课程笔记-三维点云处理02 ——Nearest Neighbor Problem
课程笔记-三维点云处理02 ——Nearest Neighbor Problem
本系列笔记是对深蓝学院所开设的课程:《三维点云处理》的笔记
课程每周更新,我也会努力将每周的知识点进行总结,并且整理成笔记发上来,欢迎各位多多交流&批评指正!!
本文主要为课程第二章的笔记!
课程链接:
三维点云处理——深蓝学院
目录
正式内容:
####################################################
最邻近问题(NN problems)
本节课主要讲最邻近问题(Nearest Neighbor Problem)
用来找一个点离他比较近的点
处理的主要方法一个是KD树,一个是八叉树,本节课主要就是讲这两个方面,但是讲这两个方面之前还会讲一下二叉树
方法概述
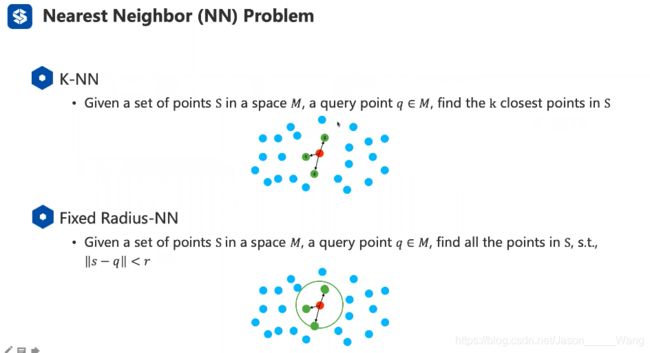
一般常见的两种方法就是K-NN 和R-NN
如上图所示 一个是根据距离排序,另一个是给定区域内搜索 是两种不同的思路
NN问题的重要性

对于点云处理来说,最邻近问题是一个基本且重要的问题,因为点云的特征信息就储存在点云的位置信息中,所以这个问题是非常基本的且常用的。
目前开源的库有很多,但是库里面集成的最临近算法都不够快(不知道为什么)
NN问题对于处理点云的困难点

主要有以下原因:
- 点云不像图像像素,是有规则排列的,具有无序性
- 点云存在在三维空间坐标中,比二维的要高,处理计算量要大一个数量级
- 按照网格化来划分的话,点云会存在很多空白的网格,而且处理起来效率很低
- 算法事实上运行起来非常大,比较吃力。
本节课结构
- 二叉树
- KD树
- 八叉树(专门为3D空间结构设计(因为2的3次方是8)) 相比于KD树更加适合三维
算法的核心思想:空间分割

