牛客网在线编程题库——个人练习打卡记录(暂时停止)
牛客网在线编程题库__个人学习记录
- SQL篇
-
- Day1、查找最晚入职员工的所有信息
-
- 题解
- Day2、查找入职员工时间排名倒数第三的的员工所有信息
-
- 题解
- Day3、查找各个部门当前领导当前薪水以及其对应部门编号
-
- 题解
- Day4、查找所有已经分配部门的员工的部分信息
-
- 题解
- Day5、查找所有已经分配部门的员工的部分信息2
-
- 题解
- Day6、查找薪水记录超过15次的员工
-
- 题解
- Day7、找出所有员工薪水salary具体情况
-
- 题解
- Day8、获取所有非manager的员工的emp_no
-
- 题解
- Day9、获取所有员工当前的manager
-
- 题解
- Day10、获取每个部门中当前员工薪水最高的相关信息
-
- 题解
- Day11、查找employess表
-
- 题解
- Day12、统计出各个title类型对应员工薪水对应的平均工资
-
- 题解
- Day13、获取当前薪水第二多的员工的emp_no及其对应薪水
-
- 题解
- Day14、获取当前薪水第二多的员工的相关信息
-
- 题解
- Day15、查找所有员工的last_name和first_name以及对应的dept_name
-
- 题解
- Day16、查找所有员工入职以来的薪水涨幅
-
- 题解
- Day17、统计各部门的工资记录数
-
- 题解
- Day18、对所有员工的薪水按照salary进行按照1-N排序
-
- 题解
- Day19、获取所有非manager员工当前的薪水情况
-
- 题解
- Day20、获取当前员工薪水比其经理还高的相关信息
-
- 题解
- Day21、汇总各个部门当前员工的title类型的分配数目
-
- 题解
- Day22、牛客每个人最近的登录日期(一)
- 算法篇(暂时停止)
-
- Day1、 重建二叉树
-
- 题解
- Day2、反转链表
-
- 题解
- Day3、排序
-
- 题解
- Day4、链表的奇偶重排
-
- 题解
- Day5、最小的K个数
-
- 题解
- Day6、跳台阶
-
- 题解
- Day7、合并区间
-
- 题解
- Day8、股票(无限次交易)
-
- 题解
- Day9、通配符匹配
-
- 题解
- Day10、买卖股票的最好时机
-
- 题解
- Day11、最长递增子序列
-
- 题解
- 前端篇(暂时停止)
-
- Day1、修改this指向
-
- 题解
- Day2、Dom节点查找
-
- 题解
- Day3、根据包名,在指定空间中创建对象
-
- 题解
- Day4、判断是否以元音字母结尾
-
- 题解
- Day5、获取url参数
-
- 题解
- Day6、数组去重
-
- 题解
- Day7、斐波那契数列
-
- 题解
SQL篇
Day1、查找最晚入职员工的所有信息
有一个员工employees表简况如下:
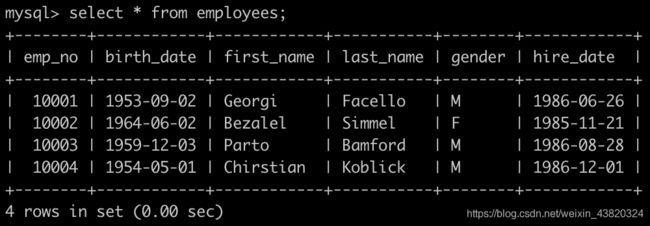
建表语句如下:
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
示例:
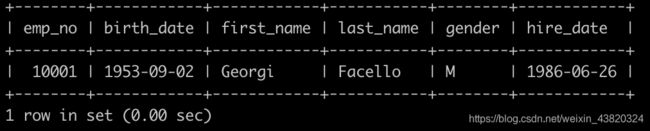
题解
select * from employees where hire_date = (select max(hire_date) from employees);
Day2、查找入职员工时间排名倒数第三的的员工所有信息
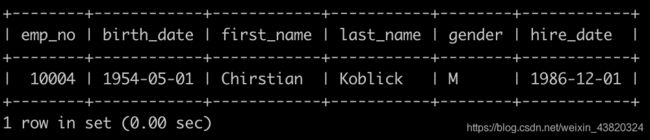
有一个员工employees表简况如下:
请你查找employees里入职员工时间排名倒数第三的员工所有信息,以上例子输出如下:
题解
select* from employees order by hire_date desc limit 2, 1;
Day3、查找各个部门当前领导当前薪水以及其对应部门编号
有一个全部员工的薪水表salaries简况如下:
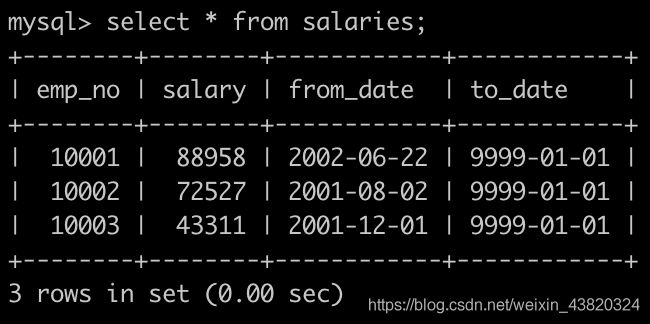
有一个各个部门的领导表dept_manager简况如下:
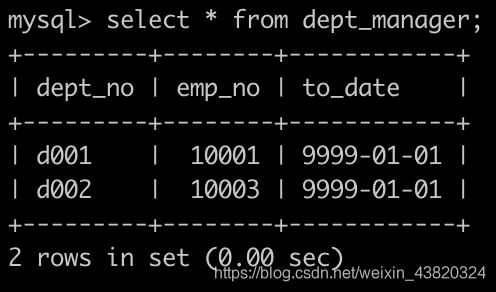
请你查找各个部门领导薪水详情以及其对应部门编号dept_no,输出结果以salaries.emp_no升序排序,并且请注意输出结果里面dept_no列是最后一列,以上例子输入如下:
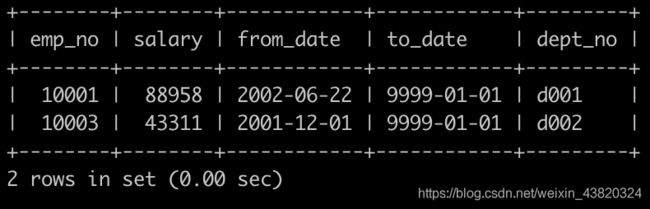
题解
select s.*, d.dept_no
from salaries s, dept_manager d
where s.emp_no = d.emp_no
order by s.emp_no;
Day4、查找所有已经分配部门的员工的部分信息
有一个员工表,employees简况如下:

有一个部门表,dept_emp简况如下:

请你查找所有已经分配部门的员工的last_name和first_name以及dept_no,未分配的部门的员工不显示,以上例子如下:

题解
# 运行时间:36ms 占用内存:5496KB
select e.last_name, e.first_name, d.dept_no
from employees e, dept_emp d
where e.emp_no = d.emp_no;
# 运行时间:40ms 占用内存:5240KB
select e.first_name, e.last_name, d.dept_no
from employees e right join dept_emp d
on e.emp_no = d.emp_no;
Day5、查找所有已经分配部门的员工的部分信息2
表信息为Day4中相同
请你查找所有已经分配部门的员工的last_name和first_name以及dept_no,也包括暂时没有分配具体部门的员工,以上例子如下:
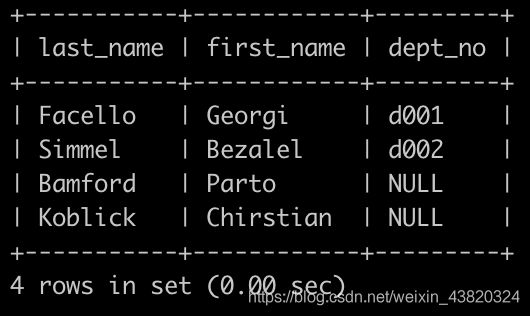
题解
select e.last_name, e.first_name, d.dept_no
from employees e left join dept_emp d
on e.emp_no = d.emp_no;
【注:本题与Day4题中的解法2区别在于left join和right join,连接好的左表是主表,若副(右)表无法与主表匹配,则自动模拟出NULL值】
Day6、查找薪水记录超过15次的员工
有一个薪水表,salaries简况如下:

请你查找薪水记录超过15次的员工号emp_no以及其对应的记录次数t,以上例子输出如下:
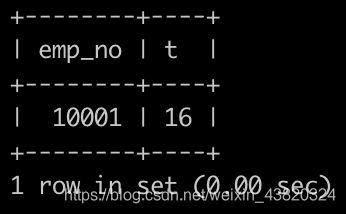
题解
SELECT emp_no, COUNT(emp_no) AS t
FROM salaries
GROUP BY emp_no
HAVING t > 15
Day7、找出所有员工薪水salary具体情况
有一个薪水表,salaries简况如下:
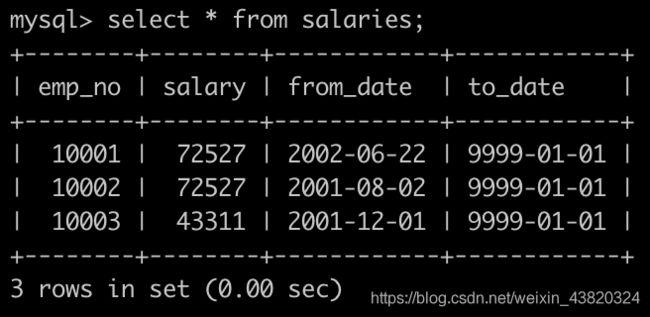
请你找出所有员工具体的薪水salary情况,对于相同的薪水只显示一次,并按照逆序显示,以上例子输出如下:
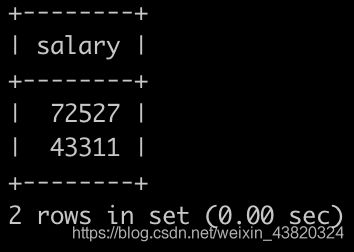
题解
select distinct salary
from salaries
order by salary desc;
Day8、获取所有非manager的员工的emp_no
有一个员工表employees简况如下:

有一个部门领导表dept_manager简况如下:

请你找出所有非部门领导的员工emp_no,以上例子输出:

题解
select e.emp_no
from employees e
where e.emp_no
not in (select d.emp_no from dept_manager d);
Day9、获取所有员工当前的manager
有一个员工表dept_emp简况如下:
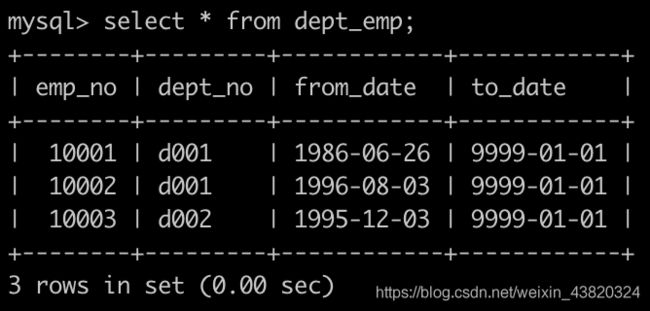
第一行表示为员工编号为10001的部门是d001部门。
有一个部门经理表dept_manager简况如下:
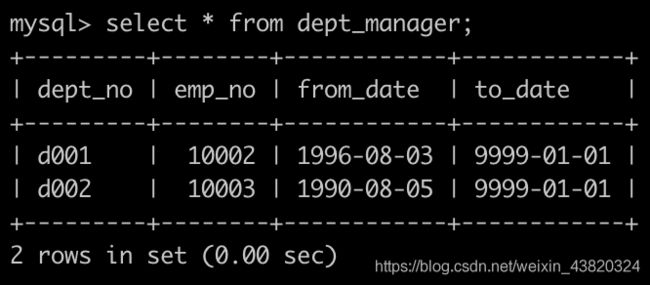
第一行表示为d001部门的经理是编号为10002的员工。
获取所有的员工和员工对应的经理,如果员工本身是经理的话则不显示,以上例子如下:

题解
SELECT e.emp_no, m.emp_no
FROM dept_emp e
JOIN dept_manager m
ON e.dept_no = m.dept_no
WHERE e.emp_no <> m.emp_no;
连接出所有的相同部门的‘员工—经理’组合,选择出员工≠经理的即可
Day10、获取每个部门中当前员工薪水最高的相关信息
有一个员工表dept_emp简况如下:
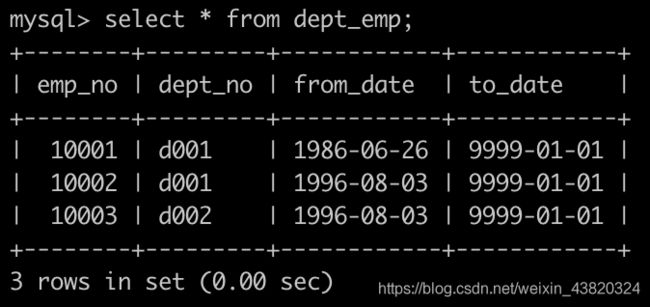
有一个薪水表salaries简况如下:
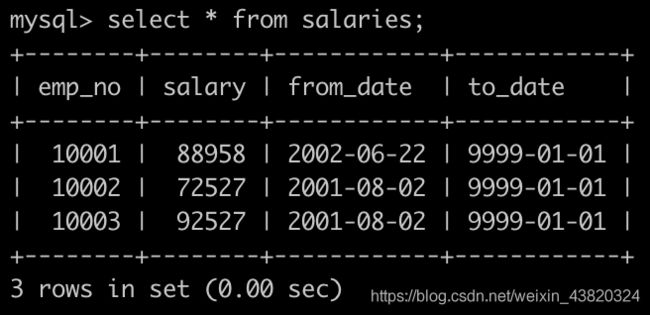
获取所有部门中员工薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary,按照部门编号升序排列,以上例子输出如下:
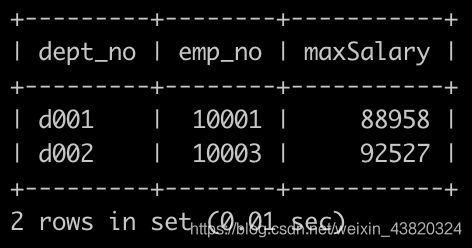
题解
SELECT d1.dept_no, d1.emp_no, s1.salary
FROM dept_emp as d1
INNER JOIN salaries as s1
ON d1.emp_no=s1.emp_no
WHERE s1.salary in (SELECT MAX(s2.salary)
FROM dept_emp as d2
INNER JOIN salaries as s2
ON d2.emp_no=s2.emp_no
AND d2.dept_no = d1.dept_no
)
ORDER BY d1.dept_no;
Day11、查找employess表
有一个员工表employees简况如下:
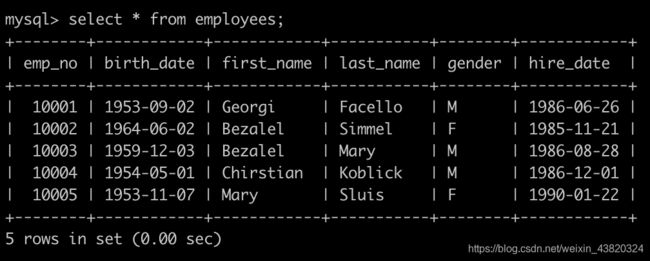
请你查找employees表所有emp_no为奇数,且last_name不为Mary的员工信息,并按照hire_date逆序排列,以上例子查询结果如下:
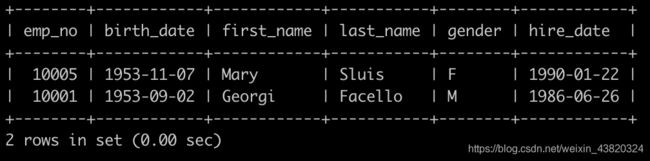
题解
select *
from employees
where emp_no%2 = 1
and last_name != 'Mary'
order by hire_date desc;
Day12、统计出各个title类型对应员工薪水对应的平均工资
有一个薪水表salaries简况如下:
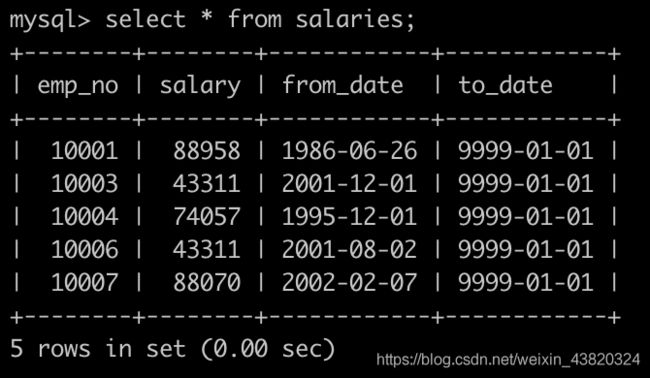
请你统计出各个title类型对应的员工薪水对应的平均工资avg。结果给出title以及平均工资avg,并且以avg升序排序,以上例子输出如下:

