redis分布式实现和原理
文章目录
- 主从复制:
-
- 主从复制原理:
-
- 连接阶段:
- 数据同步节点:
- offset
- 过期key处理
- 主从复制的不足:
- 哨兵模式:
-
- raft算法(选举sentinel的leader)
- redis的master选举
- sentinel的不足
- 基于客户端的redis分片(一致性hash算法)
-
- 一致性hash算法
- 基于服务端分片-redis cluster
-
- cluster如何解决分片问题?
- 客户端重定向
- 新增或下线master节点,数据如何迁移(重新分配)
- 高可用和主从切换
- 如何发现redis的热点数据
主从复制:
redis的主从复制配置简单,只需要在配置文件里面添加一行配置就行。
例如:一主多从,186主节点,在每个slave节点中增加一行
replicaof 192.168.1.186 6379
主从复制原理:
复制有两种模式:
- 全量复制:就是一个节点第一次连接到master节点,需要全部的数据
- 增量复制:比如之前已经连接到了master节点,但是中间网络断开,或者slave节点宕机了,缺失一部分数据。
连接阶段:
slave保存master节点的信息,每隔一秒检查是否有新的master 节点需要连接和复制,如果有就建立一个文件时间处理器负责复制工作,slave节点会定时向master发送ping请求,让master感知到slave的存在。
数据同步节点:
-
第一次加入的slave
1.1 如果是新加入到的slave,就全量复制。master生成一个RDB快照,发送给slave节点。
1.2 如果slave本来有数据怎么办?slave首先会清除自己旧数据,然后用rdb加载数据master节点生成RDB期间,接受到的写命令怎么办?
master会将新的命令放入一个缓冲区里面,等到slave同步了rdb之后,然后将新命令给slave节点。1.3 第一次同步完了之后,后面master就将命令持续发的slave节点,异步复制给slave.
总结来说:第一次用RDB加载,后面mater将命令持续发给slave,实现主从复制。 -
增量复制,断点续传
slave宕机后,或者网络断开了,怎么继续同步? slave会记录一个同步数据的偏移量offset,当这个偏移量跟主节点保持一致时候,就是已经同步完成,否则就向主节点发起同步操作,知道偏移量保持一致。
无盘复制 :RDB不再借组磁盘复制,而是直接把RDB通过网络发送到slave.
offset
master会在自身不断累加offset,slave也会在自身不断累加offset
slave每秒都会上报自己的offset给master,同时master也会保存每个slave的offset。主要是master和slave都要知道各自的数据的offset,才能知道互相之间的数据不一致的情况
过期key处理
slave不会过期key,只会等待master过期key。如果master过期了一个key,或者通过LRU淘汰了一个key,那么会模拟一条del命令发送给slave。
主从复制的不足:
当主节点挂之后,slave节点是不知道的,而写命令只能再master节点,所有就写不进去报错,就不能达到高可用
哨兵模式:
sentinel本质上是运行在特殊模式之下的redis,他通过info命令得到被监控redis机器的master,slave等信息。一般会部署奇数个sentinel,他们之间没有主从之分,sentinel上线时,会自动向所有redis的_sentinel_:hello发送消息,而每个哨兵又订阅所有redis的这个_sentinel_:hello的channel,所以可以互相感知对方的存在,进而继续监控。
服务下线;
sentinel默认每秒一次向redis服务节点发送ping心跳检测,如果指定时间内没有得到回复,就标记该服务器下线,这时并不是真正下线,这个sentinel还会向其他集群的sentinel询问,确认是否真的下线,如果多数认为下线,就确认下线。。
重新选举master
选举新的master是由谁来负责的。kafka有会在broker里面选一个controll出来,rocketMQ 用Dledger技术选举(基于raft算法)
redis的选举和故障转移是由sentinel完成,但是sentinel有多个,需要选举出来一个leader负责选举。选举算法是raft,即先到先得,少数服从多数
raft算法(选举sentinel的leader)
raft协议里面,选举有两个超时时间。第一超时时间是,为了避免节点同时参与选举,每个节点在竞争选举之前都先随机的等待一段时间,最先到达时间的,就发起投票,先投给自己,然后请求其他节点投票。没有收到投票结果,就继续等待一段时间。进行下一轮竞争。直到某个节点拿到了大多数的票,成为了leader.
成为leader之后,会发消息让其他followers来同步消息,如果followers在指定时间内,没有收到消息,就认为leader挂了,开始让其他节点投票,成为新的leader.
redis的master选举
- 对于所有的slave节点,主要看四个因素。分别是断开连接的时长,优先级排序,复制数量,进程id.
- 如果与哨兵断开时间超过一定时间,就直接失去选举权。
- 如果拥有选举权,就看谁的级别高,在配置文件设置优先级。 replica-priority 100,数值越小优先级越高。
- 如果优先级相同,就看谁的数据多,谁的复制偏移量最大,就选谁。
- 如果数据相同,就选进程ID最小的那个。
- master选举出来后,如何让其他节点成为新的master的从节点呢?
- 首先让sentinel的leader向某个节点发送slave no one ,成为一个独立节点,即master.
- 然后向其他slave节点,发送slave of ip/port,让他这个节点的从节点。( 成为一个新的slave,如果原来有数据会先清除数据,然后向master请求rdb文件,加载数据)
- 客户端连接master过程
第一步连接sentinel,sentinel获取当前的master节点ip/port,返回给client,然后client再连接到master

