Python爬虫实战之:快代理搭建IP代理池(简版)
目录
- 前言
- 项目背景
- 项目简介
- 前期准备
- 讲解1:项目搭建
- 讲解2:安装 faker 库获取user-agent
- 讲解3:分析 “快代理” 页面
- 讲解4:筛选有效IP
- 讲解5:Pandas保存数据为Excel
- 讲解6:Pandas读取Excel文件
- 项目演示
- 项目代码
- GitHub地址
- 进阶参考
- 后语
前言
你好,我是Dr.叶子,用心写最优美的博客,弹最好听的钢琴!
项目背景
- 最近,我在整理爬虫知识点,发现大多网站主流反爬虫的手段一般是“IP封锁”,我们为了防止个人IP被禁,首先想到的就是搭建“IP代理池”作为第一道防屏蔽策略。
- 网上的一些知识太过于零散,项目代码不规范,所以亲自搭建实战项目,与大家分享!
项目简介
本项目主要基于Python搭建简单爬虫,爬取快代理网站的IP数据,经过有效性验证后,通过Pandas库储存到Excel文件,形成IP代理池,方便以后开展更多的爬虫项目,能防止个人IP被封锁。
前期准备
- 操作系统:Windows 8.1;
- 语言版本:Python 3.7;
- 开发工具:Pycharm 2.1 专业版;
- requests 库:发起请求;
- pandas 库:处理数据;
- bs4 库:解析文档;
- faker 库:自动随机生成 user-agent;
讲解1:项目搭建
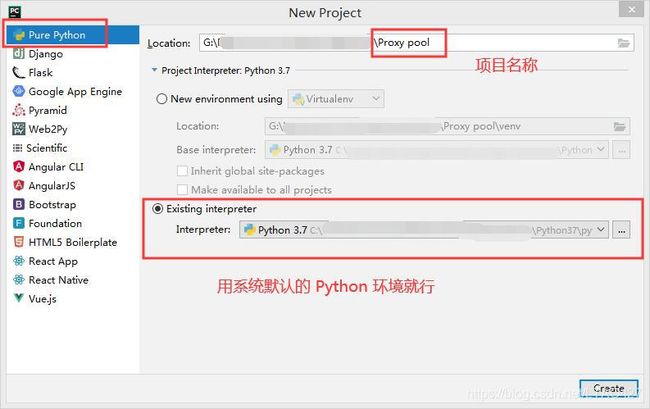
1. 打开 Pycharm: 新建 python 项目
# 首先,新建项目文件夹
File > New Project > Pure Python > ... > Create
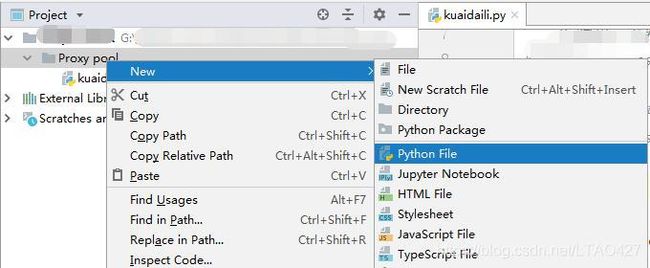
# 其次,新建 kuaidaili.py 文件
右键项目文件夹 > New > Python File > ... > Create
- 如图:
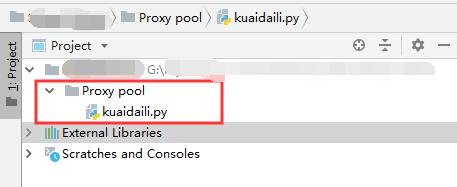
- 搭建完成,项目结构如下图:
讲解2:安装 faker 库获取user-agent
# 在终端执行
pip install faker
报错: 连接超时
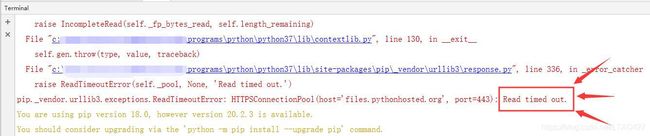
解决: 更换成豆瓣镜像
pip install faker -i http://pypi.douban.com/simple --trusted-host pypi.douban.com

如上图显示,则表示安装成功
其他库的安装同理,不再累赘
讲解3:分析 “快代理” 页面
1. 分析请求路径:
- 第 1 页
https://www.kuaidaili.com/free/inha/1/ - 第 2 页
https://www.kuaidaili.com/free/inha/2/ - 第 3 页
https://www.kuaidaili.com/free/inha/3/
… …
… … - 第 n 页
https://www.kuaidaili.com/free/inha/n/
如图:
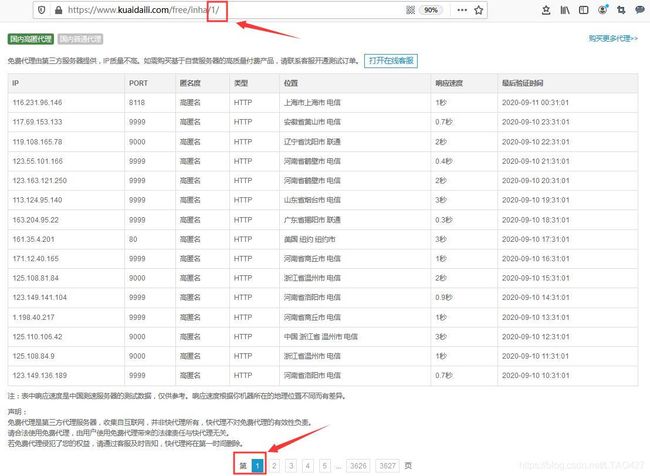
总结: 请求路径尾部的数字代表请求的是第几页,所以只要在代码里循环改变这个数字就能可持续请求爬虫。
2. 分析前端元素:
- 按F12查看,Ctrl + Shift + C 鼠标选中数据,如图:
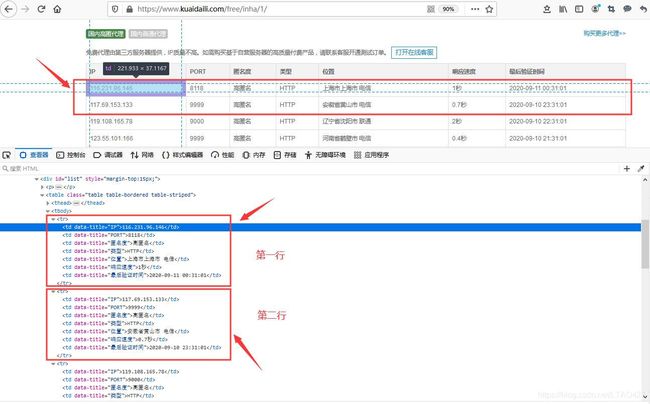
- 发现,数据存在于表格元素里,第 1~2 行数据如下:
<tr>
<td data-title="IP">116.231.96.146td>
<td data-title="PORT">8118td>
<td data-title="匿名度">高匿名td>
<td data-title="类型">HTTPtd>
<td data-title="位置">上海市上海市 电信td>
<td data-title="响应速度">1秒td>
<td data-title="最后验证时间">2020-09-11 00:31:01td>
tr>
<tr>
<td data-title="IP">117.69.153.133td>
<td data-title="PORT">9999td>
<td data-title="匿名度">高匿名td>
<td data-title="类型">HTTPtd>
<td data-title="位置">安徽省黄山市 电信td>
<td data-title="响应速度">0.7秒td>
