OpenCV计算机视觉实战 - 图像特征(Harris+Sift)检测 和 全景图像拼接
#################################################################
【纸上得来终觉浅,绝知此事要躬行】
B站视频
新课件:https://pan.baidu.com/s/1frWHqCVGR2VTn5QBtW4lPA 提取码:xh02
老课件:https://pan.baidu.com/s/1Wi31FxSPBqWiuJX9quX-jA 提取码:bbfg
################################################################
一、Harris 角点检测
角点检测算法基本思想:使用一个固定窗口在图像上进行任意方向上的滑动,比较滑动前与滑动后两种情况,窗口中的像素灰度变化程度,如果存在任意方向上的滑动,都有着较大灰度变化,那么我们可以认为该窗口中存在角点。
Harris 算法的原理 与 公式解析
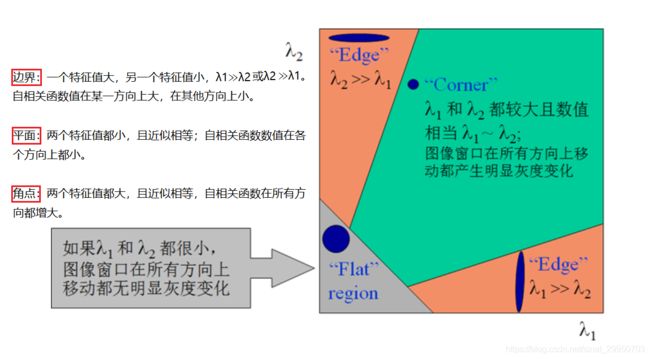
在一副图像中可能存在以下三类点:平面点,边界点 和 角点
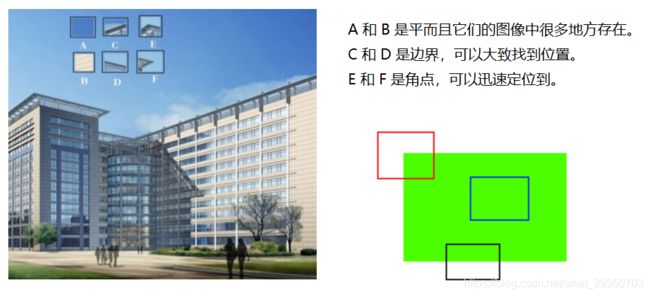
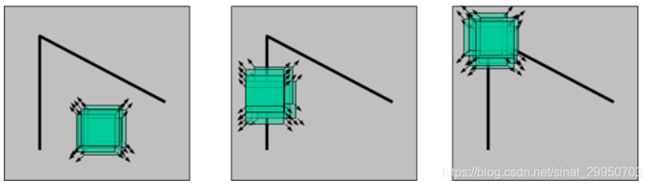
用下面这张图两条线做个夹角,表示三种点的位置。当它们移动的时候,灰度值会发生变化
平面点:x 和 y 方向变化不大
边界点:x 或 y 方向变化大
角点:x 和 y 方向的变化都大
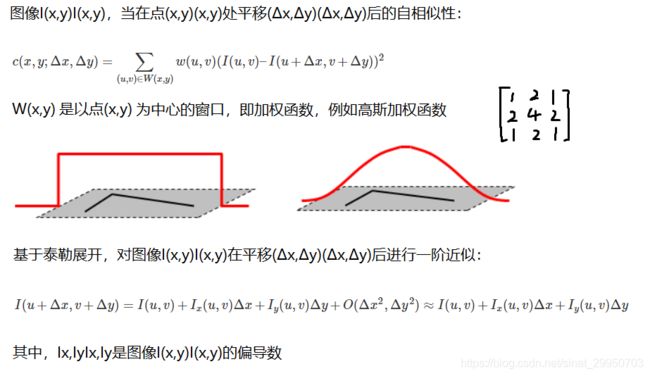
做减法:是为了获得平移前后的差异
平方:是为了获得这样一个变化的趋势,负数就无意义了,因为-5 比 2的变化幅度大;而且对这趋势做了个增强

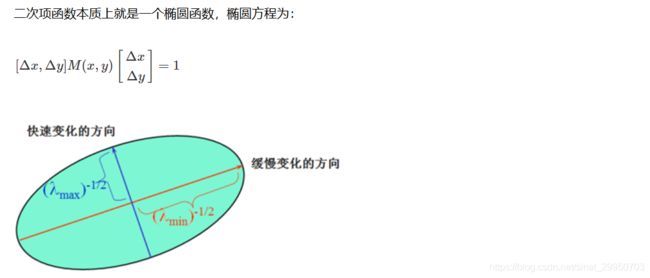
度量角点响应
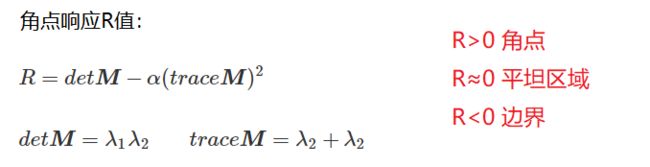
总结一下Harris算法流程
- 获取点数据后,计算Ix 和 Iy
- 整合矩阵,求特征值
- 比较特征值大小
- 非极大值抑制NMS,过滤掉不是那么角的
详细解析 https://blog.csdn.net/linqianbi/article/details/78930239
OpenCV中的Harris操作
- cv2.cornerHarris(img, blockSize, k)
img: 数据类型为 float32 的入图像
blockSize: 角点检测中指定区域的大小,前面提到的w(u,v),可能是个高斯函数
ksize: 就像Sobel求导中使用的窗口大小
k: 取值参数为 [0,04,0.06]. 默认0.04
返回dst:输出图像
import cv2
import numpy as np
img = cv2.imread(‘test_1.jpg’)
print (‘img.shape:’,img.shape)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# gray = np.float32(gray)
dst = cv2.cornerHarris(gray, 2, 3, 0.04)
print (‘dst.shape:’,dst.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
dst.max是最大值,一定是角点
只要dst中满足0.01倍的最大值,就判定为角点,要求较高的也可以调大点
# 设置为其他倍数
img[dst>0.01*dst.max()]=[0,0,255]
cv2.imshow('dst',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
二、Sift 角点检测
1.图像尺度空间
在一定的范围内,无论物体是大还是小,人眼都可以分辨出来,然而计算机要有相同的能力却很难,所以要让机器能够对物体在不同尺度下有一个统一的认知,就需要考虑图像在不同的尺度下都存在的特点,对图像进行不同尺度的改变。
尺度空间的获取通常使用高斯模糊来实现
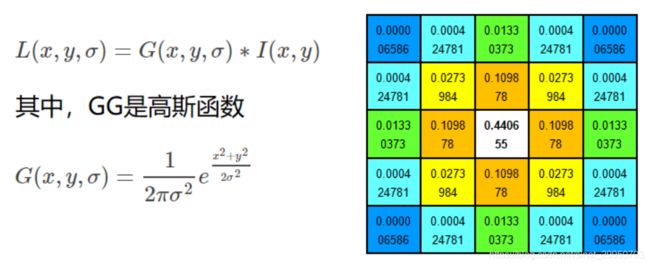
- 高斯函数对图像做滤波操作,得到高斯模糊后的结果

