JuiceFS 支持多种元数据存储引擎,且各引擎内部的数据管理格式各有不同。为了便于管理,JuiceFS 自 0.15.2 版本提供了 dump 命令允许将所有元数据以统一格式写入到 JSON 文件进行备份。同时,JuiceFS 也提供了 load 命令,允许将备份恢复或迁移到任意元数据存储引擎。命令的详细信息可以参考这里。基本用法:
$ juicefs dump redis://192.168.1.6:6379/1 meta.json
$ juicefs load redis://192.168.1.6:6379/2 meta.json该功能自 0.15.2 版本发布后到现在 v1.0 RC2 经历了 3 次比较大的优化,性能得到了几十倍的提升, 我们主要在以下三个方向做了优化:
- 减小数据处理的的粒度:通过将大对象拆分为小对象处理,可以大幅减少内存的占用。另外拆分还有利于做细粒度的并发处理。
- 减少 io 的操作次数:使用 pipline 来批量发送请求减少网络 io 的耗时。
- 分析系统中的耗时瓶颈:串行改为并行,提高 cpu 利用率。
这些优化思路比较典型,对于类似网络请求比较多的场景具有一定的通用性,所以我们希望分享下我们的具体实践,希望能给大家一定的启发。
元数据格式
在分享 dump load 功能之前,我们先看下文件系统长什么样,如下图所示,文件系统是一个树形结构,顶层根目录,根目录下有子目录或者文件,子目录下面又有子目录或者文件。所以如果想要知道文件系统里面的所有文件和文件夹,只需要遍历这颗树就行了。
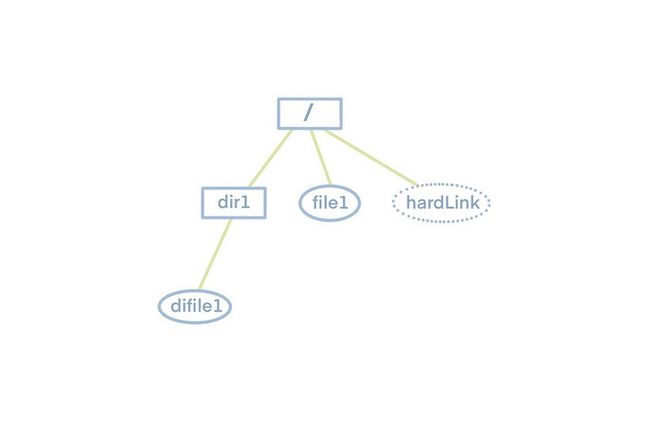
了解了文件系统的特点后,我们再看 JuiceFS 的元数据存储的特点,JuiceFS 元数据的存储主要是几张不同的 hash 表,每个 hash 表的 key 都是单个文件的 inode ,而inode 信息可以通过文件树的遍历得到。所以只需要遍历文件树拿到所有的inode,再根据 inode 为索引就可以拿到所有的元数据了。另外为了阅读性更好,并且保留原本的文件系统的树形结构,我们将导出的格式定为了 json。
将上面示例文件系统 dump 出来的 json 文件如下所示,其中 hardLink 为 file 的硬链接
json 内容:

Dump优化流程
dump 如何实现?
首先从元数据的格式来看,所有的元数据都是以inode为部分变量的为 key,也就是说我们知道了 inode 的具体值就可以通过 redis 获取到它的所有元数据信息。所以根据文件系统的特点,我们可以构建一棵FSTree,从根目录以深度优先遍历扫描填充这颗树,先扫描根目录(inode 为 1)下的所有entry,依次遍历,根据其 inode 获取其元数据信息,如果发现其是目录,就递归扫描,否则就分别请求 redis 拿其各个维度的元数据,拼装成一个 entry 的结构,作为父目录的 entry list 中的一员。当递归遍历完成后,这棵FSTree就已经建立完毕。我们再加上setting 等相对静态的元数据作为一个对象,然后将其整个序列化为 json 字符串。最后将 json 字符串写入到文件中,整个 dump 就算完成了。
性能
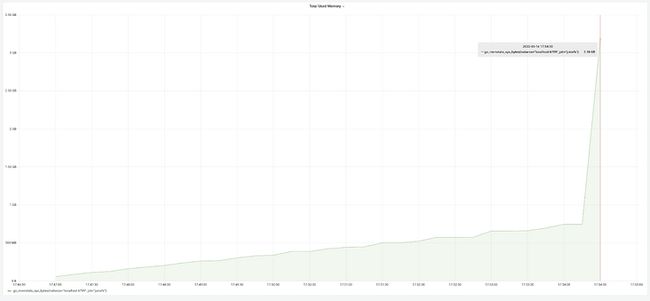
我们以包含110 万文件元数据的 redis 为例进行测试,测试结果为 dump 过程耗时 7 分 47 秒,内存占用为 3.18G。(为了保证测试结果的可比性,本文的所有测试都是使用同一份元数据)
下图为执行中的内存占用变化。内存占用刚开始缓慢上升,此时是在将深度优先遍历的过程中每扫描到一个 entry 就会将其存入内存中,所以内存缓慢增加。当构造完整个 FSTree 对象后开始进行 json 序列化,此时是 FSTree 对象大约 750M,将一个对象序列化为 json 字符串,过程大约需要 2 倍的对象大小,最后的 json 字符串大约等于一倍原始对象的大小,所以内存大约增加了 3 倍的 FSTree 对象的大小,急速攀升到 3.18G。最终内存占用峰值大约需要 4 倍的 FSTree 的大小。
上面的实现会什么问题?
根据上面的思路我们可以看出我们的核心是为了构建一个 FSTree 对象,因为 json 的序列化方法可以直接将一个对象序列化为j son 格式的字符串。所以一旦我们构建出来了 FSTree 对象,剩余的事情就可以交给 json 包来做了,非常方便。可是对于一个文件系统来说,文件可能非常多,非常大,带来的是元数据非常大,而 FSTree 保存的就是整个整个系统的entry 的元数据信息,所以dump 的进程占用内存就会比较高,另外在将对象序列化为 json 字符串后,这个 json 字符串也会非常大,其实相当于 dump 进程需要至少 2 倍的元数据的大小。如果 dump 进程所在的客户端可能并没有这么大的内存可以使用,那么 dump 进程可能会被操作系统因为 OOM 杀掉。
如何优化内存占用过高?
FSTree 由 很多个 Entry 组成,非常大,我们不能对其整个序列化,怎么办,我们可以减小数据处理的的粒度,将大对象拆分为小对象处理,分别对组成 FSTree 的 entry 进行序列化,将得到的 json 字符串写入到 json的文件末尾。具体做法就是深度优先递归扫描 FSTree,然后如果是个 entry,就将其序列化并且写入到 json 文件内,如果是个文件夹,那么就递归进去。这样得到的 json 文件中的 FSTree 仍旧是与 FSTree 对象保持一一对应的,entry 的树形结构与顺序并没有被破坏。这样我们 dump 内存中就只保留了一倍元数据大小的对象——FSTree,相比最开始节省了一半的内存,效果很明显。那剩下的这一倍内存可以省掉吗?答案是可以的,我们回想下 FSTree 是如何被构建的,是通过深度优先递归扫描根目录,所以 entry 是按照深度优先递归遍历的顺序被创建,深度优先递归遍历的顺序不也是我们序列化 FSTree 中每个 entry 的顺序吗?既然这两者顺序一致,那我们就可以在刚构建出 entry 的时候就将其序列化写入到 json 文件,这样遍历完整个文件系统的时候,所有的 entry 也被序列化完了,也就没有必要构建保存整棵 FSTree 了,最终优化的结果就是 FSTree 对象我们也不用构建了,每个 entry 只会被访问一遍,序列化后就扔掉它。这样占用的内存就是更少了。
性能
经过内存优化后的测试结果为 dump 过程耗时 8 分钟,内存占用为 62M。耗时相当,内存由 3.18G降低到62M,内存优化效果高达 5100%!
下图为内存变化占用情况