sentinel的不足
- 主从切换过程中只有一个master,即使很快选举master,也可能有数据丢失
- 只能单点写,一主多从,不能解决水平扩容问题。
如果数据量大,这时候就需要对数据分片。需要水平扩容,这时候就需要多个master-slave的group,把数据分配到不同的group中。

基于客户端的redis分片(一致性hash算法)
由客户端自己实现相关逻辑,例如使用取摸的对数据分片,查询和修改都先判断路由。
jedis客户端工具包,就支持分片功能。 它是springboot 2.x版本之前默认的客户端,RedisTemplate就是对jedis的封装。
一致性hash算法
用到的原理是一致性hash算法,把所有的hash值(从0到2 ^ 32 -1)组成一个虚拟的圆环,整个空间按顺时针方向分配。因为是环形机构,0和2^32-1是重叠的。

每个redis节点,都会计算他hash值,然后加入到圆环的相应位置(reidis节点自身hash计算是采用机器的IP或者机器唯一的别名作为输入值)),这时如果一个key加入进来,就会计算他的hash值,在这个圆环上,按照顺时针的方向找到最近的redis节点。
- 注:红色圆圈为redis节点的hash值位置,绿色圆圈为数据key的hash值位置

此时如果新增一个node 5 节点,影响范围很小,不用将全部数据迁移。如下所以,只需要重新分配蓝色线条这部分的数据(Node3 到Node5这一段)。

如果node节点很少的话,还是可能数据分配不均匀。 redis还可以设置很多个虚拟节点,尽量使数据分配均匀。
可以使用ShardedJedis之类的客户端分片代码进行分片,配置简单 ,但是每个客户端都要自己维护分片策略,存在重复代码。
可以使用官方自带的redis cluster进行分片管理。客户端不需要关注细节。
基于服务端分片-redis cluster
redis cluster是由多个redis实例组成的集合,客户端不需要关注数据存储在哪个节点,只需要关注整体。每个节点之间两两交互、共享数据分片、节点状态信息等。
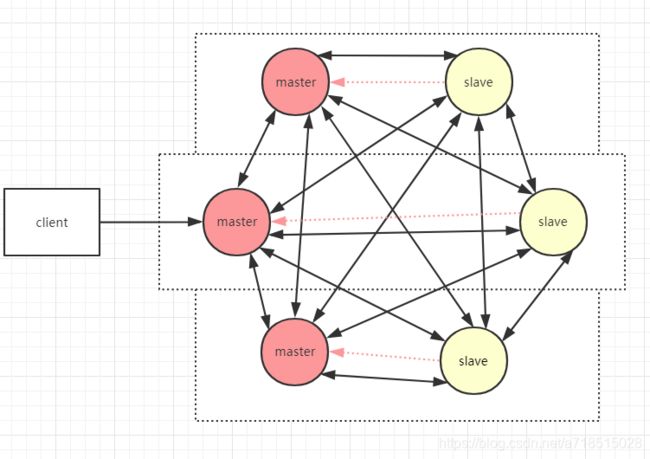
cluster如何解决分片问题?
redis cluster并没有用一致性hash算法。而是用的虚拟槽来实现。redis创建了16384个槽,每个节点负责一定区间的槽。
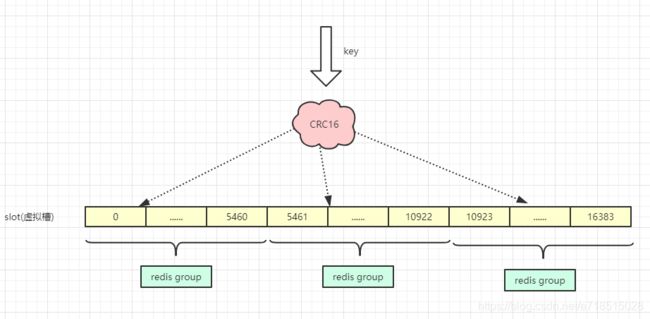
