Linux——MySQL高级(day19)
目录
一、用户与权限管理
1.1 创建与赋予权限
1.2 查看和回收权限
1.3 修改密码
1.4 删除用户
1.5 查看当前登录
二、事务
2.1 概述
2.2 手动提交
2.3 自动提交
2.4 隐式处理
三、视图和索引
3.1 视图
3.2 索引
四、存储过程
4.1 创建、调用和删除存储过程
4.2 存储过程的变量
4.3 条件语句
4.4 while循环语句
五、函数
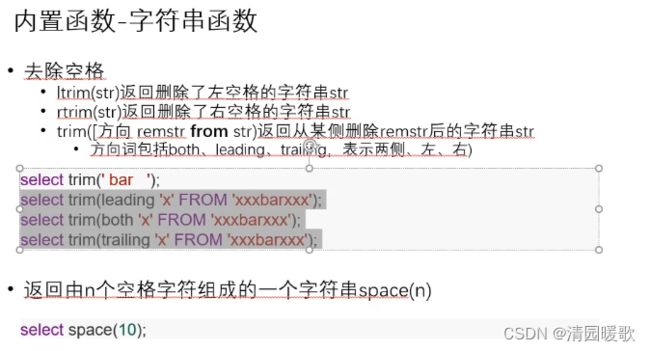
5.1 内置函数-字符串函数
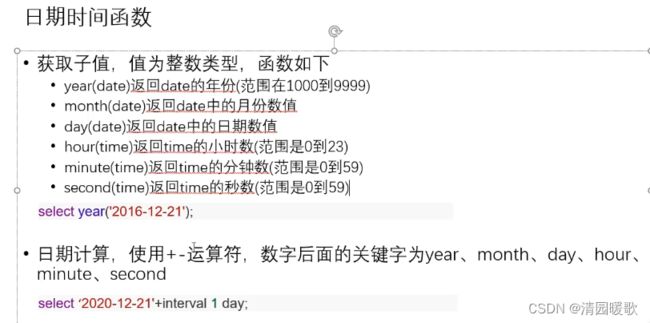
5.2 日期时间函数
5.3 自定义函数
5.4 查询变量
六、Python DB-API
七、查询实战
八、小结
8.1 知识总结
8.2 mysql索引区别
8.3 mysql存错过程
8.4 mysql函数
8.5 存储过程和函数区别
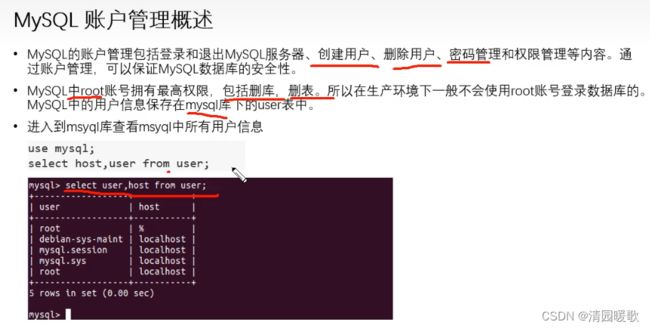
一、用户与权限管理
1.1 创建与赋予权限

create user 'peter'@'%' identified by '123465' # 创建用户 peter,
# %:允许所有用户登录这个用户访问数据库刚创建的新用户是什么权限都没有,需要赋予权限
grant select on mysql.* to 'peter'@'%';
# 赋予select查看权限; .*表示可查看mysql下的所有表,也可以选择性允许查看表
flush privileges; # 记得刷新一下,让修改立即生效(1)本地赋予创建用户并赋予权限
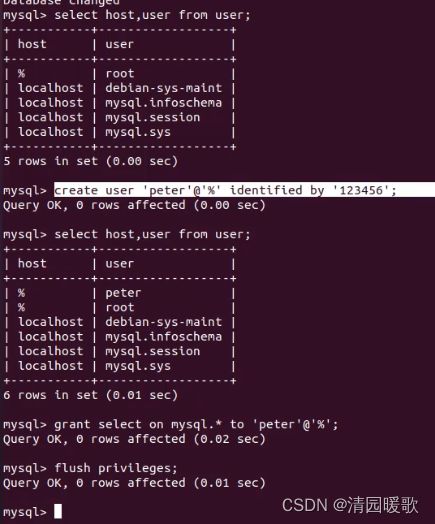
(2)在外部访问数据库,没给权限时,访问失败,如第一行命令,给完权限可以访问,并可以select查看
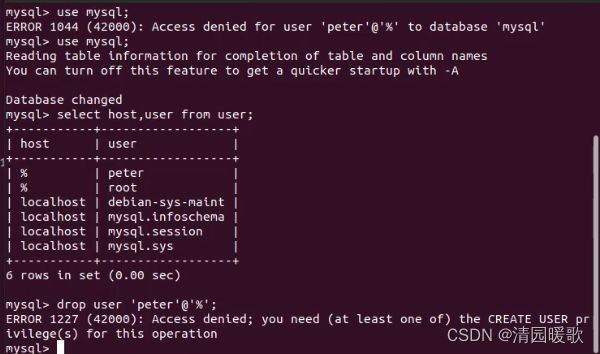
1.2 查看和回收权限

