理解NLP迁移学习/Transformers/GPT/Bert中遇到的难点和笔记
这篇笔记主要是我在学习这些算法的过程中,遇到难以理解的地方之后去查询资料,然后记录下了我自己的一些针对这些难点的理解,并不是对大标题中的概念进行一个基础地介绍,如果你完全没有听说过这些概念,建议先去百科一下,或者看看原文,然后如果有卡壳的地方,希望这篇笔记能帮助到你。
Seq-to-Seq model
- 以Neural Machine Translation来说,seq1的每个字依次进入encoder被encode成一个个hidden states(也可以称context——越是往后的hidden states/context,包含句子的内容越多),当最后一层hidden states被算出来,这个last hidden states就包含了seq1句子所有的context,并且被送入decoder,decoder开始output seq2的每个字,并且在decoding的过程中,不断地产生hidden states(即so far目前被decode了的所有context)。
- context vector,即最后一层的hidden layer,会比较有问题,因为没办法处理过长的句子的所有信息(毕竟要把一整个句子的含义全部encode到一个vector里),后来出现了Attention这种结构,作为弥补RNN的hidden layers的解决办法。
- Seq-to-Seq with Attentions:
1)不同于之前只把最后一层encoder生成的hidden layer递给decoder,现在encoder生成的所有的hidden layers都要递给decoder,然后让decoder自己来判断当它想翻译一个字(例如f3 -> e3)的时候,它会更多更多地参考哪个 f i , i ≠ 3 f_i, i \ne 3 fi,i=3词向量,所以decoder的第一层hidden states其实是一个weighted sum of encoder hidden states。
2)所以整个流程是:
- encoder生成所有的hidden layers, h 1 e h_1^e h1e,…, h n e h_n^e hne
- decoder接收到 < E N D >
- 然后通过 h 1 e h_1^e h1e,…, h n e h_n^e hne计算出attention vector a n + 1 d a^d_{n+1} an+1d,并把 a n + 1 d a^d_{n+1} an+1d和 h n + 1 d h_{n+1}^d hn+1d给concatenate在一起变成一个n+1时间点的context vector c n + 1 d c_{n+1}^d cn+1d
- 把 c n + 1 d c_{n+1}^d cn+1d递给feed-forward来生成n+1时刻预测的output o n + 1 d o^d_{n+1} on+1d
- decoder接收到 o n + 1 d o^d_{n+1} on+1d的词向量,和一个decoder hidden layer h n + 1 d h^d_{n+1} hn+1d,生成 h n + 2 d h_{n+2}^d hn+2d——即第2个decoder hidden context
- 然后通过 h 1 e h_1^e h1e,…, h n e h_n^e hne计算出attention vector a n + 2 d a^d_{n+2} an+2d,并把 a n + 2 d a^d_{n+2} an+2d和 h n + 2 d h_{n+2}^d hn+2d给concatenate在一起变成一个n+2时间点的context vector c n + 2 d c_{n+2}^d cn+2d
- 把 c n + 2 d c_{n+2}^d cn+2d递给feed-forward来生成n+2时刻预测的output o n + 2 d o^d_{n+2} on+2d
- Repeat
参考:
https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
Transformers
-
Transformers实质上舍弃了sequential的模型,而是通过不断地计算不同的词在同一个高维度的空间里(维度越高的空间,空间范围就越巨大)是否有关联,来建立词的概率分布。
-
Transformers相较于LSTM的好处就是能够将整个句子作为input来处理,这种优势主要体现在feed-forward layer的计算中,但self-attention layer的计算并非互相独立的,而且decoder也predicts one by one (sequentially).
-
依靠非sequential的模型来理解词与词之间的关系,相对应的downside就是失去了词的顺序这个重要的信息,意思也就是input sentence的词的顺序可以随意颠倒,也不会什么影响,所以需要额外的将词的positional information给嵌入(encode)到模型中。具体嵌入的方法有很多种,一种是直接用一个和word embedding同维度的positional encoding向量来表示词的相对位置,再用向量加法加到word embedding中,取一个比句子要长很多embedding dimension可以使模型无压力地generate sentence longer than what’s in training.
