C语言杂谈01---如何理解条件编译
架构图

前言
由于地区翻译关係,有些书籍将macro翻译成"巨集",有些翻译成"宏",为了避免混淆(我自己),所以文章内容会以英文名macro来代替中文译名
甚麽是条件编译
条件编译就是根据已经定义的macro进行选择性判断的语句,它会在compiler进行编译前完成,主要由预处理器负责
预处理器会将条件编译指令的结果告诉compiler,让他去编译指定区段的程式码。条件编译指令可能会出现在程式的任何一个位置,端看使用方法,例如下方这个简单的程式范例就含有条件编译:
#include 和一般的条件语句不同的是,条件编译在compile之前就已经决定,相反的,正常的条件语句(if, else if, else…)需要我们在执行时(run time)才能进行判断
也就是说条件编译语句可以让compiler知道那些程式码区段需要编译,那些可以直接捨去;而正常的条件语句因为需要在执行时依照变数值去判断执行区块,所以无论如何整个逻辑区块都会被全部编译
下图我们看到一个.c档被编译成可执行档的过程,绿色区块就是条件编译主要涉及部分。条件编译有点超前部署的味道,它会决定谁会被包含、编译、忽略,它不被编译器编译,想当然也不属于C/C++范畴
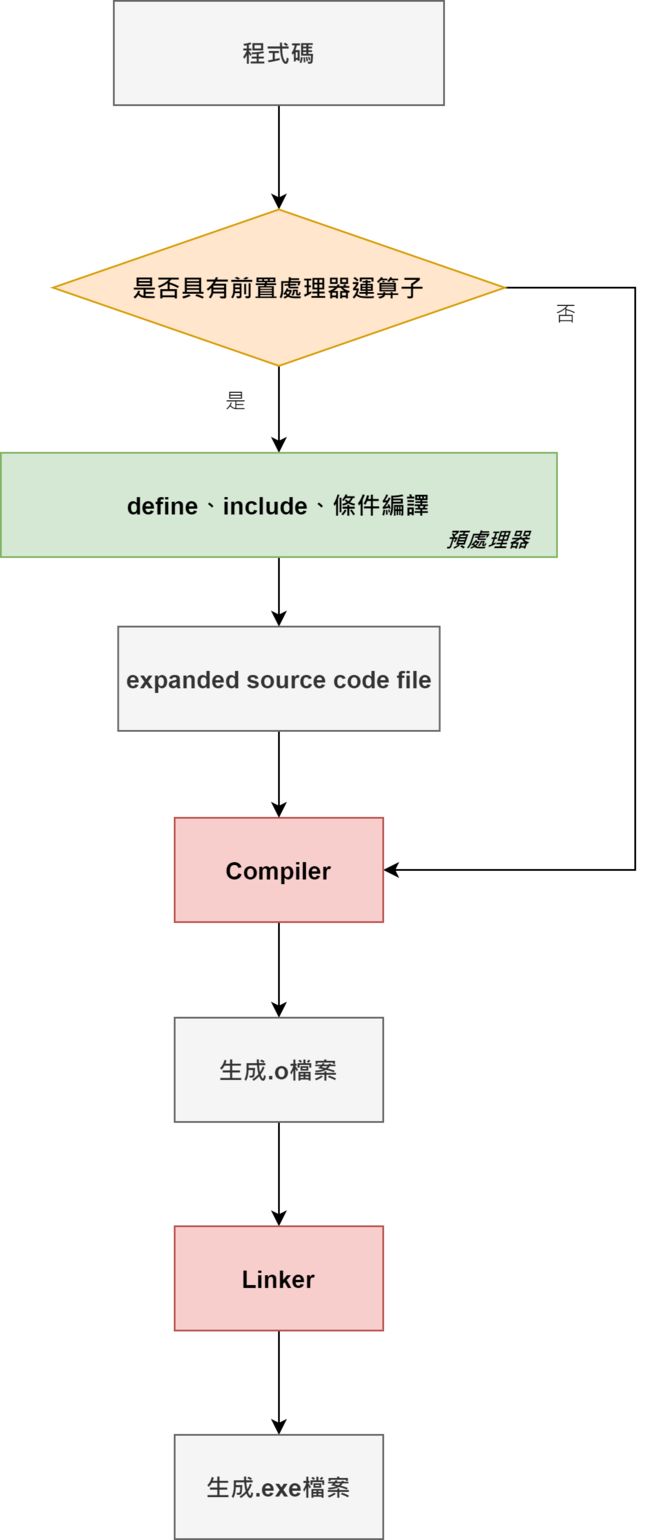
条件编译种类
#if, #elif, #defined
#if, #elif利用后方的常数表达式(constant-expression)来判断程式码区段是否需要被包含
例如下面简单的程式码片段,因为test被定义成1,这个条件恰好吻合第一个区段,所以会编译并执行#if到#else之间区段
#include 输出结果:
Macro test exist...