怎么优化dump 耗时太长?
从上面的测试结果来看,一百万 dump 大约需要 8 分钟,如果 1 亿文件就是 13 个小时之久,可见如果数据量太大,耗时就非常长。这么长的时间,生产上是不能被接受的。内存不够尚且可以通过钞能力解决,但是太耗时的话,钞能力也效果不大,所以根治还是要从内部程序来优化。我们先分析一下现在的耗费最多的环节是什么。
一般耗时分两个方面,大量的计算操作,大量的 io 操作,很明显我们属于大量的网络 IO 操作,dump 进程每扫描到一个 entry就需要请求其元数据信息,每次请求耗时由 RTT(Round Trip Time)+命令计算时间组成,redis 基于内存操作计算时间是非常快的,所以主要耗时是 RTT 上。N 个 entry 就是 N 个 RTT,耗时非常多。
如何减少RTT 的次数那?答案是使用 redis 的 pipline 技术,pipline 的基本原理就是将N个命令一次性发送过去,redis计算完 N 个命令后将结果按照顺序打包一次性返回给客户端,所以 N 个命令的耗时为 1 个RTT 加 N 条命令计算时间。从实践来看,pipline 的优化是非常可观的。顺着这个思路,我们可以使用 pipline 将存在 redis 中的元数据全部拿到内存中存起来,类似在内存中做个 redis的快照,代码上实现就是将其放入map 里面,原逻辑需要请求 redis 的现在直接从map中拿到。这样即用了 pipline 批量拉取数据减少了 RTT,原本的逻辑又不需要改变太多,只需要把 redis 请求操作改为读 map 即可。

性能
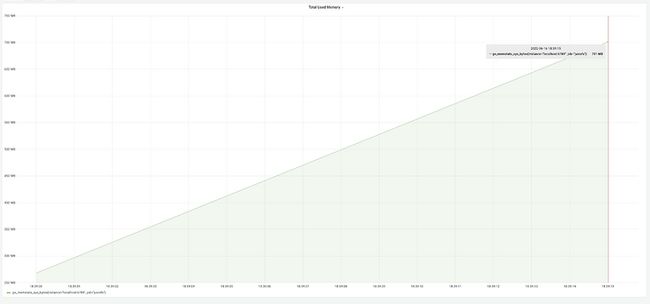
经过“快照”方式优化后的 dump 性能测试结果:耗时 35 秒,内存占用 700M,耗时从 8 分钟减少到 35 秒,提升高达 1270%,但是内存占用却因为我们在内存中构造了元数据缓存而增加到了 700M,从上面的测试可知这大约是一倍的元数据大小,这也符合预期。
低内存与低耗时能否兼得?
在内存中做 redis 的快照版本虽然速度快了很多,但是我们相当于把 redis 的数据全部放到了内存中,这样内存占用又回到到了一倍的元数据大小。当元数据太大的时候,dump 占用内存非常高。所以针对耗时的优化是牺牲了内存为代价的。一倍的内存占用与耗时长对于生产都是不可接受的,所以我们需要一个鱼和熊掌兼得的优化方法。我们回想之前的两次优化,针对内存占用高使用流式写入解决,针对耗时长通过使用 redis pipline 减少 RTT 次数解决。这两个优化手段都是必须的,关键在于如何将两者结合起来一起使用。
我们可以在针对优化内存占用过高做的流式写入这版上思考如何加上 pipline。流式写入版本其实可以看着是一个流水线处理,源端负责按照顺序构造 entry,接收端负责按照顺序序列化 entry,entry 的顺序就是 FSTree 的深度优先遍历的顺序。要使用 pipline,就必须走批量处理,那么我们可以逻辑上将 entry 按照顺序划分为多个批次,每个批次长度 100,将流水线的处理逻辑单元变成一个批次,这样流程变为:
- 当源端处理完 1个批次后通知接收端开始序列化这个批次
- 接收端序列化完这 1 个批次后再通知源端构造下一个批次
- 以此反复到结束
每一个批次都通过 pipline 来加速获取结果,这样就做到了pipline 与流式写入共存了。
关于内存的优化已经结束了,那关于耗时还能再优化吗?我们分析现在的流水线的运行情况,当源端发送 pipline 请求元数据时,此时接收端在做什么?在无事可做,因为没有数据可以序列化,那么当接收端在序列化的时候源端在做什么,也是无事可做。所以其实流水线是走走停停的,这样的是串行计算。如果将这两者并行,提高 cpu 利用率,速度就可以进一步提升。接下来我们思考怎么才能让源端与序列化端并行?同一个批次数据产生与处理肯定是无法并行的,能并行的只能是未请求回来元数据的的批次与待序列化的批次。也就是说源端不用等等序列化端是否处理完毕了,源端只管开足马力拿数据就好了,拿到的数据按照顺序放入到流水线上,序列化端按照顺序序列化,如果发现某个批次还没拿到,就等源端告诉自己这个批次ready 了再处理。同时考虑到构造批次的速度慢于序列化批次的时间,所以我们还可以给源端加上并发。源端同时序列化多个批次来减少序列化端的等待时间。
我们可以看着下图,模拟一下流程,假设我们当前源端并发度为 2,那么首先 1 号协程 2 号协程会同时分别构建批次 1,批次 2,而序列化端与在等待批次 1 是否构造完毕,一旦 1 号协程构造完毕批次 1 就会通知序列化端端开始依次序列化批次 1。当批次 1序列化完毕时,序列化端会通知 1 号协程构造批次 3(因为批次 2,批次 4 是该协程 2 处理的,每个协程按照一定规则分配批次序列化端才可以按照规则反过来推算出该通知哪个协程开始构造下一个批次),通知完 1 协程后就会开始序列化批次 2(先检查批次 2 是否 ready,如果没 ready 就等协程 2 通知ready,一般来讲此时批次 2 已经 ready 了),序列化完批次 2 就通知协程 2 开始构造批次 4以此类推。这样就做到了序列化端在序列化 entry 时源端在并行的处理 entry 以便跟上序列化的速度。

