MySQL为什么会选择B+树索引?
前言
我们都知道MySQL的InnoDB存储引擎中,默认、且提供给客户端使用的只能是B+树存储结构,尽管MySQL中还会有像Hash、R树、全文索引这样的存储方式,但在InnoDB中并不能显示的使用,这主要还是因为在大多数普适场景中,还是B+树这样的存储结构,更能满足实际的业务使用场景,本文就来分析分析B+树到底适用在哪里?
二叉树
那我们不妨先来看看,同样是树的存储结构,为什么不能使用二叉树系列的存储方式。
假设现在我们有如下一些索引值:20,4,13,7,1,17,9,2,6,11
我们先按照搜索二叉树的方式进行构建,得到下图所示:
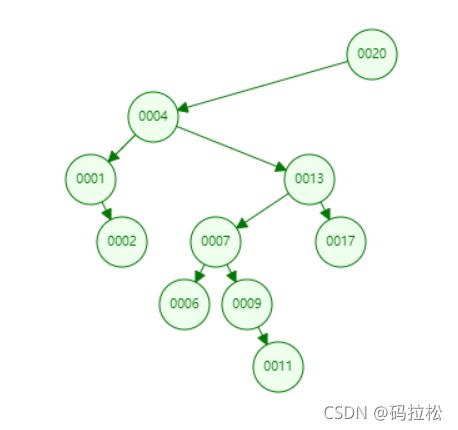
很明显这样的二叉树存在数据倾斜的问题,我们看到所有的数据都集中在20的左节点中,于是便有了像平衡二叉树这样的结构,例如下图所示,当我们使用平衡二叉树后,整颗树又变成了这样:

现在看起来,整个树的左右节点高度平衡了许多。
二叉树的问题在哪里?
实际上,无论是二叉树、平衡二叉树又或者是红黑树,它们都不能满足实际的业务场景,因为它们都有一个共同且致命的问题,就是一个节点的度太小了,无论哪一个节点只有左右两个子节点,只这对于使用内存进行存储的场景来说没有问题,但像MySQL这样使用磁盘存储的数据库来说,就不太适用了,因为每经过一个节点,实际上就需要一次磁盘IO,而我们知道磁盘IO与内存比起来是相当耗时的,如果按照这样的存储方式,可能刚存个几千条数据就查询就已经非常非常慢了。
如何减少磁盘IO?
二叉的问题说白了就是一次磁盘IO能从磁盘读到内存中的数据太少了,只读取了1条以及这1条指向左右节点的两个指针,那我们想,是不是一次性多读一点数据到内存中不就好了,那问题又来了,难道是一次性读的越多越好吗?内存有多大我就读多少?
局部性原理
要搞清楚这个问题,我们先来了解下程序局部性原理,Linux操作系统中在磁盘与内存交互之间有一个名为pagecache的一种机制,比如当从磁盘读取数据时、是先读到pagecache中,之后再从pagecache读到用户缓冲区,一个pagecache默认大小为4KB,并且数据被读到pagecache后并不会立马就从pagecache中移除,还是会按照一定的规则进行保留,因为按照时间局部性原理,可能会再次被访问到,而假设你只读了4KB的内容,但系统依然会按照一定的规则,比如读16KB的数据到pagecache中,这种叫预读,这是按照空间局部性原理,系统认为你有很大的可能也会用到与这批数据相邻的一些数据,所以就干脆把这些相邻的数据也一起加载回来得了。
页
与pagecache设计思想一样,MySQL InnoDB中也有一个页的概念,并且一页大小为16KB,也就是说MySQL可以一次从磁盘中加载16KB的数据,那16KB一般来说肯定不会只有一条数据,因此就需要有一种存储结构能够支持,于是就有了B+树。
B+树
B+树的特点就在于,一个节点中的度理论上是没有限制的,假设我们索引的字段时int类型,也就是4个字节,那么也就意味着我们一次性可以读取4096条索引值到内存中(16KB/4byte=4096)。
假设我们现在节点的度为3,我们再来看一下保存这些数的效果:20,4,13,7,1,17,9,2,6,11
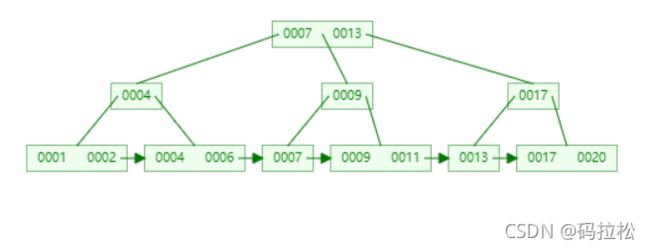
可以看到度为3时,树的高度为3,如果度为5时,树的高度尽为2了。

这就是B+树的优势所在,树的高度越低也就意味着磁盘IO的次数越少!
MySQL中的B+树结构

MySQL在标准的B+树上完成了索引结构,最底层的叶子节点使用双向链表的方式链在一起,同时还有一个指针指向数据所在的区域,并且索引值都是按顺序存储的。
之所以要有序+链表,这也是为了能够更好的支持范围查询和排序的业务需求。
B+树优势总结
- 1、树的高度低,大大减少了磁盘IO,数据在内存中进行过滤。
- 2、有序+链表,更好的支持范围和排序的业务需求。
- 3、与B-树相比,数据只保存在最底层的叶子节点上,而B-树会每个节点上都挂数据,这就造成了在节点度大小固定的情况下,一次从磁盘取回的数据相比不挂数据的B+树就要少很多,也就间接的造成了树的高度过高的问题。