关键词:
TF-IDF实现、TextRank、jieba、关键词提取
数据来源:
语料数据来自搜狐新闻2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据
数据处理参考前一篇文章
介绍:
介绍了文本关键词提取的原理,tfidf算法和TextRank算法
利用sklearn实现tfidf算法
手动python实现tfidf算法
使用jieba分词的tfidf算法和TextRank提取关键词
1.关键字提取:
关键词抽取就是从文本里面把跟这篇文档意义最相关的一些词抽取出来。这个可以追溯到文献检索初期,当时还不支持全文搜索的时候,关键词就可以作为搜索这篇论文的词语。因此,目前依然可以在论文中看到关键词这一项。
除了这些,关键词还可以在文本聚类、分类、自动摘要等领域中有着重要的作用。比如在聚类时将关键词相似的几篇文档看成一个团簇,可以大大提高聚类算法的收敛速度;从某天所有的新闻中提取出这些新闻的关键词,就可以大致了解那天发生了什么事情;或者将某段时间内几个人的微博拼成一篇长文本,然后抽取关键词就可以知道他们主要在讨论什么话题。
目前大多数领域无关的关键词抽取算法(领域无关算法的意思就是无论什么主题或者领域的文本都可以抽取关键词的算法)和它对应的库都是基于后者的。从逻辑上说,后者比前着在实际使用中更有意义。
从算法的角度来看,关键词抽取算法主要有两类:
- 有监督学习算法,将关键词抽取过程视为二分类问题,先抽取出候选词,然后对于每个候选词划定标签,要么是关键词,要么不是关键词,然后训练关键词抽取分类器。当新来一篇文档时,抽取出所有的候选词,然后利用训练好的关键词抽取分类器,对各个候选词进行分类,最终将标签为关键词的候选词作为关键词;
- 无监督学习算法,先抽取出候选词,然后对各个候选词进行打分,然后输出topK个分值最高的候选词作为关键词。根据打分的策略不同,有不同的算法,例如TF-IDF,TextRank等算法;
2.TF-IDF算法:
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
- TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
- TF是词频(Term Frequency):词频(TF)表示词条(关键字)在文本中出现的频率。
- 逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
- TF-IDF实际上是:TF *IDF。某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TF-IDF计算:
(1)计算词频

(2)计算逆文档频率
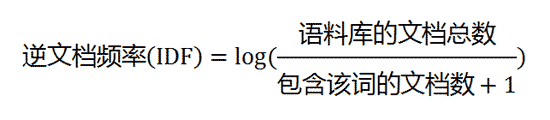
(3)计算TF-IDF
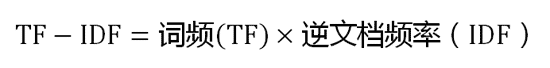
3.TextRank算法:
此种算法的一个重要特点是可以脱离语料库的背景,仅对单篇文档进行分析就可以提取该文档的关键词。基本思想来源于Google的PageRank算法。这种算法是1997年,Google创始人拉里.佩奇和谢尔盖.布林在构建早期的搜索系统原型时提出的一种链接分析算法,基本思想有两条:
1)链接数量。一个网页被越多的其他网页链接,说明这个网页越重要.
2)链接质量。一个网页被一个越高权值的网页链接,也能表明这个网页越重要.
