目录
Deeplabv3+网络结构详解与模型的搭建
转载链接
一、Dilated Convolution 膨胀卷积
二、ASPP与Encoder & Decoder
三、深度可分离卷积
3.1 深度可分离卷积原理
3.2 深度可分离卷积减小参数量和计算量
3.3 深度可分离卷积实现细节
四、Xception作为Backbone
DeepLab v3+笔记,记录一些自己认为重要的要点,以免日后遗忘。
论文地址:https://arxiv.org/abs/1802.02611
DeepLab v3+将特征提取阶段最后几个layer的conv(图片中黄色部分)变成了dilated conv,使分辨率不再降低,但增大感受野。也就是说这样在保留位置信息的同时,语义信息保持不变。
DeepLab v3+采用ASPP(Atrous Spatial Pyramid Pooling)空洞空间金字塔池化,用不同的感受野和上采样,实现多尺度提取特征。
DeepLab v3+采用深度可分离卷积,降低参数数列,提高计算效率。
复现DeepLabV3+的代码地址https://github.com/Ascetics/Pytorch-SegToolbox/blob/master/models/deeplabv3p.py
一、Dilated Convolution 膨胀卷积
Dilated Convolution膨胀卷积在语义分割(Deeplab v3+)、目标检测(SSD)、生成算法(pixelcnn)中都有广泛应用。
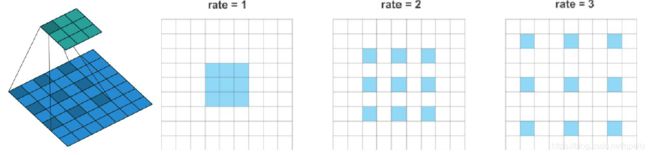 膨胀卷积与膨胀率
膨胀卷积与膨胀率
第一张图描述膨胀卷积过程。膨胀卷积是将卷积核变大,一个3×3的卷积核(深蓝色),膨胀为5×5卷积核,还是9个参数,但他们之间加入了空白(浅蓝色部分)。
第二、三、四图描述膨胀卷积率。当rate=1时,参数距离为1,这就是普通卷积;当rate=2时,参数距离为2,参数之间增加1个空白;当rate=3时,参数距离为3,参数之间增加2个空白……所以这个rate就是参数距离,rate-1就是参数间距。公式描述就是,其中i表示哪个像素的卷积操作,r是参数距离,k是哪个参数。
![]()
膨胀卷积输入输出维度大小公式。
膨胀卷积的same卷积加padding大小。
![]()
膨胀卷积的感受野。在一张图上连续用dilation=1、dilation=2和dilation=4的卷积,感受野的变换对比。
- 如果是dilation=1的3×3卷积,9个参数,也就是普通卷积,其感受野为3×3;
- 如果是dilation=2的3×3卷积,9个参数,在前面dilation=1结果的基础上,其感受野为7×7;
- 如果是dilation=4的3×3卷积,9个参数,在前面dilation=1和dilation=2的基础上,其感受野增大到15×15;
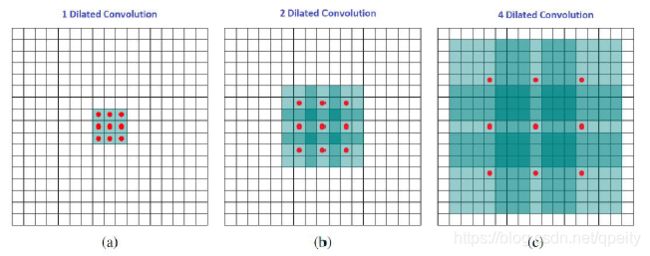 膨胀卷积与感受野
膨胀卷积与感受野
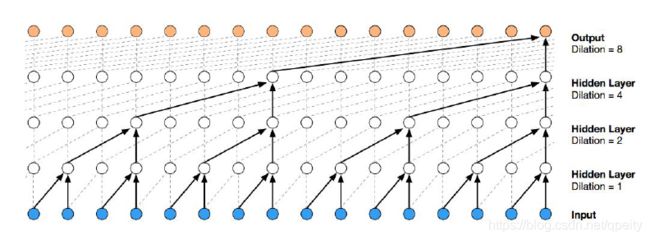
膨胀卷积的计算有2中实现方式。一种是根据上面的描述,在卷积核里面插入空白(也就是插入0)再卷积,这种方式效率低,一般不用。另一种方式是,在输入上等间隔采样(dilation间隔采样)计算,这种效率高。在pytorch中,膨胀卷积的API就是在Conv2d里面加上dilation参数来实现的,dilation就是膨胀率,默认dilation=1就是普通卷积。