-
计算self-attention的过程:
- self-attention:It is a layer that helps encoder/decoder to look at other words in the input sentence as it encodes/decodes a specific word. 其中self是相对于decoder block中的encoder-decoder-attention layer的,即self-attention是encoder-encoder或者decoder-decoder的。
- Q,K,V分别是E和三个不同的W matrix相乘之后得到的vector(类似于projection of input(here it is Embedding) in a different dimension - usually a smaller dimension-subspace),其中Q是在比较的过程中用来代表本身,K用来和其它的词比较,Q和所有词的K一起相乘得出softMax(scores),V是用来往下一步传送的本身(当然要被scores weighted之后),最后再把V*scores的vector给element-wise的sum起来,就是self-attention score了(in lower dimension form as well)。

- Multi-headed self-attention:然而z1涵盖其它词的程度还不够,以至于在训练中词i还是很容易收到其本身的影响更多一点,所以transformers的结构中用了8个这样的Q/K/V组合来尽可能代表多一点subspace的信息(不同的attention head会focus on不同的词),最后再把这8个Z matrix给concat起来,linear transform的reshape一下,得出最终的一个Z matrix喂给FF。
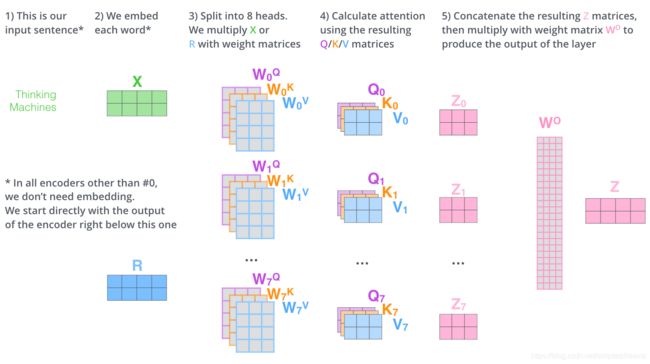
-
Transformers也是有加residual的,如LayerNorm()里的X,因为Z已经是对原文的多重抽象了,为了更稳定的训练模型(避免模型一开始一直learn from noise),所以有必要加上residual X。decoder也是同理(所有normalize layer都是)。
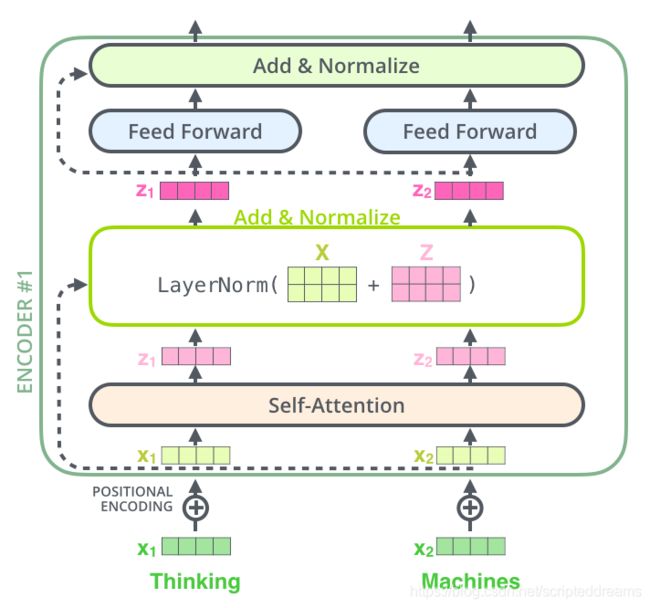
-
不同于encoder, which takes in all input words at once, Decoder sequentially makes prediction, because it is simply impossible to USE the next word when the decoder’s current task is to predict it. 所以To make sequential predictions, what decoder does is to mask all the subsequent positions while computing attentions and softmax. 这也是Decoder大大区别与Encoder的地方,即Decoder需要使用到Mask来进行sequential predictions.
-
minor note: even though the feed-forward layer is able to take the whole sentence as an input and do parallelly computation,
-
beam search: greedy algorithm but with multiple good top candidates.
