Mysql事务隔离机制
SQL隔离机制:
所谓隔离机制,指的是读与写之间的隔离,指的是在多事务并行的时候,A事务的读与B事务的写之间的隔离,也就是说B事务的写对A事务的可见性。
多事务并发运行的时候,同时读写一个数据,可能会出现脏写、脏读、不可重复读、幻读几个问题。
脏写:
两个事务都更新一个数据,结果A事务回滚了,把B事务更新的数据回滚没了。
脏读:
A事务读取到B事务没有提交的但修改了的数据,结果B事务回滚了,A事务下次就读不到了。
不可重复读:
A事务运行期间,B事务修改了一条数据,并且提交了,A事务前后对这条数据读取到的值不一样。
幻读:
A事务进行范围查询,B事务插入了新的几条数据,并且提交了,A事务前后范围查询查到的结果不一样。
针对以上问题,才有了RU、RC、RR和串行化四个隔离级别。
RU:
Read Uncommited,读未提交,就是可以读到其他事务修改了但没有提交的数据。
RC:
Read Commited,读已提交,可以读到其他事务已提交的数据,可以避免脏读、脏写。
RR:
Read Repeated,可重复读,不会读到别的已经提交事务修改的数据,可以避免脏读、脏写、不可重复读。
串行化:
让所有事务都串行执行,可以避免所有问题,但是效率很低,会大大降低并发。
MYSQL隔离机制:
设置隔离级别:SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL level
level值可以是:REPEATABLE READ, READ COMMITED, READ UNCOMMITTED, SERIALIZABLE
Mysql默认的RR隔离级别,使用MVCC机制,避免了脏写、脏读、不可重复读、幻读的问题的。
所谓MVCC机制,是基于undo log多版本链条 + ReadView机制来实现的。
MVCC机制:
所谓MVCC机制,就是多版本并发控制机制,只要是多线程访问同一份数据,都可以使用这种多版本并发控制机制。基于undo版本链 + ReadView机制 来实现的
Undo log版本链:
其实我们每条数据都有两个隐藏字段,一个是trx_id,一个是roll_pointer,这个trx_id就是最近一次更新这条数据的事务id,roll_pointer就是指向更新这个事务之前生成的undo log。
举个例子:
假设有一个事务A(id=50),插入了一条数据,此时这条数据的值以及隐藏字段的值如下图所示,插入的值为值A,因为事务的id是50,所以trx_id等于50,roll_pointer指向一个空的undo log,因为之前这条数据是没有的。
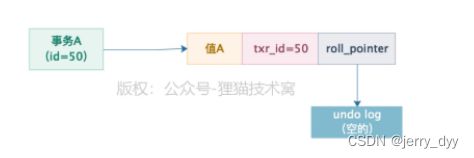
接着假设事务B跑过来修改了一下这条数据的值,把值改成了值B,事务的id是58,那么此时更新之前会生成一个undo log记录之前的值,然后会让roll_pointer指向这个实际的undo log回滚日志。

接着假设事务C又来修改了一下这个值为值C,它的事务id时69,此时会把数据行里的trx_id改为69,然后生成一条undo log,记录及之前事务B修改的那个值,然后roll_pointer指向了本次修改之前生成的undo log,也就是记录了事务B修改的那个undo log。
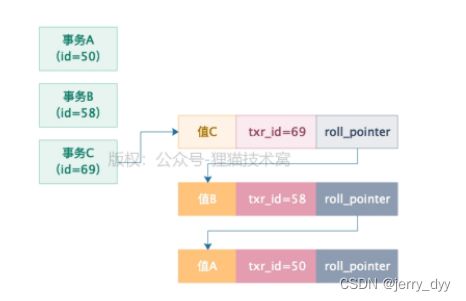
总结:
每个事务修改一行数据的值,都会更新隐藏字段trx_id和roll_pointer,同时之前多个快照对应的undo log会通过roll_pointer指针串联起来,形成一个版本链,也就是undo log版本链。
ReadView机制:
执行一个事务的时候,就会生成一个ReadView,里面有四个比较关键的东西:
一个是m_ids,这个就是说事务开启那一刻有哪些事务在Mysql里面执行还没有提交的;
一个是min_trx_id,就是m_ids里最小的事务id的值;
一个是max_trx_id,就是此刻mysql下一个要生成的事务id,就是最大事务id;
一个是creator_trx_id,就是你这个事务的id。
举了例子:
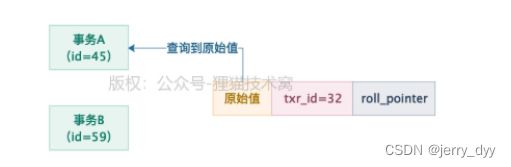
假设原来数据库里就有一行数据,事务id是32,如下图所示:

接着呢,此时两个事务并发过来执行了,一个是事务A(id=45),一个是事务B(id=59),事务B是要去更新这条数据的,事务A是要去读取这条数据的,此时两个事务如下图所示:

现在事务A直接开启一个ReadView,这个ReadView里的m_ids就包含了事务A和事务B的两个id,45和59,然后min_trx_id就是45,max_trx_id就是60,creator_trx_id就是45,就是事务A自己。
这个时候事务A第一次查询这行数据,会走一个判断,就是判断当前这行数据的trx_id是否小于ReadView的min_trx_id,此时发现trx_id=32,小于ReadView里的min_trx_id就是45的,说明事务开启前这行数据早就提交了,所以此时可以查看到这行数据,如下图所示:
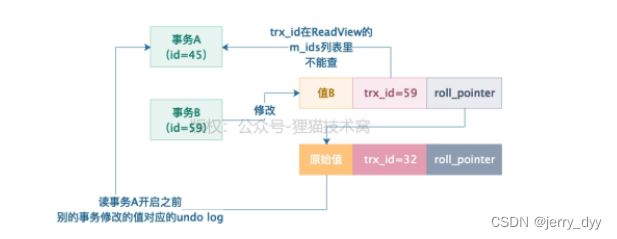
接着事务B开始动手了,它把这行数据的值修改为了值B,然后这行数据的trx_id设置为了自己的id,也就是59,同时roll_pointer指向了修改之前生成的一个undo log,接着这个事务B就提交了,如下图所示:
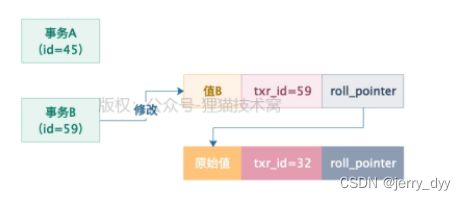
这个时候,事务A再次查询,此时查询的时候,发现此时数据行里的trx_id=59,大于它的ReadView里的min_trx_id(45),同时小于ReadView里的max_trx_id(60)的,说明这条数据的事务,很可能就跟自己差不多同时开启的,于是会看一下这个trx_id=59是否在ReadView的m_ids列表(包含45,59)里,发现在列表里,这个修改数据的事务是跟自己同一时段并发执行然后提交的,所以这行数据是不能查询的。

