大数据架构之Hadoop生态圈
第一章:集群规划
测试开发集群(逻辑划分):1台管理节点理解点+1台工具节点/1台边缘节点——N太工作节点

可在Cloudera Manager界面查看,端口号:7180
1台机器上部署管理节点,通常包括以下叫角色:
NN:NameNode(HDFS);
SHS:Spark History Server(Spark);
RM:Reduce Manager(YARN);
JHS:jobHistoryServer
ZK:Zookeeper;
KM:kudu Master
ISS:Impala Statestore
1台机器部署工具节点/边缘节点,工具节点通常包括的角色:、
CM:Cloudera Manager
JN:journalNode
CMS:Cloudera Management service
ICS:Impala Catelog service
NMS:NavigatorMetadata
HMS:Hive Metadata
NAS:Navigator Audit Srver
ZK, Fluem, Sqoop, Hue, HttpFS
边缘节点通常包括的角色:
GW: Gateway configuration
Hue, Sqoop, Flume, HiveServer
工作节点通常包括的角色:
Impala Daemon, NodeManager, DataNode, Kudu Tablet Server
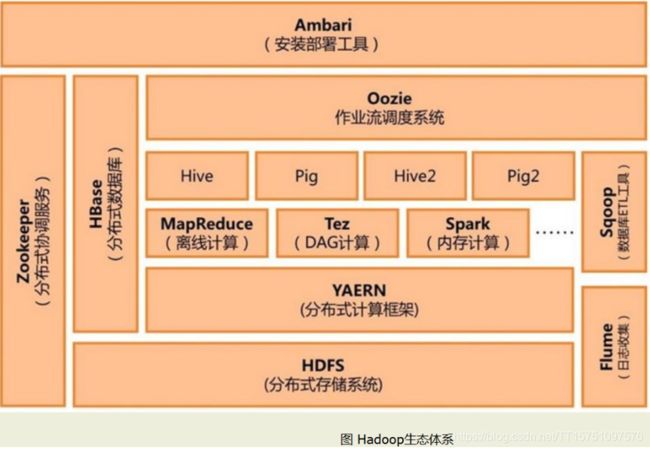
第二章:Hadoop生态圈
Hadoop生态圈中,HDFS提供文件存储,YARN提供资源管理,在基础上,进行各种处理,包括mapreduce,Tez,Sprak,Storm等计算。
第三章:Hadoop三大核心组件
Hadoop集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但是物理上常在一起。
(1)HDFS集群:负责海量数据的存储
(2)YARN集群:负责海量数据运算时的资源调度
(3)Map Reduce:它其实是一个应用程序开发包 。(最重要)
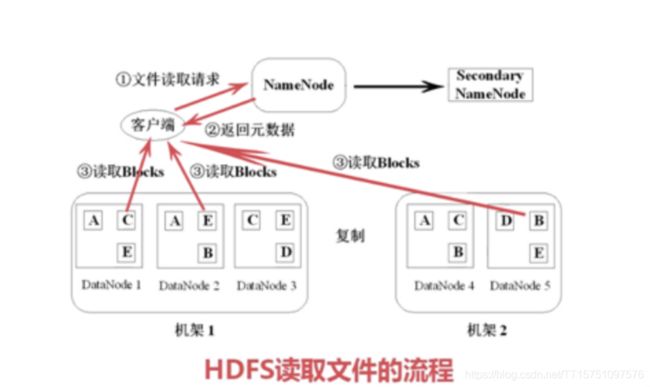
(1)HDFS(Hadoop Distributed File System)
HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序的数据访问功能,适合大型数据集的应用程序,它提供了一次写入多次读取的机制,数据以块的形式,同时分布在集群中不同物理机器上。
快速理解:
1)HDF的文件被分成块进行存储,默认为64M,块是文件存储处理的逻辑单元。
2)HDFS有两个节点,Name Node和DATa Node
3)Name Node是管理节点,存储文件元数据。文件与数据的映射表;数据块与数据节点的映射表
4)DATa Node是HDFS的工作节点,存储数据库。
5)每个数据库3个副本,分布在两个机架内的三个节点。
6)DATa Node定期向Name Node发送消息。
7)二级Name Node定期同步元数据映射文件和修改日志,作为备胎。
特点:
1)数据冗余,硬件容错
2)流式事务数据访问
3)存储大文件
应用:
1)适合数据批量读写,吞吐量高。不适合交换式应用,低延迟很难满足。
2)适合一次性写入多次读取,顺序读写。不支持多用户并发写入相同文件。
常用操作指令:
常用操作指令:
#初始格式化
hadoop namenode -format
#打印Hdfs当前文件夹
hadoop fs -ls/
#创建并上传文件操作
hadoop fs -mkdir input
hadoop fs -put hadoop_env.sh input /
#查看具体文件
