opencv3/C++ 级联分类器训练样本数据
利用opencv_traincascaded训练样本数据。
需要准备的数据
具体的创建过程及程序见:
① opencv3/C++ 从视频中获取人脸数据
② C++ 遍历文件夹中的图片
③ C++读写txt与dat文件
以下是准备好的样本数据。
1、训练数据:
训练数据包含两部分:包含人脸图片的样本数据和背景图片数据,如图所示;
其中,negitive文件夹下存放的是背景图片数据img和文件bg.txt:
如图,文件夹img下存放的即背景图片数据(此处共232个,大小不一,且背景图片中不含有人脸):

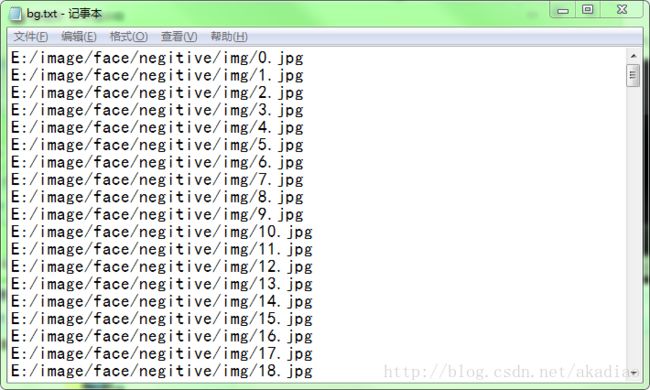
如图,bg.txt文件下的内容为图片的路径列表:
其中,negitive文件夹下存放的是样本数据img和文件info.dat:
如图,文件夹img下为含有人脸的样本数据(此处共760个):
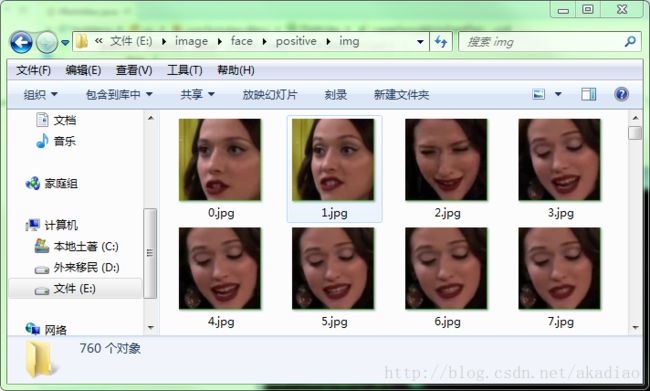
如图,info.dat文件下的内容依次为【图片相对路径 包含人脸个数 人脸所在区域的左上角坐标 人脸所在区域的右下角坐标】(此处采集的图片每张上只有一个人脸,且图像大小均为150,故info.dat内容为如图格式):
2、使用的OpenCV文件:
OpenCV编译后在OpenCV“…\x64\vc11\bin”目录下:
可以看到有opencv_createsamplesd.exe、opencv_traincascaded.exe等文件:
一、创建正样本VEC文件
使用文件:opencv_createsamplesd.exe
1、进入文件所在目录
打开命令提示符:
进入文件opencv_createsamplesd.exe所在的目录下:
cd /d D:\opencv3.1.0\opencv\tools\opencv_contrib\install\x64\vc11\bin
回车后再输入:
opencv_createsamplesd.exe可以看到文件opencv_createsamplesd.exe的用法说明:
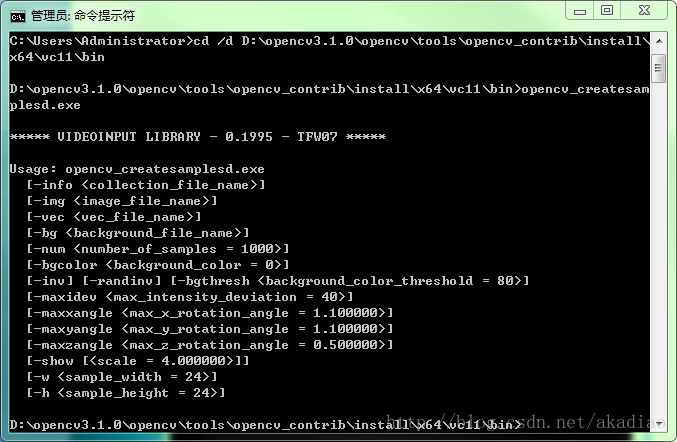
***** VIDEOINPUT LIBRARY - 0.1995 - TFW07 *****
Usage: opencv_createsamplesd.exe
[-info <collection_file_name>]//待训练的样本文件
