【C语言字符和字符串的库函数的使用注意事项和模拟】

文章目录
- 前言
- 一、求字符串长度的strlen函数
-
- 1.1 基本语法
- 1.2 注意事项
- 1.3 模拟实现strlen函数
-
- 1.3.1 计数器方法实现
- 1.3.2 递归方法实现
- 1.3.3 指针相减的方法实现
- 1.4 strlen库函数源码查看
- ==长度不受限制的字符串函数:(二、三、四)==
- 二、复制字符串strcpy函数
-
- 2.1 基本语法
- 2.2 注意事项
- 2.3 模拟实现strcpy函数
- 2.4 strcpy库函数源码查看
- 三、追加字符串strcat函数
-
- 3.1 基本语法
- 3.2 注意事项
- 3.3 模拟实现strcat函数
- 3.4 strcat库函数源码查看
- 四、字符串比较strcmp函数
-
- 4.1 基本语法
- 4.2 注意事项
- 4.3 模拟实现strcmp函数(和特殊②结果不同)
-
- 4.3.1 版本1
- 4.3.2 版本2
- 4.4 strcmp库函数源码查看
- ==长度受限制的字符串函数:(五、六、七)==
- 五、复制字符串strncpy函数
-
- 5.1 基本语法
- 5.3 注意事项
- 5.4 模拟实现strncpy函数
- 5.5 strncpy库函数源码查看
- 六、追加字符串strncat函数
-
- 6.1 基本语法
- 6.2 注意事项
- 6.3 模拟实现strncat函数(有变动,允许==源==字符串不以'\0'结束)
- 6.4 strncat库函数源码查看
- 七、字符串比较strncmp函数
-
- 7.1 基本语法
- 7.2 注意事项
- 7.3 模拟实现strncmp函数(不考虑特殊情况②)
- 7.4 strncmp库函数源码查看
- ==字符串查找函数:(八、九)==
- 八、字符串查找strstr函数
-
- 8.1 基本语法
- 8.2 注意事项
- 8.3 模拟实现strstr函数
-
- 8.3.1 版本1(两个指针来控制)
- 8.3.2 版本2(三个指针来控制,前提str1和str2都完整)
- 8.3.3 版本3(KMP算法)
- 九、分隔字符串strtok函数
-
- 9.1 基本语法
- 9.2 注意事项
- 9.3 使用举例
- ==错误信息报告:(十)==
- 十、返回错误信息strerror函数
-
- 10.1 基本语法
- 10.2 注意事项
- 10.3 使用举例
- 10.4 补充用法
-
- 10.4.1 补充用法使用说明
- 10.4.2 fopen函数基本语法说明
- 10.4.3 补充用法使用举例
- ==字符操作:(十一)==
- 十一、字符分类函数
- 总结
前言
本文主要介绍:
①处理字符和字符串的库函数的使用和注意事项;
②部分库函数的模拟。
一、求字符串长度的strlen函数
1.1 基本语法

1.2 注意事项
- 字符串以’\0’作为结束标志,strlen函数返回的是在字符串中’\0’前面出现的字符个数(不包含’\0’);
- 参数指向的字符串必须要以’\0’结束,否则strlen函数无法找到所需计算位置的结束标志,则会在内存继续向后读取,直到遇到’\0’;
- 注意:函数的返回值为size_t,是无符号的,例:
#include 我们预期:“abc”的长度明显更小,所以strlen(“abc”) - strlen(“abcdef”)<0,输出值为<,但是输出值为>,不符合预期。

这就是因为函数的返回值为size_t,是无符号的,所以误将-3识别为无符号整数,所以识别为一个非常大的正整数,输出值为>。
解决方案:(将strlen函数的返回值强制转换为int(int默认为有符号整形unsigned int))
#include 
1.3 模拟实现strlen函数
1.3.1 计数器方法实现
#include 1.3.2 递归方法实现
#include 1.3.3 指针相减的方法实现
// 方法3:(指针相减的方法)
int My_Strlen(const char* str) // const保护str所指内容不被改变
{
assert(str);
char* end = str;
// 相当while ('\0' != *end)
while (*end) {
end++;
}
// 最后end指向'\0'
return end - str;
// 或者:
//while (*mask++) { //方法2,这样的话指针会指向‘\0’的后面,
// //画图分析即可,所以return后额外减去1
// ;
//}
//return mask - arr - 1;
}
int main()
{
char str[20] = {0};
scanf("%s", str);
int len = My_Strlen(str);
printf("%d\n", len);
return 0;
}
1.4 strlen库函数源码查看
/***
*strlen.c - contains strlen() routine
*
* Copyright (c) Microsoft Corporation. All rights reserved.
*
*Purpose:
* strlen returns the length of a null-terminated string,
* not including the null byte itself.
*
*******************************************************************************/
#include 和指针相减方法实现的模拟函数思路基本相同。
长度不受限制的字符串函数:(二、三、四)
二、复制字符串strcpy函数
2.1 基本语法