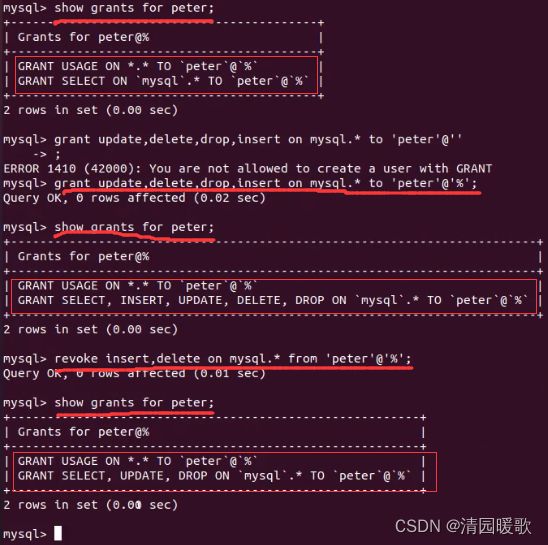
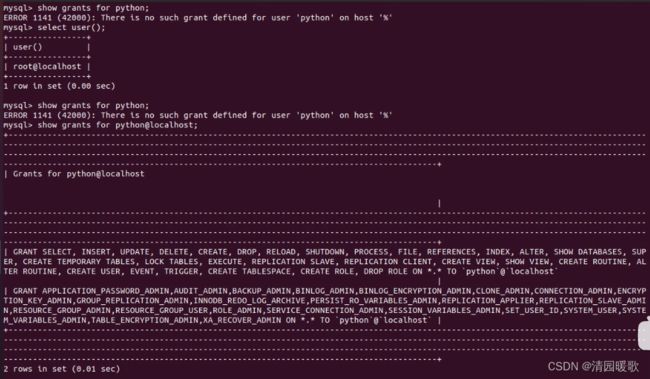
show grants for python;会报错,因为host默认是@%
所以要修改 show grants for python@localhost;
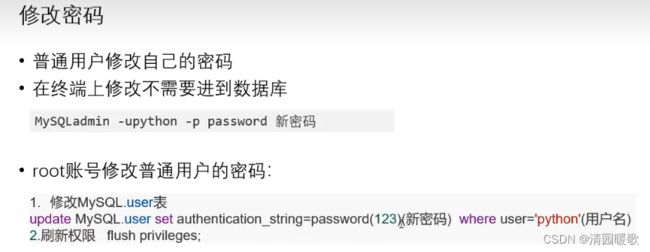
1.3 修改密码
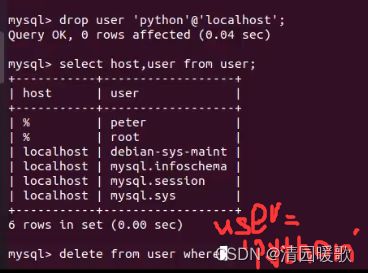
1.4 删除用户

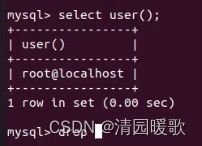
1.5 查看当前登录
查看当前登录的用户:是本机登录的root用户
二、事务
2.1 概述

