linux性能工具--ftrace框架
对于ftrace架构,主要来了解下内核是如何实现的,其主要包括如下内容:
- ring buffer的原理和代码分析
- tracer(function、function_graph、irq_off)原理和代码分析
- trace event
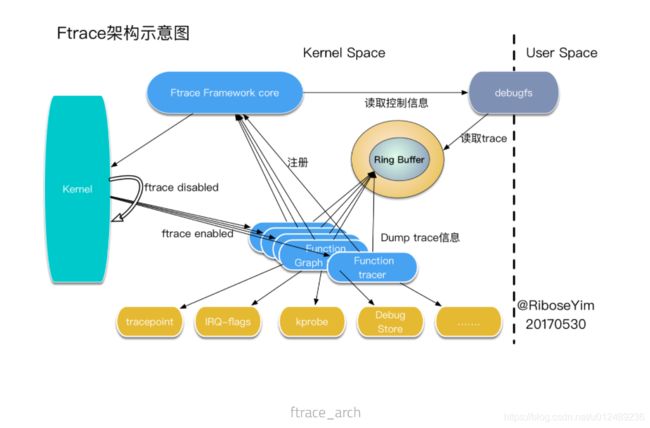
1. ring Buffer
Ringbuffer是trace32框架的一个基础,所有的trace原始数据都是通过Ring Buffer记录的,其主要有以下几个作用:
- 存储在内存中,速度非常快,对系统的性能影响降到最低的水平
- ring结构,可以循环写,安全而不浪费内存空间,能够get到最新的trace信息
对于系统,真正的难点在于系统在各种复杂的场景下,例如常规的上下文、中断上下文(NMI/IRQ/SOFTIRQ)等都能很好的trace,如何保证既不影响系统的逻辑,又能处理好相互之间的关系,同时又不影响系统的性能。
1.1 Ring buffer设计思路
对于Ring Buffer面临的最大问题
- 当我们使用trace工具的时候,可能处在不同的上下文中执行,对Ring Buffer的访问时随时可能被打断的,所以需要对Ring Buffer的访问时需要互斥保护的
- RingBuffer不能使用常规的lock操作,这样会使不同的上下文之间出现大量的阻塞操作,产生了大量的耦合逻辑,影响程序原理的逻辑和性能
如何解决这些问题呢?首先从Ring Buffer使用的方式来看,工作模式,对于该模式,是一个很典型的生产者和消费者,其主要分为
- Producer/Consumer模式: 有不断的数据写入到Ring Buffer,是一个写入者;同时对于用户也不断的从RingBuffer中读取数据,在生产者已经把Ring Buffer空间写满的情况下,如果没有消费者来读取数据,没有Free空间,那么生产者就会停止写入丢弃新的数据
- Overwrite模式: 在生产者已经把Ring Buffer空间写满的情况下,如果没有消费者来读数据free空间,生产者会覆盖写入,最老的数据会被覆盖;
其次,从架构图中,我们面对有很多的写者,对于同一个per cpu的RingBuffer,其写必须满足:
- 不能同时有两个写入者在进行写操作
- 允许高优先级的写入者中断低优先级的写入者
对于读操作必须要满足:
- 读操作可以随时发生,但是同一时刻只有一个读者在工作
- 读操作和写操作可以同时发生
- 读操作不会中断写操作,但是写操作会中断读操作
- 支持两种模式的读操作:简易读,也叫iterator读,在读取时会关闭写入,且读完不会破坏数据可以重复读取,实例见"/sys/kernel/debug/tracing/trace";并行读,也叫custom读,常用于监控程序实时的进行并行读,其利用了一个reader page交换出ring buffer中的head page,避免了读写的相互阻塞,实例见"/sys/kernel/debug/tracing/trace_pipe";
1.2 代码流程和框架