hadoop fs -cat input/hadoop_env.sh
#下载文件
hadoop fs -get input/hadoop_env.sh hadoop_env2.sh
#查看文件系统所有文件
hadoop dfadmin -report


(2)YARN(Yet Another Reduce Negotiator,另一种资源协调者)
YARn是一个通用的资源管理平台,可为各类计算框架提供资源的管理和调度。
其核心出发点是为了分离资源管理器与作业调度/监控,实现分离的做法是拥有一个全局的资源管理器。
(Reduce Manager,RM),以及每个应用程序对应一个的应用管理器(Reduce NanaManager,RM),以及每个应用程序对应一个应用管理器(Application Master,AM),应用程序由一个作业(job)或者job的有向无环图(DAG)组成。
快速理解:
1)YARN可以将多种计算框架(如离线处理Map Reduce,在线处理的Storm,迭代式计算框架Spark,流式处理框架S4等)部署到一个公共集群中,共享集群的资源。并提供如下功能:
资源的统一管理和调度:
集群中所有节点的资源(内存,CPU,磁盘,网络等)抽象为Container(集装箱)。计算框架需要资源进行运算任务时需要向YARN申请Container,YARN按照特定的策略对资源进行调度进行Container的分配。
资源隔离:
YARN使用了轻量级资源隔离机制Cgroups进行资源隔离以避免相互干扰,一旦Container使用的资源量炒作事先定义的上限值,就将其杀死。
YARN时对Map Reduce V1重构得到的,有时候也成为Map Reduce V2.
YARN可以看作成一个云操作系统,有一个ReduceManager和多个Node Manager(启动一个Container相当于启动一个进程)方式分配给应用程序启动Application Master(相当于主进程中运行逻辑),或运行Application Master切分的各Task(相当于子进程中运行逻辑)
(3)Map Reduce(分布式计算,是大数据应用技术的解决方案)
分而治之,一个大任务分成多个小任务(map),并行执行后,合并结果(reduce)
快速理解:
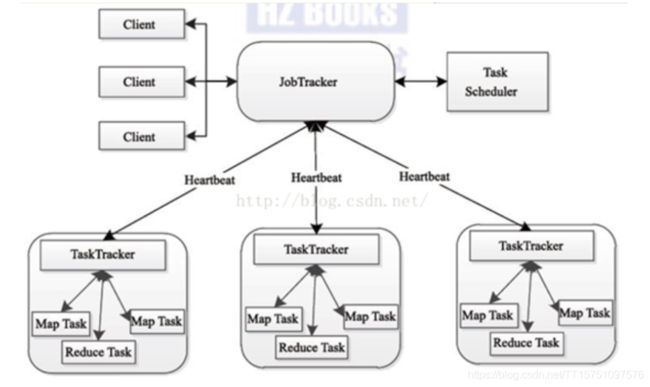
1)用于执行Map Reduce任务的机器角色有两个:一个是job Tracker;另一个时Task Tracker,job Tracker适用于调度工作的,Task Tracker是用于执行工作的。一个Hadoop集群中只有一台job Tracker。
2)Task Tracker对应HDFS中的Data Node。
3)job Tracker的作用:作业调度,分配任务,监控任务执行进度;监督Task Tracker的状态
4)Task Tracker的作用:执行任务没,汇报任务状态。
5)mapreduce的容错机制,重复执行(4次),推测执行。
应用:
1)100G的网络访问日志文件,找出访问次数最多的地址。
2)wordcount
第四章:Hadoop其他组件介绍
(4)Flume(日志收集工具)【水槽】
Flume数据流提供对日志数据进行简单处理的能力,如过滤,格式转换等。同时,Flume还具备能够将日志邪王各种数据目标的能力。
相关概念:
Flume逻辑上分为三层架构:agent,collector,storage
agent用于采集数据,collector用户数据汇总,storage是存储系统
(5)sqoop(数据同步传输工具)
用于Hadoop(hive)与传统数据库的数据传输。TEL
(6)Zookeeper(分布式协作服务)【动物饲养员】
