Hadoop生态系统之Flume
文章目录
-
- Flume概念(数据实时采集)
- Flume版本更迭
- Flume结构(核心为Agent)
-
- 完整工作流程
- 核心(event)
- 组件剖析
-
- source
- channel
- sink
- Interceptor(chain 责任链形式)
- Selector
- Process
- 组件配置(可配置项过多,可以自行百度,只贴基本配置)
-
- 1.基础配置(配置conf文件)
- 2.特定组件具体配置
-
- source组件配置
- channel组件配置
- sink组件配置
- 拦截器配置 (配置在source中)
- 选择器配置(配置在source中)
- Process配置(在配置Agent组件中配置)
- 3.执行Agent的命令
- Flume的特点
-
- 1:可靠性
- 2:可恢复性
- Flume使用场景
-
- 5.1、多个agent顺序连接
- 5.2、扇入流
- 5.3、多级流(扇出流)
- 5.4、load balance功能
Flume概念(数据实时采集)
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统
Flume版本更迭
老版本:flume-og 需要zookeeper的支持
新版本:flume-ng 不需要zookeeper的支持(本文说的都是新版本的)
Flume结构(核心为Agent)
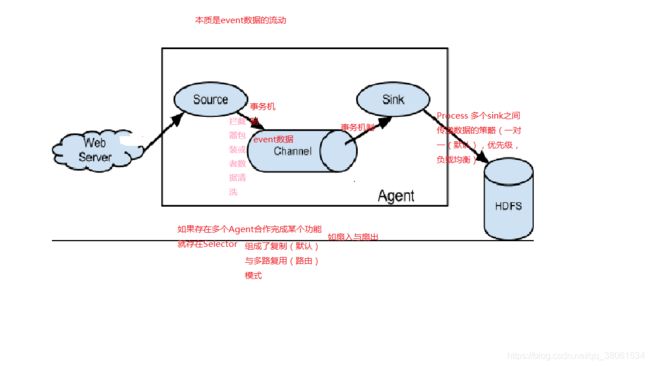
完整工作流程

这种机制保证了数据传输的可靠与安全
核心(event)
本身是一个字节数组,可携带headers信息,是事务的基本单位,如果是文本文件,通常为一行记录,flume处理日志时流动的是event
组件剖析
source
职能:
专门从网络收集数据
可处理类型:
avro thrift exec jms spooling directory netcat sequence
generator syslog http legacy 甚至自定义
channel
职能:
存放的临时数据,缓存
可存放地点:
内存(memory),jdbc,磁盘(file)
sink
职能:
将数据发往目的地的组件
目的地类型:
hdfs,logger(控制台),avro,thrift,ipc,flie,hbase,solr,自定义
Interceptor(chain 责任链形式)
职能:
用于在Source与channel之间的数据包装或者数据清洗
Selector
职能:
选择器可以工作在在复制,路由模式下
Process
职能:
指定sink传递给下一个(或者多个)Agent的传递策略
组件配置(可配置项过多,可以自行百度,只贴基本配置)
1.基础配置(配置conf文件)
1)配置Agent的组件
a1.sources=r1
a1.channels=c1(可配置多个通道 以空格隔开)
a1.sinks=s1(可配置多个 以空格隔开)
(其中a1,r1,c1,s1都可以随意定义)
2)配置Channel绑定source与sink
a1.sources.r1.channels=c1(可对应多个通道 以空格隔开)
a1.sinks.s1.channel=c1(一个通道对应一个sink)
3)配置source
4)配置channel
5)配置sink
2.特定组件具体配置
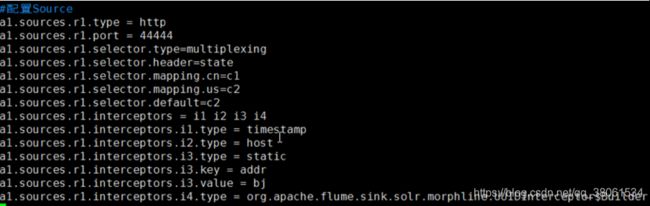
source组件配置
1)配置avro类型source
接收数据是经过avro序列化的后数据 反序列化继续传输
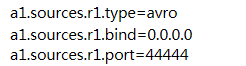
设置类型,绑定ip与端口,本机IP定义为(0.0.0.0)
2)配置exec类型source
将linux产生的输出作为数据源
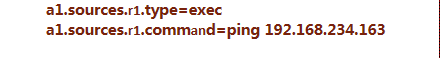
command的内容也可以是cat的文件内容也可以是其他
3)配置Spooling Directory类型的Source
监听目录(一旦有文件就当做source处理) 目录中文件不能修改 不能重名

4 )配置NetCat类型的Source
监听某个端口 接收的是字符串类型的数据 nc命令传输数据
![]()

5)Sequence Generator Source(用于测试)
序列发生器 不断产生事件 值从0开始每次递增1
![]()
6)http类型的source
将http post get(get仅用于实验)请求作为flume事件源
curl命令可以模拟一次http的Post请求
![]()
![]()
channel组件配置
1)内存类型的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=50000(事件在信道中最大数目)
a1.channels.c1.transactionCapacity=1000(每个事务中最大事件数目)
2)磁盘文件类型的channel
![]()
sink组件配置
1)Logger Sink
放在日志中 控制台显示
要求:–conf参数制定的目录下有log4j的配置文件
![]()
2 )File Roll Sink
以文件保存日志信息