#if后的常数表达式可以使用一元运算子进行判断,也可以使用逻辑运算子结合多个判断式。当判断条件超过两组时可以使用#elif, #else,和一般的if-else if-else语句没什麽分别
#include 输出结果:
Macro test meet the requirement
切记
#if后方的判断式要加上小括号()
#if还可以加上条件编译语句defined(),它用来判断一个macro是否被定义。例如我们把上面的程式码稍微改写一下:
#include 输出结果:
Macro test doesn't meet the requirement
由于test2被我们註解掉,所以实际上它没有被定义,所以最后输出结果没能满足#if与#elif条件
一些常见问题
使用#if与 #defined的时机其实有点不同,前者单独使用必须搭配表达式,对macro的值进行判断;后者仅用来判断macro是否被定义
假设我们想用#if来代替#defined判断一个test2是否被定义:
#include 输出结果为:
success
test1, test2均判断成功。但我们修改一下test2的定义值,结果会大为不同:
#include 这时的输出结果变成:
fail
与我们期望的判断功能大相迳庭,但至少还能打印输出。再次对test2的定义值进行修改:
#include 执行时得到compiler的报错missing expression between '(' and ')',因为test2若没有填入参数,会被解读为空字串,这个空字串不能用表达式进行判断,所以尽管为上述程式码加上判断(test2 > 10)也是会发生错误error: operator '>' has no left operand
如果单纯没有定义macro,在#if判断式中会传入0,这点有点不同
#include 输出结果:
test equal to 0...
我们明明没有定义test,输出结果确判断它等于0,这是因为预处理器将未定义macro替换成0的关係
从上面一连串的案例可以发现,若是要判断一个macro是否被定义,一定要在#if后面加上#defined()指令。另外使用表达式判断前应先判断macro是否存在
用来条件编译的macro避免定义成小数点
#ifdef, #ifndef
其实#ifdef就是#if defined();#ifndef就是#if !defined(),使用目的当然也是用来判断macro是否被定义,它的使用逻辑如下:
- 若macro有定义:
#ifdef()会判断为true#ifdef()会判断为false
- 若macro没有定义
#ifdef()会判断为false#ifndef()会判断为true
举例来说:
#include 输出结果:
test1 is defined...
test2 is defined...
#else
#else语句是条件编译判断的扩充。当#if, #elif的判断均为否,则会执行#else与#endif之间的程式码区段:
#include 使用在#ifndef, #ifdef则相对简单,因为它们只有存在与不存在两个状态:
#include #endif
#endif用来结束条件编译区段,每完成一个条件判断结构就需要使用一个#endif语句,以下为伪代码范例,每一个完整的条件编译语句都需要#endif来收尾:
/*条件编译*/
#if (...)
#if (...)
