图神经网络:dgl官方教程( 一 )
1.1 关于图的基本概念
1.2 图、节点和边
1.3 节点和边的特征
1.4 从外部源创建图
1.5 异构图
1.6 在GPU上使用DGLGraph
2.1 内置函数和消息传递API
2.2 编写高效的消息传递代码
2.3 在图的一部分上进行消息传递
2.4 在消息传递中使用边的权重
2.5 在异构图上进行消息传递
3.1 DGL NN模块的构造函数
3.2 编写DGL NN模块的forward函数
3.3 异构图上的GraphConv模块
4.1 DGLDataset类
4.2 下载原始数据(可选)
4.3 处理数据
4.4 保存和加载数据
4.5 使用ogb包导入OGB数据集
5.1 Node Classification/Regression
One of the most popular and widely adopted tasks for graph neural networks is node classification, where each node in the training/validation/test set is assigned a ground truth category from a set of predefined categories. Node regression is similar, where each node in the training/validation/test set is assigned a ground truth number.
节点分类是图神经网络最受欢迎和广泛采用的任务之一,其中训练/验证/测试集中的每个节点都从一组预定义的类别中分配一个ground truth类别。节点回归类似,训练/验证/测试集中的每个节点都被分配一个地面真值。
Overview
To classify nodes, graph neural network performs message passing discussed in Chapter 2: Message Passing to utilize the node’s own features, but also its neighboring node and edge features. Message passing can be repeated multiple rounds to incorporate information from larger range of neighborhood.
为了对节点进行分类,图神经网络通过第2章的消息传递来利用节点自身的特征,以及它的邻近节点和边缘特征。消息传递可以重复多次,以吸收来自更大范围的邻居的信息。
Writing neural network model
DGL provides a few built-in graph convolution modules that can perform one round of message passing. In this guide, we choose dgl.nn.pytorch.SAGEConv (also available in MXNet and Tensorflow), the graph convolution module for GraphSAGE.
Usually for deep learning models on graphs we need a multi-layer graph neural network, where we do multiple rounds of message passing. This can be achieved by stacking graph convolution modules as follows.
DGL提供了一些内置的图形卷积模块,可以执行一轮消息传递。在本指南中,我们选择dgl.nn.pytorch。SAGEConv(在MXNet和Tensorflow中也可用),GraphSAGE的图形卷积模块。
通常对于图上的深度学习模型,我们需要一个多层图神经网络,在那里我们做多轮的消息传递。这可以通过叠加图卷积模块实现,如下所示。
Note that you can use the model above for not only node classification, but also obtaining hidden node representations for other downstream tasks such as 5.2 Edge Classification/Regression, 5.3 Link Prediction, or 5.4 Graph Classification.
For a complete list of built-in graph convolution modules, please refer to dgl.nn.
For more details in how DGL neural network modules work and how to write a custom neural network module with message passing please refer to the example in Chapter 3: Building GNN Modules.
请注意,您不仅可以使用上面的模型进行节点分类,还可以为其他下游任务(如5.2边缘分类/回归、5.3链接预测或5.4图分类)获取隐藏的节点表示。
有关内置图卷积模块的完整列表,请参阅dgl.nn。
有关DGL神经网络模块如何工作以及如何编写带有消息传递的自定义神经网络模块的更多细节,请参阅第三章:构建GNN模块中的示例。
Training loop
Training on the full graph simply involves a forward propagation of the model defined above, and computing the loss by comparing the prediction against ground truth labels on the training nodes.
This section uses a DGL built-in dataset dgl.data.CiteseerGraphDataset to show a training loop. The node features and labels are stored on its graph instance, and the training-validation-test split are also stored on the graph as boolean masks. This is similar to what you have seen in Chapter 4: Graph Data Pipeline.
在全图上的训练只涉及上面定义的模型的前向传播,并通过与训练节点上的ground truth标签比较预测来计算损失。
本节使用DGL内置数据集DGL .data。CiteseerGraphDataset显示一个训练循环。节点特性和标签存储在它的图实例中,训练-验证-测试分割也作为布尔掩码存储在图中。这类似于您在第4章:图形数据管道中看到的内容。
Heterogeneous graph
If your graph is heterogeneous, you may want to gather message from neighbors along all edge types. You can use the module dgl.nn.pytorch.HeteroGraphConv (also available in MXNet and Tensorflow) to perform message passing on all edge types, then combining different graph convolution modules for each edge type.
The following code will define a heterogeneous graph convolution module that first performs a separate graph convolution on each edge type, then sums the message aggregations on each edge type as the final result for all node types.
如果您的图是异构的,您可能希望从所有边缘类型的邻居收集消息。你可以使用模块dgl.nn.pytorch。HeteroGraphConv(也可用于MXNet和Tensorflow)在所有边缘类型上执行消息传递,然后为每种边缘类型组合不同的图卷积模块。
下面的代码将定义一个异构图卷积模块,该模块首先对每个边缘类型执行单独的图卷积,然后对每个边缘类型的消息聚合求和,作为所有节点类型的最终结果。
5.2 Edge Classification/Regression
Sometimes you wish to predict the attributes on the edges of the graph, or even whether an edge exists or not between two given nodes. In that case, you would like to have an edge classification/regression model.
