
01 背景
内存不足引发的APP崩溃通常称为OOM(Out Of Memory),iOS端无法捕获OOM异常,也得不到任何堆栈信息,给我们排查和解决问题带来很多困扰。引起OOM的原因归根结底就是因为内存分配不合理引起的,尤其是内存处于危险水位时单次内存分配过大引起Jetsam机制开始生效而杀掉进程,通过我们线上数据监控,百度APP客户端单次内存分配超过30M的case很多。
针对这种潜在的引起OOM的隐患,我们开发了一种大内存分配监控方案,充分利用线上监控优势(丰富真实的用户场景和用户路径)和线下流水线优势(可获取更多的堆栈信息),其中线上环境除了功能实现外,还要重点考虑稳定性,不能引入额外的性能问题,经过技术探索我们解决了此类难题,线上监控和线下流水线监控相结合实现对百度APP大块内存的监控。
02 技术方案综述
大块内存监控大体分为两个功能模块,缺一不可:
- 获取内存分配详情。判断单次内存分配是否超过阈值,若超过阈值,说明是大内存分配行为;
- 获取堆栈信息。丰富的堆栈信息可直接帮助开发同学定位到产生大内存分配的具体代码,定位分配不合理的case。
最终可通过优化内存分配不合理的case,达到降低OOM率的目标。
03 获取内存分配详情
3.1 方案对比
关于获取iOS端每次内存分配信息,有如下解决方案:
- 通过 hook 内存分配函数 alloc 方法获取,用 swizzle 方法实现 hook,存在的缺点是监控范围不够全面,只能监控 OC 对象,不能监控 C/C++ 对象。
- hook 库libsystem\_malloc 内存分配函数 malloc\_zone\_malloc、malloc\_zone\_calloc、malloc\_zone\_valloc、malloc\_zone\_realloc来获取内存信息。这种方案对于 OC 对象和 C/C++ 对象都可监控,但是因为要 hook 系统 C/C++ 方法而不是 OC 方法,目前的技术条件需要使用 fishhook。

百度APP 采用的技术方案如下图所示,首先通过重置 libsystem\_malloc 库中的malloc\_logger 函数指针获取内存活动详情(分配和释放两种活动),然后通过Type类型过滤出内存分配的活动, 最后获取内存分配大小,该方案可监控 OC 对象和 C/C++ 对象,对iOS框架系统没有侵入性,没有用 fishhook 库所以没有对 mach-o 文件做任何修改,也没有 hook 任何底层分配内存系统方法,从 APP 性能和质量角度来说是最好的选择。