// do-something
#else
// do-something
#endif
#endif
巢状结构
条件编译和一般的条件语句一样可以巢状嵌套。
我们假定该程式码会依照定义来决定该执行哪种作业系统平台的执行绪初始化。使用巢状结构有助于我们细分目标,你可以看看它的结构,其实跟普通的条件语句根本是同一个妈生的:
#if defined(Linux)
#ifdef ubuntu
ubuntu_thread_init();
#endif /*ubuntu*/
#ifdef centos
centos_thread_init();
#endif /*centos*/
#elif defined(MS)
#ifdef WIN10
windows_10_thread_init();
#endif /*WIN10*/
#ifdef WIN7
windows_7_thread_init();
#endif /*WIN7*/
#endif
空定义
空定义顾名思义就是没有为macro定义任何数值:
#define test
空定义是一个甚麽都没有的macro,预处理器不会将任何参数替换给使用它的程式码,它代表一个空字串:
#include 输出结果
empty macro!
但你以为它没甚麽用处吗?空定义虽然不代表任何值,但它可以被#if defined(),#ifdef等条件编译捕捉
换句话说有一些根本不需要替换定义值的场景,使用空定义还是非常有用的,例如接下来将要介绍的标头守卫功能
标头守卫
首先科普一下#include这条语句的功能,预处理器会将包含的标头档内容全部複製过来,然后把#include这条语句删除
不过这中间产生了一个问题,若是主程式重複#include同一个标头档会发生甚麽事?,例如下面这个程式:
/*test1.h*/
#define SerialName "my_test_0001\n"
#define SW_version "V.1.3.0\n"
#define FW_version "V.1.3.0\n"
typedef enum
{
socket_init = 0,
socket_connecting,
socket_connected,
socket_close
}socket_process;
// ...
/*test2.h*/
#include "test1.h"
#include
#define MAX_SOCKET_NUMBER 4
typedef struct{
uint8_t family;
uint8_t port;
uint8_t* addr;
socket_process socket_information;
}socket_info[MAX_SOCKET_NUMBER];
// ...
/**
* main.c
*/
#include "test1.h"
#include "test2.h"
int main(){
// do-something
return 0;
}
上述这个程式的问题在于,test1.h在main.c中被包含,同时在包含test2.h的时候又被嵌套包含,相同标头档如果被重複包含2次,实际上它的内容会被编译2次,不仅浪费资源,又可能会发生错误
例如编译器会提醒你"xxx" has already been declared in the xxx file或类似的讯息,就是发生重複编译
这就是标头守卫(header guards)该挺身而出的时候,它的目的就是防止标头档内容被重複编译,例如各种类型的数据、结构体数据、静态变数等等
回到原先的程式范例,我们来改写它:
/*test1.h*/
#ifndef __TEST1_H
#define __TEST1_H
#define SerialName "my_test_0001\n"
#define SW_version "V.1.3.0\n"
#define FW_version "V.1.3.0\n"
typedef enum
{
socket_init = 0,
socket_connecting,
socket_connected,
socket_close
}socket_process;
// ...
#endif /*__TEST1_H*/
/*test2.h*/
#ifndef __TEST2_H
#define __TEST2_H
#include "test1.h"
#include
#define MAX_SOCKET_NUMBER 4
typedef struct{
uint8_t family;
uint8_t port;
uint8_t* addr;
socket_process socket_information;
}socket_info[MAX_SOCKET_NUMBER];
// ...