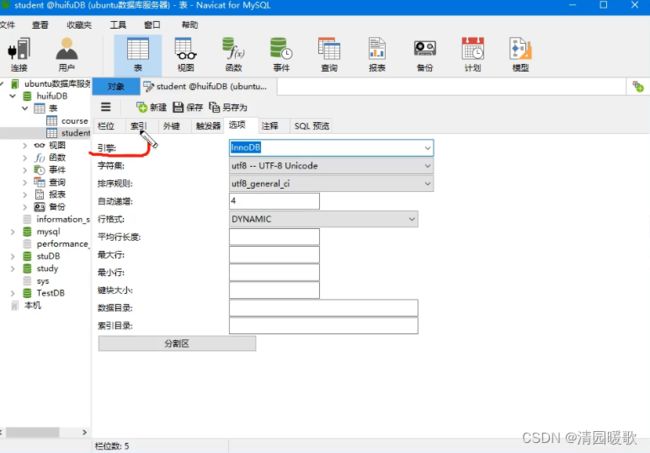

2.2 手动提交
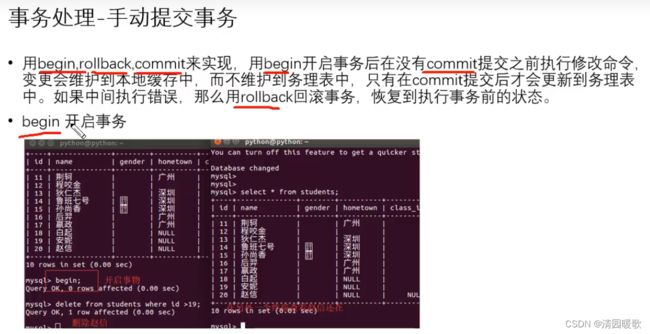
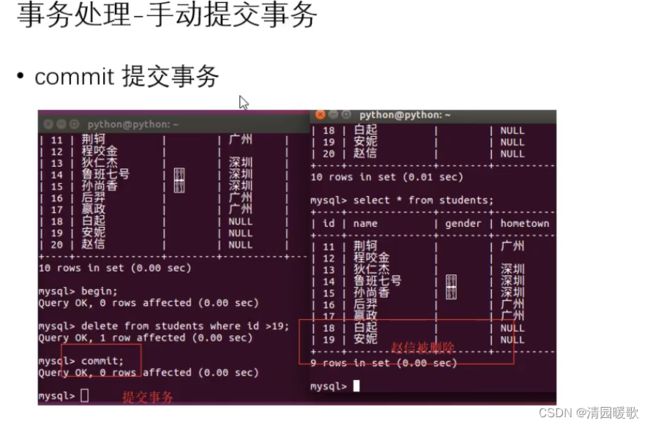

begin开启事务后,未提交,删除的修改命令储存在本地缓存中,会回滚,所以另一终端看没有删除,提交后就会删除
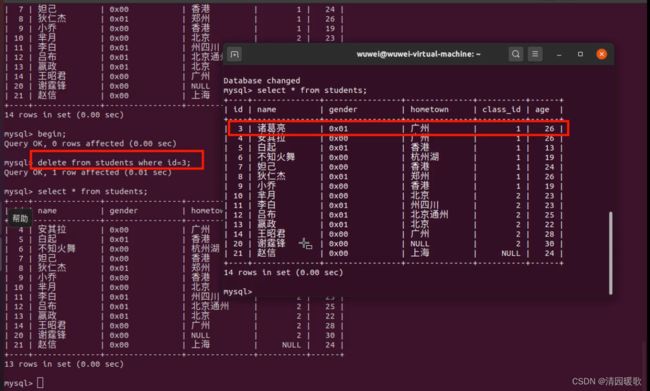
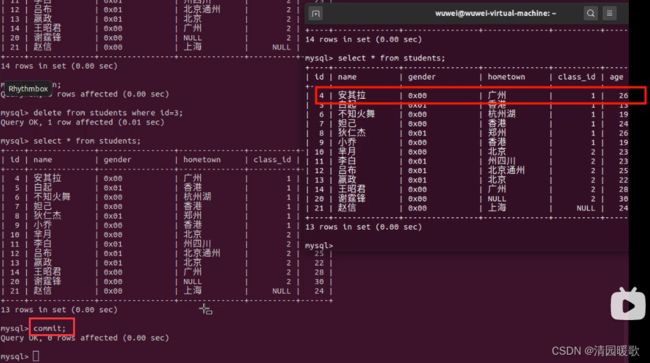
如果有误操作还未提交的,可以使用rollback回滚一下,返回刚才的操作;没提交时,出现异常,也会自动回滚
2.3 自动提交