3.2 libsystem\_malloc源码分析
libsystem\_malloc.dylib 是iOS系统虚拟内存管理的核心库之一,任何涉及到OC、C/C++ 对象的内存分配都会调用该库的API,由它去调用操作系统Mach内核提供的接口去分配或释放内存。具体来说 libsystem\_malloc 提供了 malloc\_zone\_malloc,malloc\_zone\_calloc,malloc\_zone\_valloc,malloc\_zone\_realloc,malloc\_zone\_free 五个API来实现内存分配和释放,在 iOS 系统中所有涉及到的内存活动都会调用如上接口,当我们App进程需要创建新的对象时,如调用 [NSObject alloc],或释放对象调用 release 方法时(编译器会添加),请求先会走到 libsystem\_malloc.dylib 的上述函数。
Apple 已开源此库,从如下地址可以下载到源码:https://opensource.apple.com/...
void *malloc_zone_malloc(malloc_zone_t *zone, size_t size){ MALLOC_TRACE(TRACE_malloc | DBG_FUNC_START, (uintptr_t)zone, size, 0, 0);void *ptr;if (malloc_check_start && (malloc_check_counter++ >= malloc_check_start)) { internal_check(); }if (size > MALLOC_ABSOLUTE_MAX_SIZE) {return NULL; } ptr = zone->malloc(zone, size); // if lite zone is passed in then we still call the lite methodsif (malloc_logger) { malloc_logger(MALLOC_LOG_TYPE_ALLOCATE | MALLOC_LOG_TYPE_HAS_ZONE, (uintptr_t)zone, (uintptr_t)size, 0, (uintptr_t)ptr, 0); } MALLOC_TRACE(TRACE_malloc | DBG_FUNC_END, (uintptr_t)zone, size, (uintptr_t)ptr, 0);return ptr;}3.3 关键函数malloc\_logger
从源码中我们发现malloc\_zone\_malloc、malloc\_zone\_calloc、malloc\_zone\_valloc、malloc\_zone\_realloc、malloc\_zone\_free五个API,在每次调用mach内核函数进行内存分配和释放后都有如下函数调用:
if (malloc_logger) {
malloc_logger(MALLOC_LOG_TYPE_ALLOCATE | MALLOC_LOG_TYPE_HAS_ZONE, (uintptr_t)zone, (uintptr_t)size, 0, (uintptr_t)ptr, 0);
}先判断malloc\_logger函数指针是否为空,如果不为空会调用上述函数,将内存活动的详细信息通过该函数传递进来,从源码分析的角度来看这是iOS系统提供的一个日志函数,具体函数定义如下所示:
typedef void(malloc_logger_t)(uint32_t type,
uintptr_t arg1,
uintptr_t arg2,
uintptr_t arg3,
uintptr_t result,
uint32_t num_hot_frames_to_skip);
extern malloc_logger_t *malloc_logger;根据源码我们对malloc\_logger函数的入参做如下分析:
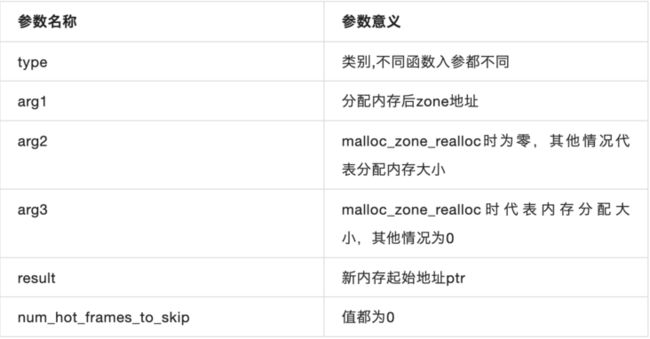
对于第一个type字段,不同函数都不同,具体值后面详细解释,此外,我们发现malloc\_logger生命为extern类型,在C++中声明extern关键字的全局变量和函数可以使得它们能够跨文件被访问。
3.4 通过重置malloc\_logger函数指针获取内存活动详情
在前面章节我们说过malloc\_logger为extern全局变量,所以通过以下步骤可以重置该变量获取内存活动详情;
1. 引入libmalloc头文件malloc/malloc.h
2. 定义函数bba\_malloc\_stack\_logger,参数定义与源码定义完全一致,这样做的目的是防止实参传递的时候出现类型和参数个数不一致的问题。
3. 先保存malloc\_logger函数指针的值到一个临时变量origin\_malloc\_logger,目的是保存系统原始调用方法,交换函数指针后还要调用此方法。
#import
typedef void (malloc_logger_t)(uint32_t type, uintptr_t arg1, uintptr_t arg2, uintptr_t arg3, uintptr_t result, uint32_t num_hot_frames_to_skip);
//定义函数bba_malloc_stack_logger
void bba_malloc_stack_logger(uint32_t type, uintptr_t arg1, uintptr_t arg2, uintptr_t arg3, uintptr_t result, uint32_t backtrace_to_skip);
// 保存malloc_logger到临时变量origin_malloc_logger
orgin_malloc_logger = malloc_logger; 4. 将malloc\_logger赋值为自定义函数bba\_malloc\_stack\_logger,在定义函数中先调用原始的系统方法origin\_malloc\_logger,该方法的调用保证了本方案对系统没有侵入性,接下来做大块内存检测。
//malloc_logger赋值为自定义函数bba_malloc_stack_logger
malloc_logger = (malloc_logger_t *)bba_malloc_stack_logger;
//bba_malloc_stack_logger具体实现
void bba_malloc_stack_logger(uint32_t type, uintptr_t arg1, uintptr_t arg2, uintptr_t arg3, uintptr_t result, uint32_t backtrace_to_skip)
{
if (orgin_malloc_logger != NULL) {
orgin_malloc_logger(type, arg1, arg2, arg3, result, backtrace_to_skip);
}
//大块内存监控
......
}经过上面四个步骤,malloc\_zone\_malloc、malloc\_zone\_calloc、malloc\_zone\_valloc、malloc\_zone\_realloc每次内存分配结束后,调用如下函数,因为malloc\_logger现在不为空,具体值为bba\_malloc\_stack\_logger,所以在bba\_malloc\_stack\_logger中可以获取内存分配活动详情。
if (malloc_logger) { malloc_logger(MALLOC_LOG_TYPE_ALLOCATE | MALLOC_LOG_TYPE_HAS_ZONE, (uintptr_t)zone, (uintptr_t)size, 0, (uintptr_t)ptr, 0);}3.5 通过type类型过滤出内存分配详情
通过上面章节我们知道malloc\_zone\_malloc、malloc\_zone\_calloc、malloc\_zone\_valloc、malloc\_zone\_realloc、malloc\_zone\_free五个API都会调用bba\_malloc\_stack\_logger,其中的API实现又各有不同,malloc\_zone\_malloc、malloc\_zone\_calloc、malloc\_zone\_valloc代表内存分配,malloc\_zone\_realloc代表内存先释放再分配,malloc\_zone\_free代表内存释放,不同的API调用是通过入参type来区分的,所以本技术方案通过type反解析来获取内存分配,过滤掉内存释放。

3.6 获取单次内存分配大小并判断是否超过阈值
根据源码我们知道malloc\_logger函数的入参arg2,arg3代表内存分配大小,不同type代表含义不同,具体见下面表格分析。