题解
select t.title avg(s.salary)
from titles t join salaries s
on t.emp_no = s.emp_no
group by t.title;
Day13、获取当前薪水第二多的员工的emp_no及其对应薪水
有一个薪水表salaries简况如下:
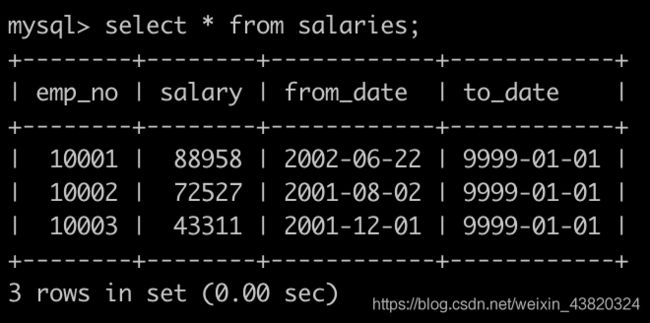
请你获取薪水第二多的员工的emp_no以及其对应的薪水salary

题解
select emp_no, salary
from salaries
order by salary desc
limit 1, 1;
Day14、获取当前薪水第二多的员工的相关信息
有一个员工表employees简况如下:
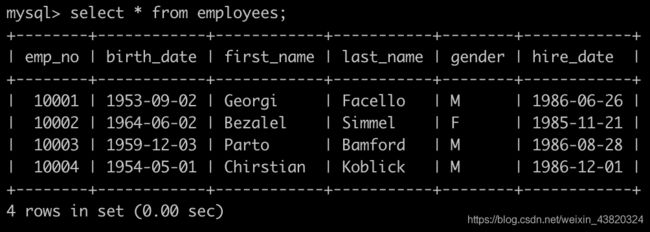
有一个薪水表salaries简况如下:

请你查找薪水排名第二多的员工编号emp_no、薪水salary、last_name以及first_name,不能使用order by完成,以上例子输出为:
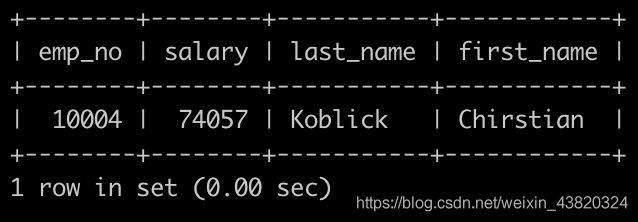
题解
select s.emp_no, s.salary, e.last_name, e.first_name
from salaries s join employees e
on s.emp_no = e.emp_no
where s.salary = -- 第三步: 将第二高工资作为查询条件
(
select max(salary) -- 第二步: 查出除了原表最高工资以外的最高工资(第二高工资)
from salaries
where salary <
(
select max(salary) -- 第一步: 查出原表最高工资
from salaries
)
)
Day15、查找所有员工的last_name和first_name以及对应的dept_name
有一个员工表employees简况如下:

有一个部门表departments表简况如下:
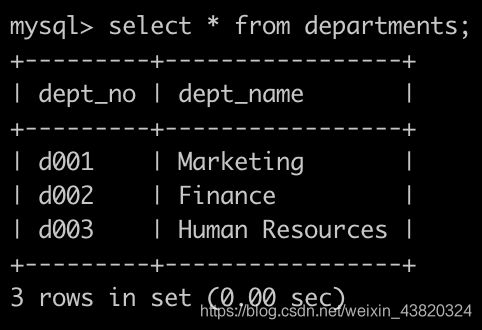
有一个,部门员工关系表dept_emp简况如下:

请你查找所有员工的last_name和first_name以及对应的dept_name,也包括暂时没有分配部门的员工,以上例子输出如下:

题解
select e.last_name, e.first_name, d.dept_name
from employees as e
left join dept_emp as de
on e.emp_no = de.emp_no
left join departments as d
on de.dept_no = d.dept_no
Day16、查找所有员工入职以来的薪水涨幅
有一个员工表employees简况如下:
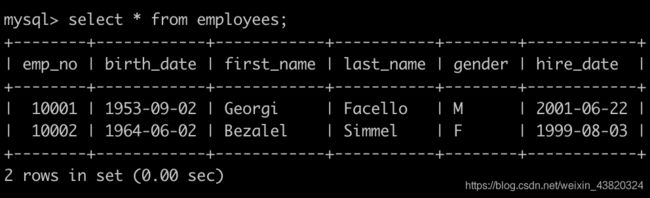
有一个薪水表salaries简况如下:

请你查找所有员工自入职以来的薪水涨幅情况,给出员工编号emp_no以及其对应的薪水涨幅growth,并按照growth进行升序,以上例子输出为
(注:可能有employees表和salaries表里存在记录的员工,有对应的员工编号和涨薪记录,但是已经离职了,离职的员工salaries表的最新的to_date!=‘9999-01-01’,这样的数据不显示在查找结果里面,以上emp_no为2的就是这样的)
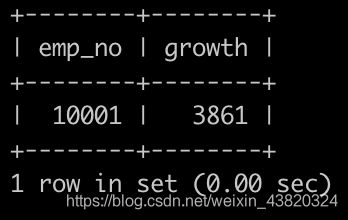
题解
/*
临时表a是员工入职时的薪水
临时表b是未离职员工当前的薪水
*/
select b.emp_no,(b.salary-a.salary) growth
from
(select s.emp_no,s.salary
from employees e,salaries s
where e.emp_no=s.emp_no
and e.hire_date=s.from_date) a,
(select emp_no,salary
from salaries
where to_date='9999-01-01') b
where b.emp_no=a.emp_no
order by growth
Day17、统计各部门的工资记录数
有一个部门表departments简况如下:
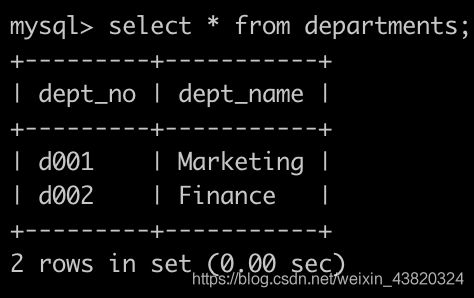
有一个,部门员工关系表dept_emp简况如下:
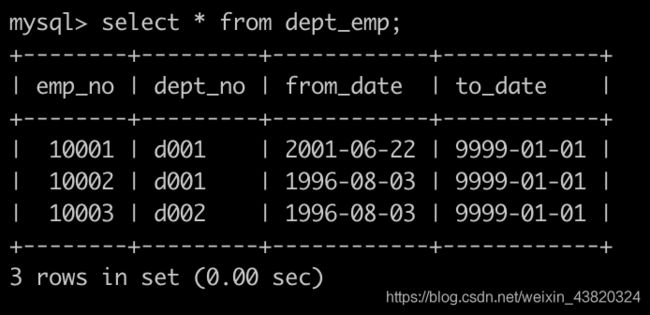
有一个薪水表salaries简况如下:

请你统计各个部门的工资记录数,给出部门编码dept_no、部门名称dept_name以及部门在salaries表里面有多少条记录sum,按照dept_no升序排序,以上例子输出如下: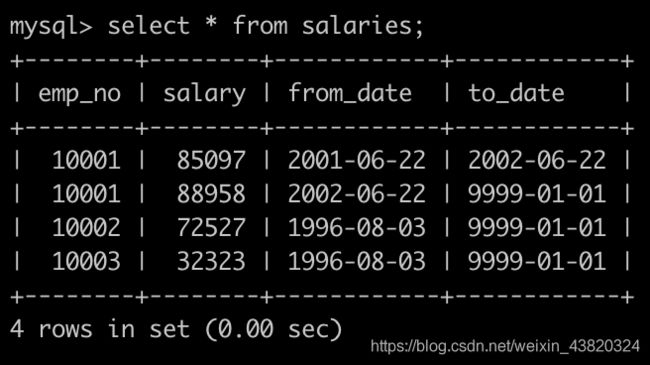
题解
SELECT de.dept_no, dp.dept_name, COUNT(s.salary) AS sum
FROM (dept_emp AS de INNER JOIN salaries AS s ON de.emp_no = s.emp_no)
INNER JOIN departments AS dp ON de.dept_no = dp.dept_no
GROUP BY de.dept_no
ORDER BY de.dept_no
Day18、对所有员工的薪水按照salary进行按照1-N排序
有一个薪水表salaries简况如下:
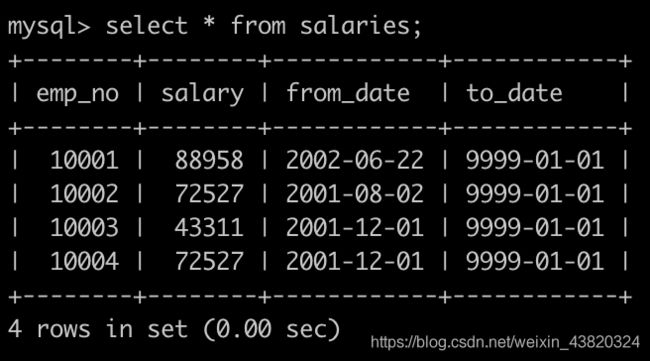
对所有员工的薪水按照salary进行按照1-N的排名,相同salary并列且按照emp_no升序排列:

题解
select emp_no,salary,dense_rank() over(order by salary desc)as rank
from salaries
order by rank,emp_no;
注
下面介绍三种用于进行排序的专用窗口函数:
1、RANK()
在计算排序时,若存在相同位次,会跳过之后的位次。
例如,有3条排在第1位时,排序为:1,1,1,4······
2、DENSE_RANK()
这就是题目中所用到的函数,在计算排序时,若存在相同位次,不会跳过之后的位次。
例如,有3条排在第1位时,排序为:1,1,1,2······
3、ROW_NUMBER()
这个函数赋予唯一的连续位次。
例如,有3条排在第1位时,排序为:1,2,3,4······
窗口函数用法:
<窗口函数> OVER ( [PARTITION BY <列清单> ]
ORDER BY <排序用列清单> )
其中[ ]中的内容可以忽略
Day19、获取所有非manager员工当前的薪水情况
有一个员工表employees简况如下:
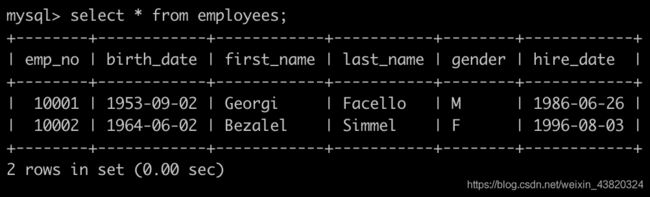
有一个,部门员工关系表dept_emp简况如下:

有一个部门经理表dept_manager简况如下:

有一个薪水表salaries简况如下:

获取所有非manager员工薪水情况,给出dept_no、emp_no以及salary,以上例子输出:

题解
select de.dept_no, de.emp_no, s.salary
from dept_emp de inner join employees e on de.emp_no = e.emp_no
inner join salaries s on de.emp_no = s.emp_no
where de.emp_no not in (select emp_no from dept_manager);
Day20、获取当前员工薪水比其经理还高的相关信息
有一个,部门关系表dept_emp简况如下:
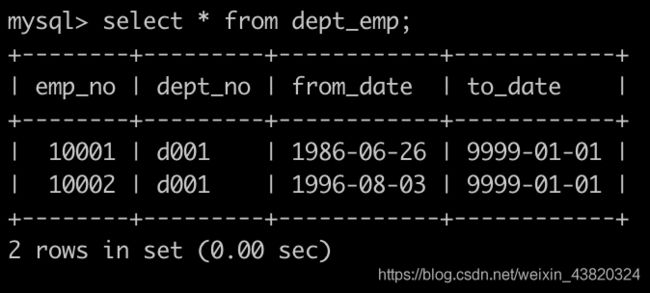
有一个部门经理表dept_manager简况如下:

有一个薪水表salaries简况如下:
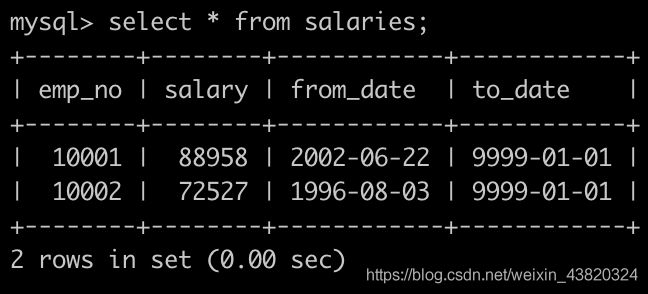
获取员工其当前的薪水比其manager当前薪水还高的相关信息,
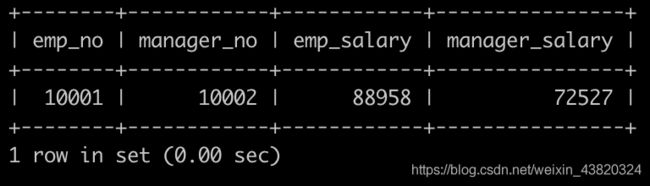
题解
select a.emp_no,b.emp_no,a.salary,b.salary
from
(select de.emp_no,sa.salary,de.dept_no
from dept_emp de,salaries sa
where de.emp_no = sa.emp_no) as a,
(select dm.emp_no,sal.salary,dm.dept_no
from dept_manager as dm,salaries as sal
where dm.emp_no = sal.emp_no) as b
where a.dept_no = b.dept_no and a.salary>b.salary
Day21、汇总各个部门当前员工的title类型的分配数目
有一个部门表departments简况如下:
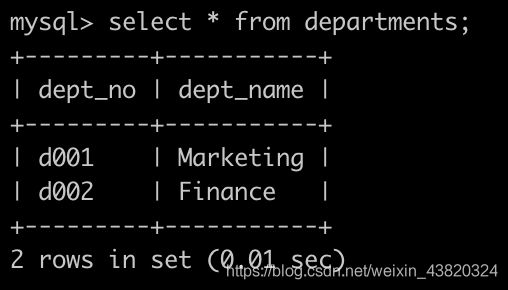
有一个,部门员工关系表dept_emp简况如下:
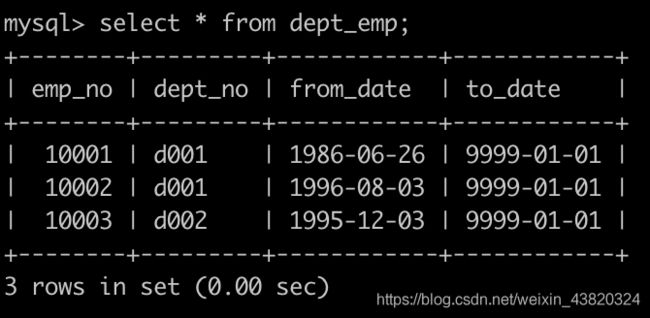
有一个职称表titles简况如下:

汇总各个部门当前员工的title类型的分配数目,即结果给出部门编号dept_no、dept_name、其部门下所有的员工的title以及该类型title对应的数目count,结果按照dept_no升序排序

题解
select de.dept_no, d.dept_name, title, count(de.emp_no) as count
from dept_emp de join titles t
on de.emp_no = t.emp_no
join departments d on de.dept_no = d.dept_no
group by de.dept_no, d.dept_name, title
order by de.dept_no;
Day22、牛客每个人最近的登录日期(一)
牛客每天有很多人登录,请你统计一下牛客每个用户最近登录是哪一天。有一个登录(login)记录表,简况如下:

请你写出一个sql语句查询每个用户最近一天登录的日子,并且按照user_id升序排序,上面的例子查询结果如下:
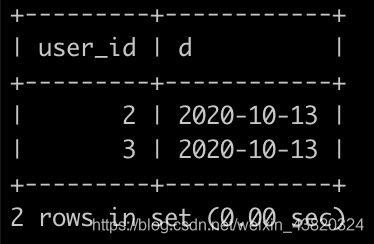
select user_id, max(date) as d
from login
group by user_id
order by user_id;
算法篇(暂时停止)
Day1、 重建二叉树
** 输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6},则重建二叉树并返回。**
示例:
输入
[1,2,3,4,5,6,7],[3,2,4,1,6,5,7]
输出
{1,2,5,3,4,6,7}
题解
JAVA
/**
* Definition for binary tree
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
public class Solution {
public TreeNode reConstructBinaryTree(int [] pre,int [] in) {
// 树为空或长度不等则返回空值
if(pre.length == 0 || in.length == 0 || pre.length != in.length) return null;
/*
根据前序、中序的特点,还原二叉树构造:
1. 前序的第一个值为根节点;
2. 找到后序中的该值(1中的)所在位置,从而分出左右子树;
3. 分别记录左右子树的长度,根据各自的长度从前序中截取新的子前序;
4. 重复1~3.
*/
// 前序第一个值为根节点,创建节点
TreeNode node = new TreeNode(pre[0]);
// 循环,开始重建二叉树
for(int i = 0; i < in.length; i++) {
// 根据(子)前序的首个为根,寻找在(子)中序中的位置
if(pre[0] == in[i]) {
// 左子树所在前、中序的范围:pre[1, i]、in[0, i-1]
node.left = reConstructBinaryTree(subArray(pre, 1, i), subArray(in, 0, i-1));
// 右子树所在前、中序的范围:pre[i+1, pre.len-1]、in[i+1, in.len-1]
node.right = reConstructBinaryTree(subArray(pre, i+1, pre.length-1), subArray(in, i+1, in.length-1));
}
}
return node;
}
int[] subArray(int[] arr, int start, int end) {
// 左\右子树的长度:end-start+1,之所以加1,因为有个根节点
int[] subTree = new int[end - start + 1];
for(int i=start; i <= end; i++) {
subTree[i-start] = arr[i];
}
return subTree;
}
}
Python
# -*- coding:utf-8 -*-
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
# 返回构造的TreeNode根节点
def reConstructBinaryTree(self, pre, tin):
# write code here
if(not pre): return None
# 创建Hash表,存放中序数组,便于分割
hashtable = {}
for i in range(len(tin)):
hashtable[tin[i]] = i
def recurGetRoot(root, left, right):
if left > right:
return
# (子)前序的根节点
node = TreeNode(pre[root])
# 根据前序的根节点,找出Hash表中根节点在中序的位置
i = hashtable[pre[root]]
# 递归分割左右子树
node.left = recurGetRoot(root + 1, left, i - 1)
node.right = recurGetRoot(root + 1 + i - left, i + 1, right)
# 返回最后的二叉树
return node
return recurGetRoot(0, 0, len(pre) - 1)
Day2、反转链表
输入一个链表,反转链表后,输出新链表的表头。
示例:
输入:
{1, 2, 3}
输出:
{3, 2, 1}
题解
JAVA
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode ReverseList(ListNode head) {
// 空链表直接返回
if(head == null || head.next == null) return head;
// 创建新链表头
ListNode result = null;
// 创建临时节点
ListNode temp = null;
while(head!= null){
// 令临时节点等于当前节点的下一个节点
temp = head.next;
// 令当前节点的下一个指向前
head.next = result;
// 将当前节点存给新表头
result = head;
// 当前节点移动到下一个
head = temp;
}
return result;
}
}
Python
# -*- coding:utf-8 -*-
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
# 返回ListNode
def ReverseList(self, pHead):
# write code here
if(pHead == None or pHead.next == None):
return pHead
# 前节点,当前节点
pre, cur = None, pHead
# 当前节点部位None,继续
while cur:
# 临时节点指向当前的下一个
tmp = cur.next
# 当前节点指向反转向前
cur.next = pre
# 赋值新链表
pre = cur
# 当前节点后移
cur = tmp
return pre
Day3、排序
给定一个数组,请你编写一个函数,返回该数组排序后的形式。
示例:
输入
[5,2,3,1,4]
输出
[1,2,3,4,5]
题解
JAVA
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
* 将给定数组排序
* @param arr int整型一维数组 待排序的数组
* @return int整型一维数组
*/
public int[] MySort (int[] arr) {
// write code here
/*
冒泡排序(稳定排序):
双重for循环: 外循环: 数组有几个值,就循环几次
内循环: 每次循环时,都将一个最值放到数组最后面(首次放最后的是最值,其次都是剩余元素中的最值)
时间复杂度:O(n^2);空间复杂度:O(1)。
因此提交可能不通过。
*/
/*
int temp;
for(int i=0; i < arr.length; i++){
for(int j=0; j arr[j+1]){ // 升序冒泡,则挑大的往后放
temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
*/
// ***********************************************************************************************
/*
选择排序(不稳定排序):
双重for循环:外循环:由于只需挑选出n-1个值,所以循环n-1次
内循环:利用minIndex,将数组中最值挑选出来赋值给arr[i],i随外循环增大
时间复杂度:O(n^2);空间复杂度:O(1)。
因此提交可能不通过。
*/
/*
int minIndex, temp;
for(int i=0; i
// ************************************************************************************************
/*
希尔排序:
插入排序中的一种,又称“缩小增量”排序,非稳定排序。
双重for加while循环组成:
1、外层for循环:定义增量,确定每次最外循环时的间隔步长
2、间隔步长,如长度为10的数组,第一次间隔步长为step=5,则使得第一次的内循环进行【第6(step+1)个
元素和第1(step+1-step)个元素比较,第7(step+2)个元素和第2(step+2-step)个元素比较,直
到最后】;第二次间隔步长为step=2.则第二次内循环进行【第3(step+1)个元素和第1(step+1-step)
个元素比较...】——————总得来说,就是间隔一个步长的两个元素依次比较。
3、while循环:内循环的每次进入while,为了将轮到的那个元素值进行比较交换,直至不满足while的条件。
以上以实际例子代入尝试,更加方便理解。
时间复杂度:O(nlogn);空间复杂度:O(1)
*/
int flag, current;
for(int step = arr.length/2; 0 < step; step = step/2){
for(int j = step; j<arr.length;j++){
flag = j;
current = arr[j];
while(flag - step >= 0 && current < arr[flag - step]){
arr[flag] = arr[flag - step];
flag = flag - step;
}
arr[flag] = current;
}
}
return arr;
}
}
本题主要是针对排序的各种算法,因此暂不做Python解。(2021-03-09)
各种排序算法的介绍和图解强烈推荐:排序算法时间复杂度、空间复杂度、稳定性比较
(PS:如若有时间,尝试使用通俗大白话唠叨出各种排序算法,方便简单理解)
Day4、链表的奇偶重排
给定一个单链表,请设定一个函数,将链表的奇数位节点和偶数位节点分别放在一起,重排后输出。
注意是节点的编号而非节点的数值。
示例:
输入:
{1,4,6,3,7}
输出:
{1,6,7,4,3}
题解
JAVA
import java.util.*;
/*
* public class ListNode {
* int val;
* ListNode next = null;
* }
*/
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
* @param head ListNode类
* @return ListNode类
*/
public ListNode oddEvenList (ListNode head) {
// write code here
// 链表本身为空或只有一个节点,直接返回
if(head == null || head.next ==null) return head;
// 创建奇偶子链表,最后用于返回的
ListNode oddHead = new ListNode(0);
ListNode evenHead = new ListNode(0);
// 操作过程中使用的游标