上面的逻辑步骤在树形的文件系统上执行的真实的过程如下图所示

性能
经过“鱼和熊掌”兼得的优化方式后测试性能,耗时为 19 秒,内存占用 75M,都达到了各自优化时的最佳效果。真正做到了“两个都要”。

Load 优化流程
load如何做
与 dump 相比,load 逻辑相对简单,最直接的方法,我们将 json 文件内容全部读入内存,然后反序列化到 FSTree 的对象上,深度优先遍历 FSTree 树,然后把每个 entry 的各个维度的元数据分别插入到 redis 中。但是如果这么做就会存在一个问题,以上面的示例 json 文件内容的文件树为例,在 dump 这个文件系统的时候存在某种情况,此时 file1 已经扫描到,redis 返回 file1的 nlink 为 2(因为 hardLink 硬链接到了 file1),此时用户删除了 hardLink ,file1 的 nlink 在 redis 中被修改为了 1,但是因为其在 dump 中已经被扫描过了,所以最终 dump 出来的 json 文件中 nlink 仍旧为 2,导致 nlink 错误,nlink 对于文件系统来说非常重要,其值的错误会导致删不掉或者丢数据等问题,所以这种会导致 nlink 错误的方式不太行。
为了解决这个问题,我们需要在 load 的时候重新计算 nlink 值,这就需要我们再 load 前记录下所有的inode 信息,所以我们在内存中构建了一个 map,key 为 inode,value 为 entry 的所有元数据,在遍历 entry 树的时候将所有扫描到的文件类型的 entry 放入 map 中而不是直接插入 redis,每次放入 map 前判断这个 inode 是否已经存在,如果存在意味着是这是一个硬链接,需要将这个 inode 的 nlink++。同样的情况也可能出现在子目录上,所以需要在遍历到子目录的时候将父目录的 nlink++。遍历完 entry 后nlink 也就全部重新计算完毕了。此时遍历 entry map,将所有的 entry 的元数据插入到 redis 中即可。当然为了加快插入速度,我们需要使用 pipline 的方式插入。
性能
按照上面的思路的代码测试结果如下,耗时 2 分 15 秒,内存占用 2.18G。