space partition 空间分割是这三个算法的核心思想
比较直观的理解,寻找一个点的临近点时,肯定不能漫无目的的搜索,而是要首先在他的周围进行寻找。 这就是空间分割的原理
K-NN问题 :就是找他最近的K个点的意思
worst distance: 就是目前查找到的最远的点。 也就是说,如果查找的是K-NN问题的话,如果已知有K个点了,且其中最远的点的距离为x,那么这个x就是 worst distance,也就是说,不用在worst distance以外查找,只需要在这个距离里面查找就行了(因为在这个距离外面就算找到了也是没有意义的)
核心任务提炼
- 怎样对空间进行分割
- 如何去判断以及跳过搜索空间
- 如何去判断何时停止搜索
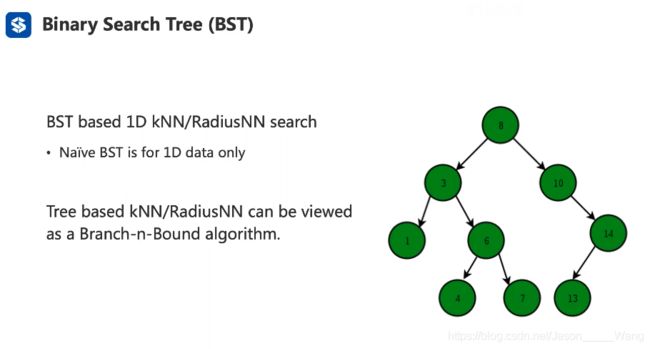
Binary Search Tree
认识二叉树
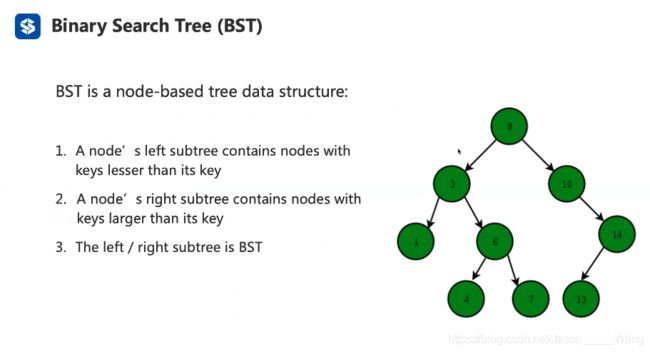
二叉树就是一个数分两个叉,跟两个数建立联系
但是这种联系是有规律的:
-
一个二叉树节点有且最多有两个分支
-
在划分分支的时候,小的放左边,大的放右边
二叉树早在计算机科学的开端就已经被提出使用了(是计算机一些很基础的数据结构)
很多算法岗在找工作的时候也会被问到 怎么搜索或遍历一个二叉树
二叉树定义
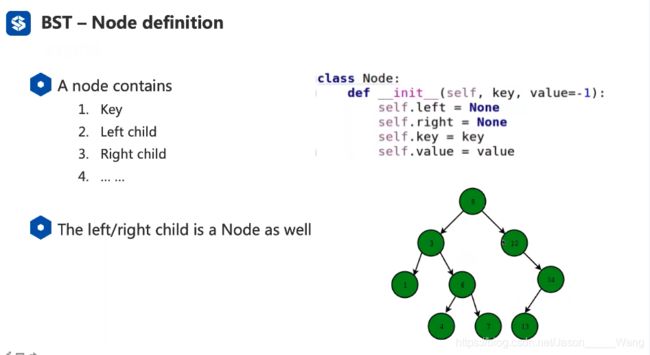 一个二叉树由三个部分组成:左边界点 右边节点 储存值 key(储存一些比如源文件路径之类的信息)
一个二叉树由三个部分组成:左边界点 右边节点 储存值 key(储存一些比如源文件路径之类的信息)
因此在计算机里面可以对其进行一个赋值 如上图定义一个二叉树类
二叉树插入数值
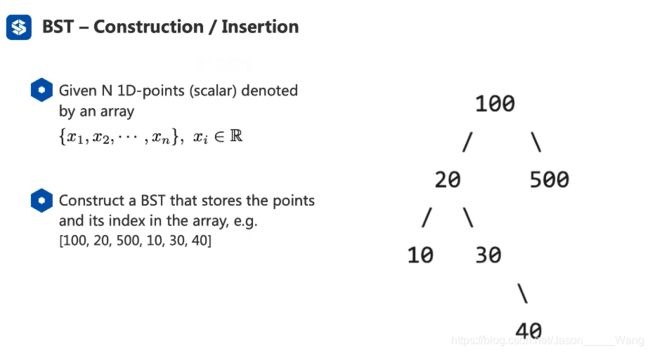
总结起来很简单,就是从二叉树的头开始判断,如果比他小就判断左边,如果比他大就判断右边,最后填充到二叉树的最底部即可

二叉树的代码实现 ↑ (算法岗面试时常见)
上面的函数采用了自身调用
其中将变量i 储存到了二叉树中。 因为方便对应查找

如果二叉树建的好,其实是能够省很多搜索时间的。
但是如果二叉树建的不好,那么就会形成一个链条,甚至成为一个遍历的过程
如何衡量二叉树的质量:
左右平衡的二叉树是最好的 :即有一个左节点就有一个右节点,对应起来,越对称说明二叉树所能提供的信息量越大。
也可以这么理解,同样的数据,层数越少的二叉树效果更好(因为只需要做更少的判断)
从理论上讲,一个n个数的二叉树效果最坏的是判断 n次,效果最好的是判断log2 n 次
二叉树查找

查找可以用递归或者循环的方式。
1. 递归方式

设置一个函数反复调用自身
2. 循环方式

可以手动创建一个“栈” 来代替递归
3.二者优劣比较

递归实现起来更容易,且更容易理解 ; 但是需要不停的压栈,所以内存占用比较多 可能溢出
循环可以节省内容,但是理解比较复杂
但是对于目前的计算机和编译器来说,二者使用起来应该没有什么差别(可以理解成算力够用)
所以一般来说用递归就可以,但是如果是在GPU中 堆栈会很困难,此时用循环的方法就很不错
深度优先遍历

