李沐《动手学习深度学习》--之pytorch神经网络基础(一)
目录
如何通过继承nn.module构造模型?
怎样修改默认的参数来修改我们自己的参数?
自定义自己的网络层
模型参数的存储到读回来的一个操作实现
如何通过继承nn.module构造模型?
补充知识:线性层和全连接层没有区别,线性层即全连接层
1. 回顾多层感知机
net = nn.Sequential(nn.Linear(20,256), # 输入层 input20,output256
nn.RelU(), # 隐藏层(全连接层)
nn.Linear(256,10)) # 输出层 input256,output 10以上代码构造了一个简单的单隐藏层的MLP,关于权重和初始化问题,nn.Linear中有默认的初始化
2.nn.Sequentional定义了一种特殊的Module,任何一个层或者一个神经网络都是一个Module的子类
4. *args是手机参数,相当于吧若干个参数打包成一个来传入
5. self._modules[]:是我们放在里面的一些层;是一个order dectionary
6. 可以在自定义的类中,在前向传播函数中设置自己的前向函数(对输入X进行各种操作)
7. 沐神的套娃
不知道为啥这里显示违规,详情请见以下网址:
16 PyTorch 神经网络基础【动手学深度学习v2】_哔哩哔哩_bilibili

怎样修改默认的参数来修改我们自己的参数?
1.修改网络中的初始化参数
def init_normal(m):
if type(m) == nn.Linear:
nn.init.normal_ = (m.weight, mean=0, std=0.01) # normal_是替换掉原来网络中自己带的初始化权重的函数
nn.init.zero_(m.bias)
net.apply(init_normal) # net.apply函数将net中的所有module遍历,将init_normal传入进行应用2. >= 的优先级高于 *=
x *= x.abs() >= 5 # x绝对值大于5的 x进行累乘
3. 两个层之间share parameters
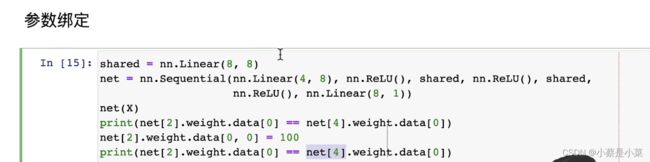

自定义自己的网络层
1. 自定义网络参数要放在nn.Parameters()中进行初始化
class MyLinear(nn.Module):
def __init__(self, in_units, units):
super().__init__()
self.weight = nn.Parameter(torch.randn(in_units, units)) # 参数的初始化
self.bias = nn.Parameter(torch.rand(units))
def forward(self, X):
linear = torch.multiply(X, self.weight.data) + self.bias.data
return F.relu(linear)2. 使用自己的定义的层利用Sequential 建立自己的模型
net = nn.Sequential(MyLinear(n,m),MyLinear(m,n))模型参数的存储到读回来的一个操作实现
1. 首先我们使用简单的tensor张量实现Demo
x = torch.arange(4) # 随机生成一个张量x
torch.save(x, 'x-file') # 保存在name为x-file的文件中,文件夹在当前项目文件夹中
x2 = torch.load('x-file') # 下载x-file中的值
print(x2)
2. 保存模型参数
# 自定义一个MLP模型
class MLP(nn.Module):
def __init__(self):
spuer().__init__()
self.hidden = nn.Linear(2, 256)
self.output = nn.Linear(256,10)
def forward(self,x):
return self.output(F.relu(self.hidden(x)))
net = MLP()
x = torch.randn(size=(200, 2))
Y = net(x)
# 存储模型的参数使用torch.save API
torch.save(net.state_dict(),'mlp.parameter') # net.state.dict()可以得到从字符串到parameter的映射 这里是将MLP中的所有参数存成一个字典
3.加载模型参数(将参数load回来)
沐神所言:不仅要将参数带走,还要将MLP定义带走
clone = MLP() # 这里就是将模型带走的
clone.load_state_dict(torch.load('mlp.parameter')) # 将load到的参数overwrite掉之前网络中的初始化参数
clone.eval()