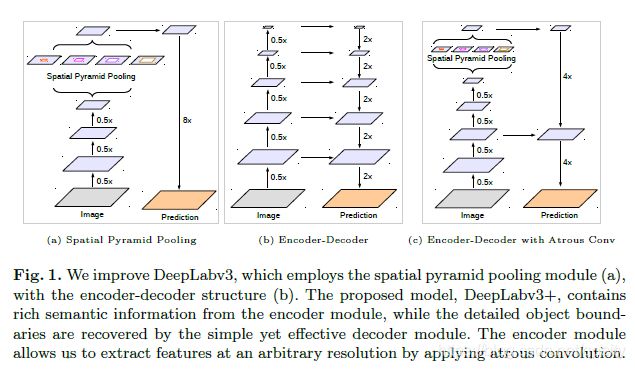
二、ASPP与Encoder & Decoder
论文定义输入图像分辨率与输出图像分辨率比值为output stride,比如一次maxpool k=2就是output stride=2x。
先理解图中(a)说的SPP(Spatial Pyramid Pooling 空间金字塔池化),这里有篇博客把SPP讲的很清楚了https://www.cnblogs.com/marsggbo/p/8572846.html#commentform。
然后理解图中(b)说的Encoder-Decoder,这个办法U-Net里面用过,U-Net是每一次上采样都进行特征融合。
 (空洞)空间金字塔池化 ASPP
(空洞)空间金字塔池化 ASPP
再看图理解ASPP(Atrous Spatial Pyramid Pooling)。 就是图(a)和图(b)相结合得到了(c)这种Encoder-Decoder结构。注意图片里面的细节,ASPP的输出经过两次4倍上采样得到稠密估计,那么在实现的时候,也要考虑,如何从骨干网络里面找到相应的output stride为4x和16x的输出。ASPP有5个尺度。卷积可以局部提取特征,ImagePooling可以全局提取特征,多尺度特征融合。特征融合用concatenate的方法叠加,不是直接相加(FCN以后直接相加的方法很少了)。
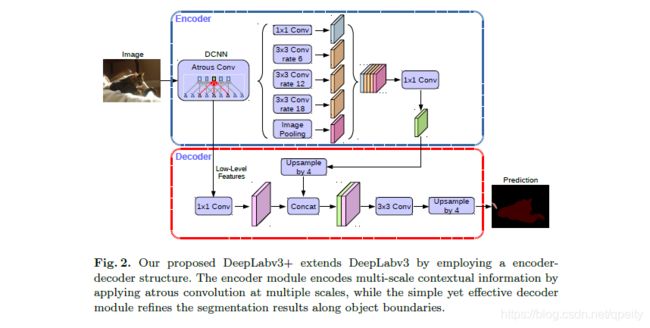 DeepLab v3+
DeepLab v3+
通过论文Fig2,来掌握整个DeepLab v3+的过程。Input经过骨干网络(backbone,也就是图中标注DCNN Atrous Conv的部分)得到两个输出:一个是low-level feature,这是个output=4x的输出;另一个是高级特征,给ASPP的输出,这是个output=16x的输出。
Encoder部分。高级特征经过ASPP的5个不同的操作得到5个输出,其中1个1×1卷积,3个不同rate的dillation conv,1个ImagePooling。这里要注意ImagePooling是全局平均池化之后再上采样到原来大小。这5个输出经过concatenate操作和1×1卷积得到output stride=16x的输出。
Decoder部分。两个输入分别操作:low-level featur经过1x1卷积调整维度(output stride=4x),论文4.1节介绍实验结果表明low-level feature调整到48 channels时效果最好;Encoder输出上采样4倍(output stride从16x变为4x)。将两个4x特征concatenate,后面接一些3×3卷积,再上采样4倍得到Dense Prediction。论文4.1节介绍实验结果表明decoder两个4x输出特征concatenate,后面接2个out_channels=256的3x3卷积,输出效果较好,可采用这种设计。
Decoder里面所有的Upsample都是用双线性差值。
注意backbone的选取,需要自己寻找output stride = 4x和16x的输出。
三、深度可分离卷积
3.1 深度可分离卷积原理
深度可分离卷积将普通卷积分成两步:
- 第一步,每个channel单独做卷积,也就是图中(a)说的depthwise;
- 第二步,将第一步卷积结果用1×1卷积夸channel组合起来,也就是图中(b)说的pointwise。