Zookeeper,解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,哟用户管理Hadoop操作。分布式应用程序可以基于ZooKeeper实现诸如数据发布/订阅,负载均衡,命名服务,分布式协调/通知,集群管理,Master选举,分布式锁和分布式队列等功能。
快速理解:
ZooKeeper的核心功能,文件系统和通信机制。
1)文件系统:
每一个目录都是一个znode节点;Znode节点可直接寻相互数据;类型,持久化。
2)通信机制:
客户端监听关心的Znode节点;znode节点有变化时,通知客户端。
3)Zookeeper的核心时原子广播,保证了各个Server之间的同步。实现这种机制的协作叫做ZAB协议。
(Zookeeper Atomic BrodCast)
ZAB协议:
核心算法paxos算法,一种基于消息传递且具有高度容错性的一致性算法。分布式系统中的节点通信存在两种模型,共享内存,消息传递。
paxos算法解决的问题是一个可能发生上述异常的分布式系统中如何就某个值达成一致,保证不论发生以上任何异常,都不会破坏决策的一致性。
(7)Hbase(分布式列存储数据库)
hbase是运行在hdfs之上的一种数据库,以键值对的形式存取数据,能够快速在主机内数十亿行数据中定位所需的数据并访问,而HDFS却缺乏随即读写操作,不能满足实时需求。
快速理解:
1)海量数据存储
2)准时查询,100ms
特点:
1)容量大,百亿行,百万列
2)面向列,列式存储,可单独对列进行操作
3)扩展性,底层依赖于HDFS,动态增加机器即可
4)可靠性,HDFS本身有备份
5)高性能,LSM数据结构,Rowkey有序排序
Hbase表结构:
1)列簇,1张列簇不超过5个,列簇没有限制,列(修饰符)只有插入数据才存在,列(修饰符)早列簇中是有序的。eg:个人信息|教育信息|工作经历
2)不支持条件查询名列动态增加,数据自动切分,高并发读写。
启动方法:
启动方式:
输入:hbase shell
查询表:list
查询表数据信息:(1)scan '表名' (2)count '表名'
命令:(注意,复制可能报错,只能手打)
#查看
scan '表名:列簇','条件'
#只返回前两行记录
scan 'table_name:info',{LIMIT =>2}
#查看具体某一行
get 'table_name:info','00123_22'
#模糊查找某一列数据
scan 'table_name:info',FILTER=>"ColumnPrefixFilter('td_id') AND ValueFilter(=,'substring:$_08_03')"
(8)Hive(数据仓库)
Hive是建立在Hadoop上的数据仓库基础架构,类似一种SQL解析引擎,它将SQL语句转化成Map Reduce,然后再Hadoop上执行。
启动方式:
hive;
show tables;
select * from table_name;
quit;
命令:
# 创建数据文件
hadoop fs -vi /home/testdata.dat
#创建库
create database test
#创建表
create table test(id int,name string,age string) ROW format DELIMITED FIELDS
TERMINATED BY '\t' stored as TEXTFILE;
#加载数据
load data local inpath '/root/data/students.txt' into table test;
#删除表
drop database if exists test;
#大小写转换
select lower('hello world'),upper('hello world')
#去掉前后的空格