有三种历遍方式可以选择:
- 中序历遍
- 前序历遍
- 后序历遍
三种历遍的代码如下:

中序历遍 :inorder
历遍出来的是按顺序排列的
顺序:先左边 再中间 在右边 哪个有值先存那个
同理 前序和顺序就是逻辑不同(由上往下和由下往上)
二叉树的 1-NN 搜索
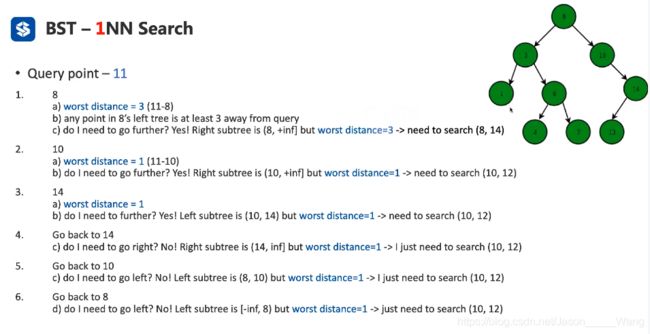
即搜索出来一个最临近的值
算法逻辑:
- 从头进入二叉树
- 计算worst distance
- 判断 转移方向(左、右还是掉头)
- 判断是否要跳过区域
二叉树的K-NN 搜索

核心思想:利用worst distance 减少需要搜索的区域
逻辑描述:

代码实现:

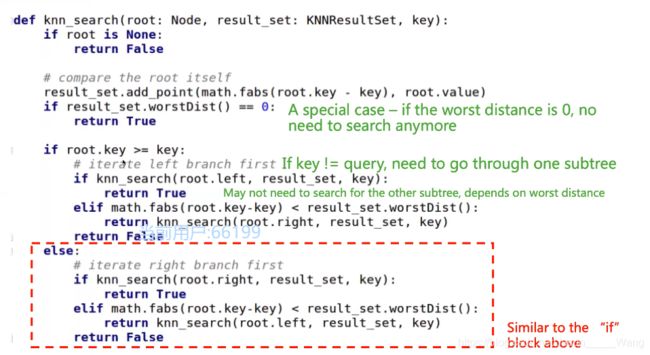
二叉树的R-NN 搜索
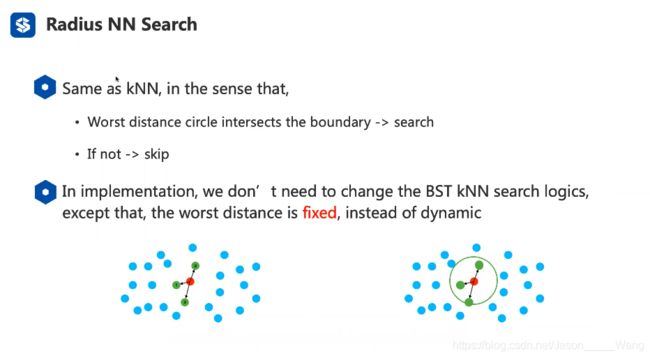
相当于最坏距离已经给定了,只需要查找就行了,所以不需要做排序和查找,只需要遍历判断就行了
KNN和 CNN比较