可以理解成为,第一步在每个通道做卷积,结果是channel数不变。第二步用1×1卷积调整channel数。
DeepLab v3+里面所说Atrous Separable Convolution指的是将深度可分离卷积的第一步改为dilation卷积。用于ASPP和Decoder部分。
 深度可分离卷积、空洞深度可分离卷积
深度可分离卷积、空洞深度可分离卷积
3.2 深度可分离卷积减小参数量和计算量
为什么深度可分离卷积可以减少参数呢?看图,普通卷积、分组卷积(N组) 、深度可分离卷积的示意图。深度可分离卷积把普通卷积变成空间卷积与通道卷积分开计算,解耦操作的相关性,减少了参数量和计算量,参数量公式对比看表格。目前在pytorch上还没有深度可分离卷积的API,但是可以自己实现,当group=in_channels=out_channels就相当于depth-wise conv,后面接一个1×1卷积就相当于point-wise conv。
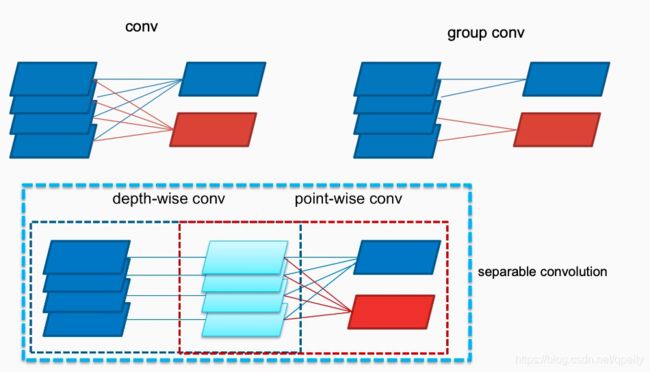 三种卷积示意图
三种卷积示意图
| 参数数量 |
|
|---|---|
| Conv |
|
|
Group Conv in_channels=I,out_channels=O kernel_size=K,groups=N |
|
|
Depth-wise Conv + Point-wise Conv in_channels=I,groups=I out_channels=O,kernel_size=K |
3.3 深度可分离卷积实现细节
在Xception论文里提到了深度可分离卷积的实现细节,通过实验在Depth-wise Conv和 Point-wise Conv之间不加ReLU效果最好,加了ELU或ReLU反而不好。实现的时候应当是BN→ReLU→Depth-wise→Point-wise,Depth-wise Conv和 Point-wise Conv之间不加ReLU和BN。
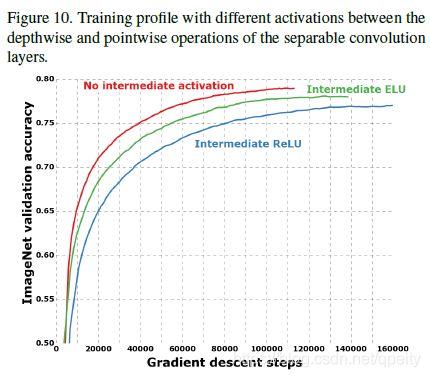
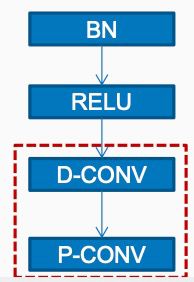
四、Xception作为Backbone
论文第7页提出用改进的AlignedXception作为DeepLabV3+的骨干网络。
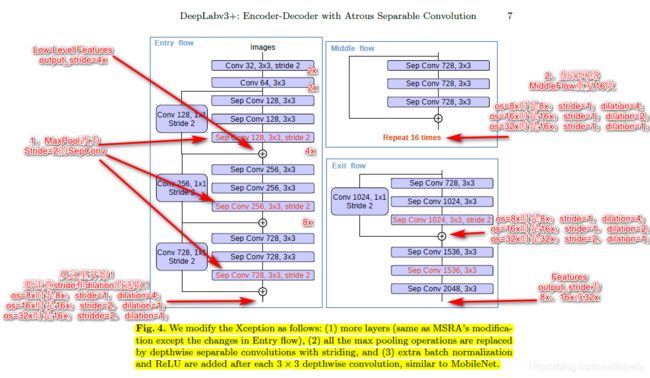
这里我们只记录AlignedXception的实现细节。
- 在Xcepition的Entry Flow中,所有的下采样MaxPool全部改为Stride=2的SeparableConv;
- 网络加深,Middle Flow中,Block由原来的重复8次改为重复16次;
- 最后一次下采样及以后的网络,要注意stride和dilation的选取。
为了实现代码复用,可以根据output_stride=8、16、32设置strides和dilations两个tuple。
- strides[0]和dilations[0] 在Entry Flow的第三个block使用;
- Middle Flow都不进行下采样,stride都等于1,dilation都使用dilations[1];
- strides[1]和dilations[1] 在Exit Flow的block使用。
这里是复现的AlignedXception的代码https://github.com/Ascetics/Pytorch-SegToolbox/blob/master/backbones/aligned_xception.py