trim
注意:HBase和Hive的区别
- hbase是基于Hadoop实现的数据库,不支持SQL
2)hive是基于Hadoop实现的数据仓库,适合海量数据的运用,支持类SQL操作。
数据仓库的特性
数据仓库用称做数据立方体的多维数据结构建模,他是一个从多个数据源收集的信息存储库,存放在一致的模式下,并通过通常驻留在单个站点上。
数据仓库是面向主题的,集成的,其数据时随着时间变化而变化的,其数据是不可修改的。
(9)Tez
支持DAG作业的计算框架,对Map Reduce的进一步拆分。
(10)OOzie(工作流调度系统)
用来管理hadoop任务,工作流调度:工作流程的编排、调整,安排事件的触发执行。OOzie是一个可扩展的工作体系,集成于Hadoop的堆栈,用于协调多个MapReduce作业的执行。OOzie的工作流是放置在控制依赖DAG(有向无环图 Direct Acyclic Graph)的一组动作(例如,hadoop的Map/Reduce作业,Pig作业等),其中指定了动作执行的顺序。OOzie使用hPDL(一种XML流程定义语言)来描述这个图。
(11) Hue (Hadoop user Experience)大数据协作框架,web访问。
访问端口:8889
使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job,执行Hive的SQL语句,浏览Hbase数据库。
(12) Impala (数据查询系统)
提供SQL语义,能查询存储在Hadoop的HDFS和HBASE的PB级的大数据。Impala没有使用MapReduce进行并行运算,所以Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询。
(13) Sentry(事件日志记录和汇集的平台)【哨兵】
Sentry是一个开源的实时错误报告工具,支持Web前后端、移动应用以及游戏。通常我们所说的Sentry是指后端,有Django编写。
(14) Solr(全文搜索服务器,基于lucene)
Sentry是一个独立的企业其搜索应用服务器,它是一个高性能,采用JAVA5开发,它对外提供类似于Web-service的API接口。用户可以通过HTTP请求,向搜索引擎提交一定格式的XML文件,生成索引。
(15) Lucene
它是一套用于全文检索和搜索的开发源代码程序库。Lucene提供了一个简单却强大的应用接口程序,能够做全文索引和搜索,它是最受欢迎的免费Java信息检索程序库。
(16) pig
为大型数据集的处理提供抽象,与MapReduce相比,Pig提供了更丰富的数据结构,一般都是多值和嵌套的数据结构。它提供强大的数据变换,包括在MapReduce中被忽视的连接Join操作。
(17) Ambari
一种基于web的工具,支持hadoop集群的供应、管理和监控。
(18)Storm(实时处理框架)【暴风雨】
类似于Hadoop的实时处理框架,毫秒级。随着越来越多的场景对Hadoop的MapReduce高延迟无法容忍,比如网站统计、推荐系统、预警系统、金融系统(高频交易)等等,大数据实时处理解决方法的应用日趋广泛,其中Strom成为流计算技术中的佼佼者。
基本概念:
Storm的主从架构由Nimbus(主结点)、zookeeper(协作框架)、supervisor(从节点)和worker(各个机器)组成。
1)Nimbus的作用:接收客户端代码,拆分成多个task,将task信息存入zookeper;将task分配给supervisor,将映射关系存入zookeeper;故障检测
2)supervisor的作用:从Nimbus目录读取代码,从zk上读取分配的task;启动工作进程worker执行任务;检测运行的工作进度worker.