ListNode odd = oddHead;
ListNode even = evenHead;
// 用于将奇偶节点分开
while(head != null && head.next != null){ // 同时确定一对奇偶节点是否存在
odd.next = head;
even.next = head.next;
odd = odd.next; // 奇游标移动到奇链表最后一个
even = even.next; // 偶游标移动到偶链表最后一个
head = even.next; // head移动到下一对奇偶节点
}
// 若原链表长度为奇数,则特地将其放置在奇链表后面
if(head != null){
odd.next = head;
odd = odd.next;
}
// 将偶链表最后指向空
even.next = null;
// 将奇偶子链表串起来
odd.next = evenHead.next;
// 奇链表的首个为空,所以返回后一个
return oddHead.next;
}
}
Python
class Solution:
def oddEvenList(self , head ):
# write code here
if not head:
return head
odd = head
even_head = even = head.next
while odd.next and even.next:
odd.next = odd.next.next
even.next = even.next.next
odd, even = odd.next, even.next
odd.next = even_head
return head
Day5、最小的K个数
给定一个数组,找出其中最小的K个数。例如数组元素是4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4。如果K>数组的长度,那么返回一个空的数组
示例:
输入:
[4,5,1,6,2,7,3,8],4
输出:
[1,2,3,4]
题解
JAVA
import java.util.ArrayList;
public class Solution {
public ArrayList<Integer> GetLeastNumbers_Solution(int [] input, int k) {
ArrayList<Integer> res = new ArrayList<>(); // 创建需返回的数组
// 输入数组为空或k大于数组长度
if (input == null || input.length == 0 || k > input.length || k == 0)
return res;
sort(input); // 对input进行排序
for(int i=0; i<k; i++){
res.add(input[i]); // 挑出前k个长度
}
return res;
}
public void sort(int[] input){
/*
通过堆排序的方法,分为两个步骤:
1、第一个for循环:对input数组进行一次找最大根,即将数组中最大值排到最前面;
2、第二个for循环:将此时数组最前面的最大值,与此时数组最后的值进行交换;
将数组长度减一,调用第一个for循环。
*/
if (input == null || input.length == 0 || input.length == 1)
return;
// 第一个for循环:实质是,从下至上,从右至左,一次循环就调整一个最小的子树(只有左右根三个)
for(int i=input.length/2-1; i>=0; i--){
adjustHeap(input, i, input.length);
}
// 第二个for循环:先将上次“第一个for循环”结果中最大值(在第一个)与最后一个调换位置;
// 数组长度减一进入“第一个for循环”,意味对数组剩下的再找最大根。
for(int j=input.length-1; j>0; j--){
swap(input, 0, j); // 0位置意味最大值,j位置意味最后一个值
adjustHeap(input, 0, j); // 对长度减一的数组进行最大根查找调整
}
}
public void adjustHeap(int[] input, int i, int length){
int temp = input[i]; // 将此时最小子树的根,其值存储一下
for(int n=2*i+1; n<length; n = 2*n+1){ // 最小子树的左节点位置就是n=2*i+1
if(n+1<length && input[n]<input[n+1]){ // 找左右节点值更大的那个,令n为它的位置
n++; // 若右节点大,则n+1;若左节点大,则不变
}
if(input[n]>temp){ // 比较(左/右)节点与根哪个更大,令根的值为最小子树中最大
input[i] = input[n]; // 节点值更大,则赋给根位置
i = n; // 调换位置,为了将节点的值换为之前根的值
}else{
break; // 比较后,发现还是根最大,所以退出此次循环
}
}
input[i] = temp;
// 将temp/root放到属于它的地方,令最后的root为最大值,如:[(root)4(temp), (left)5, (right)6]
// ——>[(root)6, (left)5, (right)4(temp)];或[(root)9(temp), (left)6, (right)3]——>不变
}
public void swap(int[] input, int a, int b){
int tmp = input[a];
input[a] = input[b];
input[b] = tmp;
}
}
【注:本题有许多解法,特地记录堆排序法,通过手动实现大根堆的方式排序。推荐阅读:图解排序算法(三)之堆排序】
Python
class Solution:
def GetLeastNumbers_Solution(self, tinput, k):
if k > len(tinput):
return []
tinput.sort()
return tinput[:k]
【注:sort方法对数组排序,返回k个即可,或heapify方法等排序。故不多做记录】
Day6、跳台阶
一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法(先后次序不同算不同的结果)。
示例:
输入:
4
输出:
5
题解
JAVA
/*
方法一:递归
假设f[i]表示在第i个台阶上可能的方法数。逆向思维。如果我从第n个台阶进行下台阶,下一步有2
中可能,一种走到第n-1个台阶,一种是走到第n-2个台阶。所以f[n] = f[n-1] + f[n-2]。(即
从台阶5往下走,可以走到4、或者直接走到3,接着台阶4或3继续往下走各有...种方法,递归相加)
*/
// 时间复杂度:O(2^n) 249ms;空间复杂度:O(n) 9720KB
public class Solution {
public int jumpFloor(int target) {
if(target == 1 || target == 2 || target == 3)
return target;
return jumpFloor(target-1) + jumpFloor(target-2);
}
}
/*
方法二:动态规划
*/
// 时间复杂度:O(n) 12ms; 空间复杂度:O(1) 9712KB
public class Solution {
public int jumpFloor(int target) {
int[] dp = new int[target+1];
dp[0] = dp[1] = 1;
if(target == 1 || target == 2 || target == 3)
return target;
for(int i=2; i<=target; ++i){
dp[i] = dp[i-1] + dp[i-2];
}
return dp[target];
}
}
/*
方法三:
简单来说,台阶数为2或3时,就为2或3种跳法,则将target往下减1或2,拆成尾端为2或3
如: 5
4 *3* ==> 2 + 3 + 3 = 8 种
*2* *3
*/
public class Solution {
public int jumpFloor(int target) {
if(target < 4) return target;
int a = 3;
int b = 2;
for(int i = 4; i <= target; i++) {
a = a + b;
b = a - b;
}
return a;
}
}
Python
class Solution:
def jumpFloor(self, number):
# write code here
if(number<4): return number
a = 3
b = 2
for i in range(4, number+1):
a = a + b
b = a - b
return a
Day7、合并区间
给出一组区间,请合并所有重叠的区间。
示例:
输入:
[[10,30],[20,60],[80,100],[150,180]]
输出:
[[10,60],[80,100],[150,180]]
题解
JAVA
/**
* Definition for an interval.
* public class Interval {
* int start;
* int end;
* Interval() { start = 0; end = 0; }
* Interval(int s, int e) { start = s; end = e; }
* }
*/
import java.util.*;
public class Solution {
public ArrayList<Interval> merge(ArrayList<Interval> intervals) {
intervals.sort((a, b) -> (a.start - b.start));//按照区间的左端点排序
ArrayList<Interval> res = new ArrayList<Interval>();
int i = 0,n = intervals.size();
int l,r;
while(i < n){
l = intervals.get(i).start;//用来存储当前区间的左端
r = intervals.get(i).end;//用来存储当前区间的右端
//合并区间
while(i < n-1 && r >= intervals.get(i + 1).start){
i ++;
r = Math.max(r,intervals.get(i).end);
}
//将当前合并完的区间进行插入
res.add(new Interval(l, r));
i ++;
}
return res;
}
}
Python
class Solution:
def merge(self , intervals ):
# write code here
intervals.sort(key=lambda x:x.start)
merged=[]
for i in intervals:
if not merged or merged[-1].end<i.start:
merged.append(i)
elif merged[-1].end <i.end:
merged[-1].end=i.end
return merged