所以没有使用begin也是有事务存在的,默认就是自动提交
2.4 隐式处理

三、视图和索引
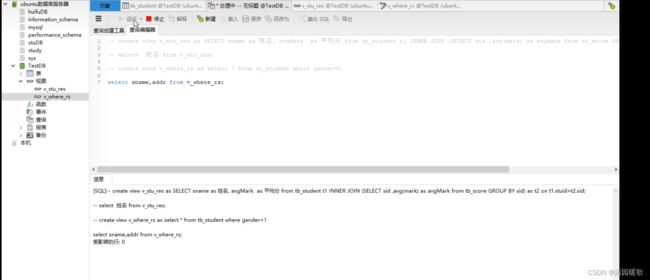
3.1 视图

视图:是一张虚拟的表,这个表的数据结构和数据是由select语句来指定的,不会生成真实的文件,本质上就是对查询的封装。
什么场景下用到视图:
场景1:如果某个查询结果出现的非常频繁,也就是说,经常用这个查询结果来做子查询,此时就可以使用视图了,用户可以将注意力集中在所关心的数据上,可以定义结构简单,清晰的查询操作[视图]
场景2:保密的诉求,可以过滤敏感数据,比如有一个工资表,希望只有财务能看到员工工资,其他人看不到,那么就可以用视图来包装这样的数据,过滤掉敏感的字段
3.2 索引


mysql索引的区别:
主键索引:他是一种特殊的唯一索引,不允许有空值
普通索引:最基本的索引没有什么限制
唯一索引[unique]:唯一约束,跟我们的普通索引类似,索引列的值必须唯一,允许有空值
全文索引: 仅可用于 myisam,针对的是较大的数据,varchar ,text,生成全文索引很耗时间和空间
组合索引:为了更好的提高mysql效率,允许建立组合索引,遵循 最左前缀 原则


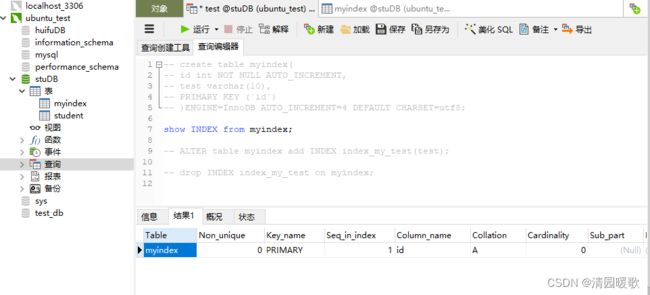
-- create table myindex(
-- id int NOT NULL AUTO_INCREMENT,
-- test varchar(10),
-- PRIMARY KEY (`id`)
-- )ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
show INDEX from myindex;
-- ALTER table myindex add INDEX index_my_test(test);
-- drop INDEX index_my_test on myindex;

四、存储过程
4.1 创建、调用和删除存储过程



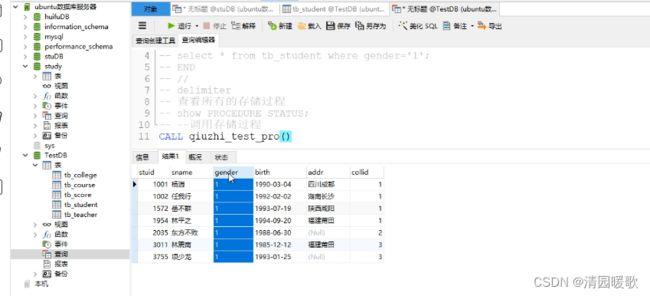
delimiter //
create PROCEDURE qiuzhi_test_pro()
BEGIN
select * from tb_student where gender='1';
END
//
delimiter;
-- 查看所有的存储过程
-- show PROCEDURE STATUS;
-- 调用存储过程
-- CALL qiuzhi_test_pro()
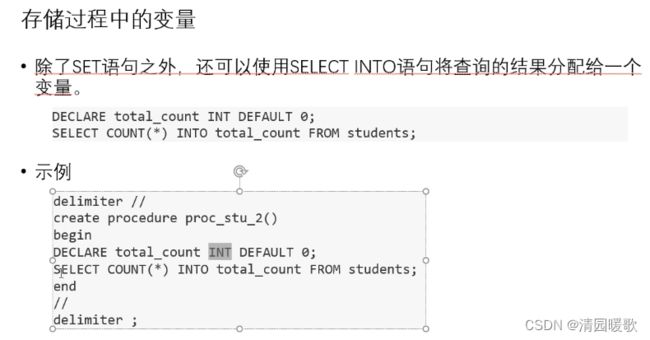
4.2 存储过程的变量

