高级OS(五) - 进程的创建和调度
高级OS(五) - 进程的创建和调度
- 一.题目
- 二.解答
-
- 1.进程从诞生到结束,是一个生命周期,在这个生命周期中,进程的创建至关重要,请分析进程的生命周期,并深入到内核源代码对fork进行分析**
-
- (1)什么是进程?
- (2)进程的生命周期?
- (3)fork.c进行分析
- 2.进程的生命周期中,有一个重要的环节是被调度到CPU上执行,请分析进程的调度算法的源代码进行分析(从最简单的0.11版着手),并比较一个高版本的算法,说明为什么要进行这样的改进
-
- 2.1 进程调度的策略讨论
- 2.2 Linux-0.11中的schedule()
- 2.3 总结
- 3.动手实践,运行P59页的内核模块,查看task_struct结构,并增加打印进程状态或者其他信息至少共5个字段的信息。给出调试截图,并对运行结果给予解释。
一.题目
1.进程从诞生到结束,是一个生命周期,在这个生命周期中,进程的创建至关重要,请分析进程的生命周期,并深入到内核源代码对fork进行分析
2.进程的生命周期中,有一个重要的环节是被调度到CPU上执行,请分析进程的调度算法的源代码进行分析(从最简单的0.11版着手),并比较一个高版本的算法,说明为什么要进行这样的改进
3.动手实践,运行P59页的内核模块,查看task_struct结构,并增加打印进程状态或者其他信息至少共5个字段的信息。给出调试截图,并对运行结果给予解释。
二.解答
1.进程从诞生到结束,是一个生命周期,在这个生命周期中,进程的创建至关重要,请分析进程的生命周期,并深入到内核源代码对fork进行分析**
(1)什么是进程?
进程是处于执行期的程序以及相关的资源的总称。进程主要包含资源有代码段、数据段、打开的文件、挂起的信号,内核内部数据、一个/多个具有内存映射的内存地址空间,一个或多个执行线程等。进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。举个例子:一个应用程序的打开关闭就是一次进程的生命周期,又提出一个生命周期的问题。
(2)进程的生命周期?
进程的生命周期分为创建、运行、撤销。
进程的创建:进程是通过fork(),vfork(),clone()系统调用创建新进程。在内核中,都是调用do_fork实现的。传统的fork函数直接把父进程的所有资源复制给子进程。而Linux的fork()使用写时拷贝页实现,也就是说,父进程和子进程共享同一个资源拷贝,只有当数据发生改变时,数据才会发生复制。一般来说,子进程创建后会立即调用exec(),这样的好处是:避免复制父进程的全部资源。
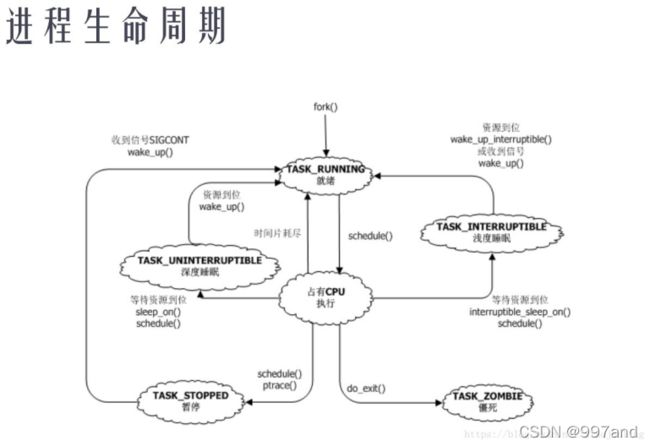
进程运行时的 3 个基本状态:
操作系统包括实时系统对应进程一般都有 3 个状态,进程在有 CPU 时对应运行态,无 CPU 时对应就绪态和睡眠态。就绪态指所有资源都准备好,只要有 CPU 就可以运行了。睡眠态指有资源还未准备好,比如读串口数据时,数据还未发送。此时有 CPU 也无法运行,需要等资源准备好后变成就绪态,然后得到 CPU 后才能变成运行态。