[-img <image_file_name>]//单个样本时用(多个样本时不用)
[-vec <vec_file_name>]//生成的vec文件的名字
[-bg <background_file_name>]//背景文件名称,也可以通过bgcolor指定
[-num <number_of_samples = 1000>]//样本数量(默认为1000)
[-bgcolor <background_color = 0>]//指定背景颜色
[-inv] [-randinv] [-bgthresh <background_color_threshold = 80>]//是否用反相
[-maxidev <max_intensity_deviation = 40>]//最大灰度方差(一般用默认值)
[-maxxangle <max_x_rotation_angle = 1.100000>]//当使用-img时,使用max_x、y、z_rotation_angle三个量时,可以将输入的图像进行旋转,产生多个样本
[-maxyangle <max_y_rotation_angle = 1.100000>]
[-maxzangle <max_z_rotation_angle = 0.500000>]
[-show [<scale = 4.000000>]]//显示处理时的图片
[-w <sample_width = 24>]//通过opencv_createsamplesd处理产生的vec文件的样本的宽
[-h <sample_height = 24>]//通过opencv_createsamplesd处理产生的vec文件的样本的高
2、生成vec文件:
进入opencv_createsam.exe文件所在目录后继续输入:
opencv_createsam
plesd.exe -info E:\image\face\positive\info.dat -vec E:\image\face\sample_310.ve
c -num 760 -bgcolor 0 -bgthresh 0 -w 24 -h 24回车后得到:
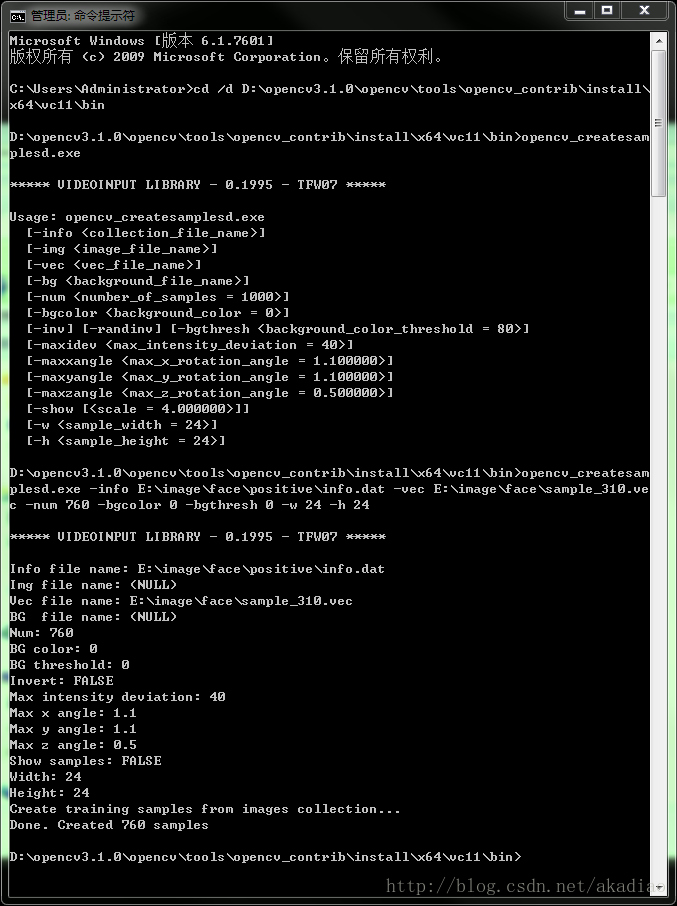
可以看到对应目录下一句生成了vec文件:

二、训练样本数据
使用文件:opencv_traincascaded.exe
1、进入文件所在目录
打开命令提示符:
进入文件opencv_traincascaded.exe所在的目录下:
cd /d D:\opencv3.1.0\opencv\tools\opencv_contrib\install\x64\vc11\bin回车后再输入:
opencv_traincascaded.exe如图:
回车后可以看到文件opencv_traincascaded.exe的用法说明:
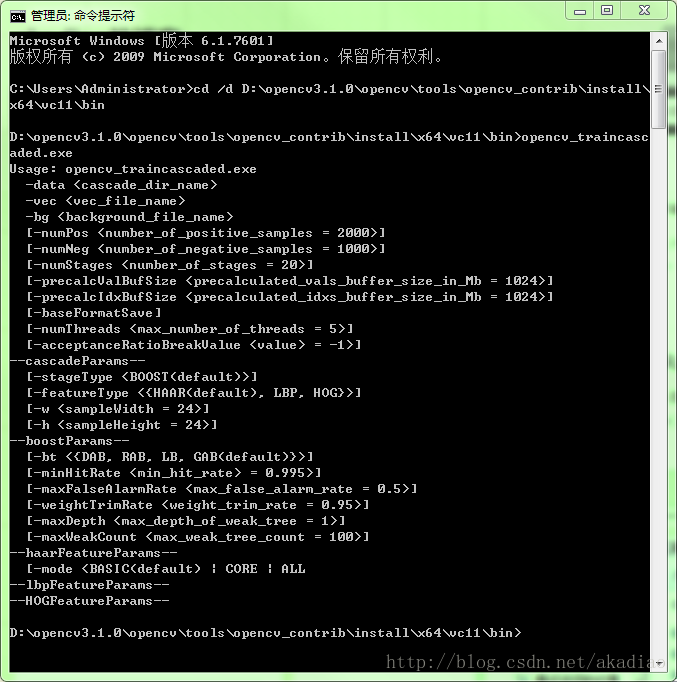
即:
Usage: opencv_traincascaded.exe
-data <cascade_dir_name>//指定生成的xml文件的目录
-vec <vec_file_name>//vec文件名
-bg <background_file_name>//负样本描述文件名称(.dat)
[-numPos <number_of_positive_samples = 2000>]//每个阶段用来训练的正样本个数
[-numNeg <number_of_negative_samples = 1000>]//每个阶段用来训练的负样本个数
[-numStages <number_of_stages = 20>]//指定训练层数,推荐15~20,层数越高,耗时越长
[-precalcValBufSize <precalculated_vals_buffer_size_in_Mb = 1024>]
[-precalcIdxBufSize <precalculated_idxs_buffer_size_in_Mb = 1024>]
[-baseFormatSave]
[-numThreads <max_number_of_threads = 5>]
[-acceptanceRatioBreakValue <value> = -1>]
--cascadeParams--
[-stageType <BOOST(default)>]
[-featureType <{HAAR(default), LBP, HOG}>]//特征类型,一般HAAR特征训练比较耗时,LBP速度较快但效果逊于HAAR
[-w <sampleWidth = 24>]//表示样本的宽,必须跟vec中声明保持一致
[-h <sampleHeight = 24>]//表示样本的高,必须跟vec中声明保持一致
--boostParams--
[-bt <{DAB, RAB, LB, GAB(default)}>]
[-minHitRate <min_hit_rate> = 0.995>]//最小命中率,即训练目标准确度
[-maxFalseAlarmRate <max_false_alarm_rate = 0.5>]//最大虚警(误检率),每一层训练到这个值小于0.5时训练结束,进入下一层训练