然后顺着这条数据的roll_pointer顺着undo log链往下找,找到最近的一条undo log,trx_id=32,此时发现trx_id=32小于ReadView里的min_trx_id(45),说明这个undo log版本必然是在事务A开启之前就执行并提交了的,然后读取该undo log里快照值。
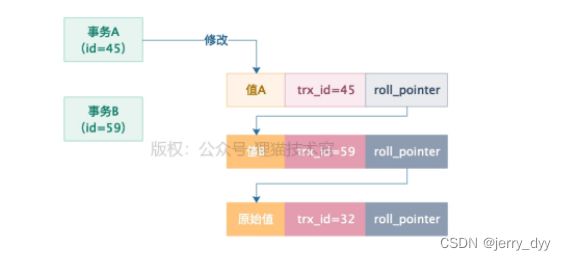
接着假设事务A自己更新了这条数据的值,改成值A,trx_id修改为45,同时保存之前事务B修改的值的快照,如下图所示:
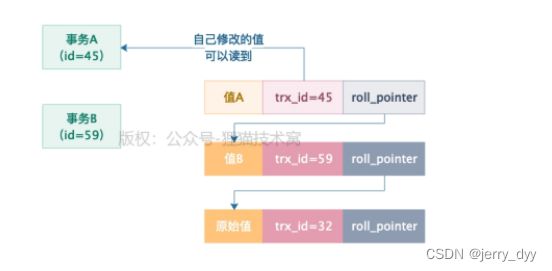
此时事务A来查看这条数据,发现trx_id=45,等于自己ReadView里的creator_trx_id(45),说明这行数据是自己修改的,可以查看。如下图:
接着在事务A执行的过程中,突然开启了一个事务C,这个事务C的id是78,然后它更新了那行数据的值为值C,还提交了,如下图所示:
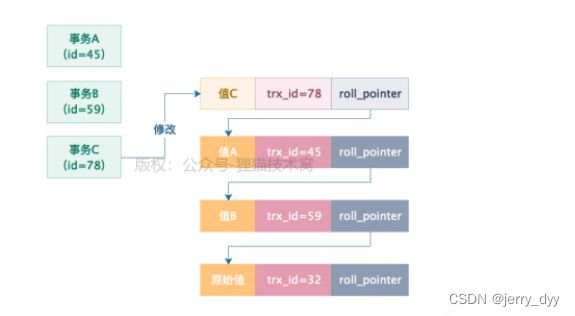
这个时候,事务A再去查询,发现当前数据的trx_id=78,大于自己的ReadView中的max_trx_id(60),说明了有个事务在事务A开启之后,更新了数据并提交了。
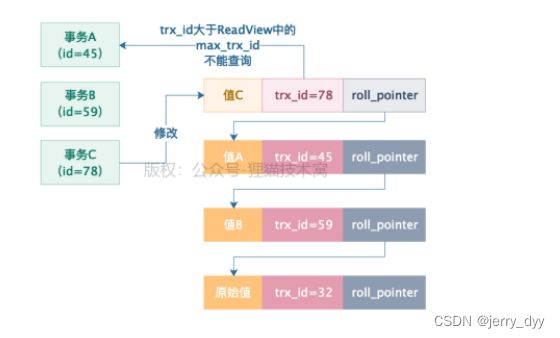
此时事务A就会顺着undo log版本链往下找,找到自己修改的那个版本,然后读出来,如下图:

总结:
通过undo log多版本链条,加上你开启事务时候生成的ReadView,然后查询的时候,根据ReadView的判断机制,你就知道应该读取那个版本的数据。
实现机制:
1、Undo log 多版本链条:
根据undo log 多版本链条进行查找,找到符合条件的版本数据;
2、ReadView:
如果trx_id < min_trx_id:在你事务开启那一刻之前就已提交的事务更新的版本
如果trx_id > max_trx_id:在你事务开启那一刻之后开启的事务更新的版本
如果trx_id = creator_trx_id:是你所在的事务更新的版本
如果trx_id 在m_ids列表中:是你事务开启那一刻已开启但未提交的事务更新的版本
实现效果:
- 可以保证你只能读到你事务开启之前已提交更新的值,还有就是自己事务更新的值;
- 在你事务开启之前,就有别的事务正在运行,然后你事务开启之后,别的事务更新提交了的值,你是读不到的;
- 你事务开启之后,比你晚开启的事务更新提交了的值,你也是读不到的。
RC隔离级别下的MVCC:
同一个事务中的每次查询都会新生成一个ReadView。
那么如果在你这次查询之前,有事务修改了数据还提交了,你这次查询生成的ReadView里,那个m_ids列表当然不包括这个已经提交的事务了,既然m_ids列表不包含已经提交的事务了,就可以读取到人家修改的值了。
RR隔离级别下的MVCC:
同一个事务中的每次查询都使用同一个ReadView,就是事务开启那个时刻的ReadView。