<td data-title="最后验证时间">2020-09-10 23:31:01td>
tr>
总结:发现规律,每一行的 “ td 标签” 都有特定的 data-title=“xxx”,然后可以根据 BeautifulSoup 的 CSS 选择器来筛选出我们想要的数据。具体看代码解释。
讲解4:筛选有效IP
- 封装一个方法,用来判断抓取的 IP 对目标地址是否有效
def is_useful(ip_port, headers, target_url):
"""
判断ip是否可用
:param ip_port: ip+端口号
:param headers: 随机请求头
:param target_url: 爬虫的目标地址,作为验证代理池ip的有效性
:return: bool
"""
url = target_url # 验证ip对目标地址的有效性
proxy_ip = 'http://' + ip_port
proxies = {'http': proxy_ip}
flag = True
try:
requests.get(url=url, headers=headers, proxies=proxies, timeout=2)
print("【可用】:" + ip_port)
except Exception as e:
print('程序 is_useful 发生错误,Error:', e)
flag = False
return flag
总结:
- 由于我们爬取的代理 IP 是免费公开的(当然也有付费的),除了我们用,其他dalao也在用,这样我们抓取的 IP 说不定已经被屏蔽;
- 所以,在抓取 IP 数据后,需要验证其对目标地址的有效性;
特别注意:
- 网上常用 icanhazip.com 作为目标地址验证,这样的弊端是大量 IP 返回的结果是“连接超时”,其实对你所需要爬取的地址是有效的(例如 baidu.com),另一个问题就是响应时间过长,不适合大批量验证;
讲解5:Pandas保存数据为Excel
- 将 IP 等数据规范好格式,根据时间命名,保存问Excel文件,保存成功返回 True,否则 False
def write_proxy(proxy_list):
"""
将清洗好的列表数据,保存到xlsx文件
:param proxy_list: 代理池数据列表
:return: bool
"""
date_now = datetime.datetime.now().strftime('%Y%m%d%H%M%S') # 当前时间
flag = True # 保存成功标志
print('--- 开始保存 ---')
try:
df = pd.DataFrame(proxy_list,
columns=['ip', 'port', 'degree', 'type', 'position', 'operator', 'speed', 'last_time'])
df.to_excel(date_now + '_proxy.xlsx', index=False)
print('--- 保存成功!---')
except Exception as e:
print('--- 保存失败!---:', e)
flag = False
return flag
讲解6:Pandas读取Excel文件
- 既然爬取下来,当然得用起来,于是封装了个读取文件的方法,返回 List 列表
def read_ip():
"""
读取代理池,返回ip:port列表
:return: list
"""
# 最新爬虫数据文件名(列表推导式写法)
file_name = [f for f in os.listdir("./") if f.split('.')[-1] == 'xlsx'][-1]
# 读取文件
proxy_list = pd.read_excel('./' + file_name)
proxy_list['port'] = proxy_list['port'].astype('str') # 先将端口号的整型转为字符串
proxy_list['ip_port'] = proxy_list['ip'].str.cat(proxy_list['port'], sep=':') # 组合成ip+port
return list(proxy_list['ip_port'])
总结:
- 这里关键点是,2列(ip 和 port)数据合并成新的1列,方便后期使用,这里用到Pandas库的语法,具体看代码,或者百度一下,你就知道。
项目演示
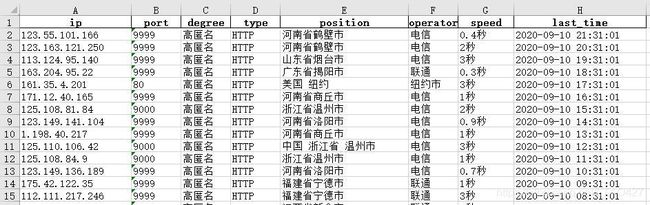
1. 直接运行,生成文件: “日期+ _proxy.xlsx” 的 Excel 文件
如图:
项目代码
kuaidaili.py
"""
作者:Dr.叶子
日期:2020年9月10日
CSDN博客主页:https://blog.csdn.net/LTAO427
github地址:https://github.com/chengyun427/Proxy_pool
"""
import os
import time
import datetime
import random
import requests
import pandas as pd
from bs4 import BeautifulSoup
from faker import Factory
def get_user_agent(num):
"""
生成不同的 user-agent
:param num: 生成个数
:return: list
"""
factory = Factory.create()
user_agent = []
for i in range(num):
user_agent.append({'User-Agent': factory.user_agent()})
return user_agent
def get_proxy(pages, ua_num, target_url):
"""
爬取代理数据,清洗整合
:param pages: 需要爬取页数
:param ua_num: 需要user-agent个数
:param target_url: 爬虫的目标地址,作为验证代理池ip的有效性
:return: list
"""
headers = get_user_agent(ua_num) # 请求头
proxy_list = [] # 最后需入库保存的代理池数据
try:
for num in range(0, pages):
print('Start:第 %d 页请求' % (num + 1))
# 请求路径
url = 'https://www.kuaidaili.com/free/inha/' + str(num + 1) + '/'
# 随机延时(randint生成的随机数n: a <= n <= b ;random产生 0 到 1 之间的随机浮点数)
time.sleep(random.randint(1, 2) + random.random())
header_i = random.randint(0, len(headers) - 1) # 随机获取1个请求头
# BeautifulSoup 解析
html = requests.get(url, headers=headers[header_i])
soup = BeautifulSoup(html.text, 'lxml')
# CSS 选择器
ip = soup.select("td[data-title='IP']")
port = soup.select("td[data-title='PORT']")
degree = soup.select("td[data-title='匿名度']")
proxy_type = soup.select("td[data-title='类型']")
position = soup.select("td[data-title='位置']")
speed = soup.select("td[data-title='响应速度']")
last_time = soup.select("td[data-title='最后验证时间']")
# 循环验证是否有效
for i, p, dg, pt, ps, sp, lt in zip(ip, port, degree, proxy_type, position, speed, last_time):
ip_port = str(i.get_text()) + ':' + str(p.get_text())
# 调用验证的方法
flag = is_useful(ip_port, headers[header_i], target_url)
if flag:
# 拼装字段
p_ip = str(i.get_text())
p_port = str(p.get_text())
p_degree = str(dg.get_text())
p_type = str(pt.get_text())
p_position = str(ps.get_text()).rsplit(' ', 1)[0]
p_operator = str(ps.get_text()).rsplit(' ')[-1]
p_speed = str(sp.get_text())
p_last_time = str(lt.get_text())