3)Avro Sink(多级流动的基础)

配置传入到下一个Agent(下一台服务器)的ip与端口
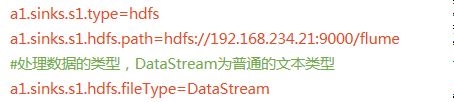
4)Hdfs Sink
将事件(event)写入到分布式文件系统中去
拦截器配置 (配置在source中)
1)Timestamp Interceptor
插入毫秒为单位的时间戳,若已有则保留原有的时间戳(默认保留可以设置覆盖)
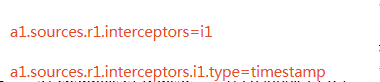
2)Host Interceptor
数据中插入当前处理Agent的主机名与ip

3)static Interceptor
用户可自定义头信息的key-value

4)UUID Interceptor
在事件头中加入全局一致标志 UUID
5 ) Search and Replace Interceptor
![]()

6 ) Regex Filtering Interceptor
![]()

![]()
7 ) Regax Extractor Interceptor
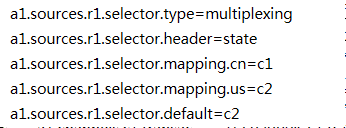
选择器配置(配置在source中)
1.复制模式配置(默认)
source内容复制 分发给多个sink(每个通道都有相同的数据)
![]()
2.路由模式配置
根据规则 选择通道进行转发

Process配置(在配置Agent组件中配置)
1)默认
2)Failover Sink Processor
为sinks分组 每个组每个sink有优先级 优先级高的先走event
sink发送事件失败,下一个最高优先级接着尝试发送

3)Load balancing Sink Processor

多个sink之间的负载均衡的能力(轮询(默认)或者随机方式,也可以自定义选择机制)通道只有一个对应多个sink

3.执行Agent的命令

Flume的特点
1:可靠性
事务保证了 节点出现故障的回滚 日志能够传送到其他节点从而不会产生丢失的情况
2:可恢复性

内存中可能因为断电或者宕机丢失数据
Flume使用场景
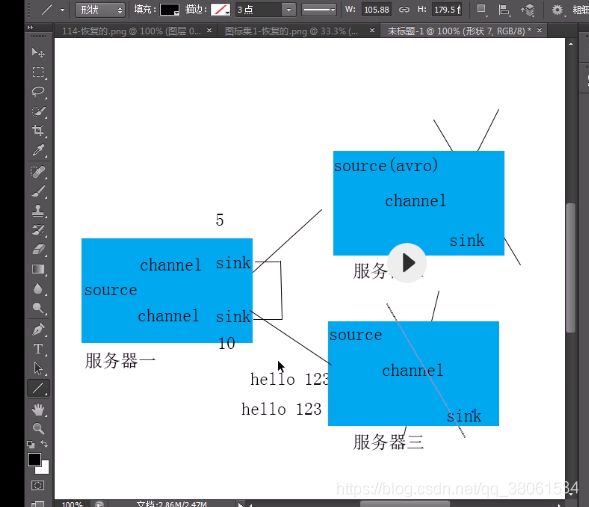
5.1、多个agent顺序连接
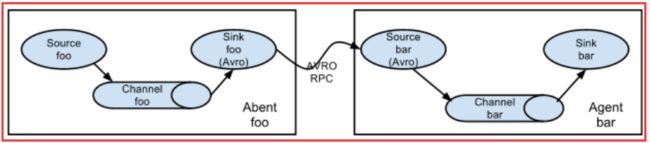
可以将多个Agent顺序连接起来,将最初的数据源经过收集,存储到最终的存储系统中。这是最简单的情况,一般情况下,应该控制这种顺序连接的
Agent 的数量,因为数据流经的路径变长了,如果不考虑failover的话,出现故障将影响整个Flow上的Agent收集服务。
5.2、扇入流

这种情况应用的场景比较多,比如要收集Web网站的用户行为日志, Web网站为了可用性使用的负载集群模式,每个节点都产生用户行为日志,可以为
每 个节点都配置一个Agent来单独收集日志数据,然后多个Agent将数据最终汇聚到一个用来存储数据存储系统,如HDFS上。
5.3、多级流(扇出流)

当syslog, java, nginx、 tomcat等混合在一起的日志流开始流入一个agent后,可以agent中将混杂的日志流分开,然后给每种日志建立一个自己的传输通道。
5.4、load balance功能
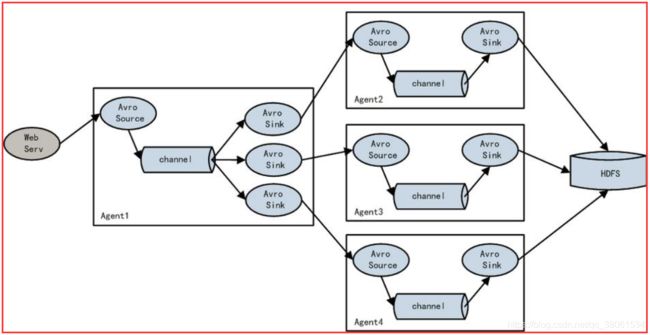
上图Agent1是一个路由节点,负责将Channel暂存的Event均衡到对应的多个Sink组件上,而每个Sink组件分别连接到一个独立的Agent上 。