SimCLR笔记
SimCLR笔记
文章目录
- SimCLR笔记
-
- 一. 对该问题进行建模, 总共分为三步:
-
- 1.1 相似和不同图像的样本
- 1.2 了解图像所表示的内容的能力
- 1.3 量化两个图像是否相似的能力
- 二. SimCLR框架的方法
-
- 2.1 算法框架
-
- 2.1.1 数据增强
- 2.1.2 得到图像的表示
- 2.1.3 投影头
- 2.1.4 模型调优(把相似图像拉的更近一些)
- 2.2 下游任务
- 2.3 目标结果
- 代码来源: leftthomas_SimCLR
- 内容来源: 图解SimCLR框架,用对比学习得到一个好的视觉预训练模型
近年来,众多的自我监督学习方法被提出用于学习图像表示,每一种方法都比前一种更好。但是,他们的表现仍然低于有监督的方法。当Chen等人在他们的研究论文“SimCLR:A Simple Framework for Contrastive Learning of Visual Representations”中提出一个新的框架时,这种情况改变了。SimCLR论文不仅改进了现有的自监督学习方法,而且在ImageNet分类上也超越了监督学习方法。在这篇文章中,我将用图解的方式来解释研究论文中提出的框架的关键思想。
一个视觉问题场景:

“这样的练习是为了让孩子能够识别一个物体,并将其与其他物体进行对比。我们能用类似的方式教机器吗?”
事实证明,我们可以通过一种叫做对比学习的方法来学习。它试图教会机器区分相似和不同的东西。

一. 对该问题进行建模, 总共分为三步:
1.1 相似和不同图像的样本
我们需要相似和不同的图像样本对来训练模型。
监督学习的思想学派需要人类手工创造这样的配对。为了实现自动化,我们可以利用自监督学习。但是我们如何表示它呢?
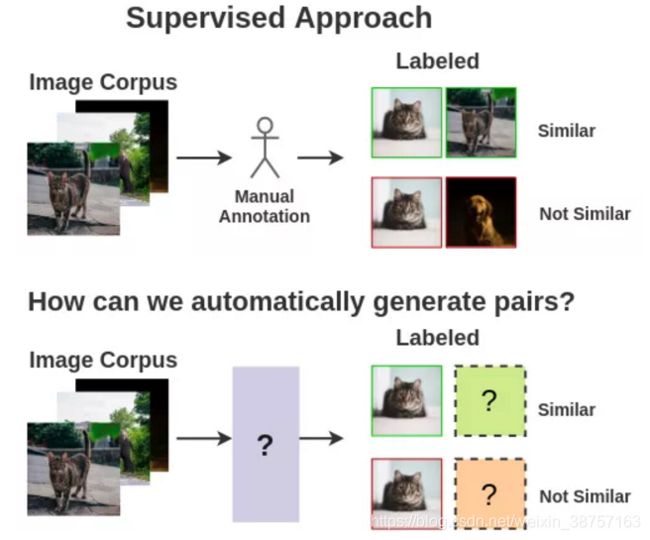
1.2 了解图像所表示的内容的能力
我们需要某种机制来得到能让机器理解图像的表示:

1.3 量化两个图像是否相似的能力
我们需要一些机制来计算两个图像的相似性

二. SimCLR框架的方法
本文提出了一个框架SimCLR来对上述问题进行自监督建模. 他将对比学习的概念与一些新颖的想法混合在一起, 在没有人类监督的情况下学习视觉的表示.
2.1 算法框架
取一副图像, 对其进行随机变化, 得到x_一对增广图像 x i x_i xi 和 x j x_j xj . 并对其中的每个图像都通过编码器以获得图像的表示. 然后用一个非线性FC层来获得图像表示z. 其任务是最大化相同图像的 z i z_i zi 和 z j z_j zj两种表征之间的相似性.
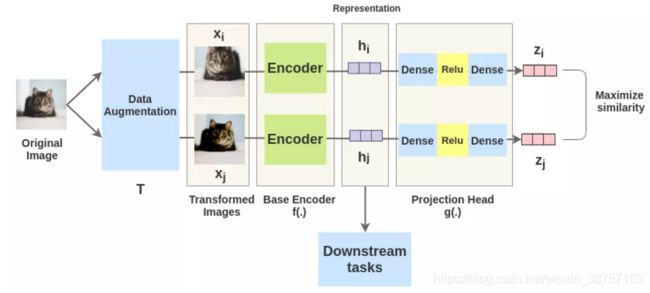
2.1.1 数据增强
from PIL import Image
from torchvision import transforms
from torchvision.datasets import CIFAR10
class CIFAR10Pair(CIFAR10):
"""CIFAR10 Dataset.
"""
def __getitem__(self, index):
img, target = self.data[index], self.targets[index]
img = Image.fromarray(img)
if self.transform is not None:
pos_1 = self.transform(img)
pos_2 = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return pos_1, pos_2, target
train_transform = transforms.Compose([
transforms.RandomResizedCrop(32),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])])
对于这个batch中的每一幅图像, 使用随机变换函数得到一对图像. 因此, 对于batch大小为2的情况, 我们得到2N = 4张总图像.
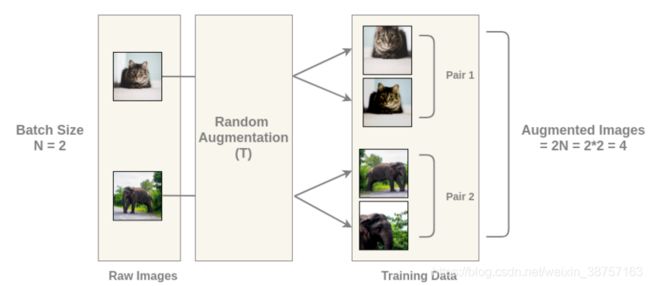
2.1.2 得到图像的表示
每一对中的增强过的图像都通过一个编码器来获得图像表示. 所使用的编码器是通用的, 可与其他架构替换. 下面显示的两个编码器有共享的权值, 我们得到向量 h i h_i hi 和 h j h_j hj .