proxy_list.append([p_ip, p_port, p_degree, p_type, p_position, p_operator, p_speed, p_last_time])
print('End:第 %d 页结束!==========================' % (num + 1))
except Exception as e:
print('程序 get_proxy 发生错误,Error:', e)
finally:
# 调用保存的方法
write_proxy(proxy_list)
return proxy_list
def is_useful(ip_port, headers, target_url):
"""
判断ip是否可用
:param ip_port: ip+端口号
:param headers: 随机请求头
:param target_url: 爬虫的目标地址,作为验证代理池ip的有效性
:return: bool
"""
url = target_url # 验证ip对目标地址的有效性
proxy_ip = 'http://' + ip_port
proxies = {'http': proxy_ip}
flag = True
try:
requests.get(url=url, headers=headers, proxies=proxies, timeout=2)
print("【可用】:" + ip_port)
except Exception as e:
print('程序 is_useful 发生错误,Error:', e)
flag = False
return flag
def write_proxy(proxy_list):
"""
将清洗好的列表数据,保存到xlsx文件
:param proxy_list: 代理池数据列表
:return: bool
"""
date_now = datetime.datetime.now().strftime('%Y%m%d%H%M%S') # 当前时间
flag = True # 保存成功标志
print('--- 开始保存 ---')
try:
df = pd.DataFrame(proxy_list,
columns=['ip', 'port', 'degree', 'type', 'position', 'operator', 'speed', 'last_time'])
df.to_excel(date_now + '_proxy.xlsx', index=False)
print('--- 保存成功!---')
except Exception as e:
print('--- 保存失败!---:', e)
flag = False
return flag
def read_ip():
"""
读取代理池,返回ip:port列表
:return: list
"""
# 最新爬虫数据文件名(列表推导式写法)
file_name = [f for f in os.listdir("./") if f.split('.')[-1] == 'xlsx'][-1]
# 读取文件
proxy_list = pd.read_excel('./' + file_name)
proxy_list['port'] = proxy_list['port'].astype('str') # 先将端口号的整型转为字符串
proxy_list['ip_port'] = proxy_list['ip'].str.cat(proxy_list['port'], sep=':') # 组合成ip+port
return list(proxy_list['ip_port'])
def main():
"""
主方法
"""
pages = 1 # 定义爬取页数
ua_num = 3 # 定义需生成user-agent个数
target_url = 'https://www.baidu.com' # 爬虫的目标地址,作为验证代理池ip的有效性
proxy_list = get_proxy(pages, ua_num, target_url)
print(proxy_list)
if __name__ == '__main__':
# 1.主方法
main()
# 2.读取代理池
read_ip()
GitHub地址
欢迎加星: https://github.com/chengyun427/Proxy_pool.
进阶参考
【1】本人博客: Python爬虫实战之:快代理搭建IP代理池(Scrapy进阶版).
后语
- 原创内容,转载说明出处哦!
- 以上内容本人整理,亲测可行,如有任何问题,敬请指正,谢谢~~
- 点赞、收藏、也欢迎打赏,我弹钢琴你听呀~~哈哈!