4.3 条件语句



4.4 while循环语句
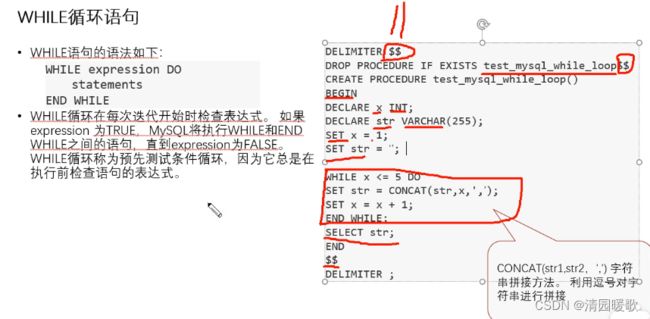
DROP PROCEDURE IF EXISTS test_mysql_while_loop$$
# 先执行这一语句,如果test_mysql_while_loop存在的话就删除int autocommit=0; # 关闭自动提交
START TRANSACTION; # 插入一个事务
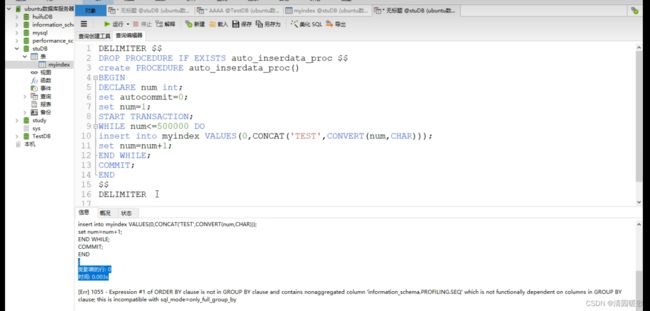
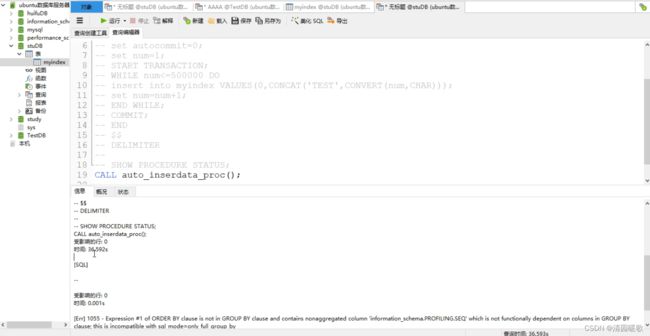
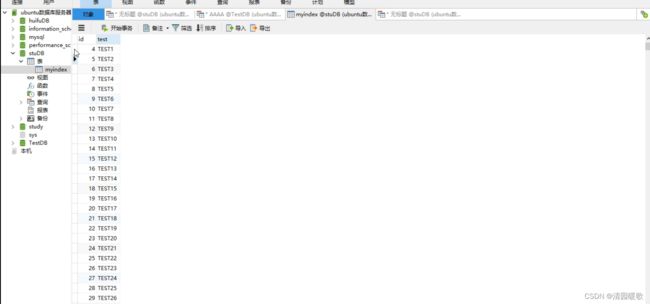
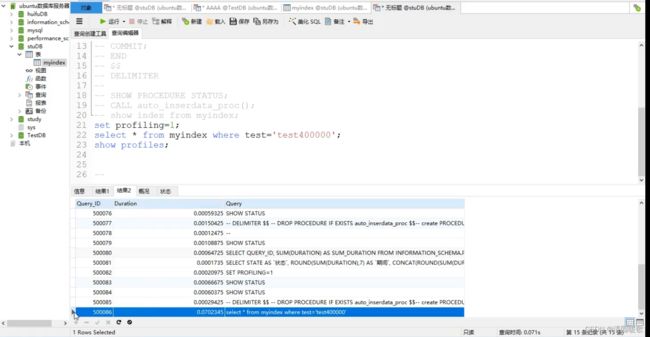
此时没有索引
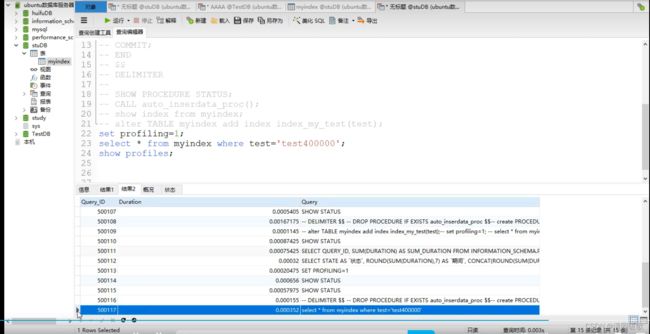
加了索引index后
五、函数
5.1 内置函数-字符串函数


