MTCNN优化和另类用法
MTCNN优化和另类用法
MTCNN是目前应用十分广泛的基于级联的特定目标检测器,也是少数能在传统硬件上落地的检测器,当然其优势不光光仅仅用于人脸检测这个任务。在人脸这个任务上,在少数人脸<5个人脸的情况下。其效能是第一梯队的水准。而且有着极大的优化空间(加上一些trick可以轻易的优化到极快的速度移动端 minSize60 60fps 1080p mt.)。而且其Alignment的准确率和精度也相对相对比较高,在工业界的人脸识别工作中,往往都采用MTCNN的点位来进行对齐。
人脸跟踪是一项很重要的任务,cascade based检测模型,在人脸基数增大的同时,往往速度上容易爆炸,在工程应用中往往需要极致的速度。在有些效率比较低的ARM板子上,一些correlation filter tracker都不能取得很好的时效性。
MTCNN的多任务特性为我们权衡这个问题提供的特别巧妙的方法。
MTCNN的优化
MTCNN (Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks)是Kaipeng Zhang在2016年提出的Face Detector,也是基于Cascade CNN来改进的Face Detector。文章认为人脸检测任务中的 face bounding box regression 和 landmark 任务存在潜在关系,可以提高人脸检测效果。由于其多任务和全卷积的特性其速度要比Cascade CNN要快不少。由于MTCNN训练的Pipeline比较繁琐,需要一定的经验和调试,后继有人又提出了把Cascade pipeline联合起来训练的(Facecraft 和 xxx 两篇文章 都来自于商汤)。后来还有加Anchor 的做法 如 Anchor CNN 本文不再赘述。本文主要是从工程角度在FDDB下降不是特别多的情况下来改进和为了人脸识别而检测人脸的目的来加速MTCNN。
基本原理
MTCNN基本原理是使用全卷积的P-Net在多尺度的待检图像上生成候选框,接着通过R-Net和O-Net来过滤。
MTCNN的结构
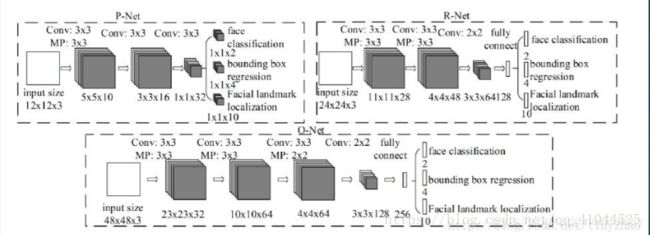
我们可以看到其网络结构和Cascade CNN基本是一致的。由于文章的发表时间是2016年。一些较为modern的网络设计trick在当时也没有被提出。所以我们改进的空间还是有的。我们做了一些实验,也发现了MTCNN速度的瓶颈在哪。
主要是以下几点
- 图片越大Pnet耗时也就越大。
- 人脸越多Onet和Rnet耗时越大。
- 噪点比较多的夜晚图像会导致Pnet误检测增多。
针对第一和第二个问题,我们选择优化网络结构,使之精度下降不太多的情况下,尽可能的减少计算量,第一个我们想到的是Mobilenet系列中的Depthwise卷积。
Depthwise卷积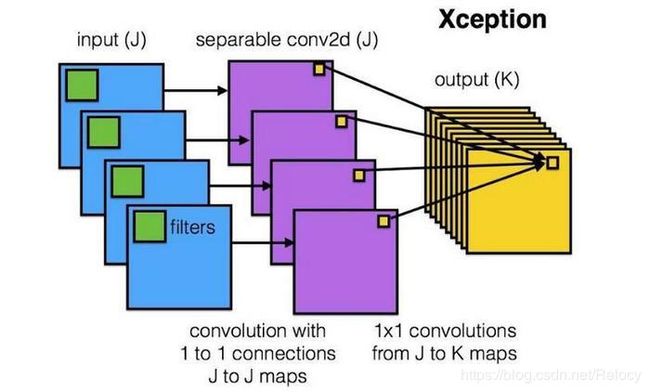
Depthwise卷积最初来源于Xception。其思路比较直接,先是对输入图的每个通道进行卷积,然后再由1x1卷积将他们合并起来,大量实验证明的这个操作基本可以等同于普通的Sptial卷积。并且在IO效率和性能不变的情况下,计算量降低9倍。我们可以利用这个思路替换Pnet和Rnet和Onet中的卷积操作使之速度有着大幅度提升。