用这两个方法做一个实验:
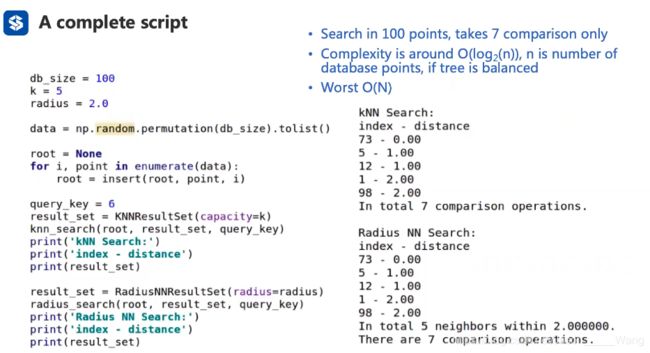
相比于暴力搜索,二叉树能够有效的降低复杂度(无论是KNN还是CNN)
二叉树的限制
二叉树最大的限制是不能向高维拓展,因此常用在一位的数组中。
因为二叉树的基本概念就是 右边大左边小,这种情况与两个数做比较时候相吻合。
而如果是一个二维的数,则有可能出现 第一个数大 第二个数小的情况 所以不适用
总结
二叉树可以帮助提升搜索的效率
(个人总结)事实上二叉树减小的是最左边分支的搜索 和最右边分支的搜索
即:
在某一超过最坏距离节点的左边, 比该节点数更小的 可以直接排除
在某一超过最坏距离节点的右边,比该节点数更大的 可以直接排除
KD-Tree
KD树的基本介绍

KD数中 KD 就是K维度的意思
事实上,KD树和二叉树的原理思想都是一样的
而顾名思义,KD-树 在任意的K个维度下都能够工作(这是二叉树办不到的)
KD数事实上就是在每个维度都跑一次二叉树
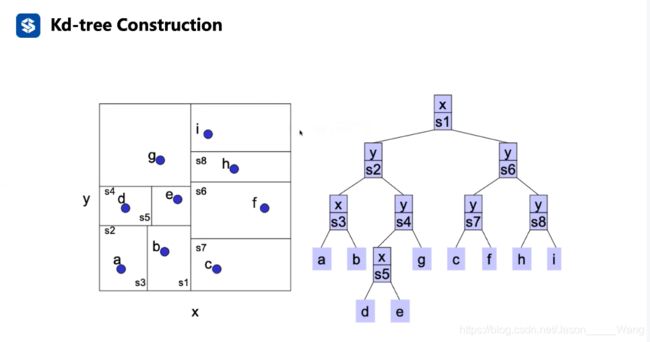
KD树的构建

和二叉树不同的是,有一个leaf 的概念,可以储存多个点(就可以不用切完了)
直观表达:
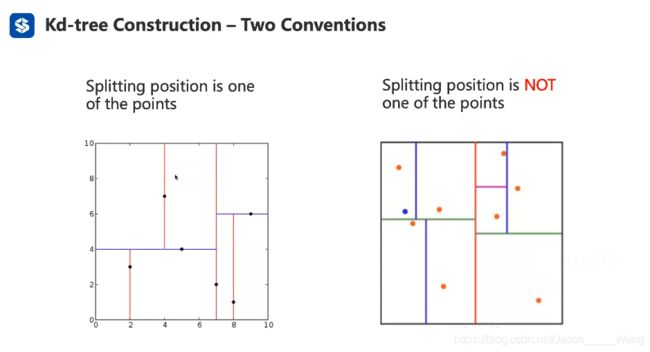
(个人理解: 就是在三个方向上轮流依次切平面)
关于切的顺序也有两种方式:(如下图)
- 不同维度以此轮流切 (如 xy xy
- 自适应 即哪个维度的切法能够分的更均匀,就从哪个维度开始切
实际上都能使用,在课程中就使用比较好理解的传统切法
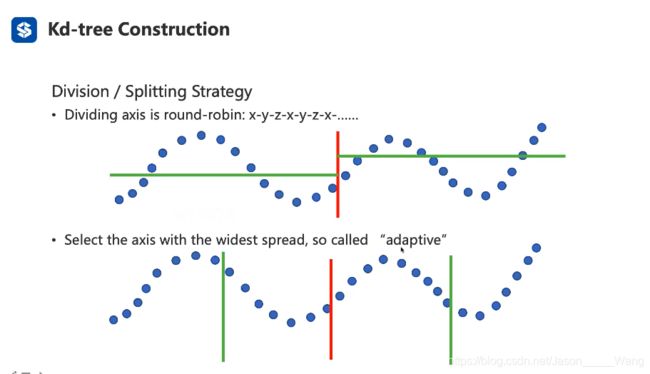
实际构建:
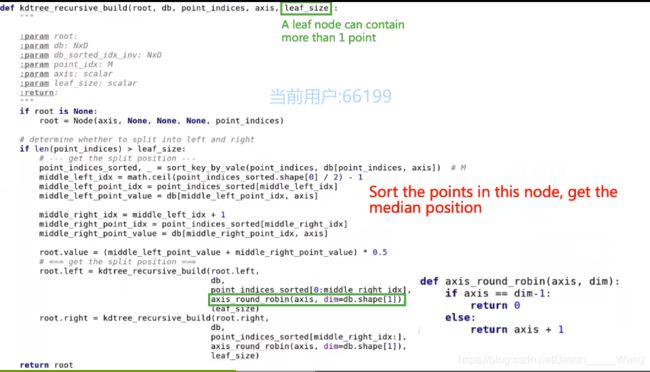
算法详解:
-
表达节点