- worker的作用:从zk上去读取分配的task,并计算出task需要给哪些task分布消息;启动一个或多个Executor线程执行任务Task.
4)zookeeper的作用:协调Nimbus与supervisor进行通信;协调supervisor与worker进行通信;保证Nimbus的高可用性。
(19)Kylin【麒麟】
一个开源的分布式分析引擎,为Hadoop等大型分布式数据平台之上的超大规模数据集提供通过标准SQL查询及多维分析(OLAP)的功能,提供亚秒级的交互分析能力。
Tips:ETL(数据仓库技术)
extract,transform,load(抽取)(转换)(加载)
(20) Kibana
它是一个开源的分析和可视化平台,设计用于和ElasticSearch一起工作,你用Kibana来搜索,查看并存在ES索引中的数据进行交互。
常用端口(ES):5601
常用es查询指令:
通常格式:GET 索引/类型
例如:
精确查找:
GET topic_index/topic_type/_search
{
"query":{
"term":{
"id":{
"value":"$09_1213"
}
}
}
}
模糊前缀查找:
GET topic_index/topic_type/_search
{
"query":{
"prefix":{
"id":{
"value":"$09"
}
}
}
}
(21) Kafka(分布式消息队列)
端口号:9092
主要用于处理活跃的流式数据,这些数据包括网站的pv,uv。
它由producer、Broker和consumer三部分组成。
基本概念:
producer: 消息和数据的生产者,向kafka的一个topic发布消息的进程、代码、服务,负责发布消息到Broker.
Broker: Kafka集群包含一个或多个服务器,这种服务被称为Broker.
Consumer: 消息和数据的消费者,订阅消息,向Broker读取消息的客户端。
Topic: kafka消息的类别,每条发布到kafka集群的消息都有一个类别,这个类别称为Topic.
Partition: kafka下数据存储的基本单元,每个Topic包含一个或多个Partition.
Consumer Group: 对于同一个Topic,会广播给不同的Group。每个Consumer属于一个特定的Consumer Group.
Replication Leader: 负责partition上Producer与Consumer的交互。
ReplicaManager: 负责管理当前Broker所有分区和副本的信息。
特点:
1)多分区
2)多副本
3)多订阅者
4)基于zookeeper调度
应用场景:
1)消息队列
2)行为跟踪
3)元数据监控
4)日志收集
5)流处理,时间源
6)持久性日志
手动导入数据到Kafka命令
#创建主题,replication-factor表示该topic需要在不同的broker中保存几份,partions为几个分区
./kafka-topics.sh --create --zookeeper cdh-node04:2111 --replication-factor 3 – partitions 1 --topic test01
#描述主题
./kafka-topic.sh --zookeeper cdh-node04:2111 --describe --topic test01
#生产者发送数据
./kafka-console-producer.sh --broker-list cdh-node04:2111,cdh-node05:3111 --topic test01 +(复制黏贴的数据【固定格式:一般为JSON 】)
#消费者消费数据
./kafaka-console-consumer.sh --zookeeper cdh-node04:2111 --topic test01 (–from-beginning从头开始查看数据)
(22) Azkaban(批量工作流任务调度器)
主要用于在一个工作流内以一个特定的顺序运行一组工作和流程,它的配置是通过简单的key:value键值对的方式,通过配置中的dependencies来设置依赖关系,这个依赖关系是无环的,否则会被视为无效的工作流。相比于OOzie的配置复杂度高,Azkaban有如下有点:
1)通过job配置文件快速建立任务和任务之间的依赖关系。
2)提供功能清晰,简单易用的web UI界面。
3)提供模块化和可插拔的插件机制,原生支持command,java,pig,hadoop。
- 基于java开发,代码结构清晰,易于二次开发。
(23) Nginx(反向代理服务器)
它是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP代理服务器。Nginx是一款轻量级的Web服务器/反向代理服务器以及电子邮件代理服务器,并在一个BSD-like协议下发型,其特点是占有内存小,并发能力强。事实上nginx的并发能力确实在同类型的网络服务器中表现较好,中国大陆使用nginx网站的有:百度,京东,腾讯,淘宝,网易。
应用:
Nginx实现负载均衡,
(24) spark和spark2(大数据处理的计算引擎)
Spark是UC Berkeley AMP lab开发的一个集群计算的框架,类似于Hadoop,但有很多的区别。最大的优化是让计算任务的中间结果可以存储在内存中,不需要每次都写入HDFS,更适用于需要迭代的MapReduce算法场景中,可以获得更好的性能提升。例如一次排序测试中,对100TB数据进行排序,Spark比Hadoop快三倍,并且只需要十分之一的机器。Spark集群目前最大的可以达到8000节点,处理的数据达到PB级别,在互联网企业中应用非常广泛.
