课程笔记-三维点云处理01 ——Introduction and Basic Algorithms
课程笔记-三维点云处理01 ——Introduction and Basic Algorithms
本系列笔记是对深蓝学院所开设的课程:《三维点云处理》的笔记
课程每周更新,我也会努力将每周的知识点进行总结,并且整理成笔记发上来,欢迎各位多多交流&批评指正!!
本文主要为课程第一章的笔记!
课程链接:
三维点云处理——深蓝学院
正式内容:
####################################################
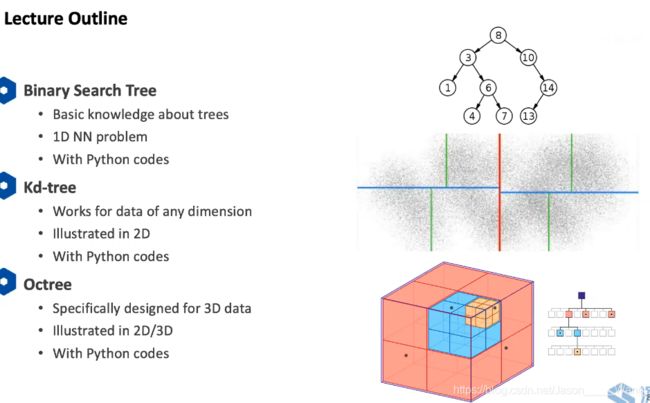
Course outline and prerequisite
####课程内容介绍
本系列课主要介绍三维点云 处理 及应用
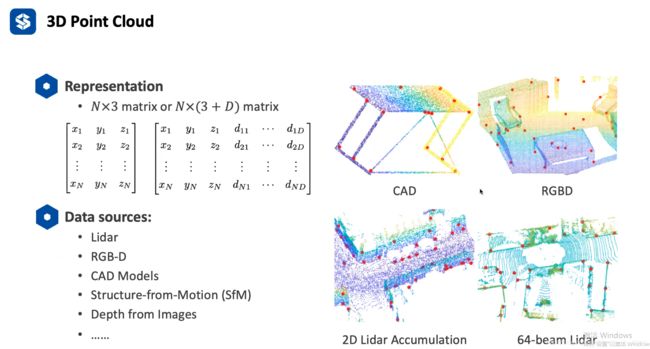
三维点云是一系列的三维点位置坐标
三维点云获取形式:
lidar
RGBD
CAD模型
SfM(交叉矩阵结构)(Structure from motion) 是一种三维重建的方法
等等
三维点云应用
应用比较广泛,因为输入信息比较简单。
应用领域:
机器人领域
自动驾驶领域
3D模型重构
人脸识别(faceID)
等等
三维空间表示方法
除点云外,三维空间的表示方法主要还有以下几种,各自有优缺点:
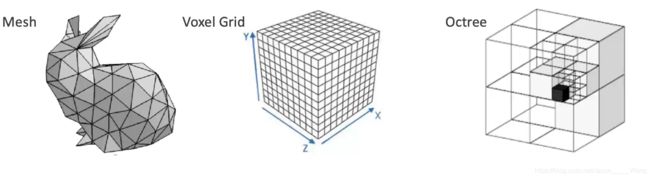
mesh是一系列的三角面片组成
体素占用内存过大
二叉树(octree)可以解决占用内存过大的缺点,但是表述起来相对困难一些

与上面几种表述方式相比,点云只是一个矩阵,表述起来非常简单。因此这些年来被广泛沿用
点云应用的困难
三维点云在应用上也有很多困难:
- 密度 点云一般在近处的物体很稠密,远处的物体很稀疏,使得远处的物体很难被识别
- 不规则 很难找到相邻点之间的规律(不想图像排列那么规范)
- 纹理信息 由于没有纹理信息,只有位置信息,所以会发成误识别
(个人理解:只能检测有没有 不能检测是什么) - 无序性 (不利于深度学习)
- 旋转不变性 (深度学习)
课程设置
传统方法+深度学习方法

