






 评论:
评论:

在 IBM Bluemix 云平台上开发并部署您的下一个应用。
开始您的试用
ftrace 简介
ftrace 的作用是帮助开发人员了解 Linux 内核的运行时行为,以便进行故障调试或性能分析。
最早 ftrace 是一个 function tracer,仅能够记录内核的函数调用流程。如今 ftrace 已经成为一个 framework,采用 plugin 的方式支持开发人员添加更多种类的 trace 功能。
Ftrace 由 RedHat 的 Steve Rostedt 负责维护。到 2.6.30 为止,已经支持的 tracer 包括:
Function tracer 和 Function graph tracer: 跟踪函数调用。
Schedule switch tracer: 跟踪进程调度情况。
Wakeup tracer:跟踪进程的调度延迟,即高优先级进程从进入 ready 状态到获得 CPU 的延迟时间。该 tracer 只针对实时进程。
Irqsoff tracer:当中断被禁止时,系统无法相应外部事件,比如键盘和鼠标,时钟也无法产生 tick 中断。这意味着系统响应延迟,irqsoff 这个 tracer 能够跟踪并记录内核中哪些函数禁止了中断,对于其中中断禁止时间最长的,irqsoff 将在 log 文件的第一行标示出来,从而使开发人员可以迅速定位造成响应延迟的罪魁祸首。
Preemptoff tracer:和前一个 tracer 类似,preemptoff tracer 跟踪并记录禁止内核抢占的函数,并清晰地显示出禁止抢占时间最长的内核函数。
Preemptirqsoff tracer: 同上,跟踪和记录禁止中断或者禁止抢占的内核函数,以及禁止时间最长的函数。
Branch tracer: 跟踪内核程序中的 likely/unlikely 分支预测命中率情况。 Branch tracer 能够记录这些分支语句有多少次预测成功。从而为优化程序提供线索。
Hardware branch tracer:利用处理器的分支跟踪能力,实现硬件级别的指令跳转记录。在 x86 上,主要利用了 BTS 这个特性。
Initcall tracer:记录系统在 boot 阶段所调用的 init call 。
Mmiotrace tracer:记录 memory map IO 的相关信息。
Power tracer:记录系统电源管理相关的信息。
Sysprof tracer:缺省情况下,sysprof tracer 每隔 1 msec 对内核进行一次采样,记录函数调用和堆栈信息。
Kernel memory tracer: 内存 tracer 主要用来跟踪 slab allocator 的分配情况。包括 kfree,kmem_cache_alloc 等 API 的调用情况,用户程序可以根据 tracer 收集到的信息分析内部碎片情况,找出内存分配最频繁的代码片断,等等。
Workqueue statistical tracer:这是一个 statistic tracer,统计系统中所有的 workqueue 的工作情况,比如有多少个 work 被插入 workqueue,多少个已经被执行等。开发人员可以以此来决定具体的 workqueue 实现,比如是使用 single threaded workqueue 还是 per cpu workqueue.
Event tracer: 跟踪系统事件,比如 timer,系统调用,中断等。
这里还没有列出所有的 tracer,ftrace 是目前非常活跃的开发领域,新的 tracer 将不断被加入内核。
回页首
ftrace 与其他 trace 工具的关系和比较
Ftrace 最初是在 2.6.27 中出现的,那个时候,systemTap 已经开始崭露头角,其他的 trace 工具包括 LTTng 等也已经发展多年。那为什么人们还要再开发一个 trace 工具呢?