-
构建KD-树
KD树的复杂度分析

在实践中比较实用的方法:
- 用一部分点代替所有点排序来找中值
- 用平均值来替代中值
(总结来看事实上就时用精度换时间的方法)

KNN 搜索

查找的逻辑可以分为以上三个步骤:(和二叉树类似)
- 从树顶端开始
- 从一边开始寻找最左端(或最右端)
- 到头了以后拐回来
下面是一个二维空间的应用案例:
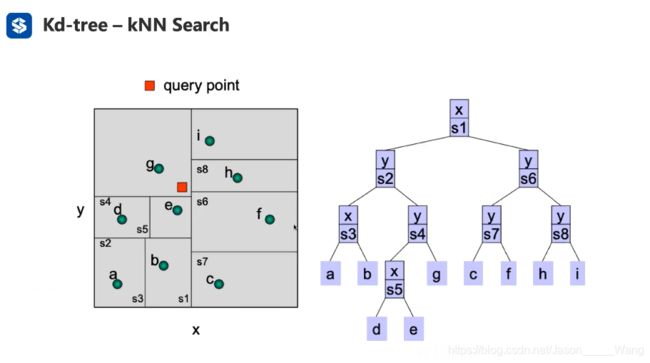

用 KD树来进行KNN搜索的核心思想是:
给定一个区域,用最坏距离的概念判断要不要对这个区域进行搜索,由此来节省搜索区域
判断需要查找的条件:
1. 点本身在这个区域中(距离为0)
2. 点离这个区域的边界距离小于 最坏距离
KD树 的 代码实现:
KNN版本:
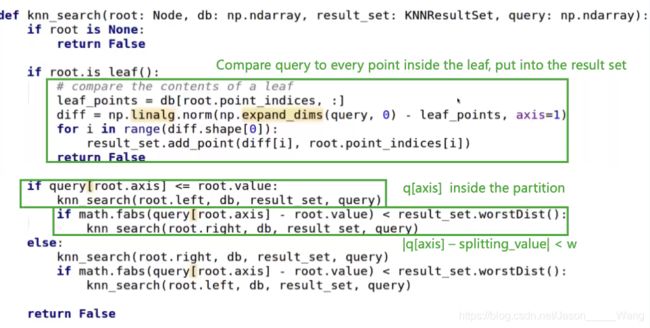
R-NN版本:(最坏距离是固定的)
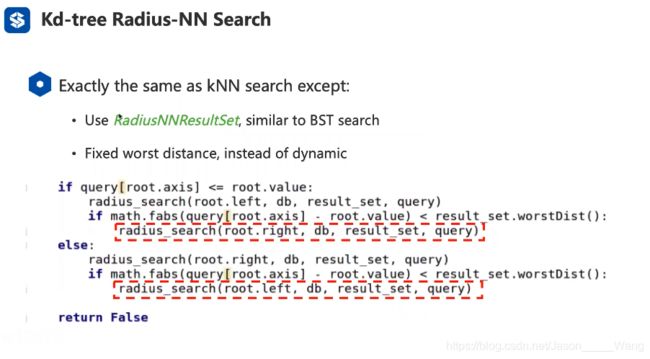
KD树的复杂度