不同σ的高斯函数决定了对图像的平滑程度,越大的σ值对应的图像越模糊。
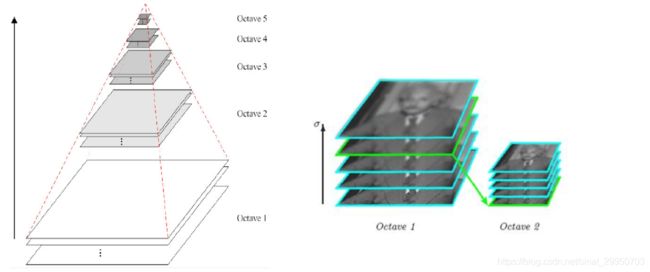
2.多分辨率金字塔
- 金字塔有多个层级
- 同一层级中,有不同的高斯滤波
3.高斯差分金字塔(DOG)
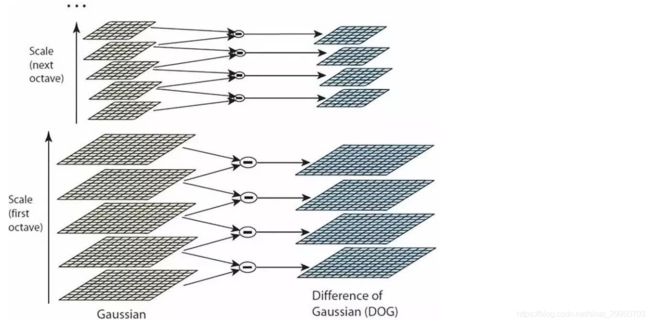
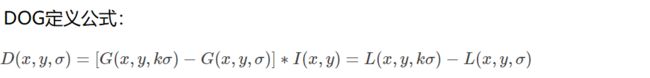
两个高斯模糊后的特征相减,得到DOG
然后怎么找极值点?每个点都要跟周围的点比较。继续往下看
4.DoG空间极值检测
为了寻找尺度空间的极值点,每个像素点要和其图像域(同一尺度空间-8个点)和尺度域(相邻的尺度空间-上下各9个 共18个)的所有相邻点(共26)进行比较,当其大于(或者小于)所有相邻点时,该点就是极值点。如下图所示,中间的检测点要和其所在图像的3×3邻域8个像素点,以及其相邻的上下两层的3×3领域18个像素点,共26个像素点进行比较。

最上/下层无法比较,故4层特征图中只有2层才能检测极值点。
但这步检测的离散极值点 不一定是 最终的极值点,故需要精确定位
5.关键点的精确定位
这些候选关键点是DOG空间的局部极值点,而且这些极值点均为离散的点,精确定位极值点的一种方法是,对尺度空间DoG函数进行曲线拟合,计算其极值点,从而实现关键点的精确定位。
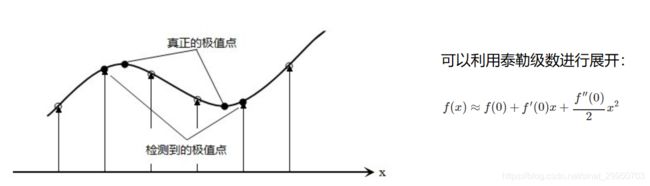
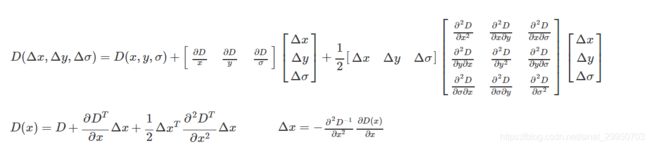
6.消除边界响应

类似于Harris角点中的角点相应R值,Tr(H)2 / Det(H),大于10的是边界,要进行过滤操作
7.特征点的主方向

每个特征点可以得到三个信息(x,y,σ,θ),即位置、尺度(m(x,y))和方向。具有多个方向的关键点可以被复制成多份,然后将方向值分别赋给复制后的特征点,一个特征点就产生了多个坐标、尺度相等,但是方向不同的特征点。
然后咋用这些点?看下面
8.生成特征描述
在完成关键点的梯度计算后,使用直方图统计邻域内像素的梯度和方向。
为了简单起见,只统计8个方向(0-45, 45-90, 90-135,135-180, 180-235, 235-270, 270-315, 315-360)
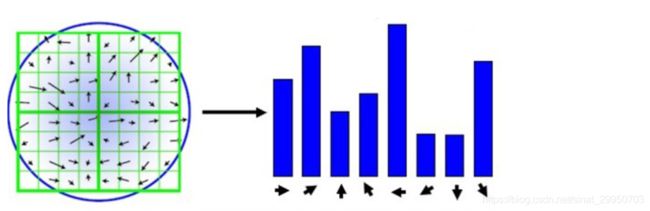
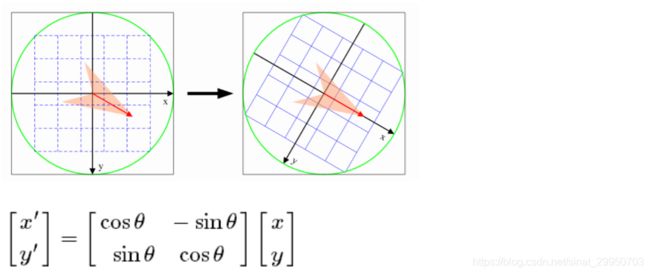
为了保证特征矢量的旋转不变性,要以特征点为中心,在附近邻域内将坐标轴旋转θ角度,即将坐标轴旋转为特征点的主方向。
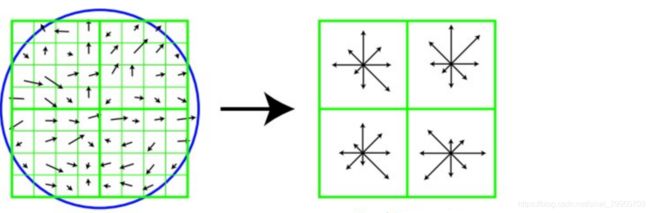
旋转之后的主方向为中心取8x8的窗口,求每个像素的梯度幅值和方向,箭头方向代表梯度方向,长度代表梯度幅值,然后利用高斯窗口对其进行加权运算,最后在每个4x4的小块上绘制8个方向的梯度直方图,计算每个梯度方向的累加值,即可形成一个种子点,即每个特征的由4个种子点组成,每个种子点有8个方向的向量信息。
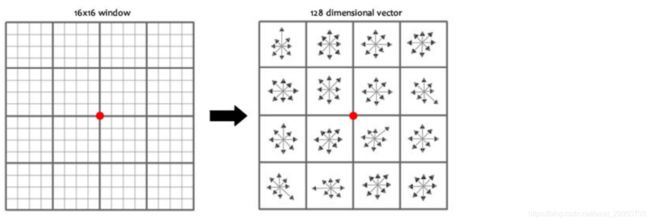
论文中建议对每个关键点使用4x4共16个种子点来描述,这样一个关键点就会产生128维的SIFT特征向量。
OpenCV中的Sift操作
OpenCV大于3.4版本 就对sift进行专利保护了,所以想免费使用的,看看sift效果的,降低一下版本吧
卸载 pip uninstall opencv-python
安装 pip install opencv-contrib-python==3.4.1.15
里面有很多包 pip install opencv-contrib-python==3.4.1.15
- 1
- 2
- 3
import cv2
import numpy as np
img = cv2.imread(‘test_1.jpg’)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
print(cv2.version) # 3.4.1.15
- 1
- 2
- 3
- 4
- 5
- 6
得到特征点 kp, 直接用drawKeypoints绘制关键点
sift = cv2.xfeatures2d.SIFT_create()
kp = sift.detect(gray, None)