SystemTap 项目是 Linux 社区对 SUN Dtrace 的反应,目标是达到甚至超越 Dtrace 。因此 SystemTap 设计比较复杂,Dtrace 作为 SUN 公司的一个项目开发了多年才最终稳定发布,况且得到了 Solaris 内核中每个子系统开发人员的大力支持。 SystemTap 想要赶超 Dtrace,困难不仅是一样,而且更大,因此她始终处在不断完善自身的状态下,在真正的产品环境,人们依然无法放心的使用她。不当的使用和 SystemTap 自身的不完善都有可能导致系统崩溃。
Ftrace 的设计目标简单,本质上是一种静态代码插装技术,不需要支持某种编程接口让用户自定义 trace 行为。静态代码插装技术更加可靠,不会因为用户的不当使用而导致内核崩溃。 ftrace 代码量很小,稳定可靠。实际上,即使是 Dtrace,大多数用户也只使用其静态 trace 功能。因此 ftrace 的设计非常务实。
从 2.6.30 开始,ftrace 支持 event tracer,其实现和功能与 LTTng 非常类似,或许将来 ftrace 会同 LTTng 进一步融合,各自取长补短。 ftrace 有定义良好的 ASCII 接口,可以直接阅读,这对于内核开发人员非常具有吸引力,因为只需内核代码加上 cat 命令就可以工作了,相当方便; LTTng 则采用 binary 接口,更利于专门工具分析使用。此外他们内部 ring buffer 的实现不相同,ftrace 对所有 tracer 都采用同一个 ring buffer,而 LTTng 则使用各自不同的 ring buffer 。
目前,或许将来 LTTng 都只能是内核主分支之外的工具。她主要受到嵌入式工程师的欢迎,而内核开发人员则更喜欢 ftrace 。
Ftrace 的实现依赖于其他很多内核特性,比如 tracepoint[3],debugfs[2],kprobe[4],IRQ-Flags[5] 等。限于篇幅,关于这些技术的介绍请读者自行查阅相关的参考资料。
回页首
ftrace 的使用
ftrace 在内核态工作,用户通过 debugfs 接口来控制和使用 ftrace 。从 2.6.30 开始,ftrace 支持两大类 tracer:传统 tracer 和 Non-Tracer Tracer 。下面将分别介绍他们的使用。
传统 Tracer 的使用
使用传统的 ftrace 需要如下几个步骤:
- 选择一种 tracer
- 使能 ftrace
- 执行需要 trace 的应用程序,比如需要跟踪 ls,就执行 ls
- 关闭 ftrace
- 查看 trace 文件
用户通过读写 debugfs 文件系统中的控制文件完成上述步骤。使用 debugfs,首先要挂载她。命令如下:
# mkdir /debug # mount -t debugfs nodev /debug
此时您将在 /debug 目录下看到 tracing 目录。 Ftrace 的控制接口就是该目录下的文件。
选择 tracer 的控制文件叫作 current_tracer 。选择 tracer 就是将 tracer 的名字写入这个文件,比如,用户打算使用 function tracer,可输入如下命令:
#echo ftrace > /debug/tracing/current_tracer
文件 tracing_enabled 控制 ftrace 的开始和结束。
#echo 1 >/debug/tracing/tracing_enable
上面的命令使能 ftrace 。同样,将 0 写入 tracing_enable 文件便可以停止 ftrace 。
ftrace 的输出信息主要保存在 3 个文件中。
- Trace,该文件保存 ftrace 的输出信息,其内容可以直接阅读。
- latency_trace,保存与 trace 相同的信息,不过组织方式略有不同。主要为了用户能方便地分析系统中有关延迟的信息。
- trace_pipe 是一个管道文件,主要为了方便应用程序读取 trace 内容。算是扩展接口吧。
下面详细解析各种 tracer 的输出信息。
Function tracer 的输出
Function tracer 跟踪函数调用流程,其 trace 文件格式如下:
# tracer: function # # TASK-PID CPU# TIMESTAMP FUNCTION # | | | | | bash-4251 [01] 10152.583854: path_put <-path_walk bash-4251 [01] 10152.583855: dput <-path_put bash-4251 [01] 10152.583855: _atomic_dec_and_lock <-dput
可以看到,tracer 文件类似一张报表,前 4 行是表头。第一行显示当前 tracer 的类型。第三行是 header 。
对于 function tracer,该表将显示 4 列信息。首先是进程信息,包括进程名和 PID ;第二列是 CPU,在 SMP 体系下,该列显示内核函数具体在哪一个 CPU 上执行;第三列是时间戳;第四列是函数信息,缺省情况下,这里将显示内核函数名以及它的上一层调用函数。
通过对这张报表的解读,用户便可以获得完整的内核运行时流程。这对于理解内核代码也有很大的帮助。有志于精读内核代码的读者,或许可以考虑考虑 ftrace 。
如上例所示,path_walk() 调用了 path_put 。此后 path_put 又调用了 dput,进而 dput 再调用 _atomic_dec_and_lock 。
Schedule switch tracer 的输出
Schedule switch tracer 记录系统中的进程切换信息。在其输出文件 trace 中 , 输出行的格式有两种:
第一种表示进程切换信息:
Context switches:
Previous task Next Task
:: ==> ::
第二种表示进程 wakeup 的信息:
Wake ups:
Current task Task waking up
:: + ::
这里举一个实例:
# tracer: sched_switch # # TASK_PID CPU# TIMESTAMP FUNCTION # | | | | fon-6263 [000] 4154504638.932214: 6263:120:R + 2717:120:S fon-6263 [000] 4154504638.932214: 6263:120:? ==> 2717:120:R bash-2717 [000] 4154504638.932214: 2717:120:S + 2714:120:S
第一行表示进程 fon 进程 wakeup 了 bash 进程。其中 fon 进程的 pid 为 6263,优先级为 120,进程状态为 Ready 。她将进程 ID 为 2717 的 bash 进程唤醒。
第二行表示进程切换发生,从 fon 切换到 bash 。
irqsoff tracer 输出
有四个 tracer 记录内核在某种状态下最长的时延,irqsoff 记录系统在哪里关中断的时间最长; preemptoff/preemptirqsoff 以及 wakeup 分别记录禁止抢占时间最长的函数,或者系统在哪里调度延迟最长 (wakeup) 。这些 tracer 信息对于实时应用具有很高的参考价值。
为了更好的表示延迟,ftrace 提供了和 trace 类似的 latency_trace 文件。以 irqsoff 为例演示如何解读该文件的内容。
# tracer: irqsoff
irqsoff latency trace v1.1.5 on 2.6.26
--------------------------------------------------------------------
latency: 12 us, #3/3, CPU#1 | (M:preempt VP:0, KP:0, SP:0 HP:0 #P:2)
-----------------
| task: bash-3730 (uid:0 nice:0 policy:0 rt_prio:0)
-----------------
=> started at: sys_setpgid
=> ended at: sys_setpgid
# _------=> CPU#
# / _-----=> irqs-off
# | / _----=> need-resched
# || / _---=> hardirq/softirq
# ||| / _--=> preempt-depth
# |||| /
# ||||| delay
# cmd pid ||||| time | caller
# \ / ||||| \ | /
bash-3730 1d... 0us : _write_lock_irq (sys_setpgid)
bash-3730 1d..1 1us+: _write_unlock_irq (sys_setpgid)
bash-3730 1d..2 14us : trace_hardirqs_on (sys_setpgid)
在文件的头部,irqsoff tracer 记录了中断禁止时间最长的函数。在本例中,函数 trace_hardirqs_on 将中断禁止了 12us 。
文件中的每一行代表一次函数调用。 Cmd 代表进程名,pid 是进程 ID 。中间有 5 个字符,分别代表了 CPU#,irqs-off 等信息,具体含义如下:
CPU# 表示 CPU ID ;
irqs-off 这个字符的含义如下:’ d ’表示中断被 disabled 。’ . ’表示中断没有关闭;
need-resched 字符的含义:’ N ’表示 need_resched 被设置,’ . ’表示 need-reched 没有被设置,中断返回不会进行进程切换;
hardirq/softirq 字符的含义 : 'H' 在 softirq 中发生了硬件中断, 'h' – 硬件中断,’ s ’表示 softirq,’ . ’不在中断上下文中,普通状态。
preempt-depth: 当抢占中断使能后,该域代表 preempt_disabled 的级别。
在每一行的中间,还有两个域:time 和 delay 。 time: 表示从 trace 开始到当前的相对时间。 Delay 突出显示那些有高延迟的地方以便引起用户注意。当其显示为 ! 时,表示需要引起注意。
function graph tracer 输出
Function graph tracer 和 function tracer 类似,但输出为函数调用图,更加容易阅读:
# tracer: function_graph
#
# CPU OVERHEAD/DURATION FUNCTION CALLS
# | | | | | | |
0) | sys_open() {
0) | do_sys_open() {
0) | getname() {
0) | kmem_cache_alloc() {
0) 1.382 us | __might_sleep();
0) 2.478 us | }
0) | strncpy_from_user() {
0) | might_fault() {
0) 1.389 us | __might_sleep();
0) 2.553 us | }
0) 3.807 us | }
0) 7.876 us | }
0) | alloc_fd() {
0) 0.668 us | _spin_lock();