2.2 注意事项
- 源字符串必须以’\0’结束;
- 会将源字符串中的’\0’拷贝到目标空间;
- 目标空间必须足够大,以确保能存放源字符串;
- 目标空间必须可变(不能为const,否则会引发异常:访问冲突);
- 目标字符串可以已经有内容,源字符串可以放入已有内容的字符空间内。例:
#include 调试到代码提示的位置,查看监视arr2:
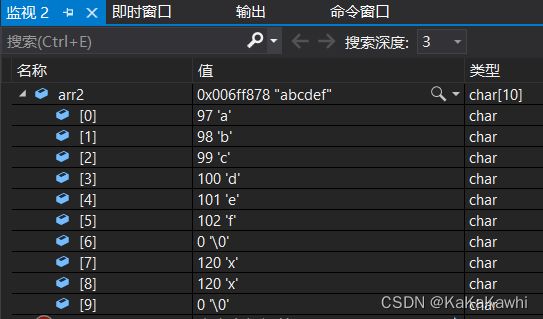
2.3 模拟实现strcpy函数
#include 2.4 strcpy库函数源码查看
/*
** Copy the string contained in the second argument to the
** buffer specified by the first argument.
*/
void
strcpy( char *buffer, char const *string )
{
/*
** Copy characters until a NUL byte is copied.
*/
while( (*buffer++ = *string++) != '\0' )
;
}
和实现的模拟函数代码思路基本相同。
三、追加字符串strcat函数
3.1 基本语法

3.2 注意事项
- 源字符串必须以’\0’结束;
- 目标空间必须足够大,能容纳下源字符串的内容;
- 目标空间必须可修改;
- 目标字符串必须以’\0’结束(因为源代码根据目标空间的’\0’作为追加的位置,char str1[20] = "abcdef\0aaaaaaa"和char str1[20] = {‘a’,‘b’,‘c’,‘d’,‘e’,‘f’},都以’\0’结尾,因为空间必须保证足够大,未初始化的部分自动初始化为’\0’)
- 字符串自己给自己追加:
#include 引发异常:
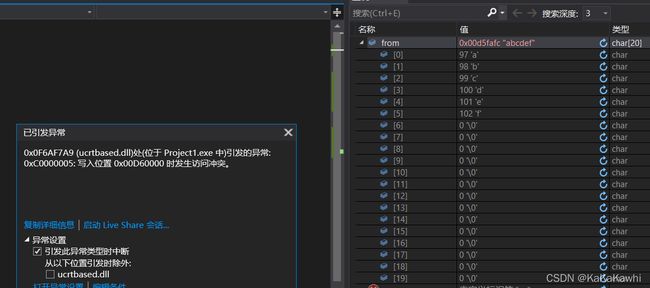
3.3 模拟实现strcat函数
#include 3.4 strcat库函数源码查看
/***
*char *strcat(dst, src) - concatenate (append) one string to another
*
*Purpose:
* Concatenates src onto the end of dest. Assumes enough
* space in dest.
*
*Entry:
* char *dst - string to which "src" is to be appended
* const char *src - string to be appended to the end of "dst"
*
*Exit:
* The address of "dst"
*
*Exceptions:
*
*******************************************************************************/
char * __cdecl strcat (
char * dst,
const char * src
)
{
char * cp = dst;
while( *cp )
cp++; /* find end of dst */
while((*cp++ = *src++) != '\0') ; /* Copy src to end of dst */
return( dst ); /* return dst */
}
源码思路和模拟函数代码基本相同。
四、字符串比较strcmp函数
4.1 基本语法

4.2 注意事项
- 字符串比较的是对应位置上的字符大小,该位置相同情况下则比较下个字符,直到有大小之分,或者最后比较结束均相同,则返回0;
- 比较字符比较的是该字符对应的ASCII码。
- 在VS下底层通过返回-1,0,1来实现返回负数,零,整数,而标准规定返回正负零,而不是-1,0,1,所以在模拟时需注意;
- 特殊情况①说明:如果如下两个字符串相比较(前面的字符都相同,字符串长短不同):
char str1[] = "abcdef";
char str2[] = "abcde";
则当str1指针指向’f’时,实际str2指针指向的是字符串最后的’\0’,’\0’的ASCII码值为0,所以‘f’的ASCII一定大于0,所以最终比较结果是str1大于str2。
- 特殊情况②说明:如果如下两个字符串相比较(前面的字符都相同,字符串长短不同):
#include 
4.3 模拟实现strcmp函数(和特殊②结果不同)
在VS下底层通过返回-1,0,1来实现返回负数,零,整数,而标准规定返回正负零,而不是-1,0,1,所以在模拟时需注意
4.3.1 版本1
#include 4.3.2 版本2
#include 4.4 strcmp库函数源码查看
/***
*strcmp.c - routine to compare two strings (for equal, less, or greater)
*
* Copyright (c) Microsoft Corporation. All rights reserved.
*
*Purpose:
* Compares two string, determining their ordinal order.
*
*******************************************************************************/
#include ※※※源码的思路大概为:
当两个指针所指位置的字符相同且不为’\0’时,两个指针同时后移,当不满足该循环条件(①两指针所指位置的字符不同;②两指针所指位置的字符均为’\0’;③某个指针所指字符为’\0’,此时两指针所指字符必不相同),先将不满足循环条件时的两指针内容相减的结果赋值给ret变量,然后退出循环,返回ret,此时ret就记录了最后退出循环时的两字符比较结果。
长度受限制的字符串函数:(五、六、七)
五、复制字符串strncpy函数
5.1 基本语法

5.3 注意事项
- 拷贝count个字符从源字符串到目标空间;
- 如果源字符串的长度小于count,则拷贝完源字符串之后,在目标后追加0,直到count个;
- 如果源字符串的长度大于count,则拷贝源字符串中的count个字符。
- count不能大于目标字符串的长度(如果目标字符串是通过初始化赋值字符串来定义大小的,类似char str[] = “abc”,则count最大值为字符串长度加1(加的是最后的’\0’);如果类似char str[20] = “abc”,初始化时已规定大小,则count最大值为20,否则会溢出,总之,count最大值为sizeof(str) / sizeof(str[0]));
- 目标空间必须可变(不能为const,否则会引发异常:访问冲突,例const char* str1 = “abcdef”);
- 目标字符串可以已经有内容,源字符串可以放入已有内容的字符空间内;
- 源字符串不需要必须以’\0’结束。
5.4 模拟实现strncpy函数
#include 5.5 strncpy库函数源码查看
/***
*strncpy.c - copy at most n characters of string
*
* Copyright (c) Microsoft Corporation. All rights reserved.
*
*Purpose:
* defines strncpy() - copy at most n characters of string
*
*******************************************************************************/
#include 源码先通过count && (*dest++ = *source++) != ‘\0’来将源字符串、目标字符串长度都小于count,且都不为’\0’的字符段完成复制,然后剩余的count如果大于0,则再目标字符串后加剩余count数量个’\0’。
但是,自己测试当count大于源字符串长度和大于目标字符串长度时有点问题。待解决。
六、追加字符串strncat函数
6.1 基本语法