linux 进程扩展的 6 个状态
僵尸态:子进程退出后,所有资源都消失了,只剩下 task_struct,父进程在 wait 函数中可以得到子进程的死亡原因。在 wait 之前子进程的状态就是僵尸态。
深度睡眠:等待资源到位后才醒过来
浅度睡眠:等待资源到位或收到信号后都会醒过来
暂停:stop 状态是被外部命令作业控制等强制进程进入的状态。
就绪:未占用 CPU,等待调度算法调度到运行态的进程
运行:占有 CPU,正在运行的线程。
(3)fork.c进行分析
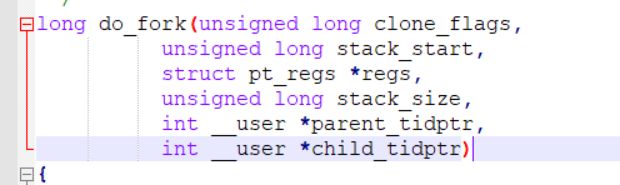
clone_flags : 宏定义 clone 标志,例如 CLONE_VM 表示与父进程共享内存描述符(线程的创建)
stack_start : 将用户态栈指针值给子进程的 esp 寄存器(给子进程分配新堆栈)
regs : 通用寄存器的地址(用户态->内核态,寄存器的值保存至内核栈中)
stack_size : 置 0
parent_tidptr : 父进程用户态变量地址
child_tidptr : 新进程用户态变量地址
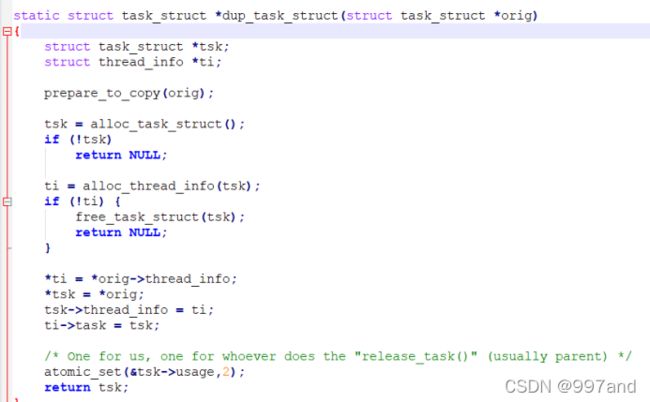
dup_task_struct函数为新的进程创建一个内核栈,thread_info结构和task_struct结构等,值都是和父进程完全一样的
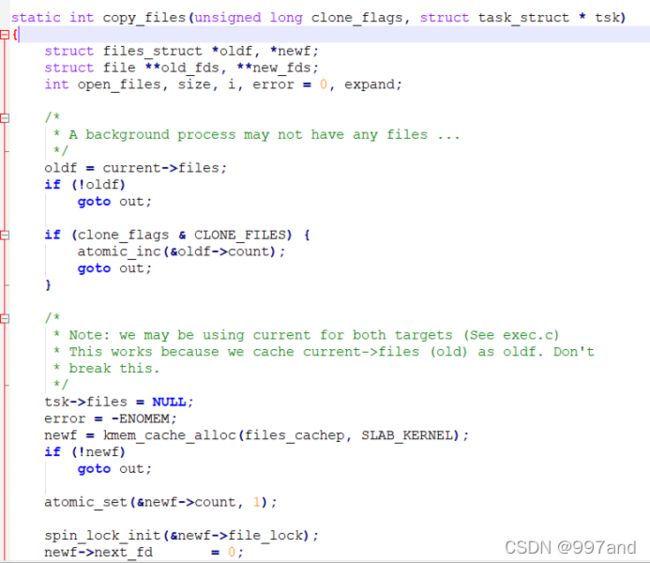
copy_files函数是去拷贝父进程的一些东西
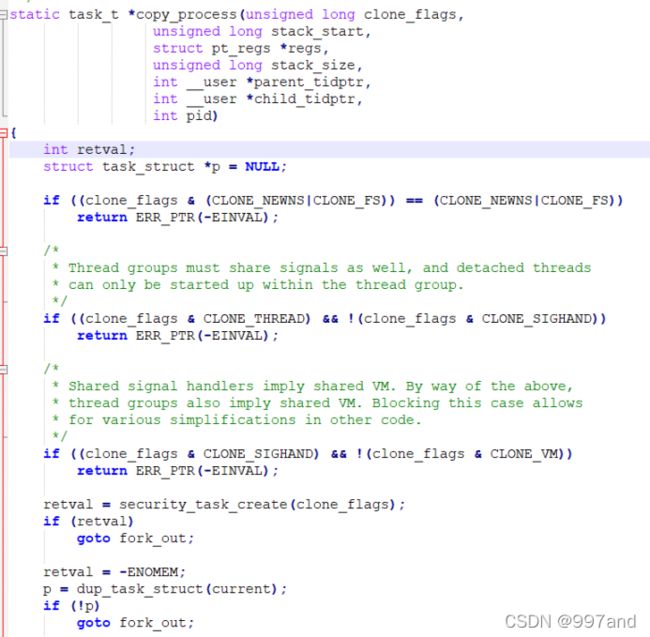
copy_process做一些收尾工作,并返回新进程的task_struct指针,此时再次回到了do_fork,新创建的子进程被唤醒,并让其先投入运行。
2.进程的生命周期中,有一个重要的环节是被调度到CPU上执行,请分析进程的调度算法的源代码进行分析(从最简单的0.11版着手),并比较一个高版本的算法,说明为什么要进行这样的改进
2.1 进程调度的策略讨论
在进⾏调度时,我们都希望操作系统能满⾜以下⽬标:
- 公平:保证每个进程得到合理的 CPU 时间。
- ⾼效:使 CPU 保持忙碌状态,即总是有进程在 CPU 上运⾏。
- 响应时间:使交互⽤户的响应时间尽可能短。
- 周转时间:使批处理⽤户等待输出的时间尽可能短。
- 吞吐量:使单位时间内处理的进程数量尽可能多。
但在实际系统中,以上⽬标往往是存在冲突的。⽐如前台任务和后台任务,前台任务关注响应时间,⽐如按下⼀次⿏标多久才能有响应,⽽后台任务关注周转时间,⽐如执⾏编译任务多久能完成,后台任务不希望被频繁打断,但这样势必会导致前台任务的响应时间变⻓。这就要求在设计进程调度算法时,需要充分的进⾏综合和折中。
在进⾏调度时,有两个⽐较直观的思路。⼀个是较为公平的先来先服务,另⼀个是带有特权级的。单纯的先来先服务可能会导致平均周转时间变⻓,因为先来的任务可能执⾏时间⾮常⻓,导致后⾯执⾏时间短的任务迟迟不能执⾏,所以衍⽣出了⼀种短作业优先(SJF)算法,先执⾏时间短的任务,以提⾼系统的平均周转时间。