在最理想情况下(即每次都找中值,把树平均分)
Octree
可以理解为三维空间里面的二叉树 (2的3次方)
专门为三维数据所设计的
与KD树不同的是,KD树进行每次搜索的时候都需要回到根节点(最上面的那个)
但是八叉树就可以不用回到根节点即可完成搜索 因此在处理三维数据时效率更高。
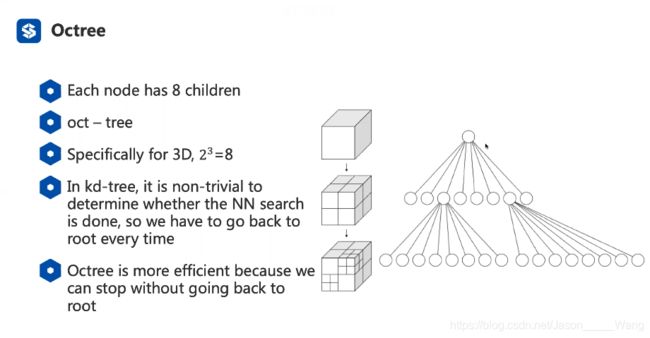
八叉树构建
和二叉树不同,八叉树的基本组成单元不是一个节点,而是可以看成一个正方体的 octant
可以看做正方体的中心区域有一个核,然后正方体被这个核分成了八块。
同样 在八叉树中也引入了 leaf 的概念,可以通过设置leaf size决定是否继续对八叉树进行切割。
(因为空间内点云是非常空的 这样的话就保证了不会对于空的点云或者只有一个点的点云继续进行切割,大大提升了效率)
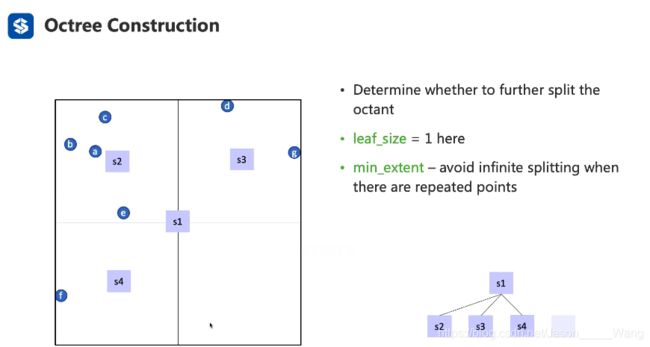
停止切割的条件:
- 达到了leaf size
- 空间内就只剩下一个点了,没必要进行切割
- 达到最小边长 (因为点云在聚集处可能非常稠密,此时如果leafsize设置的过小,可能就会导致分类过细,设置最小边长可以有效的阻止划分过于细) 同时,这个限制可以防止有几乎重合(或者重合)的点云,系统会做无限分割
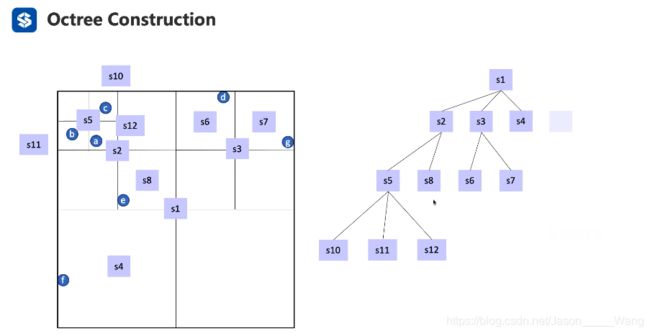
八叉树构建代码