对于Ringbuffer的初始化,主要是通过tracer_alloc_buffers调用到ring_buffer_alloc完成的,其主要流程如下:
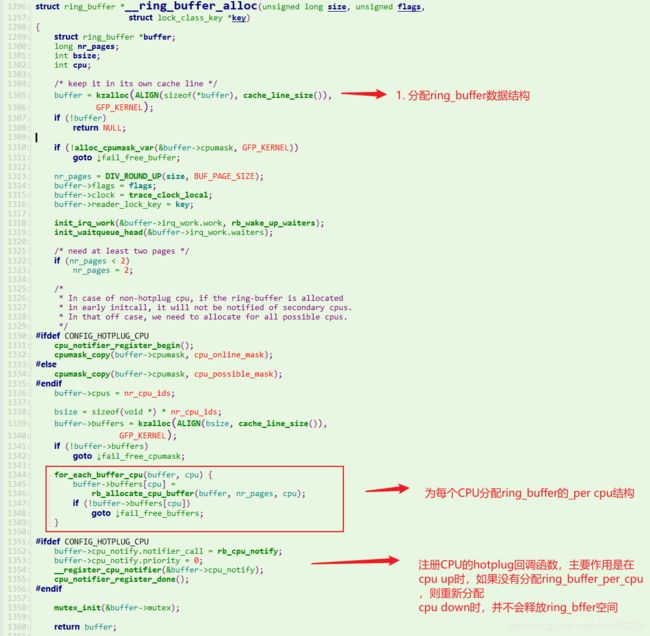
其主要数据结构图如下图所示:
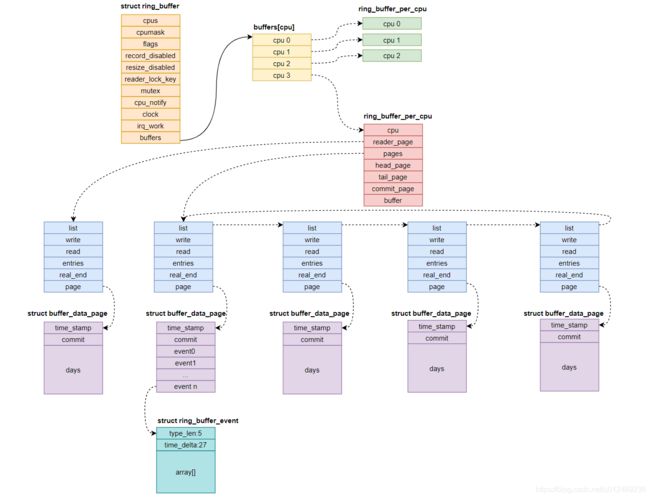
- struct ring_buffer在每个cpu上有独立的struct ring_buffer_per_cpu数据结构
- struct ring_buffer_per_cpu根据定义size的大小,分配page空间,并把page链成环形结构
- struct buffer_page是一个控制结构;struct buffer_data_page才是一个实际的page,除了开头的两个控制字段time_stamp、commit,其他空间都是用来存储数据的;数据使用struct ring_buffer_event来存储,其在包头中还存储了时间戳、长度/类型信息
- struct ring_buffer_per_cpu中使用head_page(读)、commit_page(写确认)、tail_page(写)三种指针来管理page ring;同理buffer_page->read(读)、buffer_page->write(写)、buffer_data_page->commit(写确认)用来描述page内的偏移指针
- ring_buffer_per_cpu->reader_page中还包含了一个独立的page,用来支持reader方式的读操作
2 ftrace的内核注册
对于ftrace的framwork层,首先需要建立debugfs的一系列的访问节点,是通过如下的流程完成的
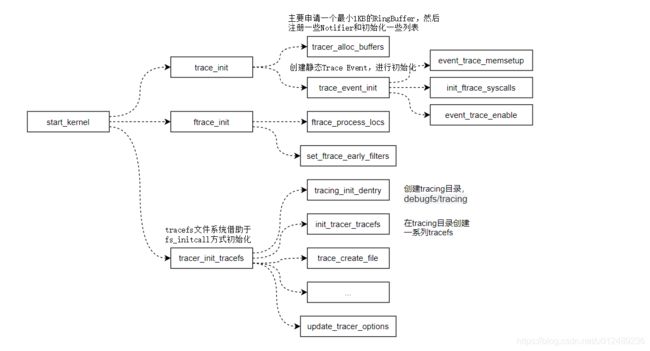
完成了核心的注册后,我们来看看ftrace是如何完成各个功能的,对于任何一个trace功能,都可以归纳于如下流程
- 函数插桩: 使用各种插桩方式把自己的trace函数插入到需要跟踪的probe point上
- Input trace数据: 在trace的probe函数中命中时,会存储数据到ring buffer当中,这里主要包括filter和tigger功能
- Output trace数据: 用户和程序需要读取trace数据,根据需要输出数据,对数据进行解析等
2.1 Function tracer的实现
这个功能是利用_mcount()函数进行插桩的,在gcc使用了"-gp“选项以后,会在每个函数入口插入以下的语句
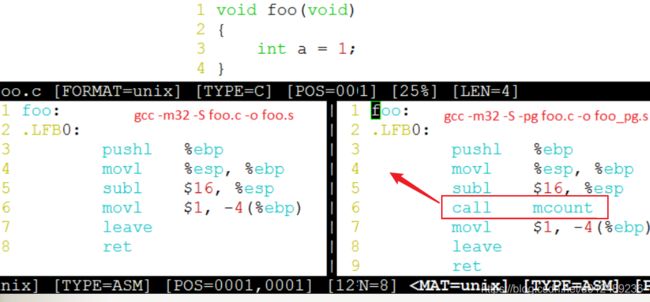
每个函数入口处插入对_mcount()函数的调用,就是gcc提供的插桩机制,我们可以重新定义_mcount()函数中的内容,调用想要执行的内容。对于tracer自身而言,是不是需要-pg选项,因此在kernel/tracing/Makefile中将-pg选项中由我们自己定义
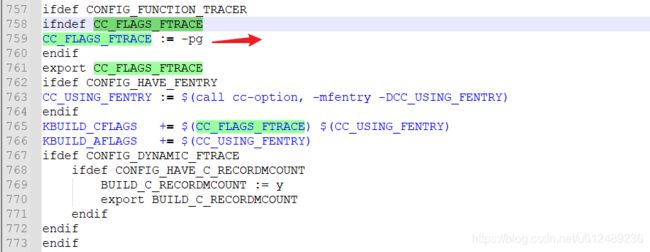
2.1.1 静态插桩
我们来看看ARM64如何处理的,其代码路径为arch/arm64/kernel/entry-ftrace.S