TextRank 用于关键词提取的算法如下:
(1)把给定的文本 T 按照完整句子进行分割,即:T=[S1,S2,…,Sm]
(2)对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,其中 ti,j 是保留后的候选关键词。Si=[ti,1,ti,2,...,ti,n]
(3)构建候选关键词图 G = (V,E),其中 V 为节点集,由(2)生成的候选关键词组成,然后采用共现关系(Co-Occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K 的窗口中共现,K表示窗口大小,即最多共现 K 个单词。
(4)根据 TextRank 的公式,迭代传播各节点的权重,直至收敛。
(5)对节点权重进行倒序排序,从而得到最重要的 T 个单词,作为候选关键词。
(6)由(5)得到最重要的 T 个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。
TextRank & PageRank
如果一个网页被很多其他网页链接到的话说明这个网页比较重要,也就是PageRank值会相对较高
如果一个PageRank值很高的网页链接到一个其他的网页,那么被链接到的网页的PageRank值会相应地因此而提高
与TF-IDF需要在语料库上计算IDF(逆文档频率)不同,TextRank利用一篇文档内部的词语间的共现信息(语义)便可以抽取关键词。
二、利用sklearn实现tfidf算法
1.一个完整的例子
# coding:utf-8 import jieba import jieba.posseg as pseg import os import sys from sklearn import feature_extraction from sklearn.feature_extraction.text import TfidfTransformer from sklearn.feature_extraction.text import CountVectorizer corpus=["我 来到 北京 清华大学", "他 来到 了 网易 杭研 大厦", "小明 硕士 毕业 与 中国 科学院", "我 爱 北京 天安门"] vectorizer=CountVectorizer() #该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频 transformer=TfidfTransformer() #该类会统计每个词语的tf-idf权值 X=vectorizer.fit_transform(corpus) #将文本转为词频矩阵 tfidf=transformer.fit_transform(X) #计算tf-idf, word=vectorizer.get_feature_names() #获取词袋模型中的所有词语 weight=tfidf.toarray() #将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重 for i in range(len(weight)): #打印每类文本的tf-idf词语权重 print("-------这里输出第",i,u"类文本的词语tf-idf权重------" ) #for j in range(len(word)): print(list(zip(word,weight[i])))
控制台输出:
-------这里输出第 0 类文本的词语tf-idf权重------ [('中国', 0.0), ('北京', 0.5264054336099155), ('大厦', 0.0), ('天安门', 0.0), ('小明', 0.0), ('来到', 0.5264054336099155), ('杭研', 0.0), ('毕业', 0.0), ('清华大学', 0.6676785446095399), ('硕士', 0.0), ('科学院', 0.0), ('网易', 0.0)] -------这里输出第 1 类文本的词语tf-idf权重------ [('中国', 0.0), ('北京', 0.0), ('大厦', 0.5254727492640658), ('天安门', 0.0), ('小明', 0.0), ('来到', 0.41428875116588965), ('杭研', 0.5254727492640658), ('毕业', 0.0), ('清华大学', 0.0), ('硕士', 0.0), ('科学院', 0.0), ('网易', 0.5254727492640658)] -------这里输出第 2 类文本的词语tf-idf权重------ [('中国', 0.4472135954999579), ('北京', 0.0), ('大厦', 0.0), ('天安门', 0.0), ('小明', 0.4472135954999579), ('来到', 0.0), ('杭研', 0.0), ('毕业', 0.4472135954999579), ('清华大学', 0.0), ('硕士', 0.4472135954999579), ('科学院', 0.4472135954999579), ('网易', 0.0)] -------这里输出第 3 类文本的词语tf-idf权重------ [('中国', 0.0), ('北京', 0.6191302964899972), ('大厦', 0.0), ('天安门', 0.7852882757103967), ('小明', 0.0), ('来到', 0.0), ('杭研', 0.0), ('毕业', 0.0), ('清华大学', 0.0), ('硕士', 0.0), ('科学院', 0.0), ('网易', 0.0)]
