pandas追加写入excel_pandas数据读取
今天呢就给大家分享一个数据分析里面的基础内容之pandas数据读取
数据读取是进行数据预处理,建模与分析的前提,不同的数据源,需要使用不同的函数读取,pandas内置了10余种数据源读取函数和对应的数据写入函数,常见的数据源有3种,分别是数据库数据,文本文件(包含一般文本文件和CSV文件)和Excel文件,掌握这三种数据源读取方法,便能够完成80%左右的数据读取工作。下面我们具体瞅瞅;
读/写数据库数据
在生产环境中,绝大多数的数据都存储在数据库中,pandas提供了读取与存储关系型数据库数据的函数和方法,除pandas库外,还需要使用SQLAlchemy库建立对应的数据库连接,SQLAlchemy配合相应数据库的python连接工具(如,mysql数据库需要安装mysqlclient或者pymysql库,Oracle数据库需要安装cx_oracle库),使用create_engine函数建立一个数据库连接,pandas支持mysql,postgtrsql,Oracle,Sql server和SQLite等主流数据库,下面将以mysql数据库为例,介绍pandas数据库数据得到读取与存储。
数据库数据读取
pandas实现数据库数据读取有三个函数,read_sql,read_sql_table和read_sql_query,read_sql_table只能读取数据库的某一个表格,不能实现查询的操作,read_sql_query则只能实现查询操作,不能直接读取数据库中的某个表,read_sql是俩者的结合,既能够读取数据库中的某一个表,也能够实现查询操作。
三个函数的语法如下
#导入相关的包from sqlalchemy import create_engineimport pandas as pdpd.read_sql_table(table_name,con, schema=None, index_col=None, coerce_float=True, parse_dates=None,columns=None, chunksize=None)pd.read_sql_query(sql, con, index_col=None,coerce_float=True, params=None, parse_dates=None,chunksize=None)pd.read_sql(sql, con, index_col=None, coerce_float=True,params=None, parse_dates=None, columns=None, chunksize=None)SQLAlchemy连接数据库的代码如下:
from sqlalchemy import create_engine#创建一个mysql连接器,用户名为root,密码为1234#地址为127.0.0.1.数据库名称为testdb,编码为utf-8#注意实验时请填写自己的数据库信息engine = create_engine('mysql+pymysql://root:[email protected]:3306/testdb?charset=utf8')print(engine)在create_engine中输入的是一个连接字符串,在使用python的sqlAlchemy时,mysql和oracle数据库连接字符串的格式如下:
数据库产品名+连接工具名://用户名:密码@数据库ip地址:数据库端口号/数据库名称?charset=数据库数据编码
上述三种函数参数及其重要参数说明 |
|
sql or table_name |
接受string,表示读取的数据的表名或者sql语句无默认 |
con |
接受数据库连接,表示数据库连接信息,无默认 |
index_col |
接受int,sequence或者False,表示设定的列作为行名,如果是一个数列,则是多重索引,默认为None |
coerce_float |
接受boolean,将数据库中的decimal类型的数据转换为pandas中的float64类型的数据,默认为True |
columns |
接受int,表示读数据的列明,默认为None |
使用read_sql_table,read_sql_query,read_sql函数读取数据库数据;
from sqlalchemy import create_engineimport pandas as pdengine =create_engine('mysql+pymysql://root:Huawei12#[email protected]:3306/example?charset=utf8')print(engine)#打印结果如下#Engine(mysql+pymysql://root:***@192.168.1.45:3306/example?charset=utf8)#使用read_sql_query查看example中的数据表数目formlist =pd.read_sql_query('show tables',con=engine)print('example数据库中的表清单为:\n',formlist) 
#使用read_sql_table读取订单详情表atail1 = pd.read_sql_table('meal_order_detail1',con=engine)print('使用read_sql_table读取订单表的长度为:',len(datail1))