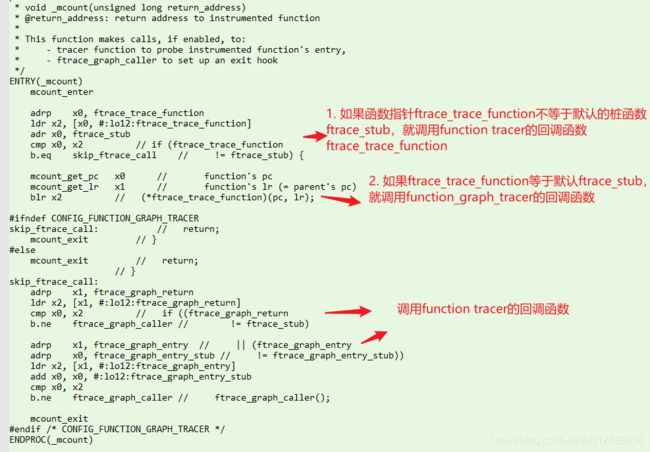
当未选中CONFIG_DYNAMIC_FTRACE时,其采用如下的方案
- 每个函数调用都会根据不同的体系结构的实现调用_mcount函数
- 如果ftrace使能了某些跟踪器,
ftrace_trace_function指针不再指向ftrace_stub,而是指向具体的跟踪函数 - 否则就执行到体系结构相关的
ftrace_stub从函数返回,而该接口为空函数

也就是说开启ftrace调用函数时,都会先调用_mcount,总是至少会执行两条指令,即使ftrace_trace_function没有被指向某个跟踪函数。
2.1.2 动态插桩
static ftrace一旦使能,对kernel中所有的函数(除开notrace、online、其他特殊函数)进行插桩,这带来的性能开销是惊人的,有可能导致人们弃用ftrace功能。
为了解决这个问题,内核开发者推出了dynamic ftrace,因为实际上调用者一般不需要对所有函数进行追踪,只会对感兴趣的一部分函数进行追踪。dynamic ftrace把不需要追踪的函数入口处指令“bl _mcount"替换成nop,这样基本上对性能无影响,对需要追踪的函数替换入口处"bl _mcount"为需要调用的函数。
- ftrace在初始化时,“scripts/recordmcount.pl”脚本记录的所有函数入口处插桩位置的“bl _mcount”,将其替换成“nop”指令,对性能基本无影响
- 在tracer enable的时,把需要跟踪的函数的插桩位置nop替换成bl ftrace_caller
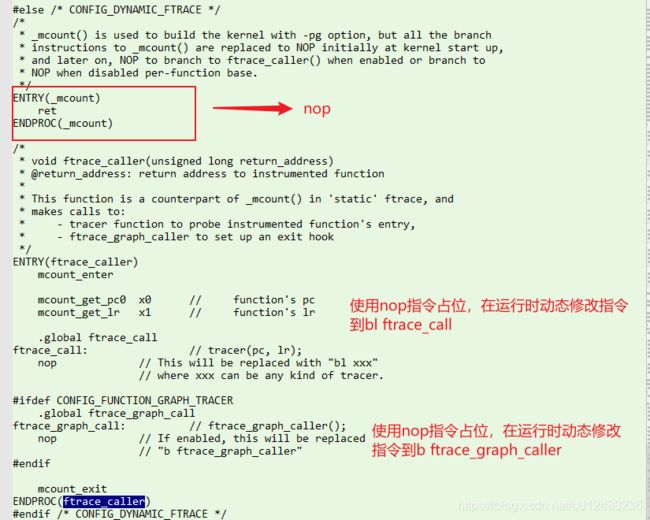
在编译的时候调用recordmcount.pl搜索所有_mcount函数调用点,并且所有的调用点地址保存到section _mcount_loc,其定义在include/asm-generic/vmlinux.lds.h,详细的见文件以具体研究“scripts/recordmcount.pl、scripts/recordmcount.c”。
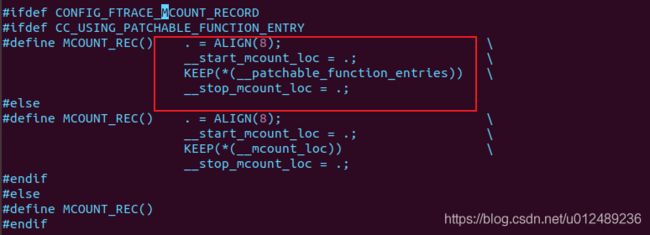
在初始化时,遍历section __mcount_loc的调用点地址,默认给所有“bl _mcount”替换成“nop”,其定义为kernel/trace/ftrace.c

2.1.3 irqs off/preempt off/preempt irqsoff tracer
- irqsoff tracer: 当中断被禁止时,系统无法响应外部事件,比如鼠标和键盘,时钟也无法产生tick中断,这也意味着系统响应延迟,irqsoff这个tracer能够跟踪并记录内核中哪些函数禁止了中断,对于其中中断禁止时间最长的,irqsoff将在Log文件中第一行标记出来,从而使开发者可以迅速定位造成响应延迟的罪魁祸首
- preemptoff tracer: 跟踪并记录禁止内核抢占并关闭中断占用期间的函数,并清晰地显示出禁止抢占时间最长的内核函数