2.根据语料库统计idf(每个词语的逆文档频率),并存持久化存储到文件中,以便下次输入一篇文档即可返回相应关键词
#-*-coding:utf-8-*- import numpy as np import math from sklearn.feature_extraction.text import CountVectorizer _trainText=[] with open('sohu_train.txt', encoding='utf-8') as trainText: for line in trainText: id,catgre,body= line.split('^_^') #print id,catgre _trainText.append(body) # for doc in _trainText[:10]: # print(doc) #将文本中的词语转换为词频矩阵 vectorizer = CountVectorizer() #计算个词语出现的次数 X = vectorizer.fit_transform(_trainText[:10000]) words = vectorizer.get_feature_names() X_mat=X.toarray() doc_num=X.shape[0] # print(X.shape[0]) # print(X.toarray()[:,1]) # doc_num=len(X_mat[:,1]) print(X.shape) fw=open('idf.txt', 'w', encoding='utf-8') for index in range(len(words)): # print(np.sign(X_mat[:,index]),X_mat[:,index]) idf=math.log(doc_num/(sum(np.sign(X_mat[:,index]))+1)) fw.write(words[index]+' '+str(idf)+'\n') # print(words[index],math.log(doc_num/(sum(np.sign(X_mat[:,index]))+1))) fw.close() print('procesing completed')
问题:词频矩阵非常稀疏矩阵,矩阵太大(文档数量×词汇数量),实际计算中文档有59万余条,出现内存错误memoryerror,可以将语料分成多片分别进行计算,但这样效率并不高,下面手动进行词频统计
三、用python3实现tfidf提取关键词
手动计算词频,计算tfidf值
#利用搜狐新闻语料库计算每个词语的idf值, #-*-coding:utf-8-*- import numpy as np import math from collections import defaultdict doc_num=0 doc_frequency=defaultdict(int) with open('sohu_train.txt', encoding='utf-8') as trainText: for line in trainText: id,catgre,body= line.split('^_^') # if doc_num>100000:break doc_num+=1 for word in set(body.split(' ')): word=word.replace('\n','').strip() # if word in stopword :continue if word =='' or word =='' :continue doc_frequency[word]+=1 fw=open('idf-1.txt', 'w', encoding='utf-8') for word in doc_frequency: idf=math.log(doc_num/(doc_frequency[word]+1)) fw.write(word+' '+str(idf)+'\n') print(word,doc_frequency[word]) fw.close() print('procesing completed') #加载已经训练好的idf值,计算部分文章的tfidf,返回相应关键词 idf_dict=defaultdict(int) with open('idf-1.txt', encoding='utf-8') as idf_dict_text: for line in idf_dict_text: word,value= line.split(' ') idf_dict[word]=float(value) doc_num=0 with open('sohu_train.txt', encoding='utf-8') as trainText: for line in trainText: id,catgre,body= line.split('^_^') #仅抽取前5篇文档的关键词 if doc_num>5:break else:doc_num+=1 word_num=0 word_frequency=defaultdict(int) for word in body.split(' '): #每篇文档中词频统计 word=word.replace('\n','').strip() if word =='' or word =='' :continue word_frequency[word]+=1 word_num+=1 for word in word_frequency: #计算当前文章中每个词的tfidf值 # print(idf_dict[word],type(idf_dict[word])) tfidf=idf_dict[word]*word_frequency[word]/word_num word_frequency[word]=tfidf word_sorted=sorted(word_frequency.items(),key=lambda x:x[1],reverse=True) print('document:',body.strip().replace(' ','')) print('keywords:',word_sorted[:5])
输出前5篇文档的关键词:
document: 主题:Re:包子老公终于早饭了主题:Re:包子老公终于早饭了 keywords: [('包子', 0.9596168091464351), ('早饭', 0.9041355597752955), ('Re', 0.8966839785996794), ('老公', 0.6378780519245452), ('主题', 0.474942714460621)] document: 主题:不管孩子多少,只要有一对无耻的儿子媳妇,老人就完蛋这次回老家,去看姑姑。姑姑老的不成样子,身体极差,姑父身体还行,就是因为脑袋做过手术,说话有点稀里糊涂的。姑姑有4个孩子,有三个生活非常不错。但有一个儿子,生活很不好,这个儿子和我还是同学。特别是这个儿子的媳妇,那是超级的愣货,我姑姑以前那么要强的人,现在被这个儿子和媳妇逼的无路可走。 keywords: [('姑姑', 0.32601072973252054), ('儿子', 0.23452820867879176), ('媳妇', 0.18669451156212183), ('姑父', 0.0983996538992101), ('无路可走', 0.09541412728971811)] document: 主题:[原创]家长自检:你的孩子有这些错误的饮食习惯吗?最近一直马不停蹄的忙着中心和妇联一起主办的公益测评活动,虽然每天都很忙很紧张但是对于我还是有收获的,希望对家长和孩子们都是有收获的。因为下午还要出发,所以就大概给宝妈们总结一下我这段时间和孩子家长的闲聊中总结的一些儿童饮食错误:问题 1 :用方便面代替正餐有的家长说早上没有时间给孩子做早餐就用方便面 给孩子当早餐,以为加上蔬菜和鸡蛋就可以成为一份“营养”的早餐。这样的认为是错误的,方便面在营养师的眼中是最不营养的东西。它以面粉为主,经过高温油炸,蛋白质、维生素、矿物质均严重不足,营养价值较低,还常常存在脂肪氧化的问题,热量非常高,常常食用方便面会导致营养不良。问题 2 :多吃营养滋补品有的家长说孩子太瘦,挑食,既然孩子吃得少那就给孩子吃醉营养的滋补品这样就能弥补孩子缺失的营养了,错误。孩子的生活饮食习惯是家长一定要孩子养成的,而且孩子生长发育所需要的热能、蛋白质、维生素和矿物质主要也完全可以通过一日三餐获得的。各种滋补营养品的摄入量本来就 很小,其中对身体真正有益的成分仅是微量,有些甚至具有副作用,增加孩子提前发育的风险。问题 3 :用乳饮料代替牛奶,用果汁饮料代替水果很多家长问我 “ 钙奶、果奶 ” 之类的乳饮料代替牛奶 是不是会更好更营养。殊不知,两者之间有着天壤之别,饮料根本无法代替牛奶和水果带给孩子的营养和健康。在以前的帖子里我也具体和大家说过,这里就不再仔细说了。问题 4 :用甜饮料解渴,餐前必 喝饮料现在的孩子很多都和我是同一时期的人, 80 后习惯饮料当水解渴的习惯其实不好,现在升级做爸爸妈妈的应该不要把这个习惯再传给我们的孩子。为了自己也为了孩子少喝饮料多喝水。甜饮料中 含糖达 10% 以上,饮后具有饱腹感,妨碍孩子正餐时的食欲。若要解渴,最好饮用白开水,它不仅容易吸收,而且可以帮助身体排除废物,不增加肾脏的负担。现在我们吃的多数都是“精米”“精面”其实长期进食精细食物并不好,不仅会因减少 B 族维生素的摄入而影响神经系统发育,还有可能因为铬元素缺乏 “ 株连 ” 视力。铬含量不足会使胰岛素的活性减退,调节血糖的能力下降,致使食物中的糖分不能正常代谢而滞留于血液中,导致眼睛屈光度改变,最终造成近视。适当给孩子吃点粗粮其实是有好处的。 