相关概念:
1)在spark中,所有计算都是通过RDDS的创建、转化和操作完成的。RDDS(Resilent Distributed datasets,弹性分布式数据集)是并行分布在整个数据集中,是spark分发数据和计算的基础抽象类。
2)Spark运行架构包括集群资源管理器(Cluster Manager),运行作业任务的工作节点(worker Node),每个应用的任务控制节点(Driver)和每个工作节点上负责任务的执行进程(Executor).
Spark程序的执行过程:
1)创建SparkContext对象
2)从外部数据源读取数据,创建fileRDD对象
3)构建依赖关系,fileRDD->filterRDD,形成DAG
4)Cache()缓存,对filterRDD进行持久化
5)Count()执行。
与Hadoop MapReduce比较:
1)spark采用多线程来执行任务,而MapReduce采用多进程,优点是减少了任务开销。
2)Excutor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,当需要多轮时,可将中间结果存储到这个模块中,下次需要时,可以直接读取,不需要读写到HDFS等文件系统中,减少IO开销。
3)实例:100T的数据量,spark 206个节点,只需23分钟;MapReduce 2000个节点,需要72分钟。
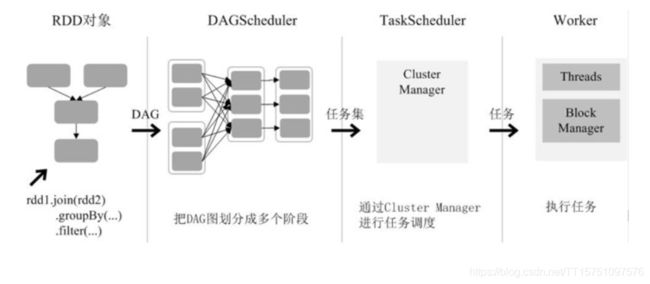
RDD在Spark架构中的运行过程(如图所示):
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点(Worker Node)上的Executor去执行。
特写:
1.1 zookeeper简介
Zookeeper 是 Hadoop 生态系统中的协同实现,是Hadoop集群管理的一个必不可少的模块,它主要来控制集群中的数据,如它管理Hadoop集群中的NameNode,还有Hbase中Master Election、Server之间状态同步等。Zookeeper 实际上是 Google 的 Chubby 一个开源的实现。Zookeeper 的配置中心实现更像一个文件系统,文件系统中的所有文件形成一个树状结构。Zookeeper 维护着这样的树形层次结构,树中的节点称为 Znode, 每个 Znode 存储的数据有小于 1m 的大小限制。zookeeper 对 Znode 提供了几种类型:临时 Znode、持久 Znode、顺序 node 等几种类型,用于不同的一致性需求。在 Znode 发生变化时,通过“观察”(watch)机制可以让客户端得到通知。可以针对 Zookeeper 服务的“操作”来设置观察,该服务的其他操作可以触发观察。Zookeeper 服务的“操作”包括一些对 Znode 添加修改获取操作。Zookeeper 采用一种类似 Paxos 的算法实现领导者选举,用于解决集群宕机的一致性和协同保障。总体上,Zookeeper 提供了一个分布式协同系统,包括配置维护、名字服务、分布式同步、组服务等功能,并将相关操作接口提供给用户。
1.2 zookeeper架构
Zookeeper 从设计模式角度来看,是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper 就将负责通知已经在 Zookeeper 上注册的那些观察者做出相应的反应,从而实现集群中类似 Master/Slave 管理模式。
Zookeeper数据结构的特点:(强记!!!)