- preempt irqsoff tracer: 跟踪和记录禁止中断或禁止抢占的内核函数,以及禁止时间最长的函数
preemptoff与irqsoff跟踪器
-
preempt off与irqs off跟踪器用的跟踪函数是相同的,都是irqsoff_tracer_call()。 -
preemptoff与irqsoff跟踪器的不同之处- irqsoff跟踪器的start点在开启或关闭中断的地方,如local_irq_disable()
- preemptoff跟踪器的start点在开启或关闭抢占的地方,如prempt_disable()

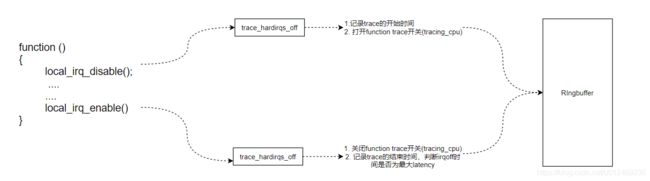
irqsoff tracer的插桩方法,是直接在local_irq_enable()、local_irq_disable()中直接插入钩子函数trace_hardirqs_on()、trace_hardirqs_off()。

我们来看看start_critical_timing的实现,其主要为:

其主要的设计思想如下
2.2 trace event
linux trace中,最基础的时function tracer和tracer event,上面学习了function,本节是学习event,其也离不开如下流程
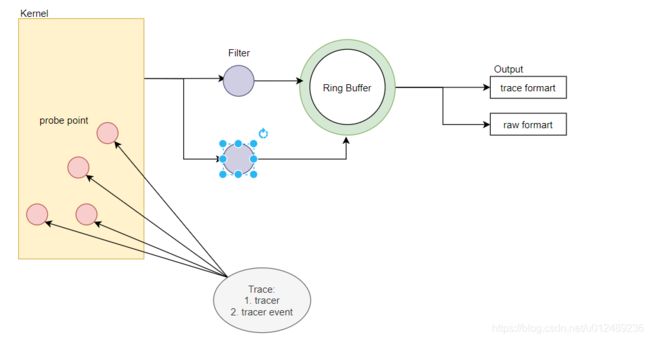
trace event的插桩使用的是tracepoint机制,该机制是一种静态的插桩方法,它需要静态的定义桩函数,并且在插桩位置显式调用。这种方法的好处是高效可靠,并且可以处于函数中的任何位置、方便的访问各种变量,坏处是不太灵活。对于kernel在重要的节点固定位置,插入了几百个trace event用于跟踪。

对于内核,我们创建了几个操作tracepoint的函数
- 桩函数: trace_##name();
- 注册回调函数: register_trace_##name();
- 注销回调函数:unregister_trace_##name();
tracepoint 的定义如下:
struct tracepoint {
const char *name; /* Tracepoint name */
struct static_key key;
void (*regfunc)(void);
void (*unregfunc)(void);
struct tracepoint_func __rcu *funcs;
};
| 成员 | 含义 |
|---|---|
| key | tracepoint是否使能开关,如果回调函数数组为空,则key为disable;如果回调函数数组中有函数指针,则key为enable |
| regfunc/unregfunc | 注册/注销回调函数时的钩子函数 |
| funcs | 回调函数数组,tracepoint的作用就是在桩函数被命中时,逐个调用回调函数数组的函数 |
我们在探测点插入桩函数:(kernl/sched/core.c)
static void __sched notrace __schedule(bool preempt)
{
...