keywords: [('孩子', 0.14306680068891997), ('饮料', 0.07809347155812614), ('营养', 0.07489176669532517), ('家长', 0.0663471334581201), ('方便面', 0.05927245295450419)] document: 创建新论坛 keywords: [('创建', 1.9655444474558943), ('论坛', 1.573322421854069), ('新', 0.8736738323593722)] document: 羽西当归透白莹润精华液产品名称:规格及价格:30ml/300 元羽西当归透白莹润精华液蕴含精纯当归素,它具有强力抗氧化功效和完全不粘配方,有效减退黯黄的同时抑制酪氨酸酶的活性,有 效美白肌肤。同时又拥 有晶莹凝露触感,使用感舒适。高浓度当归循采净白精萃有效净肤排浊,配合精纯乙基维生素C,有效隐褪黯黄,由内绽放纯净明亮。肌肤日渐透白莹润。使用说明:每日早晚在调理液后使用,之后进行当归透白日常护肤。产品特点:"当归循采净白精萃"有效净肤排浊,由内焕发匀白透润。适合各种肌肤类型 每日早晚在调理液后使用,之后进行当透白日常护肤请直立放置。一款根据中国的环境状况,为中国女性特殊的色素体系和美白需求度身定做的产品。羽西研究发现,中国女性的黑色素细胞树突组织更长,因此黑色素传导更易、更快、更多,使中国女性比其他国家女性更易变黑,羽西首度在美白产品中使用具有广谱抗氧化作用的阿魏酸,结合天然药用植物成分牡丹皮和维他命CG,帮助减缓黑色素传导,从根源谒制黑色素生成。精华露首创生态美白系统,屏蔽大环境伤害,营造肌肤美白小环境,不只是减褪色斑,更从根源抑制黑色素。产品功效肌肤只在有血气充盈的情况下才能白皙红润,要想肌肤明净剔透,白皙健康,就要活血养血,使血流顺畅,血管恢复到健康状态。养血圣品--当归其味甘而重,故专能补血,其气轻而辛,故又能行血,补中有动,行中有补,诚血中之气药,亦血中之圣药也。--《本草正》羽西首创气血养白,中国系美白秘诀。养血圣品--当归:排浊养血双管齐下,祛 黄呈白,令肌肤通透粉润。精选自1800余种药材,养血圣品当归独占鳌头,高科技萃取当归循采净白精粹。提升150%净肤排浊功效,抗氧化力2.6倍于维生素CG,抗氧化力10倍于桑叶提取物。 keywords: [('当归', 0.1866405240746113), ('羽西', 0.1265844668824549), ('排浊', 0.11178060976116114), ('黑色素', 0.09857243570844379), ('养血', 0.09812099637850542)] document: 我可能感兴趣的试用常见问题Q:为什么我提交不了试用申请 A:试用申请必须同时满足以下全 部条件:1、必须是搜狐试用频道 的注册会员;2、个人资料完成度 100%;3、非试用中心黑名单用 户;Q:为什么我的试用报告不通过 A:试用报告提交后需经过编辑审核,合格的试用报告字数应该在100字以上,并且附有产品图及试用体验过程图。试用报告字数过少或抄袭,都会被编辑审核为不通过;Q:什么是试用报告? A:试用报告是收到试用产品后,按照时间规定在试用平台提交的一份关于产品使用的心得和体会。优秀的试用心得必须是图文并茂; keywords: [('试用', 0.7254374717517048), ('报告', 0.15653977634270186), ('Q', 0.12711201927875215), ('字数', 0.1132682062893399), ('提交', 0.11185601553931523)]
四、利用jieba中的tfidf提取关键词,并自定义idf词典
jieba分词中已经对tfidf进行了实现,并预先统计出了汉语中每个词的逆文档频率(idf),存储目录为C:\Python37\Lib\site-packages\jieba\analyse\idf.txt
jieba默认使用以上路径的idf词典,并计算输入文档的tf(文本词频)值,进而求出tfidf提取关键词
jieba允许用户使用set_idf_path方法自定义idf词典
本文首先使用默认的idf词典提取测试文档的关键词,然后使用set_idf_path将idf词典设置为上一节中训练的idf-1.txt再提取关键字,并进行前后对比
PS D:\> python3 Python 3.7.1 (v3.7.1:260ec2c36a, Oct 20 2018, 14:57:15) [MSC v.1915 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> from jieba import analyse >>> tfidf = analyse.extract_tags >>> text ="""关键词抽取就是从文本里面把跟这篇文档意义最相关的一些词抽取出来。这个可以追溯到文献检索初期,当时还不支持全文搜索的时候,关键词就可以作为搜索这篇论文的词语。因此,目前依然可以在论文中看到关键词这一项。 ... 除了这些,关键词还可以在文本聚类、分类、自动摘要等领域中有着重要的作用。