若单纯采取以上的调度算法,假如处理⽤户操作的任务被排到了最后,会导致系统的响应时间⾮常⻓,这显示是不⾏的,于是有了按时间⽚轮转调度(RR)。这种调度算法把⼀个任务分为多个时间⽚来执⾏,执⾏完第⼀个任务的时间⽚后转去执⾏第⼆个任务的时间⽚,之后再去执⾏第三个任务的时间⽚,直到这些任务都执⾏完。这样做的好处是,假设处理⽤户操作的任务排到第三个,第⼀个和第⼆个任务需要的执⾏时间很⻓,在时间⽚轮转的情况下,最多也就等待两个时间⽚,避免了响应时间过⻓的问题。于是⼜有了⼀个新的⽭盾,那就是时间⽚⻓短的问题。如果选取的时间⽚⻓度很⼩,⾃然⽤户响应会很快,但是频繁的任务切换会导致系统内耗增加,导致系统吞吐量减⼩。所以时间⽚的选取也是⼀个综合和折中。
那么如何平衡以上的⽭盾呢?既然前台任务更关⼼响应时间,那么可以对前台任务采取时间⽚轮转调度,当前台任务执⾏完后,再对后台任务进⾏短作业优先调度,即前台任务的优先级⾼于后台任务。
但这⼜带来新的问题,因为前台任务优先级⼀直⽐后台任务⾼,如果不断有前台任务进来,则会导致后台任务⼀直⽆法执⾏,使后台任务产⽣“饥饿现象”。如果让后台任务的优先级动态升⾼的话,因为后台任务采⽤了短作业优先调度,⼜会导致前台任务响应时间变⻓,所以需要前后台任务都使⽤时间⽚轮转。
2.2 Linux-0.11中的schedule()
在0.11中,Schedule()函数负责选择系统中下⼀个要运⾏的进程,它位于 /kernel/sched.c 中。先看⼀下它的具体实现:
void schedule(void) {
int i,next,c;
struct task_struct ** p;
/* check alarm, wake up any interruptible tasks that have got a signal */
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p) {
if ((*p)->alarm && (*p)->alarm < jiffies) {
(*p)->signal |= (1<<(SIGALRM-1));
(*p)->alarm = 0;
}
if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
(*p)->state==TASK_INTERRUPTIBLE)
(*p)->state=TASK_RUNNING;
}
/* this is the scheduler proper: */
while (1) {
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i) {
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
if (c) break;