5.2 日期时间函数

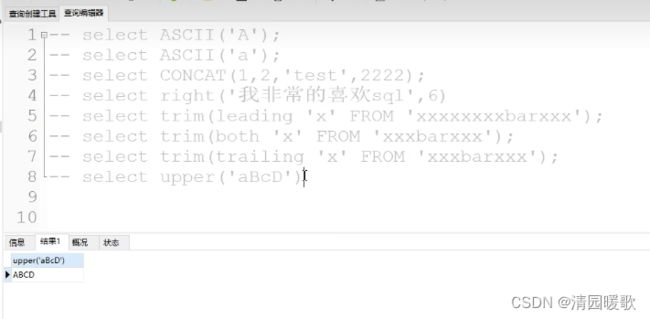
5.3 自定义函数
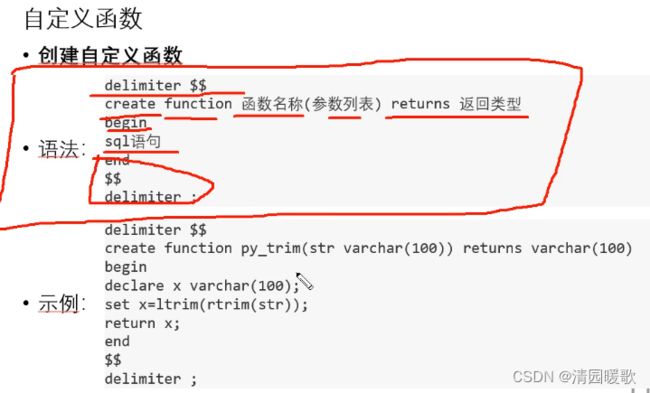
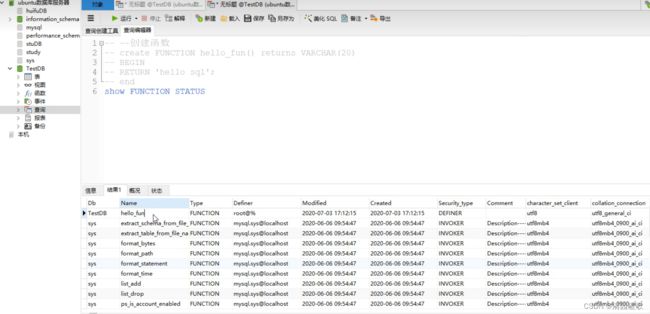
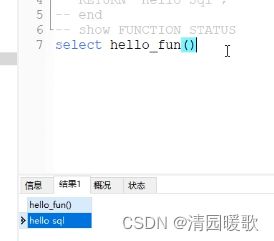
最好是先判断该函数名有没有存在
5.4 查询变量
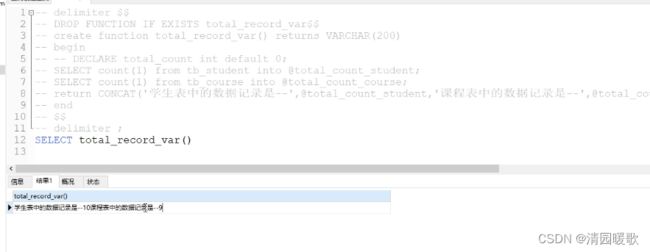
也可不先定义变量,直接使用
 函数必须要返回值,且仅仅返回一个结果集
函数必须要返回值,且仅仅返回一个结果集
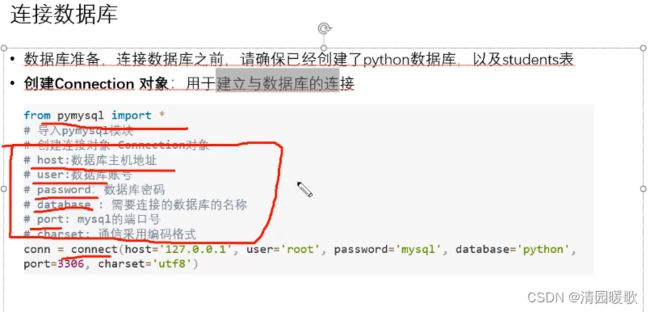
六、Python DB-API