比如在聚类时将关键词相似的几篇文档看成一个团簇,可以大大提高聚类算法的收敛速度;从某天所有的新闻中提取 出这些新闻的关键词,就可以大致了解那天发生了什么事情;或者将某段时间内几个人的微博拼成一篇长文本,然后抽取关键词就可以知道他们主要在讨论什么话题。 ... 总之,关键词就是最能够反映出文本主题或者意思的词语。但是网络上写文章的人不会像写论文那样告诉你本文的关键词是什么,这个时候就需要利用计算机自动抽取出关键词,算法的好坏直接决定 了后续步骤的效果。""" >>> >>> keywords = tfidf(text) #使用结巴默认的idf文件(C:\Python37\Lib\site-packages\jieba\analyse\idf.txt) Building prefix dict from the default dictionary ... Loading model from cache C:\Users\zh\AppData\Local\Temp\jieba.cache Loading model cost 0.878 seconds. Prefix dict has been built succesfully. >>> print(keywords) #采用默认idf文件提取的关键词 ['关键词', '抽取', '聚类', '文本', '可以', '论文', '文档', '词语', '这篇', '算法', '搜索', '自动', '微博', '新闻', '文献检索', '某天', '什么', '利用计算机', '拼成', '或者'] >>> >>> analyse.set_idf_path('D:/idf-1.txt') #使用自定义idf文件,由搜狐新闻预料库训练得到 >>> keywords = tfidf(text) >>> print(keywords) ['关键词', '聚类', '抽取', '论文', '文本', '词语', '可以', '文档', '算法', '这篇', '一个团', '什么', '拼成', '几篇', '写文章', '利用计算机', '某天', '文献检索', '新闻', '看成'] >>>
五、TextRank算法提取关键字
TextRank算法提取关键字采用了PageRank算法的思想,仅文章本身便可以提取关键词
算法原理: http://www.cnblogs.com/rubinorth/p/5799848.html
TextRank算法源码解析:https://www.cnblogs.com/zhbzz2007/p/6177832.html
from jieba import analyse textrank = analyse.textrank #引入jieba中的TextRank text="""关键词抽取就是从文本里面把跟这篇文档意义最相关的一些词抽取出来。这个可以追溯到文献检索初期,当时还不支持全文搜索的时候,关键词就可以作为搜索这篇论文的词语。因此,目前依然可以在论文中看到关键词这一项。 除了这些,关键词还可以在文本聚类、分类、自动摘要等领域中有着重要的作用。比如在聚类时将关键词相似的几篇文档看成一个团簇,可以大大提高聚类算法的收敛速度;从某天所有的新闻中提取出这些新闻的关键词,就可以大致了解那天发生了什么事情;或者将某段时间内几个人的微博拼成一篇长文本,然后抽取关键词就可以知道他们主要在讨论什么话题。 总之,关键词就是最能够反映出文本主题或者意思的词语。但是网络上写文章的人不会像写论文那样告诉你本文的关键词是什么,这个时候就需要利用计算机自动抽取出关键词,算法的好坏直接决定了后续步骤的效果。""" keywords = textrank(text) print(keywords)
输出:
['关键词', '文本', '抽取', '聚类', '自动', '算法', '发生', '时候', '搜索', '文档', '主题', '后续', '写文章', '利用计算机', '决定', '相似', '词语', '好坏', '摘要', '能够']
参考:
阮一峰tf-idf讲解:http://www.ruanyifeng.com/blog/2013/03/tf-idf.html
结巴分词tf-idf和textrank源码解析:https://www.cnblogs.com/zhbzz2007/p/6177832.html
结巴分词github:https://github.com/fxsjy/jieba
jieba分词及TF-IDF和TextRank算法提取关键字:https://blog.csdn.net/bozhanggu2239/article/details/80157305
NLP之关键词提取(jieba):https://blog.csdn.net/qq_38923076/article/details/81630442
关键词提取算法TextRank https://www.cnblogs.com/en-heng/p/6626210.html
PageRank算法--从原理到实现: http://www.cnblogs.com/rubinorth/p/5799848.html
PageRank wiki: https://de.wikipedia.org/wiki/PageRank