Flink入门到实战-阶段一(集群安装&使用)
hello world
引入pom.xml
org.apache.maven.plugins
maven-compiler-plugin
8
8
1.13.0
1.8
2.12
1.7.30
org.apache.flink
flink-java
${flink.version}
org.apache.flink
flink-streaming-java_${scala.binary.version}
${flink.version}
org.apache.flink
flink-cep_${scala.binary.version}
${flink.version}
org.apache.flink
flink-connector-kafka_${scala.binary.version}
${flink.version}
org.apache.flink
flink-clients_${scala.binary.version}
${flink.version}
org.slf4j
slf4j-api
${slf4j.version}
org.slf4j
slf4j-log4j12
${slf4j.version}
org.apache.flink
flink-table-api-java-bridge_${scala.binary.version}
${flink.version}
org.apache.flink
flink-table-planner-blink_${scala.binary.version}
${flink.version}
org.apache.logging.log4j
log4j-to-slf4j
2.14.0
log4j.properties
log4j.rootLogger=ERROR, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%nDataSet(早期的批处理)实现
数据准备
nihao nihao
jiushi nihao处理程序
public class FlinkSoctet {
public static void main(String[] args) throws Exception {
//得到执行环境对象
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSource initData = env.readTextFile("input/wc.txt");
//使用内部内的优点是不用考虑类型擦除的问题
MapOperator> mapValue = initData.flatMap(new FlatMapFunction() {
@Override
public void flatMap(String textItem, Collector out) throws Exception {
String[] resItem = textItem.split(" ");
for (String s : resItem) {
out.collect(s);
}
}
}).map(new MapFunction>() {
@Override
public Tuple2 map(String item) throws Exception {
return Tuple2.of(item, 1);
}
});
//mapValue得到的数据是(key,value)元组类型,0表示key的位置,1表示value的位置
//下面就是用key进行分组,用value进行求和
mapValue.groupBy(0).sum(1).print();
}
} 得到的结果
(nihao,3)
(jiushi,1)DataStream(流处理Api实现)
数据准备
nihao nihao
jiushi nihao处理程序
public class FlinkSoctet {
public static void main(String[] args) throws Exception {
//得到执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource initData = env.readTextFile("input/wc.txt");
SingleOutputStreamOperator> map = initData.flatMap(new FlatMapFunction() {
@Override
public void flatMap(String item, Collector out) throws Exception {
String[] resItem = item.split(" ");
for (String s : resItem) {
out.collect(s);
}
}
}).map(new MapFunction>() {
@Override
public Tuple2 map(String item) throws Exception {
return Tuple2.of(item, 1);
}
});
//对于得到的元组的流数据,进行分组聚合
map.keyBy(new KeySelector, String>() {
@Override
public String getKey(Tuple2 value) throws Exception {
return value.f0;
}
}).sum(1).print();
//由于是流处理程序,所以这里要不断的执行
env.execute();
}
} 得到的结果
前面的数字是分配到的Task的编号,可以看到key相同的数据到了一个Task里面执行,比如nihao都在1线程里面处理
2> (jiushi,1)
1> (nihao,1)
1> (nihao,2)
1> (nihao,3)DataStream(流处理Api处理Socket)
在发送数据的linux上面执行
nc -lk 9997处理程序
public class FlinkSoctet {
public static void main(String[] args) throws Exception {
//得到执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource initData = env.socketTextStream("master",9997);
SingleOutputStreamOperator> map = initData.flatMap(new FlatMapFunction() {
@Override
public void flatMap(String item, Collector out) throws Exception {
String[] resItem = item.split(" ");
for (String s : resItem) {
out.collect(s);
}
}
}).map(new MapFunction>() {
@Override
public Tuple2 map(String item) throws Exception {
return Tuple2.of(item, 1);
}
});
//对于得到的元组的流数据,进行分组聚合
map.keyBy(new KeySelector, String>() {
@Override
public String getKey(Tuple2 value) throws Exception {
return value.f0;
}
}).sum(1).print();
//由于是流处理程序,所以这里要不断的执行
env.execute();
}
} 输入数据
q v d s fd a q得到的结果
9> (d,1)
8> (fd,1)
4> (q,1)
9> (s,1)
4> (q,2)
11> (a,1)
3> (v,1)
集群搭建和使用
下载安装
Apache Flink: Downloads

集群规划
| master | node1 | node2 |
| Jobmanager,TaskManager | TaskManager | TaskManager |
解压
tar -zxvf flink-1.13.2-bin-scala_2.12.tgz修改配置文件
flink-conf.yaml
jobmanager.rpc.address: mastermasters
master:8081workers
master
node1
node2
分发到集群其他机器
./xsync /home/bigdata/congxueflink启动集群(在bin目录里面)
./start-cluster.sh访问http://master:8081/

关闭
./stop-cluster.shWebUI提交任务
加入打包插件
org.apache.maven.plugins
maven-compiler-plugin
8
8
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
jar-with-dependencies
make-assembly
package
single
编写一个监听socket的程序
public class FlinkSoctet {
public static void main(String[] args) throws Exception {
//得到执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource initData = env.socketTextStream("master",9997);
SingleOutputStreamOperator> map = initData.flatMap(new FlatMapFunction() {
@Override
public void flatMap(String item, Collector out) throws Exception {
String[] resItem = item.split(" ");
for (String s : resItem) {
out.collect(s);
}
}
}).map(new MapFunction>() {
@Override
public Tuple2 map(String item) throws Exception {
return Tuple2.of(item, 1);
}
});
//对于得到的元组的流数据,进行分组聚合
map.keyBy(new KeySelector, String>() {
@Override
public String getKey(Tuple2 value) throws Exception {
return value.f0;
}
}).sum(1).print();
//由于是流处理程序,所以这里要不断的执行
env.execute();
}
} 然后打包
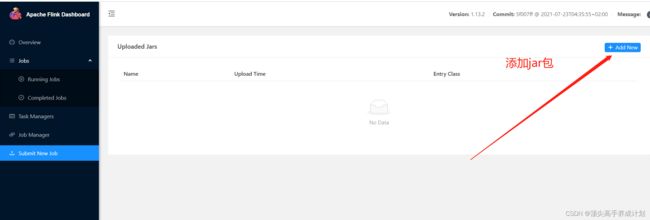
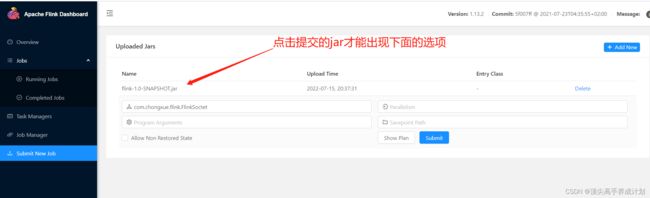
提交成功并执行
 查看处理的数据
查看处理的数据
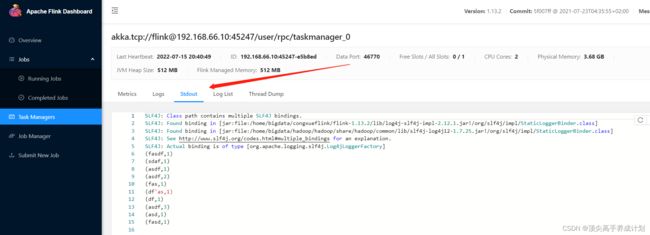
命令提交任务
-m是jobmanager开放提交的地址
-c是提交jar的启动类
-p是并行度
最后的jar就是自己打包的jar
./flink run -m master:8081 -c com.chongxue.flink.FlinkSoctet -p 2 flink-1.0-SNAPSHOT.jar停止任务(后面的是job的id)
./flink cancel d9e4f4dcb0516551d6611675c16113bb部署模式介绍
- 会话模式:上面我们搭建的就是会话模式,集群的什么周期大于一切.适合任务小而多的场景
- 单作业模式:提交一个任务就启动一个集群
- 应用模式:和单作业模式不同的是,单作业模式一个应用里面每执行一个job提交,那么就启动一个集群,如果是应用模式那么就是只启动一个集群,还有应用模式提价job的jar在jobmanager上面,缓解了单作业模式由客户端提交到jobmanager的网络开销压力
Yarn模式部署
环境准备
配置环境变量
sudo vi /etc/profile.d/my_env.shHADOOP_HOME=/home/bigdata/hadoop/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`source /etc/profile.d/my_env.sh可选配置:更具自己的需求配置启动的资源分配
vim flink-conf.yamljobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 8
parallelism.default: 1yarn会话模式
./yarn-session.sh -nm test可用参数解读:
⚫ -d:分离模式,如果你不想让 Flink YARN 客户端一直前台运行,可以使用这个参数,
即使关掉当前对话窗口,YARN session 也可以后台运行。
⚫ -jm(--jobManagerMemory):配置 JobManager 所需内存,默认单位 MB。
⚫ -nm(--name):配置在 YARN UI 界面上显示的任务名。
⚫ -qu(--queue):指定 YARN 队列名。
⚫ -tm(--taskManager):配置每个 TaskManager 所使用内存。
注意:Flink1.11.0 版本不再使用-n 参数和-s 参数分别指定 TaskManager 数量和 slot 数量,
YARN 会按照需求动态分配 TaskManager 和 slot。所以从这个意义上讲,YARN 的会话模式也
不会把集群资源固定,同样是动态分配的。
YARN Session 启动之后会给出一个 web UI 地址以及一个 YARN application ID,
用户可以通过 web UI 或者命令行两种方式提交作业。
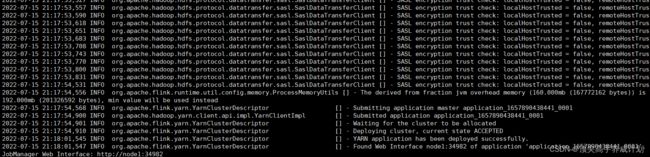
访问http://node1:34982/#/overview
如下图

提交一个job(node1:34982是刚才访问WebUI的地址和端口)
./flink run -m node1:34982 -c com.chongxue.flink.FlinkSoctet -p 2 flink-1.0-SNAPSHOT.jar
单作业模式部署
(每一次提交启动一个完整的集群)
启动
./flink run -d -t yarn-per-job -c com.chongxue.flink.FlinkSoctet flink-1.0-SNAPSHOT.jar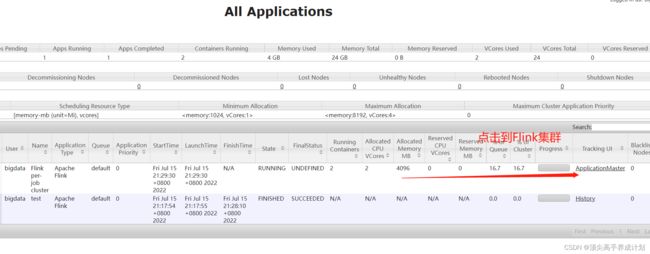
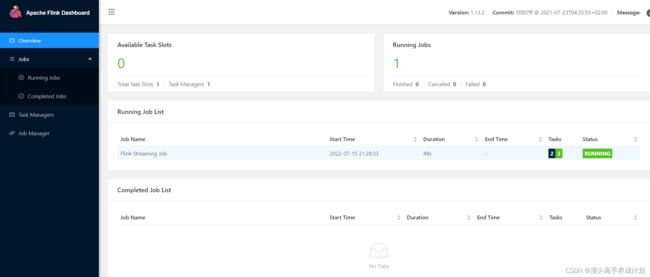
停止job
$ ./bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY$ ./bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY是作业的 ID 。注意如果取消作 业,整个 Flink 集群也会停掉。