打开pycharm 终端输入 pip install pymysql 安装PyMySQL


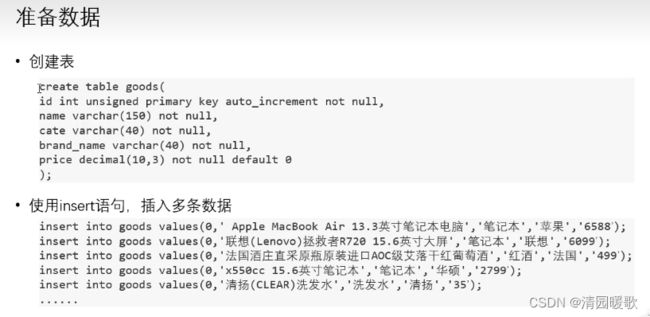
七、查询实战



八、小结
8.1 知识总结

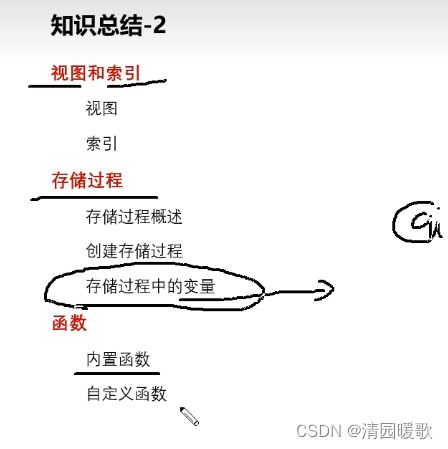

8.2 mysql索引区别
mysql索引的区别:
主键索引:他是一种特殊的唯一索引,不允许有空值
普通索引:最基本的索引没有什么限制
唯一索引[unique]:唯一约束,跟我们的普通索引类似,索引列的值必须唯一,允许有空值
全文索引: 仅可用于 myisam,针对的是较大的数据,varchar ,text,生成全文索引很耗时间和空间
组合索引:为了更好的提高mysql效率,允许建立组合索引,遵循 最左前缀 原则
8.3 mysql存错过程
delimiter就是告诉mysql解释器,该段命令是否已经结束了,
是否可以执行了。默认情况下,delimiter是分号;,遇到分号就执行。
后面的双美元符号 就是告诉mysql,遇到双美元符号再执行
这是正确的存储过程写法,可以成功执行,增加了DELIMITER,
简单解释下这个命令的用途,在MySQL中每行命令都是用“;”结尾,
回车后自动执行,在存储过程中“;”往往不代表指令结束,马上运行,
而DELIMITER原本就是“;”的意思,因此用这个命令转换一下“;”为 “//”,这样
只有收到“//”才认为指令结束可以执行
-- delimiter //
-- create PROCEDURE qiuzhi_test_pro()
-- BEGIN
-- select * from tb_student where gender='1';
-- END
-- //
-- delimiter
-- 查看所有的存储过程
-- show PROCEDURE STATUS;
-- --调用存储过程
CALL qiuzhi_test_pro()
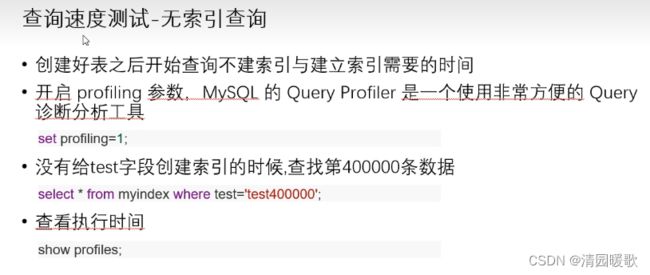
没有添加索引的时间
500086 0.0702345 select * from myindex where test='test400000'
添加完索引的时间
500117 0.000352 select * from myindex where test='test400000'
8.4 mysql函数
-- --创建函数
-- create FUNCTION hello_fun() returns VARCHAR(20)
-- BEGIN
-- RETURN 'hello sql';
-- end
-- show FUNCTION STATUS
-- select hello_fun()
-- delimiter $$