Here we generate a random graph for edge prediction as a demonstration.
有时,您希望预测图边缘上的属性,甚至希望预测两个给定节点之间是否存在一条边。在这种情况下,您希望有一个边缘分类/回归模型。
这里我们生成了一个随机图用于边缘预测作为演示。
Overview
From the previous section you have learned how to do node classification with a multilayer GNN. The same technique can be applied for computing a hidden representation of any node. The prediction on edges can then be derived from the representation of their incident nodes.
The most common case of computing the prediction on an edge is to express it as a parameterized function of the representation of its incident nodes, and optionally the features on the edge itself.
在上一节中,您已经了解了如何使用多层GNN进行节点分类。同样的技术可以应用于计算任何节点的隐藏表示。对边缘的预测可以从它们的关联节点的表示中得到。
计算边缘预测最常见的情况是将其表示为其关联节点的参数化函数,以及边缘本身的可选特征。
Model Implementation Difference from Node Classification
Assuming that you compute the node representation with the model from the previous section, you only need to write another component that computes the edge prediction with the apply_edges() method.
For instance, if you would like to compute a score for each edge for edge regression, the following code computes the dot product of incident node representations on each edge.
假设您使用前一节中的模型计算节点表示,您只需要编写另一个组件,使用apply_edges()方法计算边缘预测。
例如,如果您想为每条边计算一个边缘回归的分数,下面的代码计算每条边上事件节点表示的点积。
One can also write a prediction function that predicts a vector for each edge with an MLP. Such vector can be used in further downstream tasks, e.g. as logits of a categorical distribution.
我们也可以编写一个预测函数,用MLP为每条边预测一个向量。这种矢量可以用于进一步的下游任务,例如分类分布的logit。
Training loop
Given the node representation computation model and an edge predictor model, we can easily write a full-graph training loop where we compute the prediction on all edges.
The following example takes SAGE in the previous section as the node representation computation model and DotPredictor as an edge predictor model.
给定节点表示计算模型和边预测器模型,我们可以很容易地编写一个全图训练循环,在其中我们计算所有边的预测。
下面的例子以上一节的SAGE作为节点表示计算模型,DotPredictor作为边缘预测模型。
In this example, we also assume that the training/validation/test edge sets are identified by boolean masks on edges. This example also does not include early stopping and model saving.
在这个例子中,我们还假设训练/验证/测试边集是由边上的布尔掩码标识的。这个示例也不包括早期停止和模型保存。
Heterogeneous graph
Edge classification on heterogeneous graphs is not very different from that on homogeneous graphs. If you wish to perform edge classification on one edge type, you only need to compute the node representation for all node types, and predict on that edge type with apply_edges() method.
For example, to make DotProductPredictor work on one edge type of a heterogeneous graph, you only need to specify the edge type in apply_edges method.
异类图的边缘分类与同类图的边缘分类并没有太大的区别。如果希望对一种边缘类型执行边缘分类,则只需要计算所有节点类型的节点表示,并使用apply_edges()方法预测该边缘类型。
例如,要使DotProductPredictor工作在异构图的一种边缘类型上,你只需要在apply_edges方法中指定边缘类型。
Predicting Edge Type of an Existing Edge on a Heterogeneous Graph
5.3 Link Prediction
In some other settings you may want to predict whether an edge exists between two given nodes or not. Such model is called a link prediction model.
在其他一些设置中,您可能想要预测两个给定节点之间是否存在一条边。这种模型称为链路预测模型。
Overview
A GNN-based link prediction model represents the likelihood of connectivity between two nodes u and v as a function of h(L)u and h(L)v, their node representation computed from the multi-layer GNN.
基于GNN的链路预测模型将两个节点u和v之间的连接可能性表示为h(L)u和h(L)v的函数,它们的节点表示由多层GNN计算而来。
Training a link prediction model involves comparing the scores between nodes connected by an edge against the scores between an arbitrary pair of nodes. For example, given an edge connecting u and v, we encourage the score between node u and v to be higher than the score between node u and a sampled node v′ from an arbitrary noise distribution v′∼Pn(v). Such methodology is called negative sampling.
There are lots of loss functions that can achieve the behavior above if minimized. A non-exhaustive list include:
训练一个链接预测模型包括比较由一条边连接的节点与任意一对节点之间的得分。例如,给定一条连接u和v的边,我们建议节点u和v之间的得分要高于节点u和一个从任意噪声分布v’∼Pn(v)中采样的节点v’之间的得分。这种方法被称为负抽样。
如果最小化,有许多损失函数可以实现上述行为。一份非详尽的清单包括:
5.4 Graph Classification
Instead of a big single graph, sometimes one might have the data in the form of multiple graphs, for example a list of different types of communities of people. By characterizing the friendship among people in the same community by a graph, one can get a list of graphs to classify. In this scenario, a graph classification model could help identify the type of the community, i.e. to classify each graph based on the structure and overall information.