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) +
(*p)->priority;
}
switch_to(next);
}
这⾥的 task_struct 定义如下:
struct task_struct {
/* these are hardcoded - don't touch */
long state; /* -1 unrunnable, 0 runnable, >0 stopped */
long counter;
long priority;
long signal;
struct sigaction sigaction[32];
long blocked; /* bitmap of masked signals */
/* various fields */
int exit_code;
unsigned long start_code,end_code,end_data,brk,start_stack;
long pid,father,pgrp,session,leader;
unsigned short uid,euid,suid;
unsigned short gid,egid,sgid;
long alarm;
long utime,stime,cutime,cstime,start_time;
unsigned short used_math;
/* file system info */
int tty; /* -1 if no tty, so it must be signed */
unsigned short umask;
struct m_inode * pwd;
struct m_inode * root;
struct m_inode * executable;
unsigned long close_on_exec;
struct file * filp[NR_OPEN];
/* ldt for this task 0 - zero 1 - cs 2 - ds&ss */
struct desc_struct ldt[3];
/* tss for this task */
struct tss_struct tss;
};
在schedule函数开始,可以看到⼀个for循环,它从最后⼀个任务开始向前遍历,检查其 alarm 字段,要求其⼤于0且⼩于 jiffies 。 jiffies 是系统从开机算起的滴答数(10ms/滴答),其产⽣于时钟中断。如果alarm
时, if© break; 。进⼊循环内,⾸先将c置为-1,next (下⼀个要执⾏的任务)置为0, i (遍历⽤)初始值置为 NR_TASKS (值为64,为最多同时⽀持任务数), p 为⼀个⼆级指针,初始指向最后⼀个 task +1的指针。之后进⼊ while(–i) 内 , if(*–p) ,这⼀条语句完成了多个操作,⾸先 p ⾃减,以完成遍历,再判断其是否为空,为空则执⾏ continue 跳过本次循环。