定义网络使用的是resnet50, 为了cifar10修改了一下最后的fc层和前面的conv1
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models.resnet import resnet50
class Model(nn.Module):
def __init__(self, feature_dim=128):
super(Model, self).__init__()
self.f = []
for name, module in resnet50().named_children():
# 将imagenet的head转换成cifar10的head
if name == 'conv1':
module = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
if not isinstance(module, nn.Linear) and not isinstance(module, nn.MaxPool2d):
self.f.append(module)
# encoder
self.f = nn.Sequential(*self.f)
# projection head
self.g = nn.Sequential(nn.Linear(2048, 512, bias=False), nn.BatchNorm1d(512),
nn.ReLU(inplace=True), nn.Linear(512, feature_dim, bias=True))
def forward(self, x):
x = self.f(x)
feature = torch.flatten(x, start_dim=1)
out = self.g(feature)
return F.normalize(feature, dim=-1), F.normalize(out, dim=-1)
值得注意的是, model的输出如下:
# encoder
self.f = nn.Sequential(*self.f)
# projection head
self.g = nn.Sequential(nn.Linear(2048, 512, bias=False), nn.BatchNorm1d(512),
nn.ReLU(inplace=True), nn.Linear(512, feature_dim, bias=True))
def forward(self, x):
x = self.f(x)
feature = torch.flatten(x, start_dim=1)
out = self.g(feature)
return F.normalize(feature, dim=-1), F.normalize(out, dim=-1)
其中, feature既是向量 h i h_i hi 和 h j h_j hj .
2.1.3 投影头
两个增强过的图像的 h i h_i hi 和 h j h_j hj 表示经过一系列非线性Dense -> Relu -> Dense层应用非线性变换,并将其投影到 z i z_i zi 和 z j z_j zj 中. 本文用 g ( . ) g(.) g(.)表示,称为投影头.
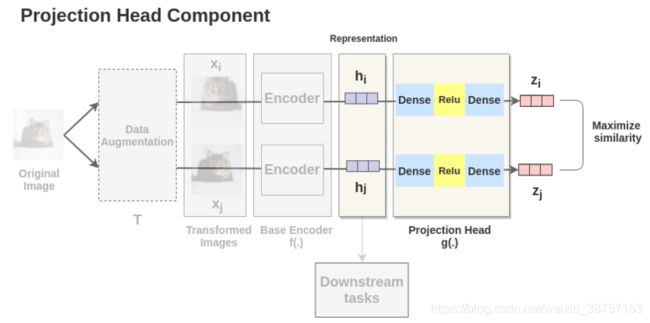
# projection head
self.g = nn.Sequential(nn.Linear(2048, 512, bias=False), nn.BatchNorm1d(512),
nn.ReLU(inplace=True), nn.Linear(512, feature_dim, bias=True))
def forward(self, x):
x = self.f(x)
feature = torch.flatten(x, start_dim=1)
out = self.g(feature)
return F.normalize(feature, dim=-1), F.normalize(out, dim=-1)
其中, F . n o r m a l i z e ( o u t , d i m = − 1 ) F.normalize(out, dim=-1) F.normalize(out,dim=−1) 是 z i z_i zi 和 z j z_j zj.
2.1.4 模型调优(把相似图像拉的更近一些)
因此, 对于batch中的每个增强过的图像, 我们得到其嵌入向量z
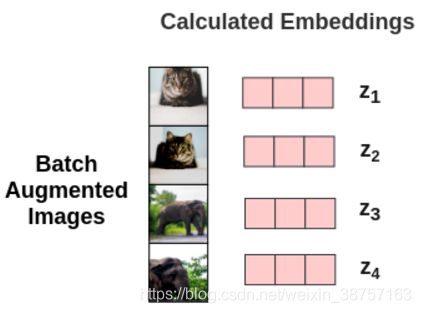
下一步, 需要计算loss:
- 计算余弦相似性
现在, 用预先相似度计算图像的两个增强的图像之间的相似度. 对于两个增强的图像 x i x_i xi 和 x j x_j xj, 在其投影表示 z i z_i zi和 z j z_j zj上计算余弦相似度.
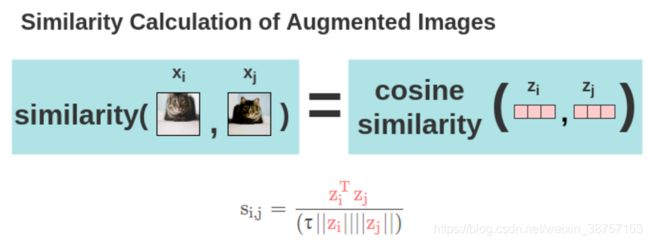
其中:
- τ \tau τ是可调参数。它可以缩放输入,并扩大余弦相似度的范围 [ − 1 , 1 ] [- 1,1] [−1,1]。
- ∣ ∣ z i ∣ ∣ ||z_i|| ∣∣zi∣∣是该矢量的模
使用上述公式计算batch中每个增强图像之间的两两余弦相似度。如图所示,在理想情况下,增强后的猫的图像之间的相似度会很高,而猫和大象图像之间的相似度会较低。