Day8、股票(无限次交易)
假定你知道某只股票每一天价格的变动。
你最多可以同时持有一只股票。但你可以无限次的交易(买进和卖出均无手续费)。
请设计一个函数,计算你所能获得的最大收益。
示例:
输入:
[1, 3, 5, 2, 4]
输出:
6
题解
JAVA
import java.util.*;
public class Solution {
public int maxProfit (int[] prices) {
// write code here
// 判断若当天和前一天的收益为正,将差值加入收益
int profit = 0;
for(int i=1; i < prices.length; i++){
if((prices[i] - prices[i-1]) > 0){
profit += prices[i] - prices[i-1];
}
}
return profit;
}
}
Python
class Solution:
def maxProfit(self , prices ):
# write code here
profit = 0
for i in range(1, len(prices)):
if(prices[i] - prices[i-1] > 0):
profit += prices[i] - prices[i-1]
return profit
判断若当天和前一天的收益为正,将差值加入收益
Day9、通配符匹配
请实现支持’?‘and’*’.的通配符模式匹配
'?' 可以匹配任何单个字符。
'*' 可以匹配任何字符序列(包括空序列)。
**返回两个字符串是否匹配
函数声明为:
bool isMatch(const char s, const char p)
下面给出一些样例:
isMatch("aa","a") → false
isMatch("aa","aa") → true
isMatch("aaa","aa") → false
isMatch("aa", "*") → true
isMatch("aa", "a*") → true
isMatch("abcdefg", "a?*f?") → true
isMatch("aab", "d*a*b") → false
题解
JAVA
public class Solution {
public boolean isMatch(String s, String p) {
if(s==null || p==null) return false;
int m = s.length();
int n = p.length();
int i = 0, j = 0, backI = -1, backJ = -1;
while(i < m){
// 判断当前位置的字符,是否相等或是否为‘?’
if(j < n && (s.charAt(i) == p.charAt(j) || p.charAt(j) == '?')){
i++;
j++; // 相等则都向后移一位
} else if(j < n && p.charAt(j) == '*'){ // // 若当前是‘*’,则j就会移动
backI = i;
backJ = j++; // 将当前位置记录下,但j向后移一位
} else if(backJ != -1){ // 意味着,正在匹配s中有几个与‘*’能匹配上
i = backI + 1; // 通过backI来移动i所指向的位置,寻找有几个
backI = i; // 更新backI
j = backJ + 1; // backJ记录着最新的‘*’所在的位置
} else {
return false; // 没有‘*’、‘?’,字符也不匹配
}
}
while(j < n && p.charAt(j) == '*') j++; // 此行是当m
// 若p字符串没查看完,后面剩下的除了‘*’还有其他,则说明不匹配
return j == n; // 证明p字符串都查看完了,都匹配上了
}
}
Python
class Solution:
def isMatch(self , s , p ):
# write code here
# 同样判断4种情况
# 1. p[j]=='?' || s[i]==p[j] 那么 i++; j++
# 2. p[j]== '*' 那么 ri = i ; rj = j; j++;
# 3. rj > -1 那么 i = ++ri; j = rj +1;
# 4. 其余情况 return false;'''
i = j = 0
m, n = len(s), len(p)
back_i = -1
back_j = -1
while i < m:
if j < n and (p[j] == '?' or s[i] == p[j]):
i += 1
j += 1
elif j < n and p[j] == '*':
back_i = i
back_j = j
j += 1
elif back_j != -1:
j = back_j + 1
i = back_i + 1
back_i = i
else:
return False
# 若字符串遍历完之后pattern还未匹配完,继续检查剩余部分
while j < n and p[j] == '*':
j += 1
return j == n
Day10、买卖股票的最好时机
假设你有一个数组,其中第 i 个元素是股票在第 i 天的价格。
你有一次买入和卖出的机会。(只有买入了股票以后才能卖出)。请你设计一个算法来计算可以获得的最大收益。
示例:
输入:
[1,4,2]
输出:
3
题解
JAVA
import java.util.*;
public class Solution {
public int maxProfit (int[] prices) {
// write code here
if(prices == null || prices.length == 1) return 0;
int max = 0;
int min = prices[0];
for(int i = 0; i < prices.length; i++){
// 贪心算法,从左往右遍历向量,遇到当前最小值,则保存
min = Math.min(min, prices[i]);
// 对于不是最小值,则计算它到最小值的距离,保存为最大利润
max = Math.max(max, prices[i]-min);
}
return max;
}
}
Python
class Solution:
def maxProfit(self , prices ):
# write code here
min_price = prices[0]
max_price = 0
for i in (prices):
min_price = min(i, min_price)
max_price = max(max_price, i-min_price)
return max_price
Day11、最长递增子序列
给定数组arr,设长度为n,输出arr的最长递增子序列。(如果有多个答案,请输出其中字典序最小的)
示例:
输入:
[2,1,5,3,6,4,8,9,7]
输出:
[1,3,4,8,9]
输入:
[2, 3, 5, 4]
输出:
[2, 3, 4]
题解
JAVA
import java.util.*;
public class Solution {
/**
* retrun the longest increasing subsequence
* @param arr int整型一维数组 the array
* @return int整型一维数组
*/
public int[] LIS (int[] arr) {
// write code here
if(arr == null || arr.length <= 1) return arr;
int n = arr.length;
// end数组用于存放当前元素的最长的递增子序列结果
// 最后的end的值就是[0, 当前元素最长子序列]
int[] end = new int[n+1];
// dp数组用于存放当前元素的与每个元素的递增的长度,如:
// arr=[2,3,5,4],当前元素为2时,dp=[1,2,3,3]
// 即当前元素2,分别与2,3,5,4的递增长度为1,2,3,4
int[] dp = new int[n];
// len总是为end数组服务,定位于end数组最后一位
int len = 1;
end[1] = arr[0];
dp[0] = 1;
for(int i = 0; i < n; i++){
if(end[len] < arr[i]){
end[++len] = arr[i];
dp[i] = len;
}else{
// 此else里的一切,是二分法查找
// 为了寻找end数组里,第一个比当前元素大的值的下标
int l = 0, r = len;
while(l <= r){
int mid = (l + r) >> 1;
if(end[mid] >= arr[i]){
r = mid - 1;
}else l = mid + 1;
}
// 将当前元素按照最小递增幅度添加到end数组最后,如:
// 本来是end=[2,5,9],若当前元素为7,则end=[2,5,7]
// 若当前元素为4,则end=[2,4]
end[l] = arr[i];
dp[i] = l;
}
}
// 通过dp数组的值与len比较,将最后结果输出
// len记录的是最长的长度,dp的值是每位元素能代表的最长的长度
// 如:[2, 1, 3, 5, 4, 6, 8, 9, 7]
// len=6, [2,3,5,6,8,9]、[1,3,5,6,8,9]...等等,反正最长只有6
// dp =[1, 1, 2, 3, 3, 4, 5, 6, 5]
int[] res = new int[len];
for(int j = n - 1; j >= 0; j--){
// dp数组逆序查找,该元素长度不能等于当前len长度,说明不是最长子序列的末值
if(dp[j] == len){
// j和len都会减一,这样就能向前查找
res[--len] = arr[j];
}
}
return res;
}
}
前端篇(暂时停止)
Day1、修改this指向
封装函数 f,使 f 的 this 指向指定的对象
示例:无
题解
JavaScript
function bindThis(f, oTarget) {
return function(){
return f.apply(oTarget, arguments);
}
}
知识点:this指向、arguments类数组对象、柯里化;call、apply、bind 都是改变上下文的,但是call apply是立即执行的,而bind是返回一个改变上下文的函数副本。
Day2、Dom节点查找
查找两个节点的最近的一个共同父节点,可以包括节点自身:oNode1 和 oNode2 在同一文档中,且不会为相同的节点
示例:无
题解
JavaScript
function commonParentNode(oNode1, oNode2) {
while(true){
oNode1 = oNode1.parentNode
if(oNode1.contains(oNode2)){
return oNode1;
break;
}
}
}
不用管谁包含谁,只要随便找一个节点,直到某个祖先节点(或自己)包含另一个节点就行了
Day3、根据包名,在指定空间中创建对象
示例:
输入:
namespace({a: {test: 1, b: 2}}, 'a.b.c.d')
输出:
{a: {test: 1, b: {c: {d: {}}}}}
题解
JavaScript
function namespace(oNamespace, sPackage) {
var list = sPackage.split('.');
var tmp = oNamespace;
for (var k in list) {
if (typeof tmp[list[k]] !== 'object') {
tmp[list[k]] = {};
}
tmp = tmp[list[k]];
}
return oNamespace;
};
Day4、判断是否以元音字母结尾
给定字符串 str,检查其是否以元音字母结尾
1、元音字母包括 a,e,i,o,u,以及对应的大写
2、包含返回 true,否则返回 false
示例:
输入:
'gorilla'
输出:
true
题解
JavaScript
/*
function endsWithVowel(str) {
var arr = ['a','e','i','o','u','A','E','I','O','U'];
return arr.includes(str[str.length-1]) // includes() 方法用于判断字符串是否包含指定的子字符串
}
*/
/*
function endsWithVowel(str) {
return ("aeiouAEIOU".indexOf(str[str.length-1])!=-1) // indexOf()返回某个指定的字符串值在字符串中首次出现的位置
}
*/
function endsWithVowel(str) {
// 正则化方式
var reg = /(a|o|e|i|u)$/gi; // $ 规定匹配模式必须出现在目标字符串的结尾
// /g是全局匹配模式; i是不区分大小写
return reg.test(str);
}
Day5、获取url参数
获取 url 中的参数
- 指定参数名称,返回该参数的值 或者 空字符串
- 不指定参数名称,返回全部的参数对象 或者 {}
- 如果存在多个同名参数,则返回数组
示例:
输入:
http://www.nowcoder.com?key=1&key=2&key=3&test=4#hehe key
输出:
[1, 2, 3]
题解
function getUrlParam(sUrl, sKey) {
// url = http://www.nowcoder.com?key=1&key=2&key=3&test=4#hehe
var paramsN = sUrl.split("?")[1]; // 取出url后的字符串, key=1&key=2&key=3&test=4#hehe
var params = paramsN.split("#")[0]; // 剔除字符串#后的, key=1&key=2&key=3&test=4
var param = params.split("&"); // 将字符串分割为键值对数组, ['key=1','key=2','key=3','test=4']
var arr = []; // 用于返回结果的数组
if(sKey){ //如果有参数
for(var i = 0;i<param.length;i++){ // 遍历键值对数组, 有4对
var keyV = param[i].split("="); // 分开键和值, keyV=['key', '1'] ... ['test', '4']
if(keyV[0] === sKey){ // 如果有和传入的参数一样的键,则将其值插入到空数组中
arr.push(keyV[1]);
}
}
if(arr.length === 0){ // 如果数组仍为空,则证明没有传入的参数的值
return "";
}else if(arr.length > 1){ // 有多个值
return arr;
}else{//只有一个值
return arr[0];
}
}else{//没有传入参数,返回对象
var obj = {};
for(var i = 0;i<param.length;i++){ // 遍历
var keyV = param[i].split("="); // 分开键和值
if(obj[keyV[0]]){ // 如果对象中有该属性
obj[keyV[0]].push(keyV[1]) // 插入该属性中的数组中
}else{
obj[keyV[0]] = [keyV[1]] // 如果没有则创建一个数组并且把值放入该数组中
}
}
for(var key in obj){ // 遍历插入数据的对象
if(obj[key].length === 1){ // 如果该对象的属性值的数组的长度为一
obj[key] = obj[key][0] // 则让该对象的该属性值为数组里的值
}
}
return obj;
}
}
Day6、数组去重
为 Array 对象添加一个去除重复项的方法
题解
示例:
输入:
[false, true, undefined, null, NaN, 0, 1, {}, {}, 'a', 'a', NaN]
输出:
[false, true, undefined, null, NaN, 0, 1, {}, {}, 'a']
JavaScript
Array.prototype.uniq = function () {
return [...(new Set(this))];
}
/*
Array.prototype.uniq = function () {
return Array.from(new Set(this));
}
*/
/*
Array.prototype.uniq = function () {
var args = this;
var len = args.length;
var result = [];
var flag = true;
for (var i = 0; i < len; i++) {
//NaN不等于任何,包括他自身,所以args.indexOf(args[i])遇到NaN永远返回-1
if (args.indexOf(args[i]) != -1) {
if (i === args.indexOf(args[i])) {
result.push(args[i]);
}
} else if (flag) {
result.push(args[i]);
flag = false;
}
}
return result
}
*/
Day7、斐波那契数列
用 JavaScript 实现斐波那契数列函数,返回第n个斐波那契数。 f(1) = 1, f(2) = 1 等
题解
function fibonacci(n) {
var n1 = 1, n2 = 1, sum;
for (let i = 2; i < n; i++) {
sum = n1 + n2
n1 = n2
n2 = sum
}
return sum
}
推荐:JS写斐波那契数列的几种方法