优化耗时
并不是用了 pipline 后,耗时就减少到了极致,我们仍旧可以通过其他方法进一步减少时间。众所周知 redis 是非常快的,即使是使用了 pipline,命令的处理速度仍然远小于 RTT 时间,而 load 进程构造 pipline 也是一个内存的操作,构建 pipline 的时间也远小于 RTT 时间。我们可以通过一个举一个极端的例子分析时间到底浪费到了哪里:假设如果构建 pipline与 redis 处理 pipline 的时间都是 10 ms,而 RTT 时间是 80ms,这样就意味着 load 进程每花费 10ms 构建一个 pipline 给 redis 都要等待 90ms 才能构建下一个 pipline,所以其 cpu 利用率为10%,redis 也同样如此,可见双方的 cpu 利用率之低。所以我们可以通过并发 pipline 插入,提高双方 cpu 利用率来节省时间。
性能
经过添加并发优化后的测试结果,耗时 1 分钟,内存占用 2.17G,内存基本持平,耗时优化效果 125%

优化内存
经过上面的测试应该明白了内存的优化主要在序列化上下功夫,首先读取整个 json 文件反序列化到结构体上,这个就动作就需要大约 2 倍元数据的内存,一倍的 json 字符串,一倍的结构体。可见整个读入的代价太高了,所以我们要以流式读取的方式来处理,每次读取并反序列一个最小的 json 对象,这样内存占用就非常低了。load 的另一个问题是我们把所有的 entry 存到了内存中来重新计算 nlink,这个也是导致内存占用非常高的原因之一。解决方法也非常简单,nlink 固然是需要重新计算的,不过把 entry 的所有属性都记录下其实是没有必要的,我们回想重新计算的逻辑,每次将文件类型的 entry 放入 map 前根据 inode 判断 entry 是否存在,如果存在就意味着这是一个硬链接,将这个 inode 的 nlink++。所以将 map 的 value 类型改为 int64 即可,每次放入时 value 值+1,这样比较大的 map 也就不存在了,内存占用进一步减少。
性能
经过了流式读取优化的测试结果如下,耗时 40s,内存占用 518M。内存优化效果 330%

总结
当前 1.0-rc2 版本与最初版优化效果
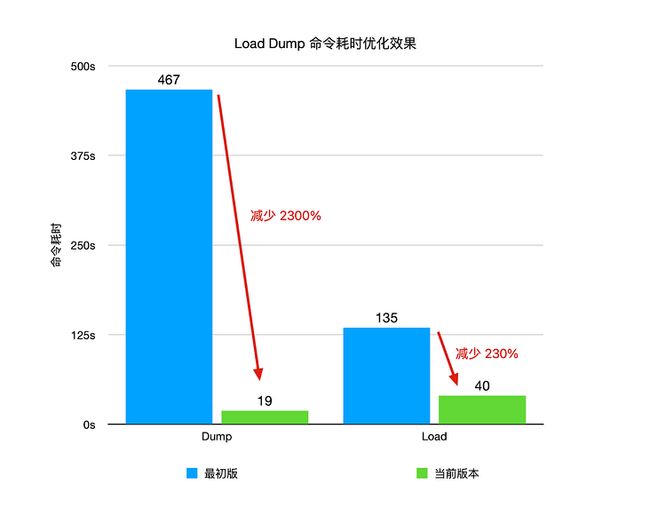
- Dump 耗时 7 分 47 秒,内存占用为 3.18G ,优化为耗时 19 秒,内存占用 75M,优化效果分别为 2300%和 4200%
- Load 耗时 2 分 15 秒,内存占用 2.18G, 优化后为耗时 40 秒,内存占用 518M。优化效果分别为 230%和 330%

可以看到优化效果是非常明显的。
以上就是我们的优化的思路与结果了,如果遇到类似的场景,希望这些实践经验也可以帮助大家拓展优化的思路,提升系统的性能!
如有帮助的话欢迎关注我们项目 Juicedata/JuiceFS 哟! (0ᴗ0✿)