img = cv2.drawKeypoints(gray, kp, img)
cv2.imshow(‘drawKeypoints’, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
计算特征 sift.compute
还是关键点kp 和 关键点相应的特征des (每个关键点都转化为128维向量)
kp, des = sift.compute(gray, kp)
print (np.array(kp).shape) # (6827,) 原来是list, 用np转化一下, 就可以看shape了
# des.shape # (6827, 128)
# des[0]
'''
array([ 0., 0., 0., 0., 0., 0., 0., 0., 21., 8., 0.,
0., 0., 0., 0., 0., 157., 31., 3., 1., 0., 0.,
2., 63., 75., 7., 20., 35., 31., 74., 23., 66., 0.,
0., 1., 3., 4., 1., 0., 0., 76., 15., 13., 27.,
8., 1., 0., 2., 157., 112., 50., 31., 2., 0., 0.,
9., 49., 42., 157., 157., 12., 4., 1., 5., 1., 13.,
7., 12., 41., 5., 0., 0., 104., 8., 5., 19., 53.,
5., 1., 21., 157., 55., 35., 90., 22., 0., 0., 18.,
3., 6., 68., 157., 52., 0., 0., 0., 7., 34., 10.,
10., 11., 0., 2., 6., 44., 9., 4., 7., 19., 5.,
14., 26., 37., 28., 32., 92., 16., 2., 3., 4., 0.,
0., 6., 92., 23., 0., 0., 0.], dtype=float32)
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
三、特征匹配
- cv2.drawMatches(imageA, kpsA, imageB, kpsB, matches[:10], None, flags=2) # 对两个图像关键点进行连线操作
参数说明:imageA和imageB表示图片,kpsA和kpsB表示关键点, matches表示进过cv2.BFMatcher获得的匹配的索引值,也有距离, flags表示有几个图像
书籍的SIFT特征点连接:
第一步:使用sift.detectAndComputer找出关键点和sift特征向量
第二步:构建BFMatcher()蛮力匹配器,bf.match匹配sift特征向量,使用的是欧式距离
第三步:根据匹配结果matches.distance对matches按照距离进行排序
第四步:进行画图操作,使用cv2.drawMatches进行画图操作
- bf.match(des1, des2) 1 对 1 匹配
- bf.knnMatch(des1, des2, k=2) k对最佳匹配,此处是1个点最多可以跟2个点匹配
import cv2
import numpy as np
img1 = cv2.imread(‘box.png’, 0)
img2 = cv2.imread(‘box_in_scene.png’, 0)
def cv_show(name,img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv_show(‘img1’,img1)
cv_show(‘img2’,img2)
# 第一步:构造sift,求解出特征点和sift特征向量
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# 第二步:构造BFMatcher()蛮力匹配,匹配sift特征向量距离最近对应组分
# crossCheck 表示两个特征点要互相匹,
# 例如A中的第i个特征点与B中的第j个特征点最近的,并且B中的第j个特征点到A中的第i个特征点也是
# NORM_L2: 归一化数组的(欧几里德距离),如果其他特征计算方法需要考虑不同的匹配计算方式
bf = cv2.BFMatcher(crossCheck=True)
