强化学习算法 DDPG 解决 CartPole 问题,代码逐条详解
本文内容源自百度强化学习 7 日入门课程学习整理
感谢百度 PARL 团队李科浇老师的课程讲解
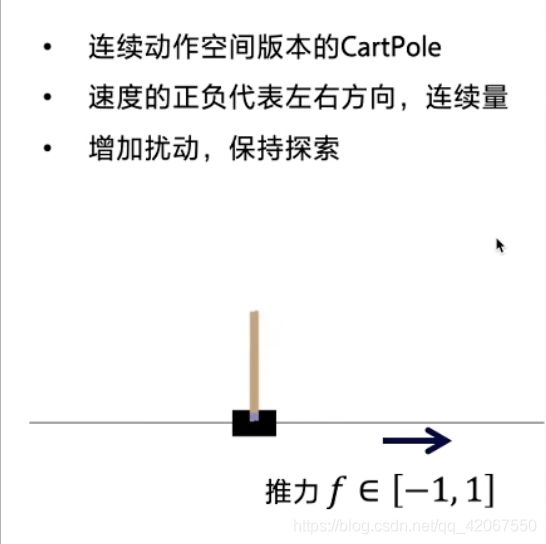
使用DDPG解决连续控制版本的CartPole问题,给小车一个力(连续量)使得车上的摆杆倒立起来。
文章目录
- 一、安装依赖
- 二、导入依赖
- 三、设置超参数
- 四、搭建Model、Algorithm、Agent架构
-
- 4.1 Model
- 4.2 Algorithm
- 4.3 Agent
- 五、连续控制版本的CartPole环境
- 六、设置经验池
- 七、Training && Test(训练&&测试)
- 八、创建环境和Agent,创建经验池,启动训练,保存模型
一、安装依赖
!pip install gym
!pip install paddlepaddle==1.6.3
!pip install parl==1.3.1
# 检查依赖包版本是否正确
!pip list | grep paddlepaddle
!pip list | grep parl
二、导入依赖
import gym
import numpy as np
from copy import deepcopy
import paddle.fluid as fluid
import parl
from parl import layers
from parl.utils import logger
三、设置超参数
ACTOR_LR = 1e-3 # Actor网络的 learning rate
CRITIC_LR = 1e-3 # Critic网络的 learning rate
GAMMA = 0.99 # reward 的衰减因子
TAU = 0.001 # 软更新的系数
MEMORY_SIZE = int(1e6) # 经验池大小
MEMORY_WARMUP_SIZE = MEMORY_SIZE // 20 # 预存一部分经验之后再开始训练
BATCH_SIZE = 128
REWARD_SCALE = 0.1 # reward 缩放系数
NOISE = 0.05 # 动作噪声方差
TRAIN_EPISODE = 6000 # 训练的总episode数
四、搭建Model、Algorithm、Agent架构
Agent把产生的数据传给algorithm,algorithm根据model的模型结构计算出Loss,使用SGD或者其他优化器不断的优化,PARL这种架构可以很方便的应用在各类深度强化学习问题中。
4.1 Model
Model用来定义前向(Forward)网络,用户可以自由的定制自己的网络结构
class Model(parl.Model):
def __init__(self, act_dim):
self.actor_model = ActorModel(act_dim)
self.critic_model = CriticModel()
def policy(self, obs): # 链接 ActorModel 下的该方法
return self.actor_model.policy(obs)
def value(self, obs, act): # 链接 CriticModel 下的该方法
return self.critic_model.value(obs, act)
def get_actor_params(self):
return self.actor_model.parameters() # 基类中的方法,获取参数
class ActorModel(parl.Model): # 演员模型
def __init__(self, act_dim):
hid_size = 100
self.fc1 = layers.fc(size=hid_size, act='relu') # 第一层用 relu 激活
self.fc2 = layers.fc(size=act_dim, act='tanh') # 第二层用 tanh 激活 -1~1
def policy(self, obs): # 输入 obs
hid = self.fc1(obs)
means = self.fc2(hid)
return means # 输出一个 -1~1 的浮点数
class CriticModel(parl.Model): # 评价模型
def __init__(self):
hid_size = 100
self.fc1 = layers.fc(size=hid_size, act='relu') # 第一层用 relu
self.fc2 = layers.fc(size=1, act=None) # 第二层没有激活函数,线性,因为输出的是 Q 值
def value(self, obs, act):
concat = layers.concat([obs, act], axis=1)
# 沿着第 2 个维度进行拼接,即 行数不变,列数增加
# 每一个 样本 包含了 obs 和 act
hid = self.fc1(concat)
Q = self.fc2(hid)
Q = layers.squeeze(Q, axes=[1]) # 压缩一维数据
return Q
4.2 Algorithm
Algorithm 定义了具体的算法来更新前向网络(Model),也就是通过定义损失函数来更新Model,和算法相关的计算都放在algorithm中。
# from parl.algorithms import DDPG # 也可以直接从parl库中快速引入DDPG算法,无需自己重新写算法
class DDPG(parl.Algorithm):
def __init__(self,
model,
gamma=None,
tau=None,
actor_lr=None,
critic_lr=None):
""" DDPG algorithm
Args:
model (parl.Model): actor and critic 的前向网络.