6.2 注意事项
- 目标空间必须足够大,能容纳下源字符串的内容;
- 目标空间必须可修改;
- 目标字符串必须以’\0’结束(因为源代码根据目标空间的’\0’作为追加的位置,char str1[20] = "abcdef\0aaaaaaa"和char str1[20] = {‘a’,‘b’,‘c’,‘d’,‘e’,‘f’},都以’\0’结尾,因为空间必须保证足够大,未初始化的部分自动初始化为’\0’)
- 源字符串必须以’\0’结束;
- 特殊情况①:当count小于源字符串长度时,复制源字符串的count个字符到目标空间,并在最后追加一个’\0’,见下;
#include 调试到printf步骤:
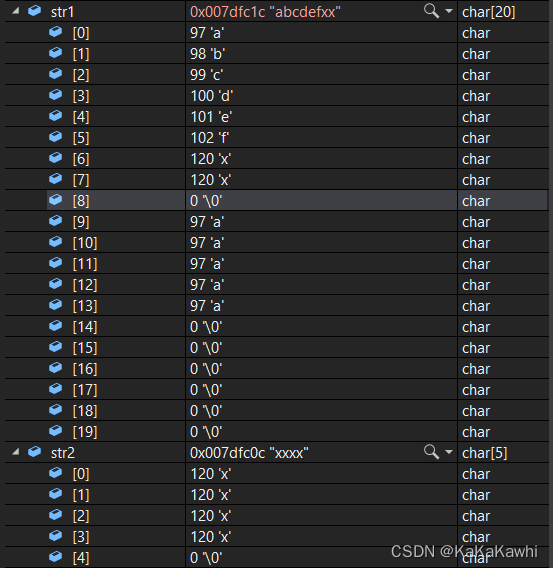
- 特殊情况②:当count大于源字符串长度时,复制源字符串的所有到目标空间,并在最后追加一个’\0’,目标后续其他字符不变动,见下;
#include 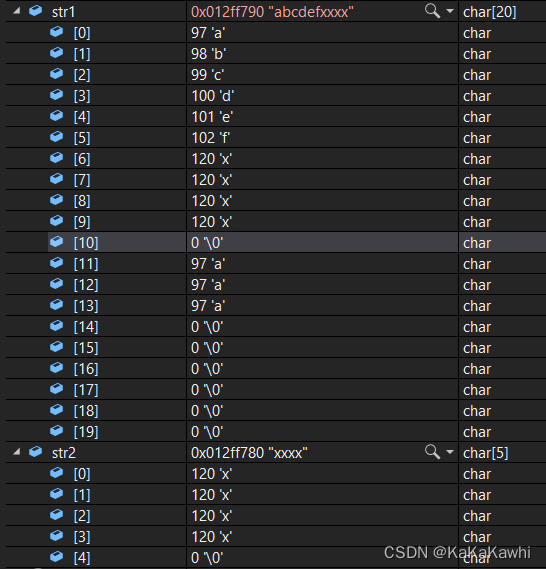
6.3 模拟实现strncat函数(有变动,允许源字符串不以’\0’结束)
#include 6.4 strncat库函数源码查看
/***
*strncat.c - append n chars of string to new string
*
* Copyright (c) Microsoft Corporation. All rights reserved.
*
*Purpose:
* defines strncat() - appends n characters of string onto
* end of other string
*
*******************************************************************************/
#include 源码分析:
先找到目标空间的’\0’,然后循环count次,中途如果遇到源字符串中的’\0’则说明count大于源字符长度,追加完毕,返回;
如果循环count次中途没有退出,则说明count小于源字符长度,追加count个字符,完毕后,返回。
七、字符串比较strncmp函数
7.1 基本语法

7.2 注意事项
- 比较到出现一个字符不一样,或者一个字符串结束,或者count个字符全部比较完;
- 字符串比较的是对应位置上的字符大小,该位置相同情况下则比较下个字符,直到有大小之分,或者count个字符比较结束均相同,则返回0;
- 比较字符比较的是该字符对应的ASCII码。
- 在VS下底层通过返回-1,0,1来实现返回负数,零,整数,而标准规定返回正负零,而不是-1,0,1,所以在模拟时需注意;
- 特殊情况①说明:如果如下两个字符串相比较(前面的字符都相同,字符串长短不同):
#include 
- 特殊情况②说明:如果如下两个字符串相比较(前面的字符都相同,字符串长短不同):
#include 
7.3 模拟实现strncmp函数(不考虑特殊情况②)
#include 7.4 strncmp库函数源码查看
/***
*strncmp.c - compare first n characters of two strings
*
* Copyright (c) Microsoft Corporation. All rights reserved.
*
*Purpose:
* defines strncmp() - compare first n characters of two strings
* for ordinal order.
*
*******************************************************************************/
#include 不懂- -待补充
字符串查找函数:(八、九)
八、字符串查找strstr函数
8.1 基本语法