[-weightTrimRate <weight_trim_rate = 0.95>]
[-maxDepth <max_depth_of_weak_tree = 1>]
[-maxWeakCount <max_weak_tree_count = 100>]
--haarFeatureParams--
[-mode <BASIC(default) | CORE | ALL//ALL指定haar特征的种类,BASIC仅仅使用垂直特征,ALL表示使用垂直以及45度旋转特征
--lbpFeatureParams--
--HOGFeatureParams--本次训练选择LBP特征(若使用HAAR特征,只需将LBP改为HAAR,可以发现训练速度明显变慢),使用的正样本个数为700,负样本个数为500,图像大小与之前生成vec文件的样本大小保持一致(24×24)。
输入以下命令行并回车,开始训练:
opencv_traincascaded.exe -data E:\image\face -vec E:\image\face\sample_310.vec -bg bg.txt -numPos 700 -numNeg 500 -numStages 12 -featureType LBP -w 24 -h 24 -minHitRate 0.995 -maxFalseAlarmRate 0.5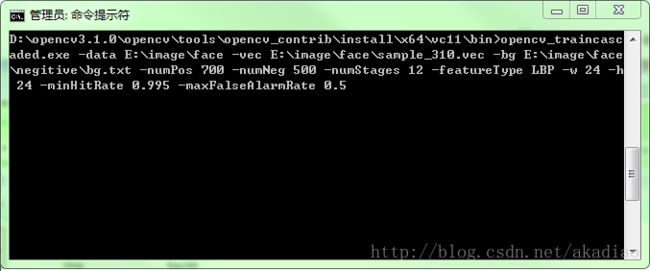
注:positive文件夹下的正样本个数为760,此处使用的正样本个数为700(即:-numPos 700);这是因为每个阶段训练时有些正样本可能会被识别为负样本,故每个训练阶段后都会消耗一定的正样本。因此,此处使用的正样本数量绝对不能等于或超过positive文件夹下的正样本个数,一般留有一定的余量。而negitive文件夹下的负样本个数为232,此处使用的负样本个数为500(即:-numNeg 500);因为给定的负样本图像大小不一,程序会根据给定的负样本个数对图像自动切割出和正样本大小一致的,一般将该参数设置为正样本数目的1~3倍,数值越大训练的时间越长。
如图,可以看到训练进行到第7个阶段结束:
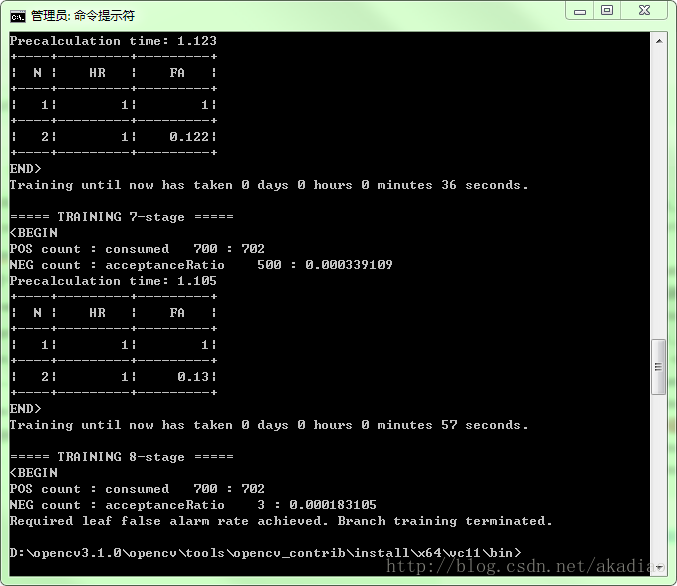
在输出的目录下可以看到训练输出的xml文件,其中cascade.xml为最终结果其他为过程文件:

参考:OpenCV2.3.2 级联分类器训练