#endif /*__TEST2_H*/
/**
* main.c
*/
#include "test1.h"
#include "test2.h"
int main(){
// do-something
return 0;
}
__TEST1_H称为前置处理变数,通常以__作为开头,英文字母均以大写表示,这种特殊写法目的是避免使用者
也定义了相同名称的macro因而造成错误
整个流程如下图所示,第一次包含test1.h时由于没有定义过__TEST1_H,会成功进入ifndef条件编译区段,并複製内容
第二次重複包含test1.h发生在包含test2.h的时候,由于test1.h中__TEST1_H已经在上一次定义过了,因此ifndef条件编译区块会被忽略,成功防止重複包含
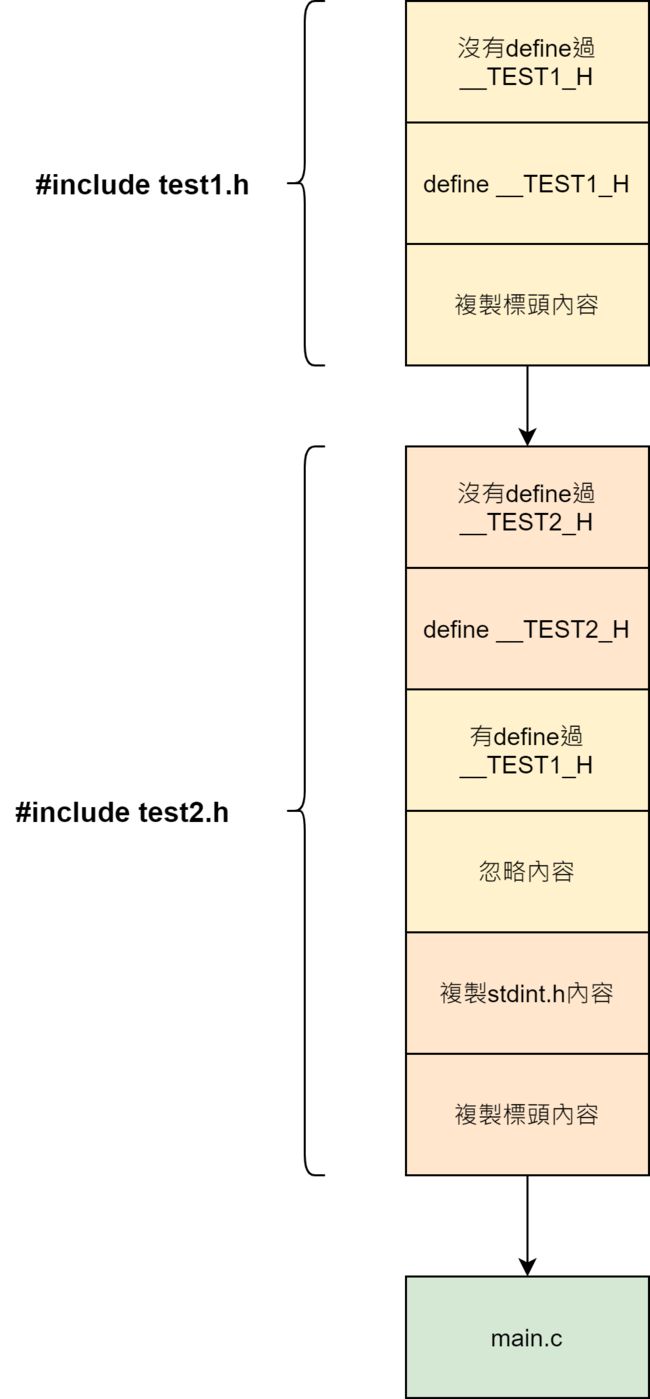
因为标头首位中间撰写的程式码有可能会很长,其中也不乏会出现其他条件编译程式码,因此最好在
#endif后方加上註解__TEST1_H来体醒开发者这个#endif属于标头守卫区段
切割特性
切割特性简单来说就是只执行某个特定程式码区段,但又不想直接删除程式码。通常条件编译的切割特性用于debug测试,或是执行指定版本程式码。例如下方伪代码就是一个例子:
debug测试
#include 当我们需要测试thread1功能时,就定义THREAD1_TEST_MODE,如此一来thread2程式码就自动被忽略了,因为thread2部分不会被编译器编译,所以就某种程度上来说,切割特性可以节省code size,这个特性在下一个案例上更加明显
指定版本程式码
例如有一个软体拥有四种不同的方案,我们只需要依照条件编译的需求,将SOFTWARE_VERSION定义成指定参数值就可以明确编译并执行指定版本的程式码:
#include 移植性问题
使用macro选择预处理区段
使用条件编译还有利于程式的移植性,我自己习惯创建一个负责设定参数的标头档,还有多个根据参数定义来切割的功能性标头档
举以下简单程式案来说,我透过在header1.h定义程式需要用到的macro,以及用来选择功能区段的条件macro
也就是说我可以透过SPECIALTY来选择预处理的区段(见header2.h),由于macro的定义名均相同,所以从程式逻辑来看,每次移植程式我只需要更改header1.h的定义值,就可以相容code base相同的程式
当然啦这个程式没有任何逻辑可言,仅仅是做为一个范例,但是核心概念不便,依然是利用条件编译提升移植性
/*header1.h*/
#ifndef __HEADER1_H
#define __HEADER1_H
#define NAME "HAU-WEI"
#define GENDER "male"
#define AGE 25
#define PROGRAMMER 0
#define MANAGER 1
#define ATHLETE 2
#define SPECIALTY PROGRAMMER
#include "header2.h"
#endif /*__HEADER1_H*/
/*header2.h*/
#ifndef __HEADER2_H
#define __HEADER2_H
#if (SPECIALTY == PROGRAMMER)
#define Intro(x) printf("Hi, my name is %s, I'm a programmer\n[Gender][%s]\n[Age][%d]\n", NAME, GENDER, AGE)
#define SKILL1 "JAVA"
#define SKILL2 "C++"
#define SKILL3 "SQL"
#define SKILL4 "linux"
#elif (SPECIALTY == MANAGER)
#define Intro(x) printf("Hi, my name is %s, I'm a manager\n[Gender][%s]\n[Age][%d]\n", NAME, GENDER, AGE)