trace_sched_switch(preempt, prev, next);
...
}
桩函数被命中时的执行流程,可以看到就是逐个的执行回调函数数组中的函数指针


可以通过 register_trace_##name()/unregister_trace_##name() 函数向回调函数数组中添加/删除函数指针

trace event 对 tracepoint 的利用,以上可以看到,tracepoint 只是一种静态插桩方法。trace event 可以使用,其他机制也可以使用,只是 kernel 的绝大部分 tracepoint 都是 trace event 在使用。
单纯的定义和使用一个 trace point,可以参考:Documentation/trace/tracepoints.txt
trace event 也必须向 tracepoint 注册自己的回调函数,这些回调函数的作用就是在函数被命中时往 ringbuffer 中写入 trace 信息。ftrace开发者们意识到了这点,所以提供了trace event功能,开发者不需要自己去注册桩函数了,易用性较好
2.2.1 增加一个新的 trace event
在现有的代码中添加探测函数,这是让很多内核开发者非常不爽的一件事,因为这可能降低性能或者让代码看起来非常臃肿。为了解决这些问题,内核最终进化出了一个 TRACE_EVENT() 来实现 trace event 的定义,这是非常简洁、智能的一个宏定义。
首先我们先来了解一下怎么样使用 TRACE_EVENT() 新增加一个 trace event,新增加 trace event,我们必须遵循规定的格式。格式可以参考:Using the TRACE_EVENT() macro (Part 1)和samples/trace_events。
以下以内核中已经存在的 event sched_switch 为例,说明定义过程。
- 首先需要在 include/trace/events/文件夹下添加一个自己 event 的头文件,需要遵循注释的标准格式:include/trace/events/sched.h
- 在探测点位置中调用桩函数,需要遵循注释的标准格式
由于内核各个子系统大量使用 event tracing 来 trace 不同的事件,每有一个需要 trace 的事件就实现这么一套函数,这样内核就会存在大量类似的重复的代码,为了避免这样的情况,内核开发者使用一个宏,让宏自动展开成具有相似性的代码。这个宏就是 TRACE_EVENT,要为某个事件添加一个 trace event,只需要声明这样一个宏就可以了
3. kprobe event
kprobe event就是这样的产物。krpobe event和trace event的功能一样,但是因为它采用的是kprobe插桩机制,所以它不需要预留插桩位置,可以动态的在任何位置进行插桩。开销会大一点,但是非常灵活,是一个非常方便的补充机制。
kprobe的主要原理是使用“断点异常”和“单步异常”两种异常指令来对任意地址进行插桩,在此基础之上实现了三种机制:
- kprobe: 可以被插入到内核的任何指令位置,在被插入指令之前调用kp.pre_handler(),在被插入指令之后调用kp.post_handler()
- jprobe: 只支持对函数进行插入
- kretprobe: 和jprobe类似,机制略有不同,会替换被探测函数的返回地址,让函数先执行插入的钩子函数,再恢复。
具体的kprobe原理可以参考:Linux kprobe(内核探针 x86)
参考文档
https://www.twblogs.net/a/5b7c4c9e2b71770a43da531e
https://blog.csdn.net/pwl999/article/details/80627095
https://www.kernel.org/doc/html/latest/trace/ftrace-design.html
Liunx ftrace中event tracing的实现原理