八叉树可以定义如上图所示,其中点的定义有八个,在children中,而二叉树只有左边和右边两个
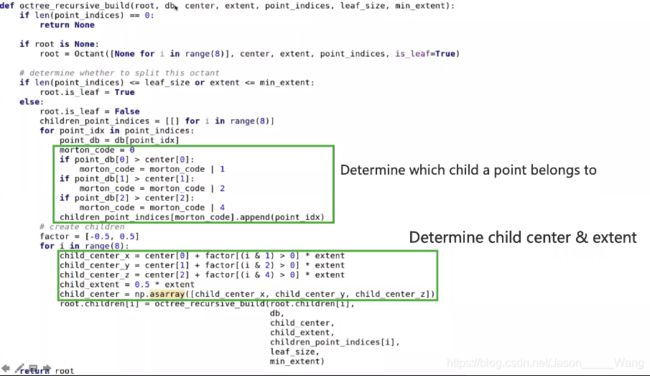
上图为八叉树定义的代码,是通过递归函数调用的
八叉树查找-KNN
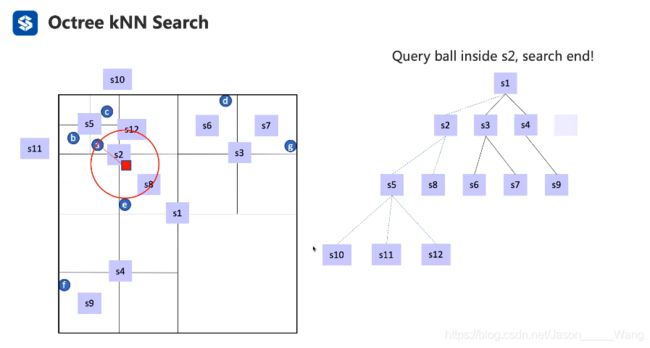
通过八叉树搜索,同样避免了搜索 s3 和s4的区块部分
八叉树搜索代码-KNN
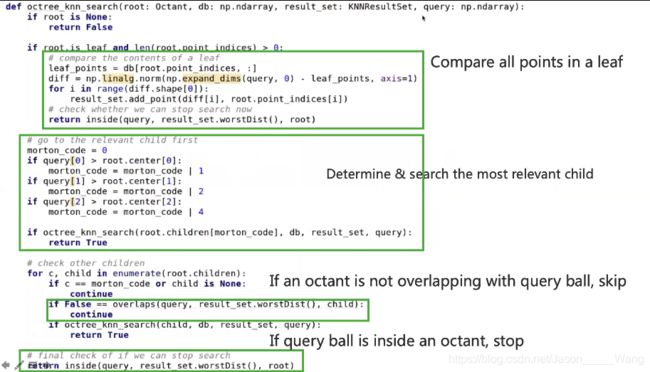
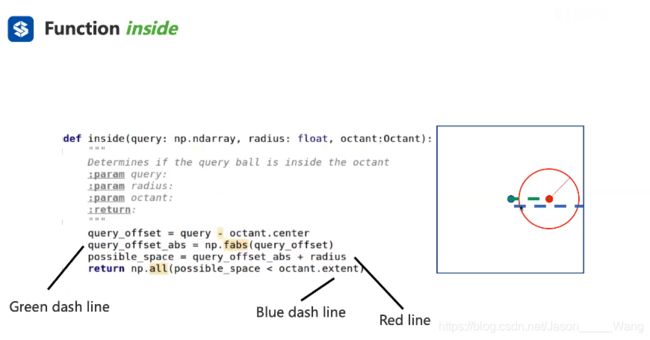
inside函数 用于判断一个点是不是在正方形里面。
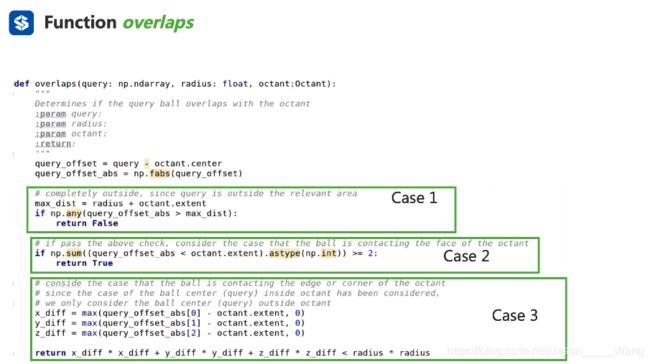
overlap用于判断以最坏距离为半径的求与区域有没有交集 比较复杂,且分为三种情况。
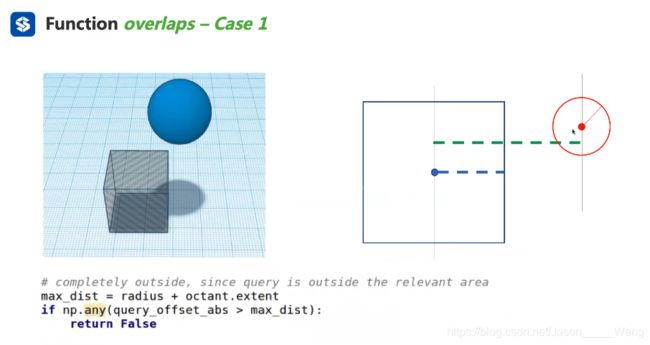
情况1 :球在任何方向上的半径 + 边长一半都达不到 那这个点肯定和这个区域没有交集
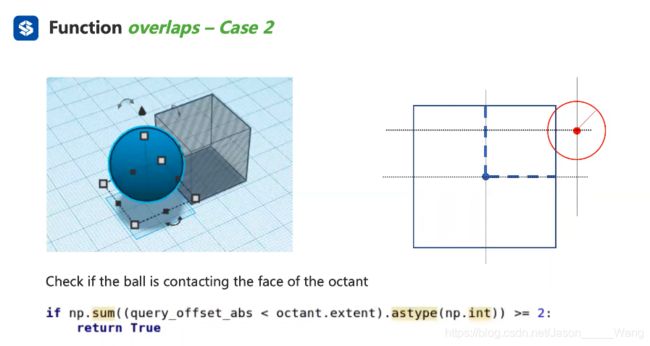
情况2:判断这个球和任何一个面有没有接触
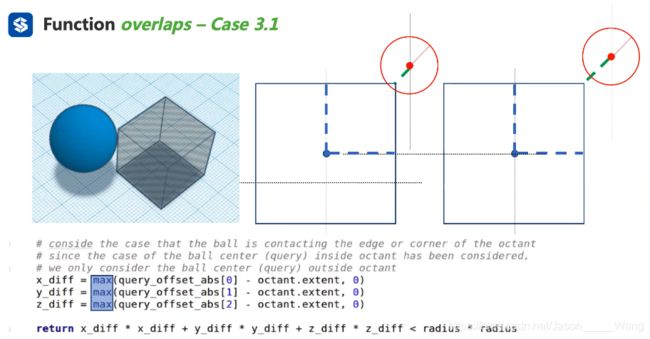
情况3.1 :判断角点与球体有没有交集。实际上但是对角线加上球的半径 。