但是有时候即使加了Depthwise卷积在某些嵌入式环境下,效果仍然不是很好,达不到良好的效果。我们发现Depthwise卷积80-90%的计算量基本都被后面的1x1卷积占据了。这时我们想是否也可以把1x1卷积也用类似于Depthwise的分组卷积来替代,但是一旦把后面1x1卷积分组,组与组之间的信息就无法相互交流了,于是shuffle-channel的出现很好的解决了这个问题。
shuffle-channel
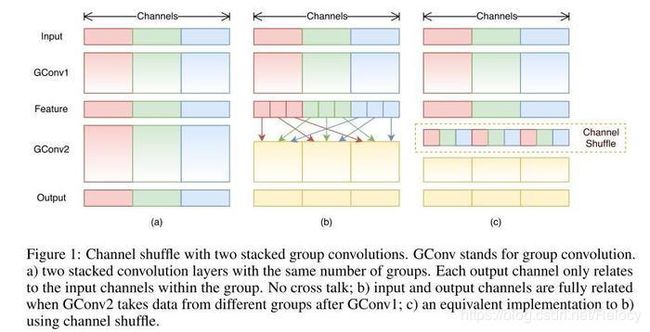
shuffle-channel来源于旷世的ShuffleNet。虽然这篇文章宣称的精度难以复现。但其shuffle-channel的思想是非常值得借鉴的。shuffle-channel的原理将特征的通道平均分到不同组里面。是之每个组卷积的时候能得到其他组的信息。起到了一个组之间通信的作用。
我们做了一些实验来证明了本文论述的结果
| sets-1 | sets-2 | |
|---|---|---|
| MTCNN | 21fps | 11fps |
| MTCNN-dw | 131fps | 101fps |
| MTCNN-shuffle | 220fps | 135fps |
其中 sets-1 数据集均为一张人脸,sets-2数据集为2-4张人脸的普通监控场景。测试框架是caffe。环境为Macbook 2015 r15 2.2GHZ 的结果。
在Pnet检测前使用中值滤波
我们注意到在某些监控场景的夜晚图片,会有大量噪点的出现,我们知道由于CNN的不稳定性,所以导致了Pnet产生了大量的误检选区,为了减少这些噪点的出现,我们可以在Pnet检测之前,使用一次中值滤波来做个快速的去噪,总体实验下来有着不错的效果,每次inference时间也会更加的稳定。
框架的加速
我们将caffe版本的MTCNN inference改成opencv dnn,在普通的opencv dnn backend下取得了差不多近四倍的加速。
将 MTCNN 用于人脸与关键点追踪
在现实人脸识别为前提的布控条件下,往往需要追踪某个人的轨迹,受边缘计算功耗等影响。连续的每帧都做检测是并不是一罐的做法。而某些传统的基于相关滤波的追踪方法,在某些嵌入式条件下,并不能取得非常好的性能。MTCNN恰好为这个任务提供了不错的解决方案。我们可以将Onet连续的用于追踪。并且在优化过后效能也相对比较高。通常数十个目标在不同CPU场景下,并不会有很大的压力。
Onet
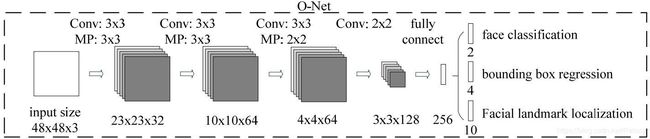
如图为原版的MTCNN结构图,其bounding box regression能力可以,在相邻帧的情况下,通过上一帧来预测下一帧的位置和关键点。
大致流程图
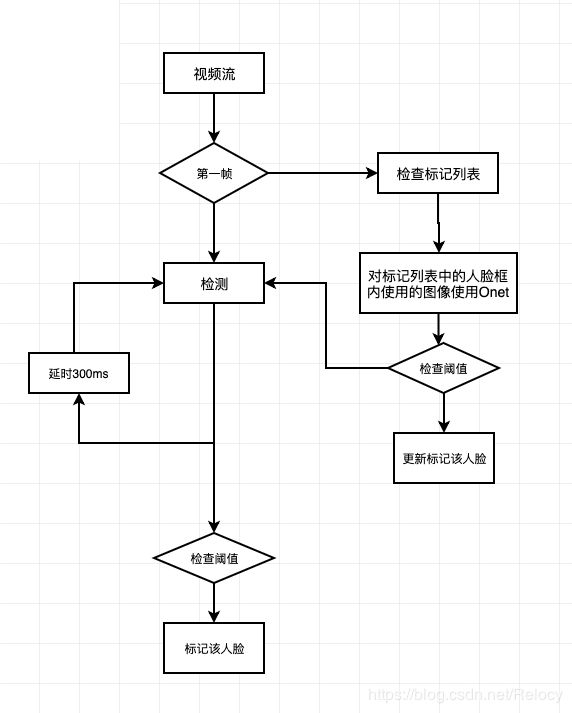
如图从视频流中读取每一帧,若当前帧是第1帧,则通过Pnet,Rnet,Onet进行一次完整的检测流程,并另起一个线程每隔指定检测人脸,接着选取大于阈值的人脸。检查是否与标记列表中的人脸有重合,若不重合,将人脸加入标记列表,之后的每一帧都会对标记列表中的每一帧,使用Onet进行forward一次,检查阈值,并将更新boundingbox。若小于阈值则认为更新失败,重新检测。
实测
在我们的实测环境下优化后的不管是原版的onet和优化后的onet在检测任务中,Onet都取得了不错的速度和性能。总体情况在一张人脸的追踪时间可以在移动端下做到2-3ms左右。虽然作为Onet tracker的追踪性能和和表现力上没有基于相关相关滤波的tracker来的好。但是在移动端或某些布控场景下也已经够用了。并且相比于相关滤波也免去了一次关键点的检测。

zeusee.com 智云视图