#使用read_sql读取订单详情表detail2 = pd.read_sql('select * frommeal_order_detail2',con=engine)print('使用read_sql函数+SQL语句读取的订单详情表长度为:',len(detail2))detail3 =pd.read_sql('meal_order_detail3',con=engine)print('使用read_sql函数+表格名称读取的订单详情表的长度为:',len(detail3))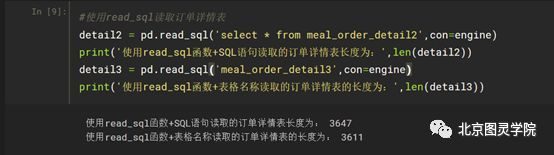
数据库数据存储
将DataFrame写入数据库中,同样也要依赖SQLALchemy库的create_engine函数创建数据库连接,数据库数据读取有3个函数,但数据存储则只有一个to_sql方法,用例如下:
df.to_sql(name,con,schema=None,if_exists='fail',index=True,index_label=None,dtype=None)to_sql方法常用参数及说明 |
|
name |
接收string,代表数据库表明,无默认 |
con |
接收数据库连接,无默认 |
if_exists |
接收fail,replace和append,fail表示如果表名存在,则不执行写入操作,replace表示如果存在,则将原数据库表删除,在重新创建,append则表示在原数据表的基础上追加数据,默认为fail |
index |
接收boolean,表示是否将行索引作为数据传入数据库,默认为True |
index_label |
接收string或者sequence,代表是否引用所用名称,如果index参数为True,此参数为None,则使用默认名称,如果为多重索引,则必须使用sequence形式,默认为None |
dtype |
接收dict,代表写入的数据类型(列明为key,数据格式为values),默认为None |
使用to_sql方法写入数据
#使用to_sql存储orderDatadatail1.to_sql('test1',con=engine,index=False,if_exists='replace')#使用read_sql读取test表formlist1= pd.read_sql_query('show tables',con=engine)print('新增一个表格后,example数据库表清单为:\n',formlist1)
读写文本文件
文本文件是一种由若干行字符构成的计算机文件,他是一种典型的顺序文件,CSV是一种用分隔符分割的文件格式,因为其分隔符不一定是逗号,因此又称为字符分隔文件,文件以纯文本形式存储表格数据,他是一种通用,相对简单的文件格式,最广泛的应用是在程序之间转义表格数据,而这些程序本身是在不兼容的格式上进行操作的,因为大量程序都支持CSV或者其变体,因此可以作为大多数程序的输入和输出格式。
文本文件读取
pandas提供了read_table来读取文本文件,提供了read_csv函数来读取CSV文件,二者语法如下:

read_table和read_csv常用参数及其说明 |
|
参数名称 |
说明 |
filepath |
接受string,代表文件路径,无默认 |
sep |
接受string,代表分隔符,read_csv默认为“,”,read_table默认为制表符“tab” |
header |
接受int或sequence表示将某行数据作为列明,默认为诶infer,表示自动识别 |
names |
接受aray,表示列明,默认为None |
index_col |
接受int,sequence或False,表示索引列的位置,取值为sequence则代表多重索引,默认为None |
dtype |
接收dict,代表写入的数据类型(列明为key,数据格式为values),默认为None |
engine |
接受c或者python,代表数据解析引擎,默认为c |
nrows |
接受int,表示读取前n行,默认为None |
使用read_table和read_csv函数读取菜品订单信息表
#使用read_table读取菜品订单信息表# order = pd.read_table('../Python数据分析与应用/第4章/任务程序/data/meal_order_info.csv',sep=',',encoding='gbk')#len(order)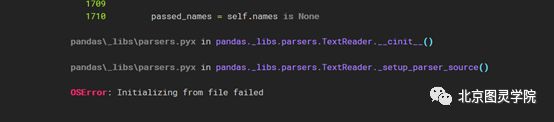
在读取过程中,有时候你会遇到这种报错,莫得荒,我也不知道为啥,但是我们可以通过读取文件的方式读取文本,如下:
f=open('../meal_order_info.csv')order=pd.read_table(f,sep=',',encoding='utf-8')len(order)order1 = pd.read_csv('../meal_order_info.csv',encoding='utf-8',engine='python')len(order1)更改参数读取表的订单信息
f=open('../meal_order_info.csv')order2=pd.read_table(f,sep=';',encoding='utf-8')order3 = pd.read_csv('../meal_order_info.csv',encoding='gbk',header=None,engine='python')len(order3)文本文件存储
文本文件的存储和读取类似,对于结构化数据,可以通过pandas中的to_csv函数实现,常用参数与语法如下:
to_csv(path_or_buf=None, sep=',', na_rep='',float_format=None, columns=None, header=True, index=True, index_label=None,mode='w', encoding=None, compression=None, quoting=None, quotechar='"',line_terminator='\n', chunksize=None, tupleize_cols=None, date_format=None,doublequote=True, escapechar=None, decimal='.')to_csv函数的常用参数及其说明 |
|
参数名称 |
说明 |
path_or_buf |
接受string,代表文件路径,无默认 |
sep |
接受string,代表分隔符,默认为逗号 |
na_rep |
接受string,代表缺失值,默认为“” |
columns |
接受list,代表写出的列名,默认为“” |
header |
接受boolean,代表是否将列明写出,默认为True |
index |
接受布尔,代表是否将行名(索引)写出,默认为True |
index_label |
接受sequence。代表索引名,默认为None |
mode |
接受特定的string,代表数据写入模式,默认为w |
encoding |
代表文件的编码格式 |
使用to_csv函数将数据写入CSV文件中
#将order以csv格式存储order.to_csv('../tmp/orderInfo.csv',sep=';',index=False)os.listdir('../tmp')
读写Excel文件
Excel是微软公司的办公软件Microsoft office的组件之一,他可以对数据进行处理,统计分析等操作,广泛的应用与管理,财经和金融等众多领域。
Excel文件读取
pandas提供了read_excel函数来读取"xls",“xlsx”俩种excel文件,其语法如下:
pd.read_excel(io, sheet_name=0, header=0, names=None,index_col=None, usecols=None, squeeze=False, dtype=None, engine=None,converters=None, true_values=None, false_values=None, skiprows=None,nrows=None, na_values=None, parse_dates=False, date_parser=None,thousands=None, comment=None, skipfooter=0, convert_float=True, **kwds)read_excel该函数常用参数及其说明 |
|
参数名称 |
说明 |
io |
接收string,表示文件路径,无默认 |
sheetname |
接收string,int,代表Execl表内数据的分表位置,默认为0 |
header |
接受int或sequence,表示将某行数据作为列明,取值为int的时候,代表将列作为列名,取值为sequence,则代表多重索引,默认为infer,表示自动识别 |
names |
接受array,表示列明,默认为None |
index_col |
接受int,sequence或者false,表示索引列的位置,取值sequence嗲表多重索引,默认为None |
dtype |
接受dict,代表写入的数据类型 |
使用read_excel函数读取菜品订单信息表
user = pd.read_excel('../users.xlsx')len(user)user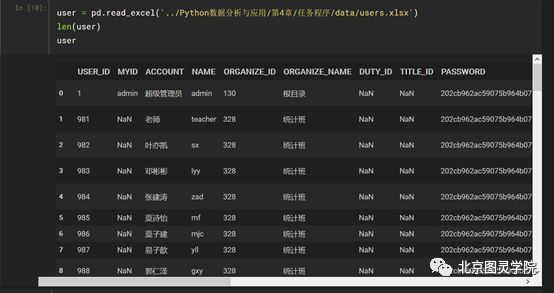
Excel文件存储
将文件存储为Excel文件,可以使用to_excel函数,其语法格式如下:
to_excel(excel_writer, sheet_name='Sheet1', na_rep='',float_format=None, columns=None, header=True, index=True, index_label=None,startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None,inf_rep='inf', verbose=True, freeze_panes=None)使用to_execl函数将数据存储为Excel文件user.to_excel('../tmp/userInfo.xlsx',sheet_name='Sheet3')os.listdir('../tmp')嗯,这就是我们常用到的pandas读取文件的一些操作,貌似没什么难的,孰能生巧就可,下篇文章为大家分享pandas的常用操作,祝大家一臂之力登上数据分析的神坛。
哦,对啦,该篇文章的素材直接来源为网络《python数据分析》