接下来判断是否超过我们设定的阈值的大小,在iOS端根据经验单次内次分配8M就是普遍认为的大块内存,当然这个值由服务端下发可灵活修改,客户端写个默认值即可,但是这个值不建议很小,太小会多次触发大块内存监控逻辑影响我们手机app的性能,超过阈值大小就进入下面的环节获取堆栈信息。
04 获取堆栈信息
4.1 百度App采用的技术方案
调用系统方法backtrace\_symbols可直接获取堆栈信息,但是存在两个问题,第一、方法具有线程属性,必须要在获取堆栈信息的当前线程调用;第二、耗时严重,实测在中高端机(iPhone8以上)有30ms耗时,在低端机(iPhone8以下)有100ms的耗时。如果大块内存是在主线程分配的,上述耗时会引起主线程卡顿问题,故此方案无法针在线上生产环境使用。
针对这个问题,百度App采用的方案如下所示,结合客户端和服务端双端优势,首先利用dyld库生成了APP所有库的起始地址和结束地址,将获取堆栈函数地址信息详情步骤获取完全放在独立子线程中实现,在客户端拼接成crash日志格式,充分利用服务端做堆栈详情反解析操作,客户端只需要在专属子线程执行耗时较少的堆栈函数地址比较操作即可,这样做不会影响所属线程任何操作,更不会引入性能问题,完全克服了系统方法的不足,具体操作流程如下图所示:

4.2 生成所有库的地址范围(dyld)
生成APP中mach-o文件的所有库的信息,该信息包括库名称、库起始地址和结束地址,该操作主要利用dyld库函数在子线程实现,不会占用主线程和内存分配所属线程任何资源。dyld库提供了丰富的api可以获取上述数据,具体来说,\_dyld\_image\_count可获取所有模块数目,dyld\_get\_image\_name 可获取模块名称,dyld\_get\_image\_header可获取每个模块的起始地址,\_dyld\_get\_image\_vmaddr\_slide获取单个模块的随机基址。
4.3 backtrace获取堆栈地址
当检测到大块内存时,在分配内存所属线程调用backtrace方法获取堆栈函数地址,代码示例:
//返回值depth表示实际上获取的堆栈的深度,stacks用来存储堆栈地址信息,20表示指定堆栈深度。
size_t depth = backtrace((void**)stacks, 20);那么backtrace耗时究竟如何?通过实践数据证明,堆栈深度设置为20,实测高端机耗时在3ms以内,对性能影响基本可以忽略,此外,不是每次内存分配都需要调用backtrace获取堆栈,只有单次内存分配大小符合大块内存标准才会去获取堆栈。
因此我们在线上生产环境堆栈深度设置为20并且只对高端机开放,深度值太小获取的堆栈信息有限,太大会明显增加backtrace方法耗时,线上数据证明堆栈深度设置为20既能满足性能要求又能解析出合理的堆栈信息,在线下流水线场景下堆栈深度为40以获取更丰富的堆栈信息,两个场景各自发挥自己的优势并相互补充。
4.4 获取每个地址详细信息
经过4.3步骤,我们获取了堆栈地址,但是这个还不够,为了方便服务端直接可以解析出堆栈信息,我们在客户端需要将堆栈地址拼装成下图所示堆栈格式(类似Crash堆栈),libsystem\_kernel.dylib 0x1b8a9dcf8 0x1b8a73000 + 175352 ,第一项是库名称,第二项是堆栈函数地址(十六进制),第三项是动态库的起始地址(十六进制),第四项是十进制偏移量,其中第二项堆栈函数地址是通过4.3步骤的backtrace获取的,下面的重点是获取每个地址对应的动态库名称和相对于动态库起始地址的偏移量。
对于上述详细信息的获取,本技术方案将该操作完全放在子线程去实现,因为我们已经在4.2构建好了每个库的起始地址和结束地址,只需要遍历一遍全量库,判断地址是否大于该库起始地址并小于该库的结束地址,那说明该地址就是属于这个库,从而得到该地址的详细信息,堆栈地址和动态库其实地址做差值可获取偏移量信息。
4.5 atos和dsym解析堆栈
经过前面的步骤生成了类似crash日志格式的堆栈,上报服务端后,最后在服务端通过atos命令和dsym文件就可以反解还原出对应的堆栈内容,如:
BaiduBoxApp 0x000000010ff0ceb4 +[BBAJSONSerialization dataFromJSONObject:error:] + 256通过这种方式可以把耗时较高的符号还原工作放到服务器端,客户端只需要执行耗时较少的堆栈函数地址比较操作即可,放在子线程队列执行,不会影响所属线程任何操作,更不会引入性能问题。
05 总结
本文主要介绍百度APP大块内存监控方案,目前在生产环境和线下流水线环境均已部署,通过该方案实现了如下三个目标:
- 降低OOM率:如果内存分配不合理,优化后对降低OOM率有帮助;
- 数据摸底,让我们明确知道百度APP哪些场景有大块内存分配;
- 起到预防的作用,因为我们有明确的监控机制,督促每个开发同学创建内存对象时采用适量原则避免无节制分配。
06 参考链接
[1] libsystem\_malloc.dylib源码
https://opensource.apple.com/...
[2] Mach-O文档介绍
https://developer.apple.com/l...
[3] Mach-O源码
https://opensource.apple.com/...\_HEADERS/mach-o/loader.h.auto.html
[4]fishhook
https://github.com/facebook/f...
——————END——————
推荐阅读: