【活体人脸识别】FaceBagNet论文翻译详解
论文题目:Bag-of-local-features Model for Multi-modal Face Anti-spoofing
论文地址:FaceBagNet
代码地址:https://github.com/SeuTao/CVPR19-Face-Anti-spoofing
摘要
人脸反欺骗检测是人脸生物识别系统中的一个重要环节。最新的(SOTA)基于卷积神经网络(CNNs)的方法在该领域取得了良好的效果。然而,以前的工作集中在单一的模态数据和数量有限的数据。最近发布的CASIA-SURF数据集是最大的数据集,包含1000名受试者和21000个视频剪辑,有3种模态(RGB、Depth和IR)。在本文中,我们提出了一个称为FaceBagNet的多流CNN架构来充分利用这一数据。FaceBagNet的输入是patch-level图像,有助于提取特定于欺骗的判别信息。此外,为了防止过拟合和更好地学习融合特征,我们在多模态特征上设计了模态特征擦除(Model Feature Erasing,MFE)操作,在训练过程中擦除随机选择的一个模态特征。我们的方法在CVPR 2019 ChaLearn Face Anti-spoofing攻击检测挑战中获得第二名。我们最终提交的成绩是99.8052% (TPR@FPR = 10e-4)。
1. 引言
人脸图像是最容易获得的生物特征模态,用于高精度的人脸识别系统,但它容易受到许多不同类型的呈现攻击[7,1]。因此,人脸反欺骗是计算机视觉领域的一个重要任务,其在人脸识别系统中的应用引起了人们的广泛关注[20,24,6]。它的目的是确定捕捉到的脸是否真实。
对于传统的方法,大多数研究者使用手工制作的特征,如LBP[19,29,6,17], HoG [29], SIFT[21], SURF和DoG[13]来学习真实人脸和假的人脸之间不同的特征分布。Boulkenafet等人[3]使用LBP特征来表征颜色-纹理。利用支持向量机(SVM)对这些颜色纹理特征向量进行分类。
最近,在人脸呈现攻击检测(PAD)社区中提出了基于cnn的方法[9,22]。他们将PAD视为一个二元分类问题。一些研究人员将CNN作为特征提取器[21],提取有区别的特征来区分真实和欺骗。Yang等人[28]提出了一种与ImageNet具有相同架构的CNN。Atoum等人[18]比较了三种不同CNN架构的性能,分别是:Inception-v3[23]和两个版本的ResNet[10],即ResNet50(一个50层的ResNet)和ResNet152(152层版本)。[2]在面部解锁系统中采用了基于patch和基于深度的CNN的集成。Feng等人[9]提出使用多个线索作为CNN输入进行真/假分类。在[25]中,Tu等人提出了一种LSTM-CNN架构,对视频的多帧进行联合预测。
所有这些方法都证明了CNNs[28, 16, 12]通过自动从训练数据中提取有用的特征,可以非常有效地用于人脸反欺骗。不幸的是,现有的人脸反欺骗数据集数量有限[31,6,4],这大大降低了这些方法的泛化能力。以往发表的著作主要基于这些数据集,很难满足实际应用的要求。最近发表的CASIA-SURF[30,15]数据集包括1000名受试者和21000个视频剪辑,有3种模态(RGB、Depth和IR)。从受试者数量和视频数量来看,该数据集是最大的人脸反欺骗干扰数据集。利用CASIA-SURF[30,15]数据集,我们设计了一种基于图像patches的多流网络来对多模态人脸图像进行分类。我们的方法的动机是BagNets[5],它通过使用小的局部图像patchs分类图像。虽然这种策略忽略了一些空间信息,但在ImageNet上却达到了令人惊讶的高精度。本文的主要工作和贡献如下:
(1)一种基于patch的特征学习方法。该方法基于局部小特征的出现对人脸图像进行分类,具有较强的分类性能。
(2)一种多流的模态特征擦除(Model Feature Erasing,MFE)式融合方法,该方法整合了子特征所涉及的多种信息。结果表明,该方法是一种有效的多模态人脸反欺骗方法。
2. 相关工作
现有的人脸反欺骗方法一般可分为两类:(1)传统的人脸反欺骗方法;(2)基于CNN的人脸反欺骗方法。
(1)传统的人脸抗欺骗方法:以往的很多工作都是利用手工制作的特征,如LBP、HoG、SIFT和SURF,通常采用传统的分类器,如SVM和LDA。为了克服光照变化的影响,Zhang等人利用多个DoG滤波器去除噪声和低频信息。他们使用SVM分类器来区分真脸和假脸。佩雷拉等[8]使用空间和时间描述符来编码丰富的信息。Chingovska等[6]使用LBP描述符从灰度图像中提取判别特征,然后使用3个分类器将其作为分类问题进行处理。由于传统的方法对不同的光照、姿态和特定的身份敏感,这些方法不能捕捉到判别表示,泛化能力较差。
(2)基于CNN的人脸抗欺骗方法:近年来,在目标检测、图像分类、图像字幕和语义分割等视觉信息处理领域,CNN已经被证明是一种有效的方法。因此,CNN被广泛应用于人脸反欺骗和活体检测。Atoum等[27]提出了基于双流CNN的人脸反欺骗方法,包括基于patch和基于深度的方法。Li等人[14]提取特征,应用主成分分析提高人脸识别系统的鲁棒性。在[9]中,Feng等人设计了不同的人脸图像,将其输入CNN,然后直接对人脸是否真实进行分类。在[14]中,Li等人通过人脸反欺骗数据集对CNN进行了微调,并取得了较高的性能。在[27]中,Xu等人首先引入了人脸反欺骗区域的LSTM,他们都使用了可以在LSTM单元中学习和排序的局部特征和时间特征。Liu等人[16]设计了一种网络架构,将深度图和rPPG信号作为监督,以提高泛化能力。Amin等人[12]通过将欺骗人脸反分解为真实人脸和欺骗噪声模式,提出了一种解决人脸反欺骗的新视角。
总的来说,以前的方法将人脸抗欺骗作为一个二值分类问题,由于对训练数据过拟合而不能很好地泛化。在[5]中,Brendel等人从输入图像中提取了patch特征,在数据集上取得了显著的改进。这项工作使我们认识到,我们需要涉及到局部特征,以解决人脸反欺骗问题。
3. 方法
3.1 整体架构
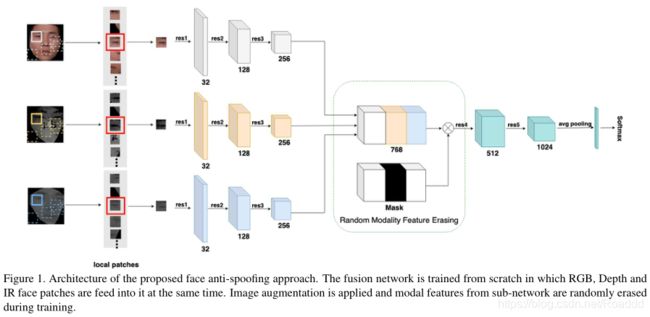
在这项工作中,我们提出了一种多流(multii-stream)的具有模态特征擦除(Model Feature Erasing,MFE)CNN架构,称为FaceBagNet,用于多模态人脸反欺骗检测。该方法由两个部分组成,(1)基于patch的特征学习,(2)多流模态擦除式融合。对于基于patch的特征学习,我们使用从人脸图像中随机提取的patch训练深度神经网络来学习丰富的外观特征。在多流融合中,在训练过程中随机去除不同模态的特征,然后进行融合分类。图1展示了三个流的high-level图,以及用于组合它们的融合策略。
3.2 基于patch的特征学习
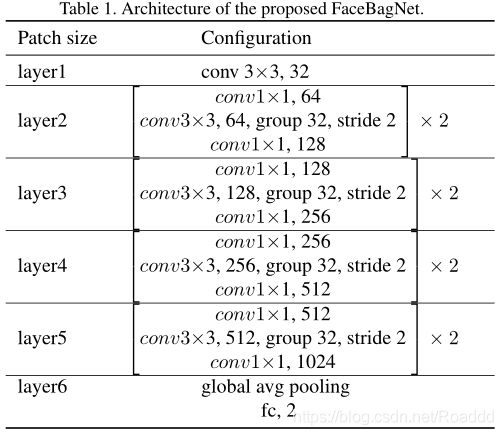
在整个人脸区域中存在欺骗特有的判别信息。因此,我们可以使用patch级图像强制CNN提取这些信息。通常基于patch的方法将全脸分割成几个固定的不重叠区域。然后每个patch用来训练一个独立的子网络。在本文中,对于每个模态,我们在从人脸提取的随机小块上训练一个单一的CNN。我们使用自己设计的ResNext[26]网络来提取深度特征。该网络由五组卷积块、一个全局平均池化层和一个softmax层组成。表1给出了网络的层次结构,即卷积核的大小、输出特征图的数量、groups的数量,以及stride的大小。我们的实验表明,基于patch的特征在不同的攻击中具有高度的区别性。在实验部分,将会给出比较不同大小patch的定量结果。
3.3 多流的模态特征擦除式融合
由于不同模态的特征分布是不同的,所提出的模型也努力利用不同模态之间的相互依赖性。如图1所示,我们使用一个包含三个子网络的多流架构来进行多模态特征融合。我们在第三个卷积块(res3)之后连接三个子网络的特征图。
正如[30]中所研究的,直接连接每个子网络的特征并不能充分利用不同模态之间的特征。为了防止过拟合和更好地学习融合特征,我们设计了一种多模态特征擦除操作。对于一个batch的输入,连接的特征张量由三个子网络计算。在训练期间,一个随机选择的模态子网络的特征被擦除,并且被擦除的区域被设置为0。融合网络从头开始训练,同时将RGB、Depth和IR数据分别输入到每个子网络中。
4. 实验
4.1 数据集和评价指标
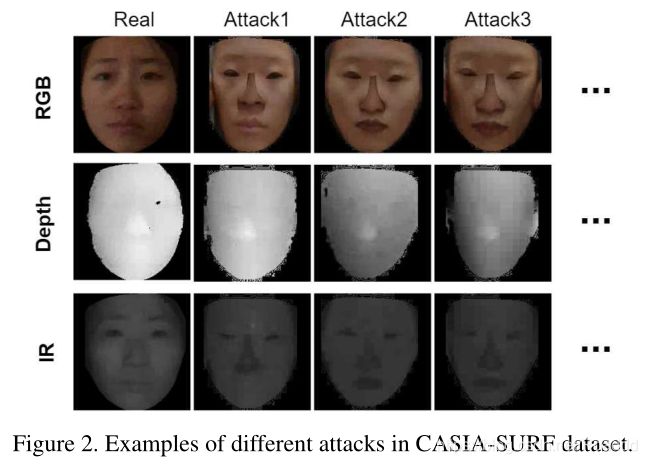
CASIA-SURF[30,15]数据集是目前最大的人脸反欺骗干扰数据集,它包括RGB、Depth和IR三种模式,如图2所示。这个数据集包含1000个中国人的21000个视频,每个样本包含在不同的攻击方式下1个实时视频剪辑,6个假视频剪辑。数据集由6次攻击生成。在不同的攻击方式下,眼睛,鼻子,嘴巴区域或它们的组合被移除。除了脸部区域,复杂的背景从原始视频中移除。数据集分为训练集、验证集和测试集。训练集、验证集和测试集分别有300、100和600个受试者。三个模态图像被裁剪和对齐。本数据集中RGB图像的分辨率为1280×720,Depth、IR和对齐图像的分辨率为640×480。它是人脸反欺骗领域中最具挑战性的数据集。
训练后,使用攻击表现分类错误率(APCER),正常表现分类错误率(NPCER)然后计算平均分类错误率(ACER)统计数据作为我们所提出模型的评估结果。根据实际应用的需要,使用受试者操作特性(ROC)来选择阈值,以权衡假阳性率(FPR)和真阳性率(TPR)。
4.2 实现细节
完整的人脸图像大小调整为112×112。我们使用随机翻转、旋转、调整大小、裁剪来增强数据。从112×112大小的人脸图像中随机提取Patches。所有模型都使用Titan X(Pascal) GPU进行训练,batch size大小为512。我们使用随机梯度下降(SGD)优化器与周期余弦退火调整学习率[11]。整个训练过程有250个epoch,大约需要3个小时。weight decay和momentum分别设置为0.0005和0.9,使用Pytorch作为深度学习框架。
4.3 实验结果
为了评估我们提出的模型的有效性,我们设计了几个不同构型的实验来进行比较。对比实验细节如下:
(1)Patch大小和模态的影响:在这个设置中,我们在我们的模型中使用不同的Patch大小,即16×16, 32×32, 48×48和64×64。为了比较性能,所有的模型都用9个不重叠的图像块和4个翻转输入进行了36次推断。如表3所示,对于单模态输入,三种模态中,深度数据表现最好,为0.8% (ACER), TPR=99.3% @FPR=10e-4。具体地说,融合所有三种模式在所有patch大小上都有很强的性能。结果表明,采用融合模态的方法取得了较好的效果。

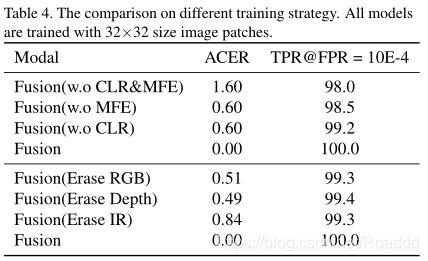
(2)模态特征擦除的效果和训练策略:我们研究了随机模态特征擦除和训练策略对人脸抗欺骗模型性能的影响。“w.o CLR”表示我们使用带有标准衰减学习率计划的常规SGD训练直到收敛,而不是使用周期学习率。“w.o MFE”表示不应用随机模态特征擦除。如表4所示,周期学习率和随机模态特征擦除策略对于实现高性能都是至关重要的。在对融合模型进行训练后,我们从一个模态中删除特征,然后对其性能进行评估。我们对训练后的融合模型进行了单模态特征擦除的性能评估。在表4中,从验证得分可以得出结论,可以学习不同模式之间的互补性,以获得更好的结果。
(3)在ChaLearn Face Antispoofing attack detection challenge中,与其他团队相比:我们最终提交的是三个模型在不同patch大小(32×32, 48×48和64×64)下的输出的集成的结果,最终排名第二。我们是唯一一个没有使用整张人脸图像作为模型输入的团队。FN = 1的结果表明,我们的基于patch的学习方法通过与其他排名靠前的团队进行比较,可以有效防止模型将真实人脸误分类为攻击人脸。如表2所示,前三名团队在测试集上的结果明显优于其他团队。特别是我们团队的TPR@FPR=10e4值与VisionLabs比较接近。然而,VisionLabs应用了大量来自其他任务的数据来预训练模型,而我们的团队只使用了一个单阶段和端到端的训练策略。因此,证明了我们的解决方案的优越性。

5. 结论
本文提出了一种基于Bag-of-local-features的人脸反欺骗网络(FaceBagNet)来判断捕获的多模态人脸图像是否真实。采用基于patch的特征学习方法提取判别信息。采用MFE层的多流融合技术提高了性能。研究表明,基于patch的特征学习方法和基于MFE的多流融合方法都是有效的人脸反欺骗方法。总体而言,我们的解决方案简单有效,易于在实际应用场景中使用。因此,我们的方法在CVPR 2019 ChaLearn Face Anti-spoofing attack detection challenge中获得第二名。在测试机上我们最终提交的成绩是99.8052% (TPR@FPR = 10e-4)。
参考文献
[1] A. Alotaibi and A. Mahmood. Deep face liveness detection based on nonlinear diffusion using convolution neural network. Signal, Image and Video Processing, 11(4):713–720,2017.
[2] Y . Atoum, Y . Liu, A. Jourabloo, and X. Liu. Face anti-spoofing using patch and depth-based cnns. In 2017 IEEE International Joint Conference on Biometrics, IJCB 2017,Denver , CO, USA, October 1-4, 2017, pages 319–328, 2017.
[3] P . L. Bartlett, F. C. N. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, editors. Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012. Proceedings of a meeting held December 3-6, 2012, Lake Tahoe, Nevada, United States, 2012.
[4] Z. Boulkenafet, J. Komulainen, L. Li, X. Feng, and A. Hadid. OULU-NPU: A mobile face presentation attack database with real-world variations. In 12th IEEE International Conference on Automatic Face & Gesture Recognition, FG 2017,Washington, DC, USA, May 30 - June 3, 2017, pages 612–618, 2017.
[5] W. Brendel and M. Bethge. Approximating cnns with bag-of-local-features models works surprisingly well on imagenet. International Conference on Learning Representations, 2019.
[6] I. Chingovska, A. Anjos, and S. Marcel. On the effectiveness of local binary patterns in face anti-spoofing. In 2012 BIOSIG-Proceedings of the International Conference of Biometrics Special Interest Group, Darmstadt, Germany, September 6-7, 2012, pages 1–7, 2012.
[7] A. da Silva Pinto, W. R. Schwartz, H. Pedrini, and A. de Rezende Rocha. Using visual rhythms for detecting video-based facial spoof attacks. IEEE Trans. Information F orensics and Security, 10(5):1025–1038, 2015.
[8] T. de Freitas Pereira, A. Anjos, J. M. D. Martino, and S. Marcel. LBP - TOP based countermeasure against face spoofing attacks. In Computer Vision - ACCV 2012 Workshops - ACCV 2012 International Workshops, Daejeon, Korea, November 5-6, 2012, Revised Selected Papers, Part I, pages 121–132, 2012.
[9] L. Feng, L. Po, Y . Li, X. Xu, F. Y uan, T. C. Cheung, and K. Cheung. Integration of image quality and motion cues for face anti-spoofing: A neural network approach. J. Visual Communication and Image Representation, 38:451–460, 2016.
[10] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las V egas, NV , USA, June 27-30, 2016, pages 770–778, 2016.
[11] G. Huang, Y . Li, G. Pleiss, Z. Liu, J. E. Hopcroft, and K. Q. Weinberger. Snapshot ensembles: Train 1, get M for free. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings, 2017.
[12] A. Jourabloo, Y . Liu, and X. Liu. Face de-spoofing: Anti-spoofing via noise modeling. In Computer Vision - ECCV 2018 - 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part XIII, pages 297–315, 2018.
[13] W. Kim, S. Suh, and J. Han. Face liveness detection from a single image via diffusion speed model. IEEE Trans. Image Processing, 24(8):2456–2465, 2015.
[14] L. Li, X. Feng, Z. Boulkenafet, Z. Xia, M. Li, and A. Ha-did. An original face anti-spoofing approach using partial convolutional neural network. In Sixth International Conference on Image Processing Theory, Tools and Applications,IPTA 2016, Oulu, Finland, December 12-15, 2016, pages 1–6, 2016.
[15] A. Liu, J. Wan, S. Escalera, H. J. Escalante, Z. Tan, Q. Y uan, K. Wang, G. Guo, I. Guyon, and S. Z. Li. Multi-modal face anti-spoong attack detection challenge at cvpr2019. CVPR workshop, 2019.
[16] Y . Liu, A. Jourabloo, and X. Liu. Learning deep models for face anti-spoofing: Binary or auxiliary supervision. CoRR, abs/1803.11097, 2018.
[17] J. Määttä, A. Hadid, and M. Pietikäinen. Face spoofing detection from single images using texture and local shape analysis. IET Biometrics, 1(1):3–10, 2012.
[18] C. Nagpal and S. R. Dubey. A performance evaluation of convolutional neural networks for face anti spoofing. CoRR,
abs/1805.04176, 2018.
[19] T. Ojala, M. Pietikäinen, and T. Mäenpää. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell., 24(7):971–987, 2002.
[20] G. Pan, L. Sun, Z. Wu, and S. Lao. Eyeblink-based anti-spoofing in face recognition from a generic webcamera. In
IEEE 11th International Conference on Computer Vision, ICCV 2007, Rio de Janeiro, Brazil, October 14-20, 2007, pages 1–8, 2007.
[21] K. Patel, H. Han, and A. K. Jain. Secure face unlock: Spoof detection on smartphones. IEEE Trans. Information Forensics and Security, 11(10):2268–2283, 2016.
[22] K. Patel, H. Han, and A. K. Jain. Secure face unlock: Spoof detection on smartphones. IEEE Trans. Information Forensics and Security, 11(10):2268–2283, 2016.
[23] C. Szegedy, V . V anhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las V egas, NV , USA, June 27-30, 2016, pages 2818–2826, 2016.
[24] X. Tan, Y . Li, J. Liu, and L. Jiang. Face liveness detection from a single image with sparse low rank bilinear discriminative model. In Computer Vision - ECCV 2010 - 11th European Conference on Computer Vision, Heraklion, Crete, Greece, September 5-11, 2010, Proceedings, Part VI, pages 504–517, 2010.
[25] X. Tu, H. Zhang, M. Xie, Y . Luo, Y . Zhang, and Z. Ma.Enhance the motion cues for face anti-spoofing using CNN-LSTM architecture. CoRR, abs/1901.05635, 2019.
[26] S. Xie, R. B. Girshick, P . Dollár, Z. Tu, and K. He. Aggregated residual transformations for deep neural networks. In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pages 5987–5995, 2017.
[27] Z. Xu, S. Li, and W. Deng. Learning temporal features using LSTM-CNN architecture for face anti-spoofing. In 3rd IAPR Asian Conference on Pattern Recognition, ACPR 2015, Kuala Lumpur , Malaysia, November 3-6, 2015, pages 141–
145, 2015.
[28] J. Y ang, Z. Lei, and S. Z. Li. Learn convolutional neural network for face anti-spoofing. CoRR, abs/1408.5601, 2014.
[29] J. Y ang, Z. Lei, S. Liao, and S. Z. Li. Face liveness detection with component dependent descriptor. In International Conference on Biometrics, ICB 2013, 4-7 June, 2013, Madrid, Spain, pages 1–6, 2013.
[30] S. Zhang, X. Wang, A. Liu, C. Zhao, J. Wan, S. Escalera, H. Shi, Z. Wang, and S. Z. Li. CASIA-SURF: A dataset and benchmark for large-scale multi-modal face anti-spoofing. CVPR, 2019.
[31] Z. Zhang, J. Y an, S. Liu, Z. Lei, D. Yi, and S. Z. Li. A face antispoofing database with diverse attacks. In 5th IAPR International Conference on Biometrics, ICB 2012, New Delhi, India, March 29 - April 1, 2012, pages 26–31, 2012.