将争夺有限概率质量(Holtzman等人,2021)。例如,如果我们将真实答案视为“Whirlpool bath”,则其生成概率通常较低,因为“Bathtub”一词具有相同的含义,它将占据很大的概率。为了解决这个问题,我们可以(i)执行答案设计,使用释义方法(§5.2.2)构建一个全面的真实答案集,或者(ii)根据上下文中单词的先验可能性校准单词的概率(Holtzman et al.,2021)。
十一、元分析
在本节中,我们旨在通过对不同维度的现有研究工作进行元分析,对prompting方法的现有研究进行定量鸟瞰。
1、时间线
论文首先以时间线的形式,按时间顺序总结了一些现有的研究论文,希望这有助于对这一主题不熟悉的研究人员了解该领域的发展。

2、趋势分析
图6:不同维度的荟萃分析。统计数据基于表7-8。在(d)中,我们使用以下缩写。TC:文本分类,FP:事实探索,GCG:一般条件生成,QA:问答,CR:常识推理,SUM:摘要,O:其他

论文还计算了不同维度下基于提示的论文数量。
年 随着各种预训练LMs的出现,基于提示的学习已经成为一个越来越活跃的研究领域,如图6-(a)所示。我们可以看到,2021出现了大幅飙升,这可能是由于GPT-3的流行(Brown et al.,2020),这大大提高了提示在few-shot多任务环境中的普及率。
任务 在图6-(b)中绘制了研究各种任务的作品数量。对于少于5个相关作品的任务,将其分组为“其他”。如条形图所示,大多数基于提示的学习任务都围绕文本分类和事实探究展开。我们推测这是因为对于这些任务,模板设计和答案设计都相对容易进行,而实验在计算上相对便宜。
Prompt与应答搜索 如前几节所述,Prompt和答案搜索都是在许多任务中利用预先训练的语言模型的重要工具。目前的研究主要集中在模板搜索,而不是答案搜索,如图6-(c)所示。
可能的原因是:(1)对于条件生成任务(例如摘要或翻译),真实参考可以直接用作答案。虽然有许多序列可能具有相同的语义,但如何在条件文本生成问题中有效地进行多参考学习是一个非常重要的问题。(2) 对于分类任务,大多数情况下,使用领域知识选择标签词相对容易。
离散搜索与连续搜索 由于目前对自动答案搜索的研究较少,因此我论文自动模板搜索进行了分析。随着时间的推移,从离散搜索到快速工程的连续搜索已经发生了转变,如图6-(d)所示。可能的原因是:(1)离散搜索比连续搜索更难优化,(2)软promt具有更大的表示能力。
十二、总结
在本文中,我们总结和分析了统计自然语言处理技术发展中的几种范式,并认为基于提示的学习是一种很有前途的新范式,它可能代表着我们看待自然语言处理方式的另一个重大变化。首先,论文希望此次调查能够帮助研究人员更有效、更全面地理解即时学习的范式,并把握其核心挑战,从而在这一领域取得更具科学意义的进展。此外,回顾§1中提出的四种NLP研究范式的总结,我们希望突出它们之间的共性和差异,使对这些范式的研究更加成熟,并可能提供催化剂,激励人们朝着下一个范式转变努力。
参考资料:
一文轻松入门Prompt(附代码)
GitHub:OpenPrompt,An Open-Source Framework for Prompt-learning
Prompt应用——信息抽取(NER & RE)任务
大模型Prompt Tuning技术分享
Prompt在中文分类few-shot场景中的尝试
prompt到底行不行
NAACL2022-Prompt相关论文&对Prompt的看法
NLP预训练语言模型新范式Prompt总结一:Pattern-Exploiting Training(PET)手动构建模版
prompt模板模式总结记录
论文阅读:Prompt统一NLP新范式Pre-train, Prompt, and Predict
近代自然语言处理技术发展的“第四范式”
NLP的四个范式
从4篇最新论文详解NLP新范式——Continuous Prompt
Prompt专栏-概述篇