model 必须实现 get_actor_params() 方法.
gamma (float): reward的衰减因子.
tau (float): self.target_model 跟 self.model 同步参数 的 软更新参数
actor_lr (float): actor 的学习率
critic_lr (float): critic 的学习率
"""
assert isinstance(gamma, float) # 确认参数类型
assert isinstance(tau, float)
assert isinstance(actor_lr, float)
assert isinstance(critic_lr, float)
self.gamma = gamma # 赋值
self.tau = tau
self.actor_lr = actor_lr
self.critic_lr = critic_lr
self.model = model # 传入 model
self.target_model = deepcopy(model) # 硬拷贝 model
def predict(self, obs):
""" 使用 self.model 的 actor model 来预测动作
"""
return self.model.policy(obs)
def learn(self, obs, action, reward, next_obs, terminal):
""" 用DDPG算法更新 actor 和 critic
"""
actor_cost = self._actor_learn(obs)
critic_cost = self._critic_learn(obs, action, reward, next_obs,
terminal)
return actor_cost, critic_cost
def _actor_learn(self, obs):
action = self.model.policy(obs) # 获得的 action 是一个 -1~1 的连续值
Q = self.model.value(obs, action) # 状态和动作下,通过神经网络,获得对应 Q 值
cost = layers.reduce_mean(-1.0 * Q) # 最小化 cost,就是最大化 Q 值
optimizer = fluid.optimizer.AdamOptimizer(self.actor_lr)
optimizer.minimize(cost, parameter_list=self.model.get_actor_params())
return cost
def _critic_learn(self, obs, action, reward, next_obs, terminal):
next_action = self.target_model.policy(next_obs) # 预测下一次的动作
next_Q = self.target_model.value(next_obs, next_action) # 获取下一步的 Q
terminal = layers.cast(terminal, dtype='float32') # 把 bool 值转化为浮点数
target_Q = reward + (1.0 - terminal) * self.gamma * next_Q # 求得 目标 Q
target_Q.stop_gradient = True # 阻止更新网络参数
Q = self.model.value(obs, action) # 状态和动作下,通过神经网络,获得对应 Q 值
cost = layers.square_error_cost(Q, target_Q) # 最小化预测 Q 和 目标 Q 的差别
cost = layers.reduce_mean(cost)
optimizer = fluid.optimizer.AdamOptimizer(self.critic_lr)
optimizer.minimize(cost)
return cost
def sync_target(self, decay=None, share_vars_parallel_executor=None):
""" self.target_model从self.model复制参数过来,可设置软更新参数
"""
if decay is None:
decay = 1.0 - self.tau
# 新参数 0.1% 权重,旧参数为 99.9% 的权重
# 使得参数更新更平滑
self.model.sync_weights_to(
self.target_model,
decay=decay,
share_vars_parallel_executor=share_vars_parallel_executor)
# 使用 PARL 自带的函数进行参数同步
4.3 Agent
Agent负责算法与环境的交互,在交互过程中把生成的数据提供给Algorithm来更新模型(Model),数据的预处理流程也一般定义在这里。
class Agent(parl.Agent):
def __init__(self, algorithm, obs_dim, act_dim):
assert isinstance(obs_dim, int)
assert isinstance(act_dim, int)
self.obs_dim = obs_dim # 状态维度
self.act_dim = act_dim # 动作维度(这里为 1)
super(Agent, self).__init__(algorithm)