8.2 注意事项
- 无法查找空字符串,如果查找的str2是空字符串,则返回的就是str1指针;
- 如果找到,函数返回的指针是字符串str2首次出现在字符串str1中的位置,如果没有找到,则返回NULL。
- 查找的是连续、完整的子串(说明见下),例见下;
代码①(所查找的字符串连续且完整):
#include 
代码②(所查找的字符串连续但不完整):
#include 代码③(所查找的字符串连续且完整):
#include 综上:完整代表该字符串包含结尾处的’\0’。
- str1字符串无特殊要求,如果查找成功即返回首次出现在字符串str1中的位置,结尾有无’\0’仅是打印结果不同。
8.3 模拟实现strstr函数
8.3.1 版本1(两个指针来控制)
#include
// 如果执行完循环后,*str1 == '\0',则说明查找失败
if (*str1 == '\0') {
return NULL;
}
else {
return (char*)str1; // 因为str1为const char*类型,避免编译器警告
}
}
int main()
{
char str1[] = "abcde";
char str2[] = "cd";
int len2 = strlen(str2);
char* ret = My_Strstr(str1, str2, len2);
if (NULL == ret) {
printf("没找到\n");
}
else {
printf("%s\n", ret);
}
return 0;
}
}
8.3.2 版本2(三个指针来控制,前提str1和str2都完整)
#include 8.3.3 版本3(KMP算法)
待补充
九、分隔字符串strtok函数
9.1 基本语法

9.2 注意事项
- str2参数是个字符串,定义了用作分隔符的字符集合;
- 第一个参数指定一个字符串,它包含了0个或者多个由str2字符串中一个或者多个分隔符分割的标记。
- strtok函数找到str1中的下一个标记,并将其用 \0 结尾,返回一个指向这个标记的指针。(注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。)
- strtok函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置。(strtok函数找第一个标记的时候,函数的第一个参数不是NULL)
- strtok函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标记。(strtok函数找非第一个标记的时候,函数的第一个参数是NULL)
- 如果字符串中不存在更多的标记,则返回 NULL 指针。
9.3 使用举例
代码①:
#include 
代码②:(代码①的基础上优化)
#include 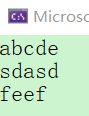
错误信息报告:(十)
十、返回错误信息strerror函数
10.1 基本语法

10.2 注意事项
- C语言中规定了一些信息,strerror函数返回错误码所对应的错误信息;
10.3 使用举例
#include 
10.4 补充用法
10.4.1 补充用法使用说明
- 当库函数使用的时候,发生错误会把errno这个全局的错误变量设置为本次执行库函数产生的错误码;
- errno是C语言提供的一个全局变量,可以直接使用,放在errno.h文件中的,使用时需包含头文件:#include
10.4.2 fopen函数基本语法说明

10.4.3 补充用法使用举例
使用举例:
说明
#include 
字符操作:(十一)
十一、字符分类函数
| 函数 | 如果他的参数符合下列条件就返回真 |
|---|---|
| iscntrl | 任何控制字符 |
| isspace | 空白字符:空格‘ ’,换页‘\f’,换行’\n’,回车‘\r’,制表符’\t’或者垂直制表符’\v’ |
| isdigit | 十进制数字 0-9(字符) |
| isxdigit | 十六进制数字(字符),包括所有十进制数字(字符),小写字母a-f,大写字母A-F |
| islower | 小写字母a-z |
| isupper | 大写字母A-Z |
| isalpha | 字母a-z或A-Z |
| isalnum | 字母或者数字(字符),a-z,A-Z,0-9 |
| ispunct | 标点符号,任何不属于数字或者字母的图形字符(可打印) |
| isgraph | 任何图形字符 |
| isprint | 任何可打印字符,包括图形字符和空白字符 |
| int tolower ( int c ); | 大写转换小写 |
| int toupper ( int c ); | 小写转换大写 |
对于isdigit函数:
int main()
{
char c = '3';
// 判断字符数字是否为十进制0-9
// 方法1
if (c > '0' && c < '9') {
printf("bingo\n");
}
// 方法2(更好)
if (isdigit(c)) {
printf("bingo\n");
}
return 0;
}
对于大小写转换函数(tolower和toupper):
int main()
{
char c = 'a';
if (islower(c)) {
c = toupper(c);
}
else {
c = tolower(c);
}
printf("%c\n", c);
return 0;
}
总结
这里对文章进行总结:
以上就是今天总结的内容,本文包括了C语言字符和字符串的库函数的使用注意事项和模拟,分享给大家。
真欢迎各位给予我更好的建议,欢迎访问!!!小编创作不易,觉得有用可以一键三连哦,感谢大家。peace
希望大家一起坚持学习,共同进步。梦想一旦被付诸行动,就会变得神圣。
欢迎各位大佬批评建议,分享更好的方法!!!