- 损失的计算
SimCLR使用了一种对比损失,称为NT-Xent损失(归一化温度-尺度交叉熵损失)。让我们直观地看看它是如何工作的。
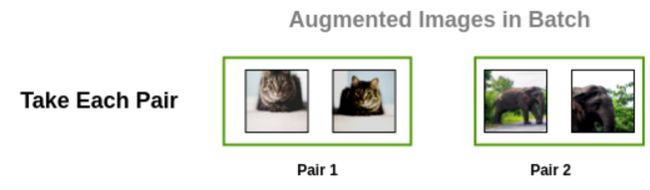
首先,将batch的增强对逐个取出。
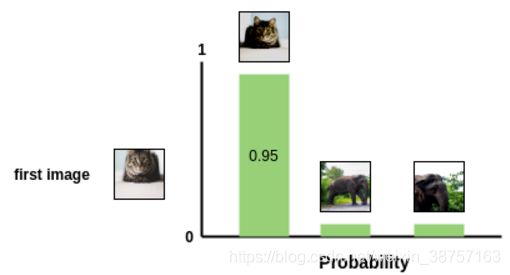
接下来,我们使用softmax函数来得到这两个图像相似的概率.
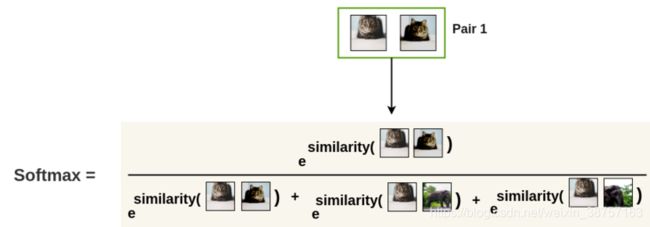
这个softmax计算等价于第二个增强的猫图像与图像对中的第一个猫图像最相似的概率. 这里, batch中所有剩余的图像都被采样为不相似的图像(负样本对).
然后, 通过取上述计算的对数的附属来计算这一对图像的损失. 这个公式就是噪声对比估计[NCE]损失;

在图像位置互换的情况下, 再次计算同一对图像的损失. 最后, 计算Batch Size=2N的所有配对的损失并取平均值.

基于这种损失,编码器和投影头表示法会随着时间的推移而改进,所获得的表示法会将相似的图像放在空间中更相近的位置.
看一下train函数:
def train(net, data_loader, train_optimizer):
net.train()
total_loss, total_num, train_bar = 0.0, 0, tqdm(data_loader)
for pos_1, pos_2, target in train_bar:
pos_1, pos_2 = pos_1.cuda(non_blocking=True), pos_2.cuda(non_blocking=True)
feature_1, out_1 = net(pos_1)
feature_2, out_2 = net(pos_2)# 所谓的共享权重, 其实就是使用同一个网络进行输出
# [2*B, D]
out = torch.cat([out_1, out_2], dim=0)
# print(out.size())([256, 128])
# [2*B, 2*B]
sim_matrix = torch.exp(torch.mm(out, out.t().contiguous()) / temperature)
# print(sim_matrix.size())([256, 256])
mask = (torch.ones_like(sim_matrix) - torch.eye(2 * batch_size, device=sim_matrix.device)).bool()
# [2*B, 2*B-1]
# print(mask) bool matrix including [Trun, False, True...]
sim_matrix = sim_matrix.masked_select(mask).view(2 * batch_size, -1)
# print(sim_matrix.size()) [2B,2B-1]; keep elements in sim_matrix which is not "False"
# compute loss
pos_sim = torch.exp(torch.sum(out_1 * out_2, dim=-1) / temperature)
# exp(s_{i,j}/temperature)
# [2*B]
pos_sim = torch.cat([pos_sim, pos_sim], dim=0)
# sim i,j and sim j,i
loss = (- torch.log(pos_sim / sim_matrix.sum(dim=-1))).mean()
# loss function constructed
train_optimizer.zero_grad()
loss.backward()
train_optimizer.step()
total_num += batch_size
total_loss += loss.item() * batch_size
train_bar.set_description('Train Epoch: [{}/{}] Loss: {:.4f}'.format(epoch, epochs, total_loss / total_num))
return total_loss / total_num
2.2 下游任务
一旦SimCLR模型被训练在对比学习任务上, 他就可以用于迁移学习. 为此, 使用来自编码器的表示, 而不是从投影头获得的表示. 这些表示可以用于想ImageNet分来这样的下游任务.

2.3 目标结果
SimCLR比以前ImageNet上的自监督方法更好,:
- 在ImageNet ilsvvc -2012上,实现了76.5%的top-1准确率,比之前的SOTA自监督方法Contrastive Predictive Coding提高了7%,与有监督的ResNet50持平。
- 当训练1%的标签时,它达到85.8%的top-5精度,超过了AlexNet,但使用带标签的数据少了100倍。