#define SKILL1 "Communication"
#define SKILL2 "Management"
#define SKILL3 "Negotiation"
#define SKILL4 "English"
#elif (SPECIALTY == ATHLETE)
#define Intro(x) printf("Hi, my name is %s, I'm a athlete\n[Gender][%s]\n[Age][%d]\n", NAME, GENDER, AGE)
#define SKILL1 "Basketball"
#define SKILL2 "Soccer"
#define SKILL3 "Swimming"
#define SKILL4 "Tenis"
#endif /*SPECIALTY*/
#endif /*__HEADER2_H*/
#include 输出结果:
Hi, my name is HAU CHEN, I'm a programmer
[Gender][male]
[Age][25]
I'm capable for JAVA!
我们试着将header1.h中的SPECIALTY改为MANAGER看看输出会发生什麽变化:
Hi, my name is HAU-WEI, I'm a manager
[Gender][male]
[Age][25]
I'm not capable for JAVA!
输出结果确实根据定义参数类型而改变!
使用不同标头档
如果想在大型程式上使用移植特性进行开发,可以利用条件编译来决定#include哪一个标头档,这些标头档所包含的函式、macro等名称均相同
我们只需要改变macro定义的值就可以依照需求切换功能,这种方式适用于主程式架构逻辑不变,想额外改写一些特殊功能时使用,通常都是类似但有一些小差异产品
举例来说,下面这个程式范例会依照FUNC的定义值#include不同的标头档。且由于每个标头档中都有一个名为print_result的函式,所以若以后想要移植档案,只要将含有print_result函式的档案移植即可
通常会移植成对的source与header files,范例为了方便起见把程式码都伈在写在header中,不过逻辑不变
/*header1*/
#ifndef __HEADER1_H
#define __HEADER1_H
int operation(int a, int b){
return a + b;
}
int print_result(int a, int b){
printf("%d + %d = %d\n", a, b, operation(a, b));
}
#endif /*__HEADER1_H*/
/*header2*/
#ifndef __HEADER2_H
#define __HEADER2_H
int operation(int a, int b){
return a - b;
}
int print_result(int a, int b){
printf("%d - %d = %d\n", a, b, operation(a, b));
}
#endif /*__HEADER2_H*/
/*header3*/
#ifndef __HEADER3_H
#define __HEADER3_H
int operation(int a, int b){
return a * b;
}
int print_result(int a, int b){
printf("%d * %d = %d\n", a, b, operation(a, b));
}
#endif /*__HEADER3_H*/
/**
* main.c
*/
#include 输出结果:
4 * 3 = 12
试着把FUNC改成2,查看输出结果:
4 - 3 = 1
好了条件编译的介绍大致就到这裡,希望对未来进行大型程式开发的各位有帮助