? 每个子目录项如 NameService 都被称作为 Znode,这个 Znode 是被它所在的路径唯一标识,如 Server1 这个 Znode 的标识为 /NameService/Server1;
? Znode 可以有子节点目录,并且每个 Znode 可以存储数据,注意 EPHEMERAL 类型的目录节点不能有子节点目录(因为它是临时节点);
? Znode 是有版本的,每个 Znode 中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据;
? Znode 可以是临时节点,一旦创建这个 Znode 的客户端与服务器失去联系,这个 Znode 也将自动删除,Zookeeper 的客户端和服务器通信采用长连接方式,每个客户端和服务器通过心跳来保持连接,这个连接状态称为 session,如果 Znode 是临时节点,这个 session 失效,Znode 也就删除了
? Znode 的目录名可以自动编号,如 App1 已经存在,再创建的话,将会自动命名为 App2
? Znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个是 Zookeeper 的核心特性。
1.2 zookeeper使用场景
1.2.1统一命名服务(Name Service)
分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住,通常情况下用树形的名称结构是一个理想的选择,树形的名称结构是一个有层次的目录结构,既对人友好又不会重复。Name Service 已经是 Zookeeper 内置的功能,你只要调用 Zookeeper 的 API 就能实现。如调用 create 接口就可以很容易创建一个目录节点。
例如有一组服务器向客户端提供某种服务,我们希望客户端每次请求服务端都可以找到服务端集群中某一台服务器,这样服务端就可以向客户端提供客户端所需的服务。对于这种场景,我们的程序中一定有一份这组服务器的列表,每次客户端请求时候,都是从这份列表里读取这份服务器列表。那么这分列表显然不能存储在一台单节点的服务器上,否则这个节点挂掉了,整个集群都会发生故障,我们希望这份列表时高可用的。高可用的解决方案是:这份列表是分布式存储的,它是由存储这份列表的服务器共同管理的,如果存储列表里的某台服务器坏掉了,其他服务器马上可以替代坏掉的服务器,并且可以把坏掉的服务器从列表里删除掉,让故障服务器退出整个集群的运行,而这一切的操作又不会由故障的服务器来操作,而是集群里正常的服务器来完成。这是一种主动的分布式数据结构,能够在外部情况发生变化时候主动修改数据项状态的数据机构。Zookeeper框架提供了这种服务。这种服务名字就是:统一命名服务。
1.2.2配置管理(Configuration Management)
配置的管理在分布式应用环境中很常见,例如同一个应用系统需要多台 PC Server 运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的 PC Server,这样非常麻烦而且容易出错。像这样的配置信息完全可以交给 Zookeeper 来管理,将配置信息保存在 Zookeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中。zookeeper服务也会保证同步操作原子性(要么成功同步成功,要么失败),确保每个服务器的配置文件都能被正确的更新。
1.2.3集群管理(Group Membership)
Zookeeper 能够很容易的实现集群管理的功能,如有多台 Server 组成一个服务集群,那么必须要一个master知道当前集群中每台机器的服务状态,一旦有机器不能提供服务,集群中其它节点必须知道,从而做出调整重新分配服务策略。同样当增加集群的服务能力时,就会增加一台或多台 Server,同样也必须让master知道。Zookeeper 不仅能够帮你维护当前的集群中机器的服务状态,而且能够帮你选出一个master,让这个master来管理集群,这就是 Zookeeper 的另一个功能 Leader Election。