# 注意:最开始先同步self.model和self.target_model的参数.
self.alg.sync_target(decay=0)
def build_program(self):
self.pred_program = fluid.Program()
self.learn_program = fluid.Program()
with fluid.program_guard(self.pred_program): # 形成预测程序
# 输入参数定义
obs = layers.data(
name='obs', shape=[self.obs_dim], dtype='float32')
# 输出参数定义
self.pred_act = self.alg.predict(obs)
with fluid.program_guard(self.learn_program): # 形成学习程序
# 输入参数定义
obs = layers.data(
name='obs', shape=[self.obs_dim], dtype='float32')
act = layers.data(
name='act', shape=[self.act_dim], dtype='float32')
reward = layers.data(name='reward', shape=[], dtype='float32')
next_obs = layers.data(
name='next_obs', shape=[self.obs_dim], dtype='float32')
terminal = layers.data(name='terminal', shape=[], dtype='bool')
# 输出参数定义
_, self.critic_cost = self.alg.learn(obs, act, reward, next_obs,
terminal)
def predict(self, obs):
obs = np.expand_dims(obs, axis=0) # 程序输入数据结构要求增维
act = self.fluid_executor.run(
self.pred_program, feed={'obs': obs},
fetch_list=[self.pred_act])[0]
act = np.squeeze(act)
return act
def learn(self, obs, act, reward, next_obs, terminal):
# 输入的数据
feed = {
'obs': obs,
'act': act,
'reward': reward,
'next_obs': next_obs,
'terminal': terminal
}
# 运行程序,并取得输出的数据
critic_cost = self.fluid_executor.run(
self.learn_program, feed=feed, fetch_list=[self.critic_cost])[0]
self.alg.sync_target()
return critic_cost # 评价网络的 cost
五、连续控制版本的CartPole环境
# env.py
# Continuous version of Cartpole
import math
import gym
from gym import spaces
from gym.utils import seeding
import numpy as np
class ContinuousCartPoleEnv(gym.Env):
metadata = {
'render.modes': ['human', 'rgb_array'],
'video.frames_per_second': 50
}
def __init__(self):
self.gravity = 9.8
self.masscart = 1.0
self.masspole = 0.1
self.total_mass = (self.masspole + self.masscart)
self.length = 0.5 # actually half the pole's length
self.polemass_length = (self.masspole * self.length)
self.force_mag = 30.0
self.tau = 0.02 # seconds between state updates
self.min_action = -1.0
self.max_action = 1.0
# Angle at which to fail the episode
self.theta_threshold_radians = 12 * 2 * math.pi / 360
self.x_threshold = 2.4
# Angle limit set to 2 * theta_threshold_radians so failing observation
# is still within bounds
high = np.array([
self.x_threshold * 2,
np.finfo(np.float32).max,
self.theta_threshold_radians * 2,
np.finfo(np.float32).max])
self.action_space = spaces.Box(
low=self.min_action,
high=self.max_action,
shape=(1,)
)
self.observation_space = spaces.Box(-high, high)
self.seed()
self.viewer = None
self.state = None
self.steps_beyond_done = None
def seed(self, seed=None):
self.np_random, seed = seeding.np_random(seed)
return [seed]
def stepPhysics(self, force):
x, x_dot, theta, theta_dot = self.state
costheta = math.cos(theta)
sintheta = math.sin(theta)
temp = (force + self.polemass_length * theta_dot * theta_dot * sintheta) / self.total_mass
thetaacc = (self.gravity * sintheta - costheta * temp) / \
(self.length * (4.0/3.0 - self.masspole * costheta * costheta / self.total_mass))
xacc = temp - self.polemass_length * thetaacc * costheta / self.total_mass
x = x + self.tau * x_dot
x_dot = x_dot + self.tau * xacc
theta = theta + self.tau * theta_dot
theta_dot = theta_dot + self.tau * thetaacc
return (x, x_dot, theta, theta_dot)
def step(self, action):
action = np.expand_dims(action, 0)
assert self.action_space.contains(action), \
"%r (%s) invalid" % (action, type(action))
# Cast action to float to strip np trappings
force = self.force_mag * float(action)
self.state = self.stepPhysics(force)
x, x_dot, theta, theta_dot = self.state
done = x < -self.x_threshold \
or x > self.x_threshold \
or theta < -self.theta_threshold_radians \
or theta > self.theta_threshold_radians
done = bool(done)
if not done:
reward = 1.0
elif self.steps_beyond_done is None:
# Pole just fell!
self.steps_beyond_done = 0
reward = 1.0
else:
if self.steps_beyond_done == 0:
gym.logger.warn("""
You are calling 'step()' even though this environment has already returned
done = True. You should always call 'reset()' once you receive 'done = True'
Any further steps are undefined behavior.