接下来⼜是⼀个判断,⾸先判断 p 所指向的task的状态是否为 TASK_RUNNING (就绪态),接着判断其 counter 是否⼤于 c , counter 代表每个就绪态任务剩余执⾏时间的值。若是,则将c替换为 counter , next 替换为 i (指向了这个进程)。在这⾥整个循环的主要意义是找出counter 值最⼤的进程作为 next 。之后,若找到了 counter 值最⼤的程序(c>0),或当前系统中没有就绪态的任务时(c=-1),执⾏ break 退出 while(1) 循环,并通过 switch_to(next) 切换过去。当c=0时,即所有任务时间⽚都已耗尽时,则会继续向下执⾏for循环。 p 重新被置为 LAST_TASK (值为 task[NR_TASKS-1] )并向前遍历到 FIRST_TASK (值为 task[0] ),在这⾥,每个任务的counter被重新赋值为 ((*p)->counter >> 1) + (*p)->priority 即counter/2+priority。
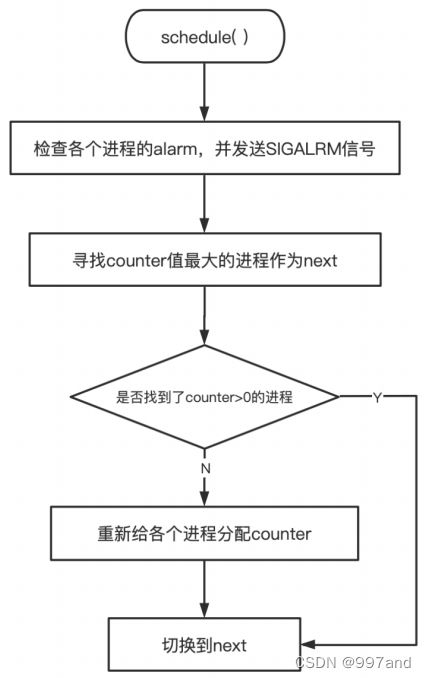
2.3 总结
进程调度是个深刻的问题。它需要平衡各种⽭盾,没有⼀个调度算法是绝对完美的,都需要考虑实际需要合理的进⾏取舍和折中,最终选择⼀个相对合适的调度算法和策略。在低版本中,由于当时的系统要⽐现在简单得多,不需要⽀持太多的进程,也不需要考虑多处理器的问题,所以采取了当时的设计。⽽现在的系统要复杂的多,进程数爆发增⻓,并且还需要考虑多处理器的问题,如果采取的调度算法不够恰当,没有充分利⽤CPU等硬件资源,会导致系统运⾏不稳定甚⾄是崩溃,所以设置了⼀系列的参数、数据结构和程序来辅助调度,使调度更加合理,从⽽更加充分利⽤硬件资源,并使系统运⾏的更稳定,响应更流畅。
3.动手实践,运行P59页的内核模块,查看task_struct结构,并增加打印进程状态或者其他信息至少共5个字段的信息。给出调试截图,并对运行结果给予解释。
a).task_struct.c文件
task_struct结构体中存放着进程描述符的内容,进程描述符中包含的数据能够完整地描述一个正在执行的程序:它打开的文件、进程的地址空间、挂起的信号、挂起的状态等等。包含了一个内核管理一个进程所需要的所有信息。
我们通过编写task_struct.c来打印进程的状态等信息。
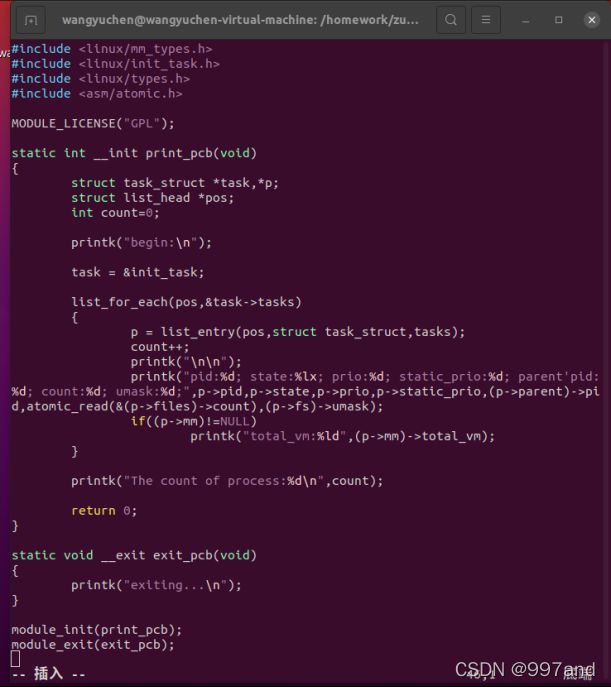
b)编译并写入内核
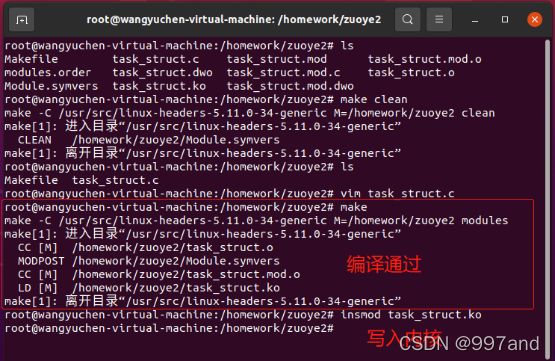
c)打印进程日志
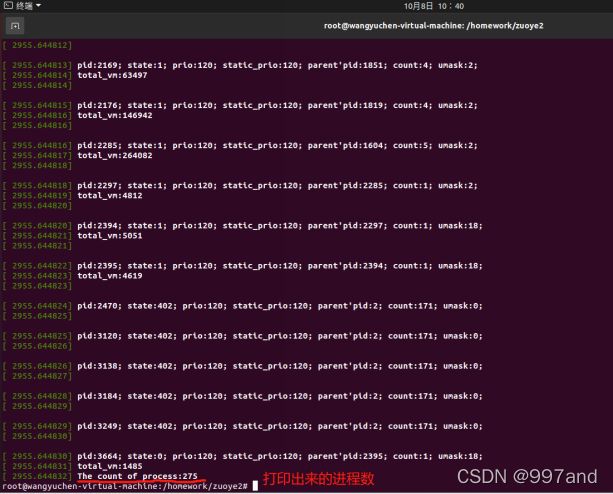
pid:该进程的进程号;
state:进程的运行状态;
prio:动态优先级;
static_prio:静态优先级;
parent’pid:父进程的进程号;
count:存放结构体被使用的次数;
umask:文件创建属性屏蔽位。
没有total_vm字段说明它们的mm是空的,他们是内核线程。
total_vm:1485说明这个进程的线性空间总共有1485个页。