# 获得匹配的结果【1 对 1 匹配】
matches = bf.match(des1, des2)
#第三步:对匹配的结果按照距离进行排序操作
matches = sorted(matches, key=lambda x: x.distance)
# 第四步:使用cv2.drawMacthes进行画图操作
# 只画前10个点
img3 = cv2.drawMatches(img1, kp1, img2, kp2, matches[:10], None,flags=2)
cv_show(‘img3’,img3)
# 【k对最佳匹配】
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)
good = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good.append([m])
# good所有点都显示,就会有很多连线了
img4 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=2)
cv_show(‘img4’,img4)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46


四、图像拼接
from Stitcher import Stitcher
import cv2
# 读取拼接图片
imageA = cv2.imread(“left_01.png”)
imageB = cv2.imread(“right_01.png”)
# 把图片拼接成全景图
stitcher = Stitcher()
(result, vis) = stitcher.stitch([imageA, imageB], showMatches=True)
# 显示所有图片
cv2.imshow(“Image A”, imageA)
cv2.imshow(“Image B”, imageB)
cv2.imshow(“Keypoint Matches”, vis)
cv2.imshow(“Result”, result)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18


Stitcher的 stitch函数 检测流程 简述:
- img A 和 img B做sift检测
- 匹配特征点(具体看matchKeypoints流程)
- 提取匹配结果,其中
H是单应性矩阵 - 对A进行H的视角变换
- 将图片B传入result图片最左端
- 检测是否需要显示图片匹配
matchKeypoints流程:
- 建立暴力匹配器
- k对匹配
- 当筛选后的匹配对大于4时,计算视角变换矩阵
其中findHomography: 计算多个二维点对之间的最优单映射变换矩阵 H(3行x3列),使用最小均方误差或者RANSAC(原理,匹配效果)方法
Stitcher.py 完整代码如下:
import numpy as np
import cv2
class Stitcher:
# 拼接函数
def stitch(self, images, ratio=0.75, reprojThresh=4.0,showMatches=False):
#获取输入图片
(imageB, imageA) = images
# 1.检测A、B图片的SIFT关键特征点,并计算特征描述子
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
# 2.匹配两张图片的所有特征点,返回匹配结果
M = self.matchKeypoints(kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh)
# 如果返回结果为空,没有匹配成功的特征点,退出算法
if M is None:
return None
# 3. 否则,提取匹配结果
# H是3x3视角变换矩阵
(matches, H, status) = M
# 4.将图片A进行视角变换,result是变换后图片
result = cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
self.cv_show('result', result)