-- DROP FUNCTION IF EXISTS hello_say$$
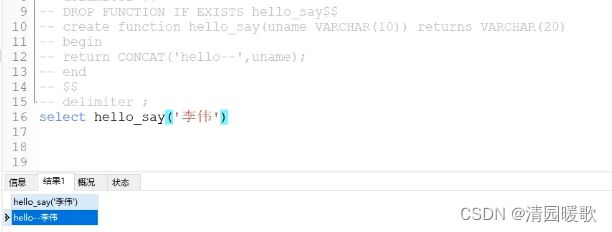
-- create function hello_say(uname VARCHAR(10)) returns VARCHAR(20)
-- begin
-- return CONCAT('hello--',uname);
-- end
-- $$
-- delimiter ;
-- select hello_say('李伟') --调用
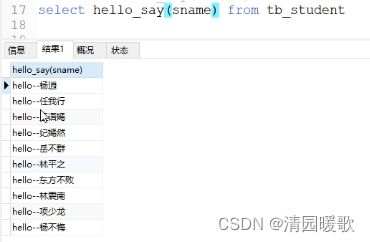
-- select hello_say(sname) as name from tb_student --调用
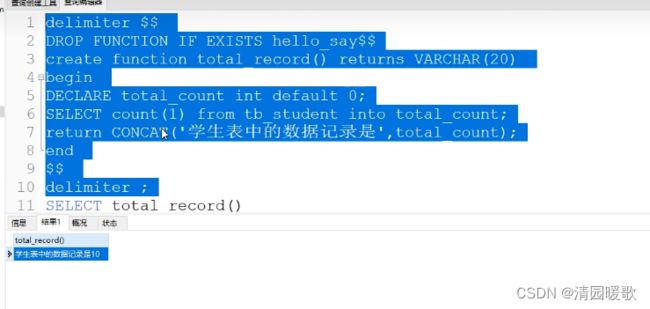
CREATE FUNCTION `total_record_var`() RETURNS varchar(200) CHARSET utf8
begin
-- DECLARE total_count int default 0;
SELECT count(1) from tb_student into @total_count_student;
SELECT count(1) from tb_course into @total_count_course;
return CONCAT('学生表中的数据记录是--',@total_count_student,'课程表中的数据记录是--',@total_count_course);
end
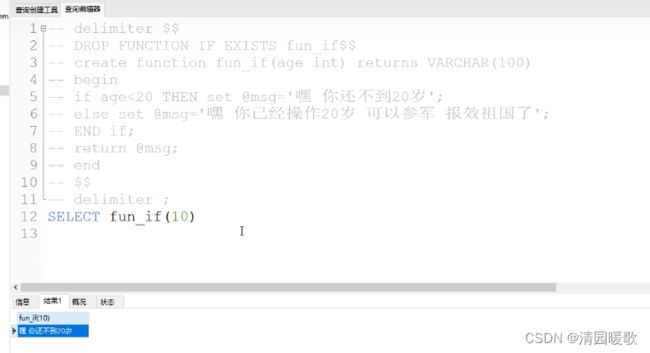
-- delimiter $$
-- DROP FUNCTION IF EXISTS fun_if$$
-- create function fun_if(age int) returns VARCHAR(100)
-- begin
-- if age<20 THEN set @msg='嘿 你还不到20岁';
-- else set @msg='嘿 你已经操作20岁 可以参军 报效祖国了';
-- END if;
-- return @msg;
-- end
-- $$
-- delimiter ;
SELECT fun_if(10)
8.5 存储过程和函数区别
存储过程和存储函数区别
1: 函数的限制比较多,比如不能使用临时表,只能使用表变量,存储过程限制比较少
2:存储过程实现的功能逻辑相对来讲要复杂一些,而函数的实现功能针对性强一些
3:返回值不同,函数是必须要返回值的,且仅仅返回一个结果,存储过程可以没有返回值,但是能返回结果集
4:调用的语法不同
函数经常会嵌入到sql中使用,通过select 函数名()
存储过程通过call 语句去调用