httpx 的使用
个人简介
作者简介:大家好,我是W_chuanqi,一个编程爱好者
个人主页:W_chaunqi
支持我:点赞+收藏⭐️+留言
愿你我共勉:“若身在泥潭,心也在泥潭,则满眼望去均是泥潭;若身在泥潭,而心系鲲鹏,则能见九万里天地。”✨✨✨

httpx 的使用
我们使用urllib 库和 requests 库,已经可以爬取绝大多数网站的数据,但对于某些网站依然无能为力。这些网站强制使用 HTTP/2.0 协议访问,这时 urllib 和 requests 是无法爬取数据的,因为它们只支持 HTTP/1.1,不支持 HTTP/2.0。
那我们使用一些支持 HTTP/2.0 的请求库不就好了嘛,目前来说,比较有代表性的是hyper 和 httpx,后者使用起来更加方便,功能也更强大,requests已有的功能它几乎都支持。
httpx的特点:
- 和使用 requests 一样方便,requests 有的它都有
- 加入 HTTP/1.1 和 HTTP/2 的支持。
- 能够直接向 WSGI 应用程序或 ASGI 应用程序发出请求。
- 到处都有严格的超时设置
- 全类型注释
- 100% 的测试覆盖率
1.示例
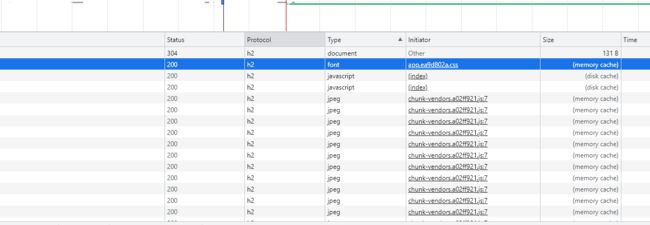
下面我们来看一个案例,https://spa16.scrape.center/就是强制使用 HTTP/2.0 访问的一个网站,用浏览器打开此网站,查看 Network 面板,可以看到 Protocol 一列都是 h2,证明请求所用的协议是HTTP/2.0,如下图所示。

找不到Protocol
一般我们使用ctrl+F12在network里看到的页面就是这样的
可以发现这里是没有protocol这个项目的,我们只要在在标签里右键,然后把protocol选项打开就可以看到使用到协议了
这样就可以啦


我们用requests库是不能爬取的,那我们不妨来尝试一下:
import requests
url ='https://spa16.scrape.center/'
response=requests.get(url)
print(response.text)
运行结果如下:

可以看到,首先抛出的就是 RemoteDisconnected 错误,请求失败。其原因是requests 库是使用 HTTP/1.1访问的目标网站,而目标网站会检测请求使用的协议是不是HTTP/2.0,如果不是就拒绝返回任何结果。
2.安装
httpx 的安装很简单,像其他的 Python 库一样,直接 pip 就完事了
pip install httpx
如果需要对 HTTP/2.0 支持,我们需要额外安装一个库
pip install httpx[http2]
这样就既安装了 httpx,又安装了 httpx 对 HTTP/2.0 的支持模块。

安装完成。。。
3.基本使用
httpx 和 requests 的很多 API存在相似之处,我们先看下最基本的 GET 请求的用法:
import httpx
response = httpx.get('https://www.httpbin.org/get')
print(response.status_code)
print(response.headers)
print(response.text)
这里我们还是请求之前的测试网站,直接使用 httpx 的 get 方法即可,用法和 requests 里的一模一样,将返回结果赋值为 response 变量,然后打印出它的 status_code、headers、text 等属性,运行结果如下:

输出结果包含三项内容,status_code 属性对应状态码,为 200;headers 属性对应响应头,是一个 Headers 对象,类似于一个字典;text 属性对应响应体,可以看到其中的 User-Agent 是python-httpx/0.23.0,代表我们是用 httpx 请求的。
下面换一个 User-Agent 再请求一次,代码改写如下:
import httpx
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'}
response = httpx.get('https://www.httpbin.org/get', headers=headers)
print(response.text)
这里我们换了一个 User-Agent 重新请求,并将其赋值为 headers 变量,然后传递给 headers 参数,运行结果如下:

可以发现更换后的 User-Agent 生效了。
回到开头提到的示例网站,我们试着用 httpx 请求一下这个网站,看看效果如何,代码如下:
import httpx
url = 'https://spa16.scrape.center/'
response = httpx.get(url)
print(response.text)
运行结果如下:

可以看到,抛出了和使用 requests请求时类似的错误,不是说好支持 HTTP/2.0 吗?其实,httpx凯认是不会开启对 HTP/2.0 的支持的,默认使用的是 HTTP/1.1,需要手动声明一下才能使用 HTTP/2.0,代码改写如下:
import httpx
client = httpx.Client(http2=True)
response = client.get('https://spa16.scrape.center/')
print(response.text)
运行结果如下:

这里我们声明了一个 Client 对象,赋值为 client 变量,同时显式地将 http2 参数设置为 True,这样便开启了对 HTTP/2.0 的支持,之后就会发现可以成功获取 HTML 代码了。这也就印证了这个示例网站只能使用 HTTP/2.0 访问。
刚才我们也提到了,httpx 和 requests 有很多相似的 API,上面实现的是 GET请求,对于 POST请求、PUT 请求和 DELETE 请求来说,实现方式是类似的:
import httpx
r = httpx.get('https://www.httpbin.org/get', params={'name': 'germy'})
r = httpx.post('https://www.httpbin.org/post', data={'name': 'germy'})
r = httpx.put('https://www.httpbin.org/put')
r = httpx.delete('https://www.httpbin.org/delete')
r = httpx.patch('https://www.httpbin.org/patch')
基于得到的 Response 对象,可以使用如下属性和方法获取想要的内容。
-
status_code:状态码。
-
text:响应体的文本内容。
-
content;响应体的二进制内容,当请求的目标是二进制数据(如图片)时,可以使用此属性
-
headers:响应头,是Headers对象,可以用像获取字典中的内容—样获取其中某个Header获取。
-
json:方法,可以调用此方法将文本结果转化为 JSON 对象。
除了这些,httpx还有一些基本用法也和requests极其类似,,可以参考官方文档:https://www.python-httpx.org/quickstart/。
4.Client 对象
httpx 中有一些基本的 APT和 requests 中的非常相似,但也有一些 API 是不相似的,例如 httpx中有一个 Client 对象,就可以和 requests 中的 Session 对象类比学习。
下而我们介绍 Client 对象的使用。官方比较推荐的使用方式是 with as 语句,示例如下:
import httpx
with httpx.Client() as client:
response = client.get('https://www.httpbin.org/get')
print(response)
运行结果如下:
![]()
另外,在声明 Client 对象时可以指定一些参数,例如 headers,这样使用该对象发起的所有请求都会默认带上这些参数配置,示例如下:
import httpx
url = 'https://www.httpbin.org/headers'
headers = {'User-Agent': 'my-app/0.01'}
with httpx.Client(headers=headers) as client:
r = client.get(url)
print(r.json()['headers']['User-Agent'])
这里我们声明了一个 headers 变量,内容为 User-Agent 属性,然后将此变量传递给 headers 参数初始化了一个 Client 对象,并赋值为 client 变量,最后用 client 变量请求了测试网站,并打印返回结果中的 User-Agent 的内容:
![]()
可以看到,headers 成功赋值了。
关于 Client 对象的更多高级用法可以参考官方文档:https/www.python-httpx.org/advanced/。
5.支持 HTTP/2.0
现在是要在客户端上开启对 HTTP/2.0 的支持,就像“基本使用”小节所说的那样,同样是声明Client 对象,然后将 http2 参数设置为 True,如果不设置,那么默认支持 HTTP/1.1,即不开启对HTTP/2.0 的支持。
写法如下:
import httpx
client = httpx.Client(http2=True)
response = client.get('https://www.httpbin.org/get')
print(response.text)
print(response.http_version)
这里我们输出了 response 变量的 http_version 属性,这是 requests 中不存在的属性,其结果为:
![]()
这里输出的 http_version 属性值是 HTTP/2,代表使用了 HTTP/2.0 协议传输。
注意在客户端的 httpx 上启用对 HTTP/2.0 的支持并不意味着请求和响应都将通过 HTTP/2.0 传输,这得客户端和服务端都支持 HTTP/2.0 才行。如果客户端连接到仅支持 HTTP/1.1 的服务器,那么它也需要改用 HTTP/1.1。
6.支持异步请求
httpx 还支持异步客户端请求(即 AsyncClient ),支持 Python 的 async 请求模式,写法如下:
from urllib import response
import httpx
import asyncio
async def fetch(url):
async with httpx.AsyncClient(http2=True) as client:
response = await client.get(url)
print(response.text)
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(
fetch('https://www.httpbin.org/grt'))
关于异步请求,大家也可以参考官方文档:https://www.python-httpx.org/async/。