# 5.将图片B传入result图片最左端
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
self.cv_show('result', result)
# 6.检测是否需要显示图片匹配
if showMatches:
# 生成匹配图片
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches, status)
# 返回结果
return (result, vis)
# 返回匹配结果
return result
def cv_show(self,name,img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def detectAndDescribe(self, image):
# 将彩色图片转换成灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 建立SIFT生成器
descriptor = cv2.xfeatures2d.SIFT_create()
# 检测SIFT特征点,并计算描述子
(kps, features) = descriptor.detectAndCompute(image, None)
# 将结果转换成NumPy数组
kps = np.float32([kp.pt for kp in kps])
# 返回特征点集,及对应的描述特征
return (kps, features)
def matchKeypoints(self, kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh):
# 1.建立暴力匹配器
matcher = cv2.BFMatcher()
# 2.使用KNN检测来自A、B图的SIFT特征匹配对,K=2
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
matches = []
for m in rawMatches:
# 当最近距离跟次近距离的比值小于ratio值时,保留此匹配对
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
# 存储两个点在featuresA, featuresB中的索引值
matches.append((m[0].trainIdx, m[0].queryIdx))
# 3.当筛选后的匹配对大于4时,计算视角变换矩阵
if len(matches) > 4: # 至少4对,8个方程的单应性矩阵
# 获取匹配对的点坐标
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
# 计算视角变换矩阵
(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)
# 返回结果
return (matches, H, status)
# 4.如果匹配对小于4时,返回None
return None
def drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status):
# 初始化可视化图片,将A、B图左右连接到一起
(hA, wA) = imageA.shape[:2]
(hB, wB) = imageB.shape[:2]
vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")
vis[0:hA, 0:wA] = imageA
vis[0:hB, wA:] = imageB
# 联合遍历,画出匹配对
for ((trainIdx, queryIdx), s) in zip(matches, status):
# 当点对匹配成功时,画到可视化图上
if s == 1:
# 画出匹配对
ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))
ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))
cv2.line(vis, ptA, ptB, (0, 255, 0), 1)
# 返回可视化结果
return vis
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106