传统方法:知道步骤,门槛较高
深度学习:简单,好用,黑盒子
传统方法 vs 深度学习

课程设置上,前四节课是传统方法,后四节课是偏向深度学习和slam应用的:
课程设置:理论讲解和实践讲解 五五开

参考 书籍&课程&课程工具

作业安排
每周都有作业,有必做和选做,选做的难度相对较高
期中和期末有大作业
期中: KITTI数据集地面提取
期末:基于点云的目标检测问题
PCA and Kernel PCA
PCA
PCA:主成分分析
主成分分析的概念和应用
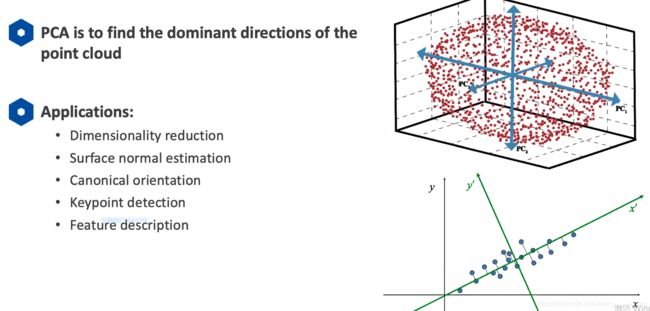
应用:
Dimensionality reduction
Surface normal estimatior
Canonical orientation
Keypoint detection
Feature description
降维
表面法向估计器
规范定向
关键点检测
功能描述
主要是用于点云分类
一些基础的数学概念
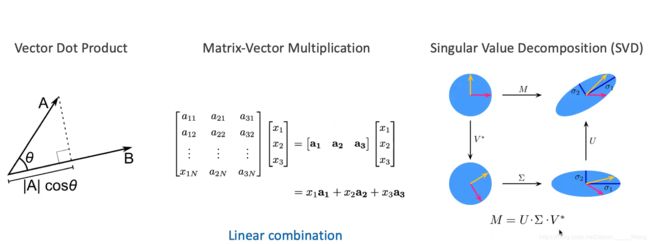
股定理:

瑞利商:

PCA原理

输入:xi…
输出:聚类过后的xi的聚类集合 zk
PCA使用方法

PCA应用
一个非常常见且重要的应用:降维
将高维数据转化为低维数据,并且尽可能的保留特征

可以用先主成分分析再聚类处理分类问题 比较著名的 eigenfaces: 不用神经网络就能做人脸识别·
Kernal PCA
普通的PCA事实上是一个线性的PCA,事实上也是对矩阵的线性组合
但是点云数据很可能不是线性的,比如:

此时,如果还用线性的话就不行了,需要将其放到更高的维度去做处理
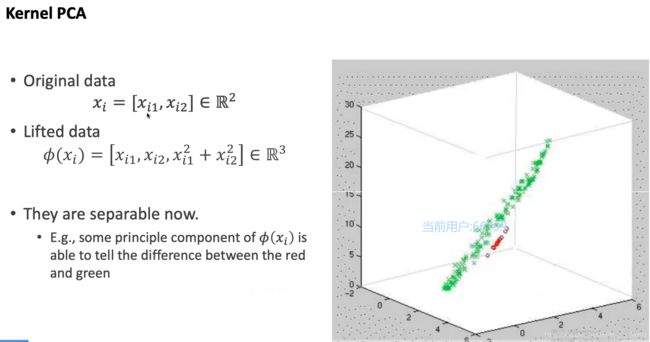
提升到三维空间中,就可以非常好的去做理解和处理了
这一个升维聚类的方法就被称为kernal PCA (核 PCA)
K-PCA的方法

数学证明:




一通操作,一个都没看懂。。。
以后慢慢再看吧
总之,最后得出了结论
核函数的选择
有多重核函数可以选择,但是通常要看应用的场景

K_PCA的步骤
- 选择一个核函数k(xi,yj),并计算出Gram Matrix K(i,j)
- 对 K做一个正态化处理(为了使函数在高位度内的平均值也为0)
- 求解高纬度下的特征值和特征向量
- 对解出来的α做一个正态化处理
- 完成以上步骤后,可以把任何一个数据点投影到主向量上,得到投影后的数据

示例1: 圆圈投影成圆锥
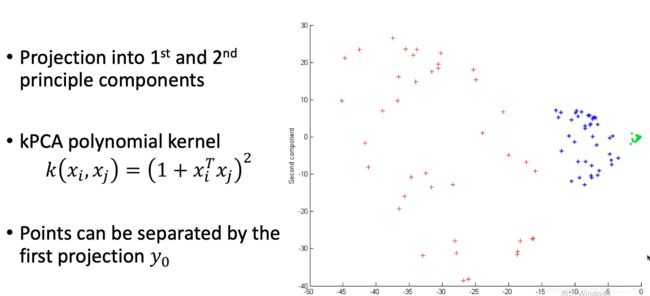
示例2:使用高斯核函数
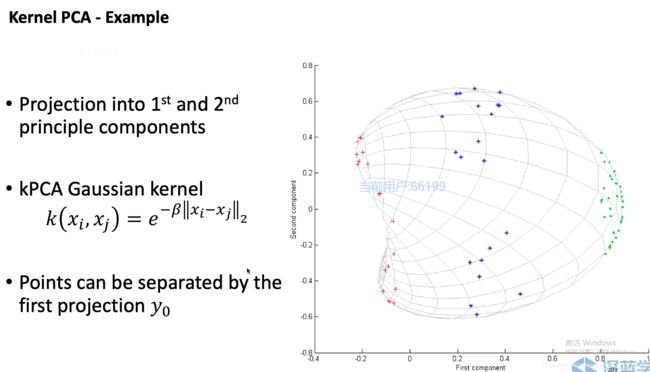
同时,运用KPCA可以将高维的运算转化为低维度的核函数
Smoothing, Filtering and Downsampling
surface normal
作为上方K-PCA的应用:
.
如何找点云里面每一个点的法向量
法向量

对于曲面、体 来说 法向量可以是垂直于他所切平面的向量
对于点云来说,寻找法向量找的是最没用的向量
所谓最没用的点,言外之意就是数据投影在这些向量上面数据为0,即最不显著的向量
曲率为最小特征值除特征值的和
点云法向量定义

找一个点云分布上最大的平面,然后根据平面方向确定这一组点云的法向量
其中,上图中点c作为这一系列平面的中心点存在。


如何确定c: 找到这一组点中和其他点平均距离最小的点值
正态化分布 这些点到c的距离
法向量求解时实际问题
实际求解法向量时,可能会遇到很多问题,比如点没有按维度分布、非常稀疏等等
即,这些点是需要做噪声处理的

大概有上述四种方法可以对于这个问题进行简化,目前先讲一下第二种方法:
带加权的正态估计
weighted normal estimation

也可以用深度学习方法进行法向量估计:

fliters 滤波
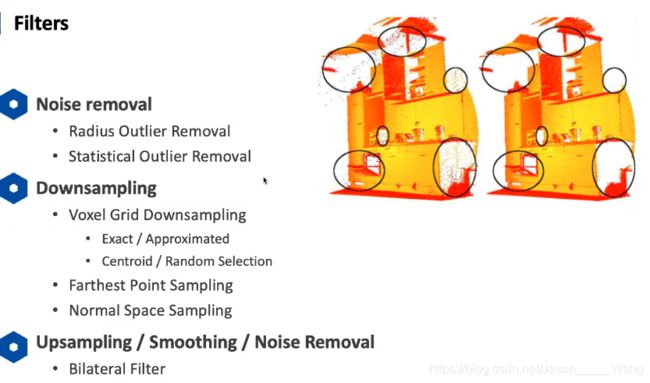
滤波是一个很宽泛的概念,如噪声去除;降采样;上采样;平滑等操作
都可以统称为滤波
降采样:变稀疏
上采样:在稀疏的点云中添加一些点使其变稠密(比如双边滤波方法)
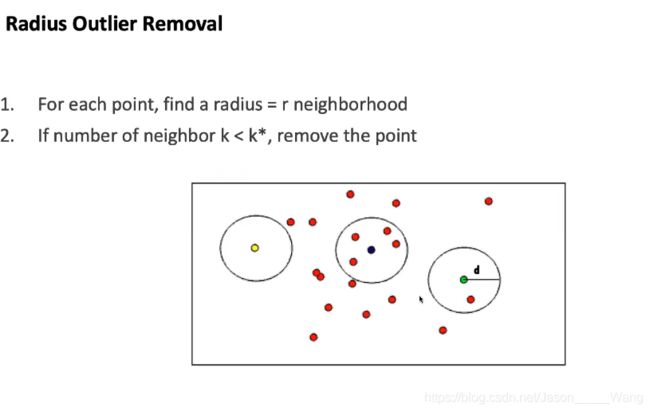
噪声去除
规定一个点的周围一定范围为其邻域,在领域内点的个数如果少于一定值则将该点去除(过滤掉)
统计版本的outlier removal
同样对领域内的点做一个邻域规定,然后根据平均的距离求一下分布,并且根据3σ去做一个筛选

降采样 voxel grid downsampling
使得需要的算力更少,是一种让数据更有代表性的方法

一般可以有几种方法,一个是以范围内的一个点代替所有点,另一个是选取方框内点的平均值,如下图

降采样的流程:

先定义一个大框,把所有点都放进去
然后定义降采样的分辨率,按照体积划分网格
然后计算每哪一个点属于哪一个格子
对每个点进行排序,然后开始进行采样(可以选择采样策略)
最后保留选择的点,完成采样
注意1:当空间很大的时候没,注意不要内存溢出
注意2:排序的时候要用小于做排序,而不能是小于等于(c++中)
降采样遇到的问题:

数据很大,应该怎么处理?
因为空间很大,所以很多voxel事实上里面是没有点的,所以我们不需要根据容器来划分点,应该根据点去装容器,然后把空的容器去掉
可以用 hash table,方法如下:

前四步都一样,第五步开始定义一个哈希函数,使得每一个点都能映射到一个函数中;
但是事实上,可能会出现冲突:

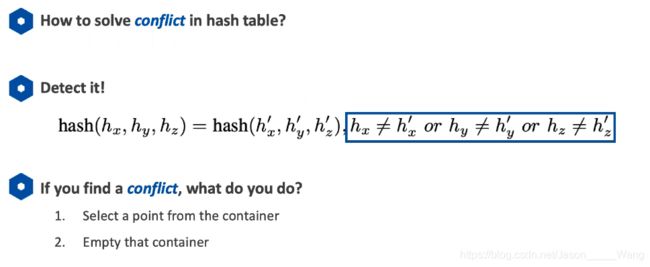
出现冲突的时候,需要释放冲突,新来的点占坑,将原有的点重新回到序列中
这个方法跟普通的降采样相比,可以更快。
其他降采样方法:(FPS、NSS)
FPS方法
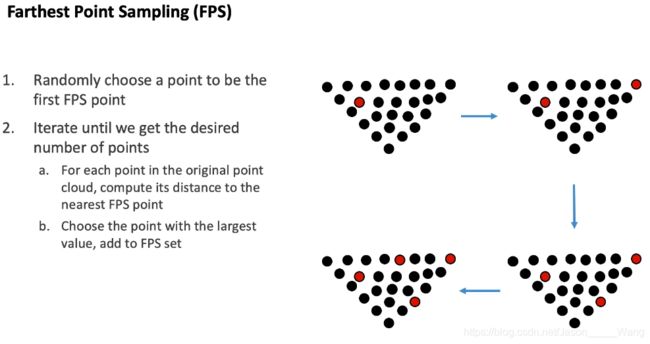
核心思想是,找一系列点,让这些点的平均距离越远越好
过程:一个一个寻找,每次寻找距离最远的点
作用:可以去除掉一些很稠密的点,让其变得更加稀疏。
NSS方法
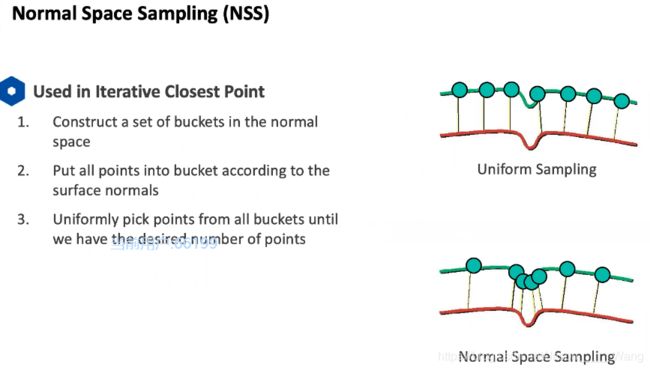
可以增加一些特征部分的采样点选取的稠密性,以此来保证特征(如上图中的一个弯)
经常应用于点云的对齐
深度学习方法
如:learning to sample
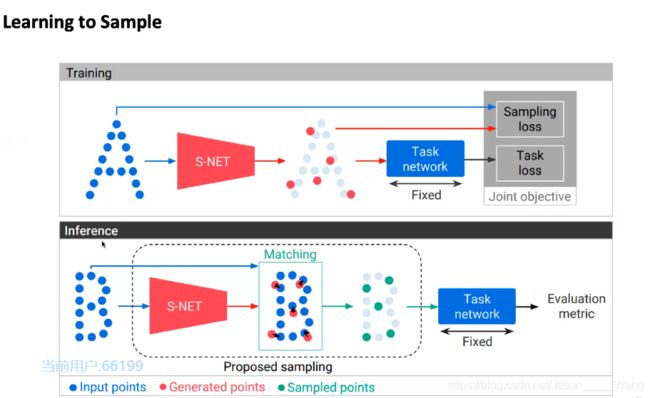
不是基于几何空间的降采样,而是基于语义的降采样
这样的话可以使得有特征的点被保留
即降采样前后,点云还是可以保留原来的语义标签

上采样 :bilateral filter
例子:希望对一个亭子做模糊
可以用高斯和 去做模糊 用他周围的xiangg
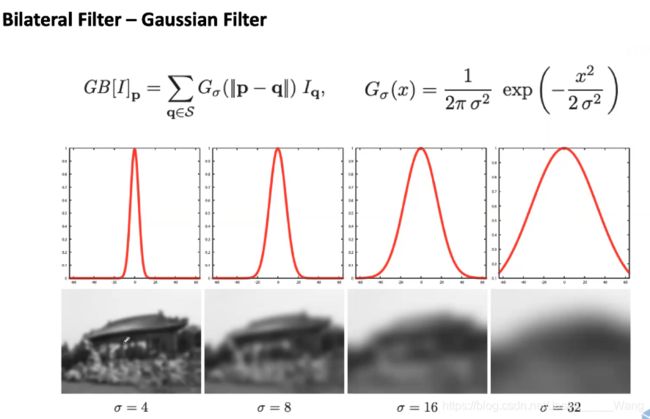
这个效果肯定是不理想的,因为我们想虽然亭子模糊,但是边缘特征要保留

就可以通过 bilateral filter 进行保留
意思是通过两个高斯核进行处理

HW 作业


下节课预告
点云的邻近搜索 三种方法