0) 0.570 us | expand_files();
0) 0.586 us | _spin_unlock();
OVERHEAD 为 ! 时提醒用户注意,该函数的性能比较差。上面的例子中可以看到 sys_open 调用了 do_sys_open,依次又调用了 getname(),依此类推。
Sysprof tracer 的输出
Sysprof tracer 定时对内核进行采样,她的输出文件中记录了每次采样时内核正在执行哪些内核函数,以及当时的内核堆栈情况。
每一行前半部分的格式和 3.1.1 中介绍的 function tracer 一样,只是,最后一部分 FUNCTION 有所不同。
Sysprof tracer 中,FUNCTION 列格式如下:
Identifier address frame_pointer/pid
当 identifier 为 0 时,代表一次采样的开始,此时第三个数字代表当前进程的 PID ;
Identifier 为 1 代表内核态的堆栈信息;当 identifier 为 2 时,代表用户态堆栈信息;显示堆栈信息时,第三列显示的是 frame_pointer,用户可能需要打开 system map 文件查找具体的符号,这是 ftrace 有待改进的一个地方吧。
当 identifier 为 3 时,代表一次采样结束。
Non-Tracer Tracer 的使用
从 2.6.30 开始,ftrace 还支持几种 Non-tracer tracer,所谓 Non-tracer tracer 主要包括以下几种:
- Max Stack Tracer
- Profiling (branches / unlikely / likely / Functions)
- Event tracing
和传统的 tracer 不同,Non-Tracer Tracer 并不对每个内核函数进行跟踪,而是一种类似逻辑分析仪的模式,即对系统进行采样,但似乎也不完全如此。无论怎样,这些 tracer 的使用方法和前面所介绍的 tracer 的使用稍有不同。下面我将试图描述这些 tracer 的使用方法。
Max Stack Tracer 的使用
这个 tracer 记录内核函数的堆栈使用情况,用户可以使用如下命令打开该 tracer:
# echo 1 > /proc/sys/kernel/stack_tracer_enabled
从此,ftrace 便留心记录内核函数的堆栈使用。 Max Stack Tracer 的输出在 stack_trace 文件中:
# cat /debug/tracing/stack_trace Depth Size Location (44 entries) ----- ---- -------- 0) 3088 64 update_curr+0x64/0x136 1) 3024 64 enqueue_task_fair+0x59/0x2a1 2) 2960 32 enqueue_task+0x60/0x6b 3) 2928 32 activate_task+0x27/0x30 4) 2896 80 try_to_wake_up+0x186/0x27f … 42) 80 80 sysenter_do_call+0x12/0x32
从上例中可以看到内核堆栈最满的情况如下,有 43 层函数调用,堆栈使用大小为 3088 字节。此外还可以在 Location 这列中看到整个的 calling stack 情况。这在某些情况下,可以提供额外的 debug 信息,帮助开发人员定位问题。
Branch tracer
Branch tracer 比较特殊,她有两种模式,即是传统 tracer,又实现了 profiling tracer 模式。
作为传统 tracer 。其输出文件为 trace,格式如下:
# tracer: branch # # TASK-PID CPU# TIMESTAMP FUNCTION # | | | | | Xorg-2491 [000] 688.561593: [ ok ] fput_light:file.h:29 Xorg-2491 [000] 688.561594: [ ok ] fput_light:file_table.c:330
在 FUNCTION 列中,显示了 4 类信息:
函数名,文件和行号,用中括号引起来的部分,显示了分支的信息,假如该字符串为 ok,表明 likely/unlikely 返回为真,否则字符串为 MISS 。举例来说,在文件 file.h 的第 29 行,函数 fput_light 中,有一个 likely 分支在运行时解析为真。我们看看 file.h 的第 29 行:
static inline void fput_light(struct file *file, int fput_needed)
{LINE29: if (unlikely(fput_needed))
fput(file);
}
Trace 结果告诉我们,在 688 秒的时候,第 29 行代码被执行,且预测结果为 ok,即 unlikely 成功。
Branch tracer 作为 profiling tracer 时,其输出文件为 profile_annotated_branch,其中记录了 likely/unlikely 语句完整的统计结果。
#cat trace_stat/branch_ annotated correct incorrect % function file line ------- ---------- ---- ------------------ -------------- ----- 0 46 100 pre_schedule_rt sched_rt.c 1449
下面是文件 sched_rt.c 的第 1449 行的代码:
if (unlikely(rt_task(prev)) && rq->rt.highest_prio.curr > prev->prio)
pull_rt_task(rq);
记录表明,unlikely 在这里有 46 次为假,命中率为 100% 。假如为真的次数更多,则说明这里应该改成 likely 。
Workqueue profiling
假如您在内核编译时选中该 tracer,ftrace 便会统计 workqueue 使用情况。您只需使用下面的命令查看结果即可:
#cat /debug/tracing/trace_stat/workqueue
典型输出如下:
# CPU INSERTED EXECUTED NAME # | | | | 0 38044 38044 events/0 0 426 426 khelper 0 9853 9853 kblockd/0 0 0 0 kacpid …
可以看到 workqueue events 在 CPU 0 上有 38044 个 worker 被插入并执行。
Event tracer
Event tracer 不间断地记录内核中的重要事件。用户可以用下面的命令查看 ftrace 支持的事件。
#cat /debug/tracing/available_event
下面以跟踪进程切换为例讲述 event tracer 的使用。首先打开 event tracer,并记录进程切换:
# echo sched:sched_switch >> /debug/tracing/set_event # echo sched_switch >> /debug/tracing/set_event # echo 1 > /debug/tracing/events/sched/sched_switch/enable
上面三个命令的作用是一样的,您可以任选一种。
此时可以查看 ftrace 的输出文件 trace:
>head trace # tracer: nop # # TASK-PID CPU# TIMESTAMP FUNCTION # | | | | |-0 [000] 12093.091053: sched_switch: task swapper:0 [140] ==> /user/bin/sealer:2612 [120]
我想您会发现该文件很容易解读。如上例,表示一个进程切换 event,从 idle 进程切换到 sealer 进程。
回页首
ftrace 的实现
研究 tracer 的实现是非常有乐趣的。理解 ftrace 的实现能够启发我们在自己的系统中设计更好的 trace 功能。
ftrace 的整体构架
Ftrace 的整体构架:
图 1. ftrace 组成
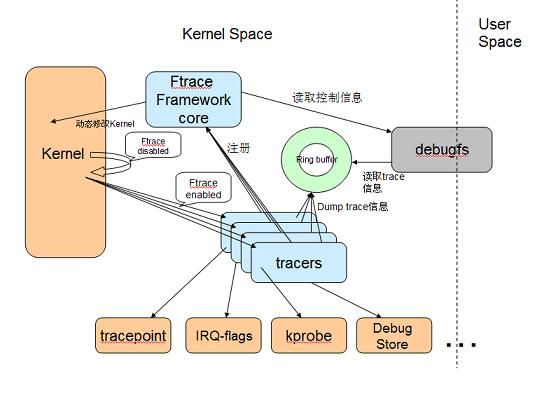
Ftrace 有两大组成部分,一是 framework,另外就是一系列的 tracer 。每个 tracer 完成不同的功能,它们统一由 framework 管理。 ftrace 的 trace 信息保存在 ring buffer 中,由 framework 负责管理。 Framework 利用 debugfs 系统在 /debugfs 下建立 tracing 目录,并提供了一系列的控制文件。
本文并不打算系统介绍 tracer 和 ftrace framework 之间的接口,只是打算从纯粹理论的角度,简单剖析几种具体 tracer 的实现原理。假如读者需要开发新的 tracer,可以参考某个 tracer 的源代码。
Function tracer 的实现
Ftrace 采用 GCC 的 profile 特性在所有内核函数的开始部分加入一段 stub 代码,ftrace 重载这段代码来实现 trace 功能。
gcc 的 -pg 选项将在每个函数入口处加入对 mcount 的调用代码。比如下面的 C 代码。
清单 1. test.c
//test.c
void foo(void)
{
printf( “ foo ” );
}
用 gcc 编译:
gcc – S test.c
反汇编如下:
清单 2. test.c 不加入 pg 选项的汇编代码
_foo:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
movl $LC0, (%esp)
call _printf
leave
ret
再加入 -gp 选项编译:
gcc – pg – S test.c
得到的汇编如下:
清单 3. test.c 加入 pg 选项后的汇编代码
_foo:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
LP3:
movl $LP3,%edx
call _mcount
movl $LC0, (%esp)
call _printf
leave
ret
增加 pg 选项后,gcc 在函数 foo 的入口处加入了对 mcount 的调用:call _mcount 。原本 mcount 由 libc 实现,但您知道内核不会连接 libc 库,因此 ftrace 编写了自己的 mcount stub 函数,并借此实现 trace 功能。
在每个内核函数入口加入 trace 代码,必然会影响内核的性能,为了减小对内核性能的影响,ftrace 支持动态 trace 功能。
当 CONFIG_DYNAMIC_FTRACE 被选中后,内核编译时会调用一个 perl 脚本:recordmcount.pl 将每个函数的地址写入一个特殊的段:__mcount_loc
在内核初始化的初期,ftrace 查询 __mcount_loc 段,得到每个函数的入口地址,并将 mcount 替换为 nop 指令。这样在默认情况下,ftrace 不会对内核性能产生影响。