有时,数据不是一个大的单图,而是多个图的形式,例如不同类型的人员社区列表。通过用图表来描述同一社区中人们之间的友谊,我们可以得到一组可以分类的图表。在这种情况下,图分类模型可以帮助识别社区的类型,即根据结构和总体信息对每个图进行分类。
Overview
The major difference between graph classification and node classification or link prediction is that the prediction result characterizes the property of the entire input graph. One can perform the message passing over nodes/edges just like the previous tasks, but also needs to retrieve a graph-level representation.
The graph classification pipeline proceeds as follows:
**图分类与节点分类或链接预测的主要区别是预测结果表征了整个输入图的属性。**可以像前面的任务一样通过节点/边执行消息传递,但也需要检索图形级表示。
图分类流程如下:
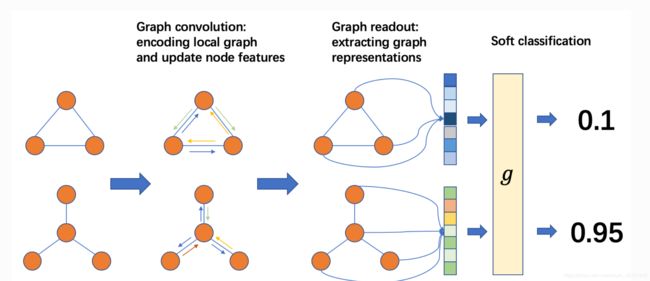
From left to right, the common practice is:
- Prepare a batch of graphs
- Perform message passing on the batched graphs to update node/edge features
- Aggregate node/edge features into graph-level representations
- Classify graphs based on graph-level representations
从左到右,常见的做法是:
- 准备一批图表
- 在批处理图形上执行消息传递,以更新节点/边缘特征
- 将节点/边缘特征聚合为图形级表示
- 根据图级表示分类图
Batch of Graphs
Usually a graph classification task trains on a lot of graphs, and it will be very inefficient to use only one graph at a time when training the model. Borrowing the idea of mini-batch training from common deep learning practice, one can build a batch of multiple graphs and send them together for one training iteration.
In DGL, one can build a single batched graph from a list of graphs. This batched graph can be simply used as a single large graph, with connected components corresponding to the original small graphs.
通常一个图分类任务是在大量的图上进行训练,训练模型时一次只使用一个图是非常低效的。从常见的深度学习实践中借鉴小批量训练的思想,我们可以构建一批多个图,并将它们一起发送,进行一次训练迭代。
在DGL中,可以从一组图构建单个批处理图。这个批处理图可以简单地用作单个的大型图,其中包含与原始小图对应的连接组件。

Graph Readout
Every graph in the data may have its unique structure, as well as its node and edge features. In order to make a single prediction, one usually aggregates and summarizes over the possibly abundant information. This type of operation is named readout. Common readout operations include summation, average, maximum or minimum over all node or edge features.
Given a graph g, one can define the average node feature readout as
数据中的每一个图都可能有其独特的结构,以及节点和边缘特征。为了做出单一的预测,人们通常会聚集和总结可能丰富的信息。这种类型的操作称为readout。常见的读出操作包括所有节点或边缘特征的求和、平均值、最大值或最小值。
给定一个图g,我们可以定义平均节点特征读出为

6.1 Training GNN for Node Classification with Neighborhood Sampling
To make your model been trained stochastically, you need to do the followings:
- Define a neighborhood sampler.
- Adapt your model for minibatch training.
- Modify your training loop.
The following sub-subsections address these steps one by one.
为了让你的模型经过随机训练,你需要做以下事情:
- 定义一个邻域采样器。
- 调整您的模型以适应小批量培训。
- 修改你的训练循环。
下面的子小节逐一介绍这些步骤。
Define a neighborhood sampler and data loader
DGL provides several neighborhood sampler classes that generates the computation dependencies needed for each layer given the nodes we wish to compute on.
The simplest neighborhood sampler is MultiLayerFullNeighborSampler which makes the node gather messages from all of its neighbors.
To use a sampler provided by DGL, one also need to combine it with NodeDataLoader, which iterates over a set of nodes in minibatches.
For example, the following code creates a PyTorch DataLoader that iterates over the training node ID array train_nids in batches, putting the list of generated blocks onto GPU.
DGL提供了几个邻域采样器类,根据我们希望计算的节点生成每个层所需的计算依赖关系。
最简单的邻居采样器是MultiLayerFullNeighborSampler,它使节点从所有邻居收集消息。
要使用DGL提供的采样器,还需要将其与NodeDataLoader组合使用,NodeDataLoader以小批量遍历一组节点。
例如,下面的代码创建了一个PyTorch数据加载器,它分批遍历训练节点ID数组train_nids,将生成的块列表放到GPU上。
6.2 Training GNN for Edge Classification with Neighborhood Sampling
6.3 Training GNN for Link Prediction with Neighborhood Sampling
6.4 Customizing Neighborhood Sampler
6.5 Implementing Custom GNN Module for Mini-batch Training
6.6 Exact Offline Inference on Large Graphs
7.1 Preprocessing for Distributed Training
7.2 Distributed APIs
7.3 Tools for launching distributed training/inference