""")
self.steps_beyond_done += 1
reward = 0.0
return np.array(self.state), reward, done, {}
def reset(self):
self.state = self.np_random.uniform(low=-0.05, high=0.05, size=(4,))
self.steps_beyond_done = None
return np.array(self.state)
def render(self, mode='human'):
screen_width = 600
screen_height = 400
world_width = self.x_threshold * 2
scale = screen_width /world_width
carty = 100 # TOP OF CART
polewidth = 10.0
polelen = scale * 1.0
cartwidth = 50.0
cartheight = 30.0
if self.viewer is None:
from gym.envs.classic_control import rendering
self.viewer = rendering.Viewer(screen_width, screen_height)
l, r, t, b = -cartwidth / 2, cartwidth / 2, cartheight / 2, -cartheight / 2
axleoffset = cartheight / 4.0
cart = rendering.FilledPolygon([(l, b), (l, t), (r, t), (r, b)])
self.carttrans = rendering.Transform()
cart.add_attr(self.carttrans)
self.viewer.add_geom(cart)
l, r, t, b = -polewidth / 2, polewidth / 2, polelen-polewidth / 2, -polewidth / 2
pole = rendering.FilledPolygon([(l, b), (l, t), (r, t), (r, b)])
pole.set_color(.8, .6, .4)
self.poletrans = rendering.Transform(translation=(0, axleoffset))
pole.add_attr(self.poletrans)
pole.add_attr(self.carttrans)
self.viewer.add_geom(pole)
self.axle = rendering.make_circle(polewidth / 2)
self.axle.add_attr(self.poletrans)
self.axle.add_attr(self.carttrans)
self.axle.set_color(.5, .5, .8)
self.viewer.add_geom(self.axle)
self.track = rendering.Line((0, carty), (screen_width, carty))
self.track.set_color(0, 0, 0)
self.viewer.add_geom(self.track)
if self.state is None:
return None
x = self.state
cartx = x[0] * scale + screen_width / 2.0 # MIDDLE OF CART
self.carttrans.set_translation(cartx, carty)
self.poletrans.set_rotation(-x[2])
return self.viewer.render(return_rgb_array=(mode == 'rgb_array'))
def close(self):
if self.viewer:
self.viewer.close()
六、设置经验池
与DQN的replay_mamory.py代码一致
# replay_memory.py
import random
import collections
import numpy as np
class ReplayMemory(object):
def __init__(self, max_size):
self.buffer = collections.deque(maxlen=max_size)
def append(self, exp):
self.buffer.append(exp)
def sample(self, batch_size):
mini_batch = random.sample(self.buffer, batch_size)
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], []
for experience in mini_batch:
s, a, r, s_p, done = experience
obs_batch.append(s)
action_batch.append(a)
reward_batch.append(r)
next_obs_batch.append(s_p)
done_batch.append(done)
return np.array(obs_batch).astype('float32'), \
np.array(action_batch).astype('float32'), np.array(reward_batch).astype('float32'),\
np.array(next_obs_batch).astype('float32'), np.array(done_batch).astype('float32')
def __len__(self):
return len(self.buffer)
七、Training && Test(训练&&测试)
def run_episode(agent, env, rpm):
obs = env.reset()
total_reward = 0
steps = 0
while True:
steps += 1
batch_obs = np.expand_dims(obs, axis=0)
action = agent.predict(batch_obs.astype('float32'))
# 增加探索扰动, 输出限制在 [-1.0, 1.0] 范围内
action = np.clip(np.random.normal(action, NOISE), -1.0, 1.0)
# action 为均值(-1~1),NOISE 为方差,正态分布区值
# np.clip 限制区间,以免区值超出范围
next_obs, reward, done, info = env.step(action) # 交互一步
action = [action] # 方便存入replaymemory
rpm.append((obs, action, REWARD_SCALE * reward, next_obs, done))
if len(rpm) > MEMORY_WARMUP_SIZE and (steps % 5) == 0:
(batch_obs, batch_action, batch_reward, batch_next_obs,
batch_done) = rpm.sample(BATCH_SIZE)
agent.learn(batch_obs, batch_action, batch_reward, batch_next_obs,
batch_done)
obs = next_obs
total_reward += reward
if done or steps >= 200:
break
return total_reward
def evaluate(env, agent, render=False):
eval_reward = []
for i in range(5):
obs = env.reset()
total_reward = 0
steps = 0
while True:
batch_obs = np.expand_dims(obs, axis=0)
action = agent.predict(batch_obs.astype('float32'))
action = np.clip(action, -1.0, 1.0)
steps += 1
next_obs, reward, done, info = env.step(action)
obs = next_obs
total_reward += reward
if render:
env.render()
if done or steps >= 200:
break
eval_reward.append(total_reward)
return np.mean(eval_reward)
八、创建环境和Agent,创建经验池,启动训练,保存模型
# 创建环境
env = ContinuousCartPoleEnv()
obs_dim = env.observation_space.shape[0]
act_dim = env.action_space.shape[0]
# 使用PARL框架创建agent
model = Model(act_dim)
# model实例化
algorithm = DDPG(
model, gamma=GAMMA, tau=TAU, actor_lr=ACTOR_LR, critic_lr=CRITIC_LR)
# algorithm 实例化,传入 model
agent = Agent(algorithm, obs_dim, act_dim)
# agent 实例化,传入 algorithm
# 创建经验池
rpm = ReplayMemory(MEMORY_SIZE)
# 往经验池中预存数据
while len(rpm) < MEMORY_WARMUP_SIZE:
run_episode(agent, env, rpm)
episode = 0
while episode < TRAIN_EPISODE:
for i in range(50):
total_reward = run_episode(agent, env, rpm)
episode += 1
eval_reward = evaluate(env, agent, render=False)
logger.info('episode:{} test_reward:{}'.format(
episode, eval_reward))