当用户打开 ftrace 功能时,ftrace 将这些 nop 指令动态替换为 ftrace_caller,该函数将调用用户注册的 trace 函数。其具体的实现在相应 arch 的汇编代码中,以 x86 为例,在 entry_32.s 中:
清单 4. entry_32.s
ENTRY(ftrace_caller)
cmpl $0, function_trace_stop
jne ftrace_stub
pushl %eax
pushl %ecx
pushl %edx
movl 0xc(%esp), %eax
movl 0x4(%ebp), %edx
subl $MCOUNT_INSN_SIZE, %eax
.globl ftrace_call
ftrace_call:
call ftrace_stubline 10popl %edx
popl %ecx
popl %eax
.globl ftrace_stub
ftrace_stub:
ret
END(ftrace_caller)
Function tracer 将 line10 这行代码替换为 function_trace_call() 。这样每个内核函数都将调用 function_trace_call() 。
在 function_trace_call() 函数内,ftrace 记录函数调用堆栈信息,并将结果写入 ring buffer,稍后,用户可以通过 debugfs 的 trace 文件读取该 ring buffer 中的内容。
Irqsoff tracer 的实现
Irqsoff tracer 的实现依赖于 IRQ-Flags 。 IRQ-Flags 是 Ingo Molnar 维护的一个内核特性。使得用户能够在中断关闭和打开时得到通知,ftrace 重载了其通知函数,从而能够记录中断禁止时间。即,中断被关闭时,记录下当时的时间戳。此后,中断被打开时,再计算时间差,由此便可得到中断禁止时间。
IRQ-Flags 封装开关中断的宏定义:
清单 5. IRQ-Flags 中断代码
#define local_irq_enable() \
do { trace_hardirqs_on (); raw_local_irq_enable(); } while (0)
ftrace 在文件 ftrace_irqsoff.c 中重载了 trace_hardirqs_on 。具体代码不再罗列,主要是使用了 sched_clock()函数来获得时间戳。
hw-branch 的实现
Hw-branch 只在 IA 处理器上实现,依赖于 x86 的 BTS 功能。 BTS 将 CPU 实际执行到的分支指令的相关信息保存下来,即每个分支指令的源地址和目标地址。
软件可以指定一块 buffer,处理器将每个分支指令的执行情况写入这块 buffer,之后,软件便可以分析这块 buffer 中的功能。
Linux 内核的 DS 模块封装了 x86 的 BTS 功能。 Debug Support 模块封装了和底层硬件的接口,主要支持两种功能:Branch trace store(BTS) 和 precise-event based sampling (PEBS) 。 ftrace 主要使用了 BTS 功能。
branch tracer 的实现
内核代码中常使用 likely 和 unlikely 提高编译器生成的代码质量。 Gcc 可以通过合理安排汇编代码最大限度的利用处理器的流水线。合理的预测是 likely 能够提高性能的关键,ftrace 为此定义了 branch tracer,跟踪程序中 likely 预测的正确率。
为了实现 branch tracer,重新定义了 likely 和 unlikely 。具体的代码在 compiler.h 中。
清单 6. likely/unlikely 的 trace 实现
# ifndef likely # define likely(x) (__builtin_constant_p(x) ? !!(x) : __branch_check__(x, 1)) # endif # ifndef unlikely # define unlikely(x) (__builtin_constant_p(x) ? !!(x) : __branch_check__(x, 0)) # endif
其中 __branch_check 的实现如下:
清单 7. _branch_check_ 的实现
#define __branch_check__(x, expect) ({\
int ______r; \
static struct ftrace_branch_data \
__attribute__((__aligned__(4))) \
__attribute__((section("_ftrace_annotated_branch"))) \
______f = { \
.func = __func__, \
.file = __FILE__, \
.line = __LINE__, \
}; \
______r = likely_notrace(x);\
ftrace_likely_update(&______f, ______r, expect); \
______r; \
})
ftrace_likely_update() 将记录 likely 判断的正确性,并将结果保存在 ring buffer 中,之后用户可以通过 ftrace 的 debugfs 接口读取分支预测的相关信息。从而调整程序代码,优化性能。
回页首
总结
本文讲解了 ftrace 的基本使用。在实践中,ftrace 是一个非常有效的性能调优和 debug 分析工具,每个人使用她的方法和角度都不相同,一定有很多 best practice,这非本文所能涉及。但希望通过本文的讲解,能让读者对 ftrace 形成一个基本的了解,进而在具体工作中使用她。