情况3.2:判断球跟一条边是否整好相切
做一个回顾:
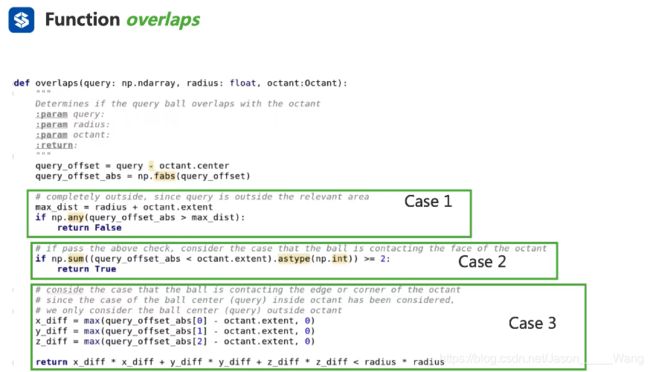
情况1:判断球和正方体是否离得太远没有接触 如果没接触,返回false 否则一定是有接触
情况2:判断球是否跟面有接触,如果有说明有交集 返回false
情况3:判断球是否跟正方体的顶点和棱长有接触,如果有说明
八叉树-RNN

此处,也有一个更好的方法来替代
增加一个判断:如果当给定的半径值的球包围了整个正方体,就不需要进一步分割,而是直接把里面的所有点都包围写进去就可以了
八叉树代码-RNN

先增加一个上述判断是否包围的函数 cotains
其他的构建代码是一样的
八叉树复杂度计算

总结
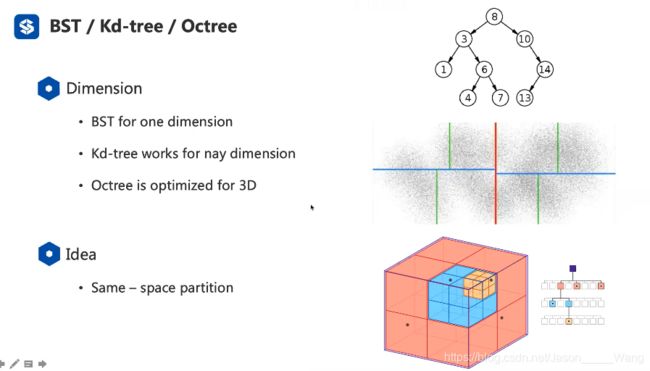
三种不同的方法
一种相同的思想:空间分割

作业