对象分布到redis节点上的时候,会对key用crc16算法计算再%16384,得到一个槽的值,数据就落到负责这个槽的相应的redis节点上。
- 怎么样相关的数据落在同一个节点上呢,比如multi key事务命令执行时候,是不能跨节点的。 在key里面加入{hash tag}即可。‘
客户端重定向
客户端该连接到哪个服务器呢? 访问的数据不在当前节点,怎么办?
比如:执行下面命令时候:
127.0.0.1:7291>set age 1
报错返回:(error) moved 13724 127.0.0.1:7293.
服务端返回的moved,表示根据当前key计算的槽,不归7291节点管理,而是归7293这个节点管理。
这个时候更换端口,去7293操作才返回ok。 这样一来客户端就要连接两次,jedis等客户端会在本地维护一份槽-node的映射关系,大部分时候不需要重定向。
新增或下线master节点,数据如何迁移(重新分配)
因为key和slot的关系是永远不会变的,即每个key计算出来的槽的位置不会变,当新增节点的时候,需要把原有的槽分配一点给新的节点负责,并且把相关的数据迁移过来。
高可用和主从切换
redis cluster集群里面的每个节点,都有主从模式,当主节点挂了之后,从节点可以竞争成为master。竞争过程,请求其它master给自己投票,超过半数投票就成为新的master。具体的可以参考。主从切换
总结redis cluster特点
- 无中心架构。
- 数据按照槽(slot)的形式存储分布在多个节点,节点之间数据共享,可以动态调整数据分布。
- 可水平扩展,节点可以动态添加和删除
- 高可用,部分节点不可用时,集群仍可用,每个节点里面实现了主从切换。
- 降低运维成本,提高了系统扩展性和可用性。
对比基于客户端的分片,客户端使用的是一致性hash算法,虽然配置简单 ,但是每个客户端都要自己维护分片策略,存在重复代码。
- redis cluster 和sentinel对比
最大的区别就是,cluster解决了水平扩展问题,可以添加节点,实现数据分片。 sentinel只能单节点的主从操作,不能实现数据分片。
如何发现redis的热点数据
redis有一个monitor命令,可以监控到所有的redis执行的命令。
monitor在高并发的场景下,会影响性能。只能统计一个redis节点的热点key.
缓存操作和布隆过滤器相关整理,移步另一篇