它们的实现方式都是在 Zookeeper 上创建一个 EPHEMERAL 类型的目录节点,然后每个 Server 在它们创建目录节点的父目录节点上调用getChildren(String path, boolean watch) 方法并设置 watch 为 true,由于是 EPHEMERAL 目录节点,当创建它的 Server 死去,这个目录节点也随之被删除,所以 Children 将会变化,这时 getChildren上的 Watch 将会被调用,所以其它 Server 就知道已经有某台 Server 死去了。新增 Server 也是同样的原理。
Zookeeper 如何实现 Leader Election,也就是选出一个 Master Server。和前面的一样每台 Server 创建一个 EPHEMERAL 目录节点,不同的是它还是一个 SEQUENTIAL 目录节点,所以它是个 EPHEMERAL_SEQUENTIAL 目录节点。之所以它是 EPHEMERAL_SEQUENTIAL 目录节点,是因为我们可以给每台 Server 编号,我们可以选择当前是最小编号的 Server 为 Master,假如这个最小编号的 Server 死去,由于是 EPHEMERAL 节点,死去的 Server 对应的节点也被删除,所以当前的节点列表中又出现一个最小编号的节点,我们就选择这个节点为当前 Master。这样就实现了动态选择 Master,避免了传统意义上单 Master 容易出现单点故障的问题。
1.2.4共享锁(Locks)
共享锁在同一个进程中很容易实现,但是在跨进程或者在不同 Server 之间就不好实现了。Zookeeper 却很容易实现这个功能,实现方式也是需要获得锁的 Server 创建一个 EPHEMERAL_SEQUENTIAL 目录节点,然后调用 getChildren方法获取当前的目录节点列表中最小的目录节点是不是就是自己创建的目录节点,如果正是自己创建的,那么它就获得了这个锁,如果不是那么它就调用 exists(String path, boolean watch) 方法并监控 Zookeeper 上目录节点列表的变化,一直到自己创建的节点是列表中最小编号的目录节点,从而获得锁,释放锁很简单,只要删除前面它自己所创建的目录节点就行了。
当分布式系统操作数据,例如:读取数据、分析数据、最后修改数据。在分布式系统里这些操作可能会分散到集群里不同的节点上,那么这时候就存在数据操作过程中一致性的问题,如果不一致,我们将会得到一个错误的运算结果,在单一进程的程序里,一致性的问题很好解决,但是到了分布式系统就比较困难,因为分布式系统里不同服务器的运算都是在独立的进程里,运算的中间结果和过程还要通过网络进行传递,那么想做到数据操作一致性要困难的多。Zookeeper提供了一个锁服务解决了这样的问题,能让我们在做分布式数据运算时候,保证数据操作的一致性。
1.2.5队列管理
Zookeeper 可以处理两种类型的队列:
同步队列:当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。
同步队列用 Zookeeper 实现的实现思路如下:
创建一个父目录 /synchronizing,每个成员都监控标志(Set Watch)位目录 /synchronizing/start 是否存在,然后每个成员都加入这个队列,加入队列的方式就是创建 /synchronizing/member_i 的临时目录节点,然后每个成员获取 / synchronizing 目录的所有目录节点,也就是 member_i。判断 i 的值是否已经是成员的个数,如果小于成员个数等待 /synchronizing/start 的出现,如果已经相等就创建 /synchronizing/start。
FIFO 队列:先进先出队列,例如实现生产者和消费者模型。
FIFO 队列用 Zookeeper 实现思路如下:
实现的思路也非常简单,就是在特定的目录下创建 SEQUENTIAL 类型的子目录 /queue_i,这样就能保证所有成员加入队列时都是有编号的,出队列时通过 getChildren( ) 方法可以返回当前所有的队列中的元素,然后消费其中最小的一个,这样就能保证 FIFO。