参考:
http://jalammar.github.io/illustrated-transformer/
Transfer Learning的尝试:ELMo和OpenAI GPT
- Transfer learning:即提前训练好的模型参数,我直接借过来,接上我需要解决的task(whether it is classification, sequence generation, translation or whatever)。由于训练好的不同layers的模型参数本身就包含了对语言的结构、单词意思的理解,所以训练个很少的epochs (say <10)就能使我当下的task有不错的performance,而且甚至不需要很大的训练集,真是省时省力。
- Feature-based Transfer Learning: ELMo:
特征一,task-specific architecture,翻译一下意思就是需要根据当下的task设计模型的结构,所以不同的任务,模型结构也不同,那么既然模型结构不同,那么模型参数大部分时候都必须从random开始训练起(也存在模型结构完全一致的情况下可以使用预训练好的模型参数的case,但是需要比较巧);
特征二,pre-trained representations,翻译一下就是,这个被transfer了的learning是在input embeddings中体现出来的,即利用训练好的双层BiLSTM的参数重组的input embedding来include context from training sentence。
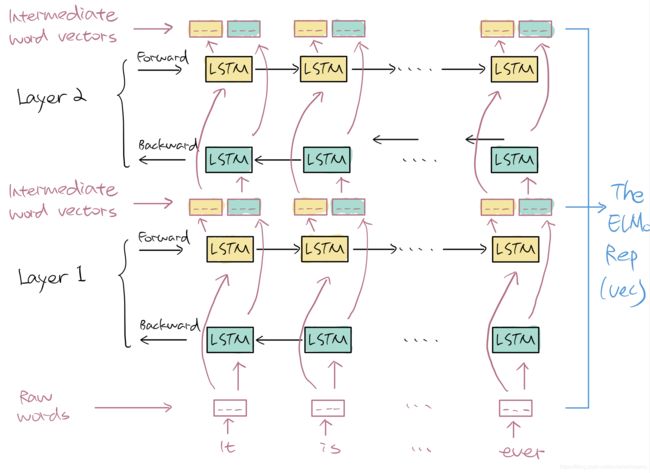
- Fine-tuning based Transfer Learning: OpenAI GPT:
特征一:和ELMo(用LSTM)不同,GPT用的是Transformers里的decoder,模型结构是12层decoders被stack起来。为什么用decoder呢,因为decoder会把未出现的词给mask起来,做到sequential prediction,在实现language modeling的时候很方便(即根据现有的词预测下一个词,使模型能够更好的理解语料库)
特征二:这个decoders stack的参数可不是randomly initialized了哦,而是预训练过的!所以只需要做一些fine-tune(原文)就可以了,那啥是fine-tune呢?其实就是只需要对模型参数进行很少的训练(say <10 epochs)即可以有不错的performance了。那fine-tune的过程是非常有技巧的,主要是利用discriminative pre-training,例如第一个epoch,我把模型参数给freeze,只训练input embeddings,第2-4个epoch,我再把第一层decoder的参数给unfreeze,把embedding给freeze了,只训练第一层decoder,第5-8个epoch,再把2-7层的decoders的参数给unfreeze了,只训练1-7层decoder,so on and so forth, pick your settings!
Bert
-
Bert looked at ELMo and GPT and was like, you guys did great, but things can get better (假笑.jpg).ELMo和GPT的问题就是没能利用到bi-directional context,GPT没用到很好理解,毕竟decoder把backward方向的context舍弃了(mask掉了),但ELMo用的可是bi-directional LSTM,怎么能说是uni-directional呢?实际上,ELMo在训练过程中,确实是使用了BiLSTM,但forward和backward是两套参数,独立训练好了再被concat起来,所以参数本身还是uni-directional的(你品,你细品)。
-
介绍了前面这么多前辈,只是想表达,Bert本身是在它们的基础上改进的,所以可见搞research,妄想一篇paper解决一个课题是很困难的(不是不可能啦),但大部分时候真的是一波researcher接着一波researcher,往往需要花费好几年的迭代,接力式地完成一个课题……扯远了,Bert还是类似于fine-tuning based appraoch,即先pre-trained模型(好几层的encoders stack),然后再接上后续的任务来fine-tune其参数。
-
Bert(Bidirectional Encoder Representation from Transformers)的利用方式:
- bidirectional contextualized word embeddings的实现方法:mask out 15% of the words in a sentence and train stack of Transformer encoders to predict the masked word based on the context. The task is basically unlabeled, because the model is not asked to fully recover the original sentence, meaning it’s good enough that the prediction is likely/natural. So the loss function is designed to measure how well BERT can predict the missing word, not reconstruction error. Then the loss gets backpropagated to the word embeddings, thus giving it more contextual information.
- 前后句[CLS]分类:因为论文当时出的时候是针对QA的任务,所以他们还在training input的开头加入了一个[CLS]特殊token,来判断training input里的两个句子是否是valid的前后句关系
- 总的来说,BERT可以接上大部分的NLP任务,只需要对stack of encoders的输出进行一些linear transformation,将那些hidden states转换成任务所需要的shape,并对参数进行一些fine-tune,基本上就是一个完整的结构。
参考:
https://medium.com/@jonathan_hui/nlp-bert-transformer-7f0ac397f524
https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html